
SCSKの畑です。5回目の投稿です。
第一回の続きです。今回は、前回説明した排他制御の仕組みをアプリケーションからどのように使用しているかが主な内容となります・・が、それだけだと書くことがほぼなくなってしまうので、使用するための前提条件などを補足しながらにしようと思います。
アーキテクチャ概要、及び排他制御に使用したサービス / コンポーネント
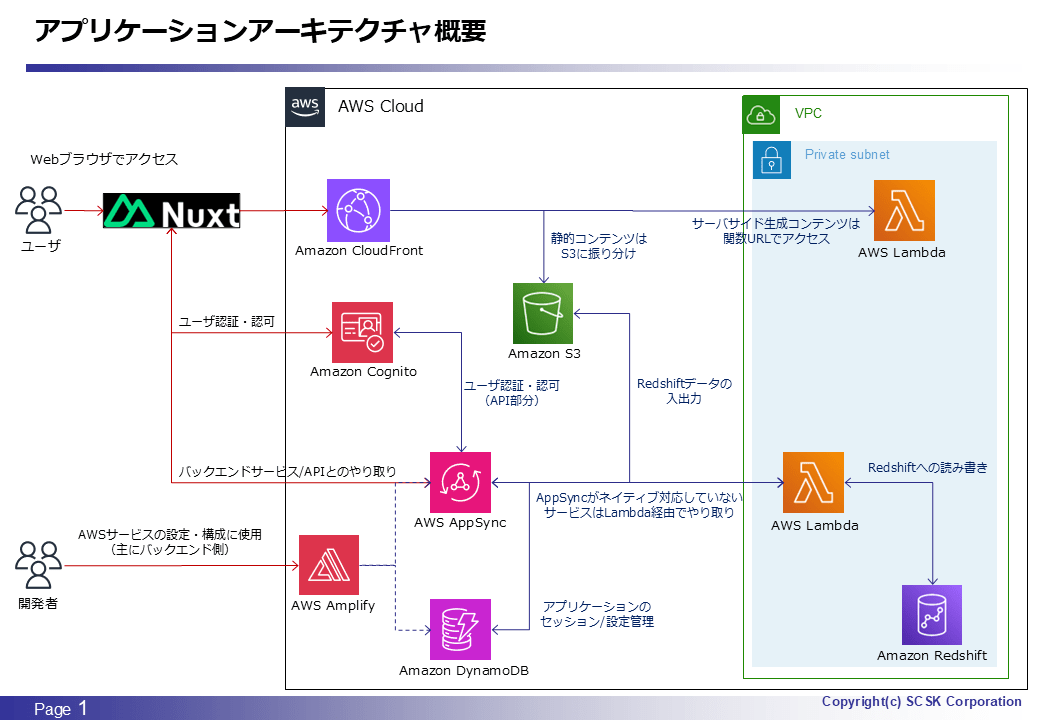
今回はほぼ AppSync & アプリケーションの話ですが、排他制御の仕組みを使用するにあたりメンテナンス対象である Redshift についても補足が必要なため、合わせて言及します。
- Amazon DynamoDB
- テーブルのステータス(編集状態)管理
- AWS Lambda
- 排他制御を考慮したテーブルのステータス更新ロジックの実装
- AWS AppSync(AWS Amplify)
- 上記 Lambda をアプリケーション上から実行するためのスキーマ定義
- アプリケーション(Nuxt.js)
- テーブルのステータスに応じた画面制御
アプリケーションにおける設計・実装
まずは、対象テーブルを通常状態から編集状態に移行する関数「setStatusEditingContent」の実装例を以下に示します。この関数を画面上のフォーム/ボタンに紐付けて実行するイメージです。
import * as mutations from "@/src/graphql/mutations";
import * as models from "@/src/API";
const setStatusEditingContent = async () => {
// 編集対象テーブルの引数定義
const input_variables:models.ChangeTableStatusWithLockInput = {
table_name: table_name,
current_status: models.TableStatus.normal,
target_status: models.TableStatus.editing,
editor: userinfo['user_name'],
}
// 編集対象テーブルのFK参照先テーブルの引数定義
const fk_tables = getTableFKList()
if (fk_tables.length > 0) {
input_variables['fk_table_name'] = fk_tables
input_variables['fk_current_status'] = models.TableStatus.normal
input_variables['fk_target_status'] = models.TableStatus.locked
input_variables['locked_by'] = table_name
}
// 排他制御を伴うステータス変更(通常状態 -> 編集状態)
const result = await client.graphql({
query: mutations.ChangeTableStatusWithLock,
variables: {
input: input_variables
}
})
// 編集状態にステータスを変更出来なかった場合
if (result.data.ChangeTableStatusWithLock.lock_result == false) {
// 対象テーブルのステータスが変更出来なかった場合
if (result.data.ChangeTableStatusWithLock.current_status === models.TableStatus.editing) {
alert('編集モードに移行できませんでした。既に他のユーザが編集中です。')
}
else if (result.data.ChangeTableStatusWithLock.current_status === models.TableStatus.locked) {
alert('編集モードに移行できませんでした。他のユーザが編集中のテーブルのFK参照先テーブルのため、ロックされています。')
}
// 対象テーブルのFK参照先テーブルのステータスが変更出来なかった場合
else {
const lock_failed_tables = []
for(const fk_table_status of result.data.ChangeTableStatusWithLock.fk_current_status){
if (fk_table_status.current_status != models.TableStatus.normal){
lock_failed_tables.push(fk_table_status.table_name)
}
}
alert(`編集モードに移行できませんでした。以下のFK参照先テーブルのロックが取得できませんでした。ロック解放後に再度試行ください。\n[${lock_failed_tables.join(', ')}]`)
}
}
}
内容自体は特に捻りもなく、前回定義した mutation の引数を最初に定義した上で graphql client から mutation を実行し、ステータス変更に失敗した場合は画面上にそのエラーを出力しています。(ステータス変更に成功した場合は画面遷移するため特に出力なし)
状態遷移に関しても、前回定義した状態遷移図に基づき、対象テーブルと FK 参照先テーブルで引数にてそれぞれ (fk_)current_status と (fk_)target_status を指定しています。ただ、FK 参照先テーブルの情報について定義している部分について、そもそもどのように FK 関連の情報を取得してきているのかここまで触れてこなかったので、この点について次のセクションで補足します。
対象 Redshift テーブルの FK 情報取得について
本アプリケーションでは、アーキテクチャ図の通り Redshift のテーブル情報を S3 上で管理しています。具体的には、アプリケーションより対象テーブルのデータ参照/編集画面にアクセスした時点で、Redshift に対して SQL 文を実行してテーブル定義情報及びデータ情報を S3 上に保存し、そのデータをアプリケーションから取得してテーブルデータを表示しています。Redshift については AppSync がネイティブ対応していないこともあり、前回説明した mutation と同じく実処理は Lambda で実装しています。
Lambda 自体は様々な要件なり理由から実装が一番複雑になってしまったこともあり今回説明はしませんが、実行している SQL 文について以下に示します。Redshift は PostgreSQL をベースとしているため、 PostgreSQL のシステムカタログを複数結合して対象テーブルの制約情報を取得しています。
なお、Redshift は DWH サービスである以上、RDBMS である PostgreSQL の機能が全てサポートされている訳ではありません。このため、一部の機能差異については今回アプリケーション側の実装でカバーする必要がありました。そのあたりの話題については、また別のエントリでまとめたいと思います。

SELECT
c.conname AS constraint_name,
CASE
WHEN c.contype = 'p' THEN 'PK'
WHEN c.contype = 'u' THEN 'UK'
WHEN c.contype = 'f' THEN 'FK'
END AS constraint_type,
t.relname AS table_name,
a.attname AS column_name,
CASE
WHEN c.contype = 'f' THEN rt.relname
ELSE NULL
END AS referenced_table_name,
CASE
WHEN c.contype = 'f' THEN ra.attname
ELSE NULL
END AS referenced_column_name
FROM
pg_constraint c
JOIN
pg_class t ON c.conrelid = t.oid
JOIN
pg_attribute a ON a.attrelid = t.oid
AND a.attnum = ANY(c.conkey)
JOIN
pg_namespace nsp ON c.connamespace = nsp.oid
LEFT JOIN
pg_class rt ON c.confrelid = rt.oid
LEFT JOIN
pg_attribute ra ON ra.attrelid = rt.oid
AND ra.attnum = ANY(c.confkey)
WHERE
t.relname = '<table_name>'
AND nsp.nspname = '<schema_name>'
ORDER BY
c.conname, column_name;
上記 SQL 文をクエリエディタ経由で実行した例です。対象テーブル「m_country」の制約情報が表示されています。

この内、constraint_type 列が「FK」の行が FK 関連の情報を示しています。 同行における referenced_table_name が FK 参照先テーブル名を示しており、この情報を先述したステータス更新用の mutation を実行する際に使用しています。
そして、アプリケーション上から FK 関連情報を取得するための関数が「getTableFKList()」となります。
まとめ
やはり、第一回の最後で危惧していた通り、分量が若干アンバランスになってしまった感があります。。このため第三回として、排他制御関連のトピックとして少し毛色の違う内容を取り上げてみようと思います。
本記事の内容がどなたかの役に立てば幸いです。