 Snowflake
Snowflake Snowflakeのエージェント評価機能を触ってみた ~Snowflake CoWorkのテスト自動化へ~
Snowflakeのエージェント評価機能について説明しています。
 Snowflake
Snowflake  Google Cloud
Google Cloud  AWS
AWS  Snowflake
Snowflake  Google Cloud
Google Cloud  AWS
AWS  データ分析・活用基盤
データ分析・活用基盤 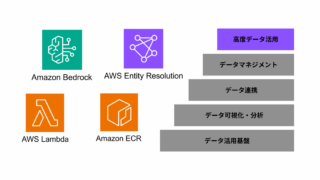 AWS
AWS 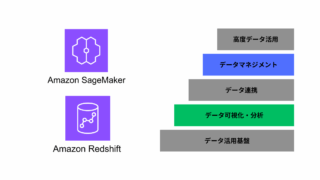 AWS
AWS 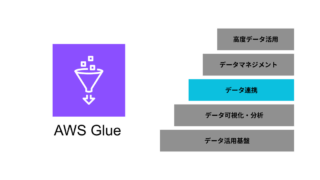 データ分析・活用基盤
データ分析・活用基盤