
SCSKの畑です。
前回のエントリで触れたアプリケーションにおいて、どのようにテーブルデータを保持していたかに関する補足的内容となります。小ネタです。
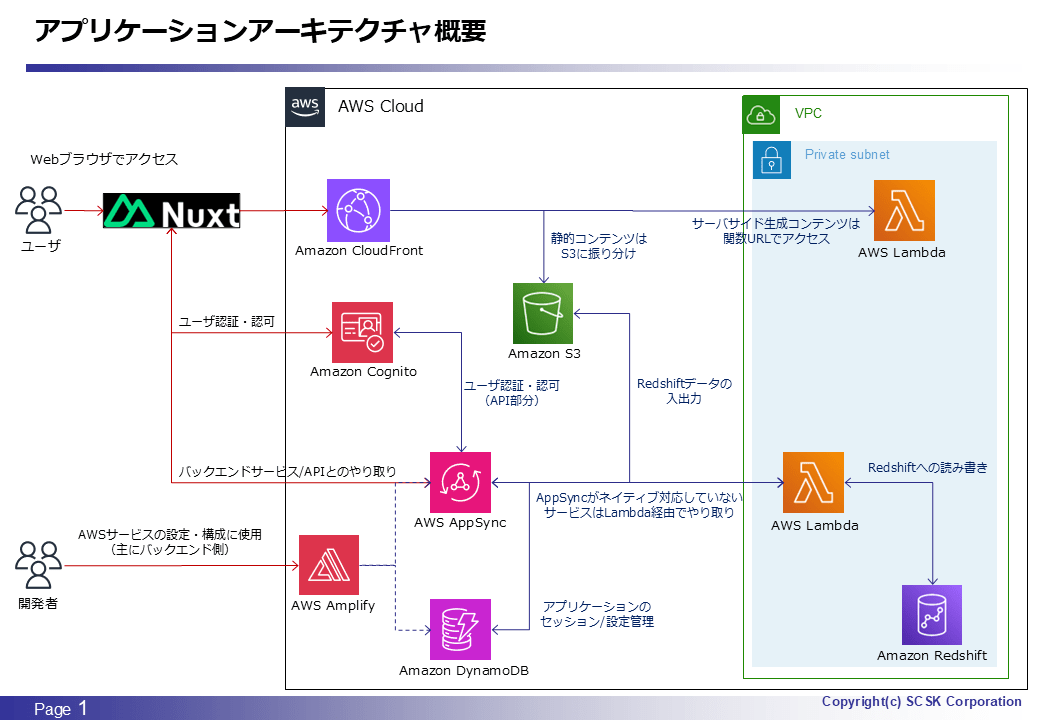
アーキテクチャ図
懲りずにいつものやつを。今回のメインは Amazon Redshift、Amazon DynamoDB、Amazon S3 あたりです。
テーブルデータメンテナンス機能要件のおさらい
最初に、改めてテーブルデータメンテナンスの要件を記載します。他、対象テーブルを所管する組織(= Cognito グループ)に属しているユーザのみデータ編集が可能となるような権限管理やデータバリデーションに関する要件もありましたが、本題にはあまり関係ないので割愛します。
- メンテナンス対象テーブルデータの更新機能(≒DML操作)
- テーブル定義の変更(≒DDL操作)は対象外
- テーブル定義の変更時は直接 Redshift に SQL を実行する想定
- テーブルのバージョン管理機能
- 過去バージョンのデータ参照や、バージョン間のデータ比較が可能(テーブル定義が同一の場合のみ)
- テーブルデータ/定義どちらの変更があった場合でも、新しいバージョンと見なして管理
- アプリケーション経由でテーブルデータを更新する際の簡易ワークフロー機能
- 別ユーザによる承認を以って、Redshift 側に編集したデータの更新が反映される
以上より、こちらも前回のエントリで記載した内容を含みますが、以下2点をアーキテクチャ設計で考慮する必要がありました。
- 1. より、テーブル定義の変更が行われてもシステム側で柔軟に対応できる必要がありました。また、テーブル定義の変更(≒DDL操作)についてはアプリケーションのスコープ外である以上、アプリケーション外での更新も取り込むことを考慮しておく必要がありました。
- 2. 及び 3. より、過去バージョンのデータや編集後の承認待ち一時データを保管しておく領域が必要になりました。また、1点目の内容より、アプリケーション外でのテーブル定義の変更に柔軟に対応できることが望ましかったです。
以上を踏まえて、どのようにこの領域を用意するかを検討していました。
第一候補:DynamoDB
当初は DynamoDB を使用する予定でした。
元々アプリケーションマスタとして DynamoDB を使用する予定だったため相乗りすればアーキテクチャとしてもシンプルですし、メンテナンス対象テーブルの編集ステータス管理なども担う都合上、合わせて実データも持てれば利便性もあるのではないかと考えました。また、実は DynamoDB って Redshift と COPY/UNLOAD 文によりテーブルと直接データの入出力ができることを知り、そういう意味でも親和性高いのではないかと。
下記 URL の通り、実は Redshift と COPY/UNLOAD 文で外部ファイル内のデータをやり取りをできるサービスは限定されており、DynamoDB はその一つです。一番ベーシックなのは S3 ですね。


ただ、DynamoDB 上でテーブル自体を保持するようにした場合、表定義の変更にどう対応するのかが課題となりました。実質的に Redshift との二重管理になってしまうため、Redshift 側での表定義変更時にどう対応するかが難しいと感じました。表定義変更自体はアプリケーション側のロジックで検知できるものの、そもそも KVS と RDBMS で根幹の仕組みも異なるため KVS 側で対応していない部分をどのように実装するかが悩ましく。例えば、DynamoDB におけるテーブルのパーティションキー/ソートキーの変更がある場合はテーブルの再作成が必要となりますが、特に UNLOAD の場合にそのようなケースに該当した場合の対応などです。
このため、対応の柔軟性を考えて DynamoDB のテーブルとしてデータを保持するのではなく、テーブル定義やデータ自体をテーブルの絡む(項目)内に持ってしまうような構成に変更しようとしたのですが、1項目の最大データサイズが 400KB であったため、データ自体を1項目に入れてしまうのは無理だと諦めました。当時はテーブルデータを圧縮する想定がなかったということもありますが、どちらにせよ足りなかったです。それ以前に設計としては無理矢理感があって良くなかったと思うので、結果的には断念することになって良かったと思っていますが・・
第二候補(決定):S3
ということで、DynamoDB 以外ということで丸い選択と考えると、ほぼ必然的に S3 を使用することになった感じです。S3 上に配置したファイル経由で COPY/UNLOAD 文により Redshift とデータ入出力が可能なこと、実質的にファイル単位で情報を保持することになる以上、DynamoDB の項目に記載したような問題が発生しない、の2点が主な理由です。
最も後者については、その分アプリケーション側での実装が必要になるとも言えるのですが、DynamoDB も KVS である以上 RDBMS との機能差異があるため、結果的にそこまでアプリケーションの実装をカバーできなかったのではないかと。
また、一時テーブルデータや古いバージョンのテーブルデータを世代管理・ハウスキーピングするにあたり、S3 のライフサイクル機能や既存の S3 ハウスキーピング用 Lambda 関数を使い回せるという点もありました。最も、DynamoDB は TTL 設定ができるため、ある程度は代用できるところもあったとは思いますが。
最後に、どのようなファイル構成で Redshift のテーブルを扱っているかを簡単に説明して終わりたいと思います。現在は、下記3種類のファイルをテーブル単位でそれぞれ扱っており、これらの情報を組み合わせてアプリケーション上でテーブルデータを表示しています。
- テーブル列定義ファイル
- 列名(論理名・物理名)やデータ型などの情報を扱っています。
- 論理名は別情報として定義されているコメントを結合して持ってくるようにしています。
- 列名(論理名・物理名)やデータ型などの情報を扱っています。
- テーブル制約定義ファイル
- 各制約(PK・UK・FKなど)の情報を扱っています。
- SQL 文を含む内容の詳細は5回目のエントリを参照ください。
- 各制約(PK・UK・FKなど)の情報を扱っています。
- テーブルデータファイル
- 7回目のエントリで記載した通り、Redshift と COPY/UNLOAD 文によりテーブルと直接データの入出力を行うため、同 SQL 文で直接扱える JSON Line 形式でファイルを保持するようにしています。
- AppSync/Lambda とアプリケーション間でデータをやり取りする際には、AppSync の最大ペイロードサイズを考慮してデータを圧縮するようにしています。
上記のようなファイル構成として扱うことで、Redshift 上のテーブルの定義やデータが変更された場合もアプリケーション側の実装含めて柔軟に対応できるようにしています。また、テーブルのバージョン管理をするにあたり、実質的には Redshift 上のテーブルデータ/定義と、アプリケーションが認識している最新のテーブルデータ/定義(=S3上のテーブルデータ/定義)間の変更有無を検出できる必要がありますが、この仕組みにすることでファイルの内容を精緻に比較することなく、ファイルのハッシュ値のみで比較できるようになったというのも利点の一つでした。もちろん、そのように比較できるように SQL 文を書く必要はありましたが、実装面では幾分楽ができました。
まとめ
今回は正に前回エントリの補足というかそれに関連した小ネタでしたが、まだこのような内容はいくつかあるため、今後も既存のエントリの内容を補完する形で投稿していければと思います。
本記事がどなたかの役に立てば幸いです。