

こんにちは SCSK株式会社の坂木です。
ところで、社内資料の管理、効率的ですか?
様々な形式の文書が散在し、必要な情報を探すのに時間を取られていませんか?
ファイルサーバーの奥底に埋もれどこにあるか分からない、バージョン管理が混乱する、などといった課題を抱えていませんか?
これらの非効率は、業務の生産性低下に直結します。 今こそ、社内資料の一元管理体制を見直しましょう!
ということで、AWS Bedrockのナレッジベースを用いた資料の一括管理およびその検索方法をご紹介します!
Amazon Bedrockについて
Amazon Bedrockは、AWSが提供するフルマネージドサービスで、簡単に生成AIアプリケーションを構築できます。基盤モデルと呼ばれる大規模言語モデルをAPI経由で利用可能で、テキスト生成やチャットボット、要約、翻訳など、多様なユースケースに対応しています。
特に便利なのが、ナレッジベース機能です。ナレッジベースとは、社内文書やFAQなど、組織固有の情報を集めたデータベースのことです。Bedrock と接続すれば、AI がナレッジベースの内容を学習し、より精度の高い回答や情報を生成できます。
事前準備
今回は、「データ1.txt」「データ2.xlsx」「データ3.docx」の3つのファイルをもとにデータベースを作成します。
各ファイルには料理のレシピが記載されています。
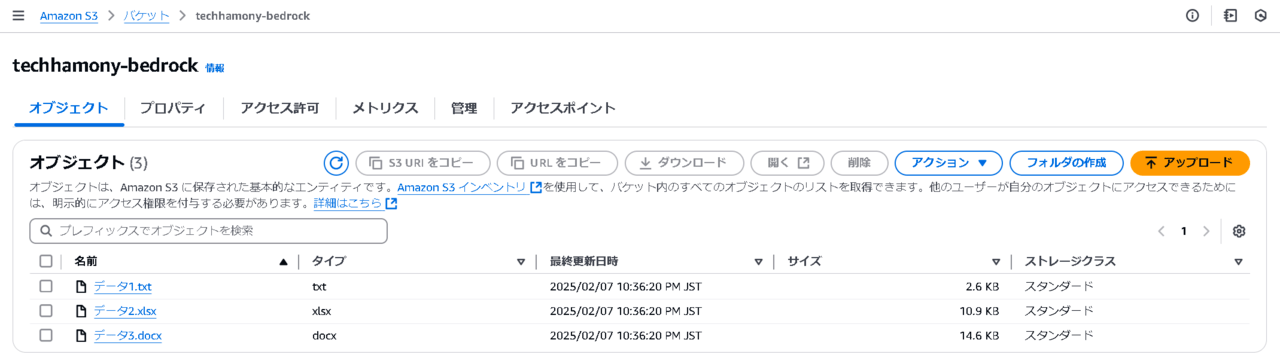
S3バケットを作成し、対象のデータをアップロードします。
このとき、ナレッジベースにサポートされているファイルの拡張子は「.txt」「.md」「.html」「.doc/.docx」「.csv」「.xls/.xlsx」「.pdf」となります。これら以外の拡張にて管理しているファイルは、一度拡張子を変換してからS3へアップロードする必要があります。

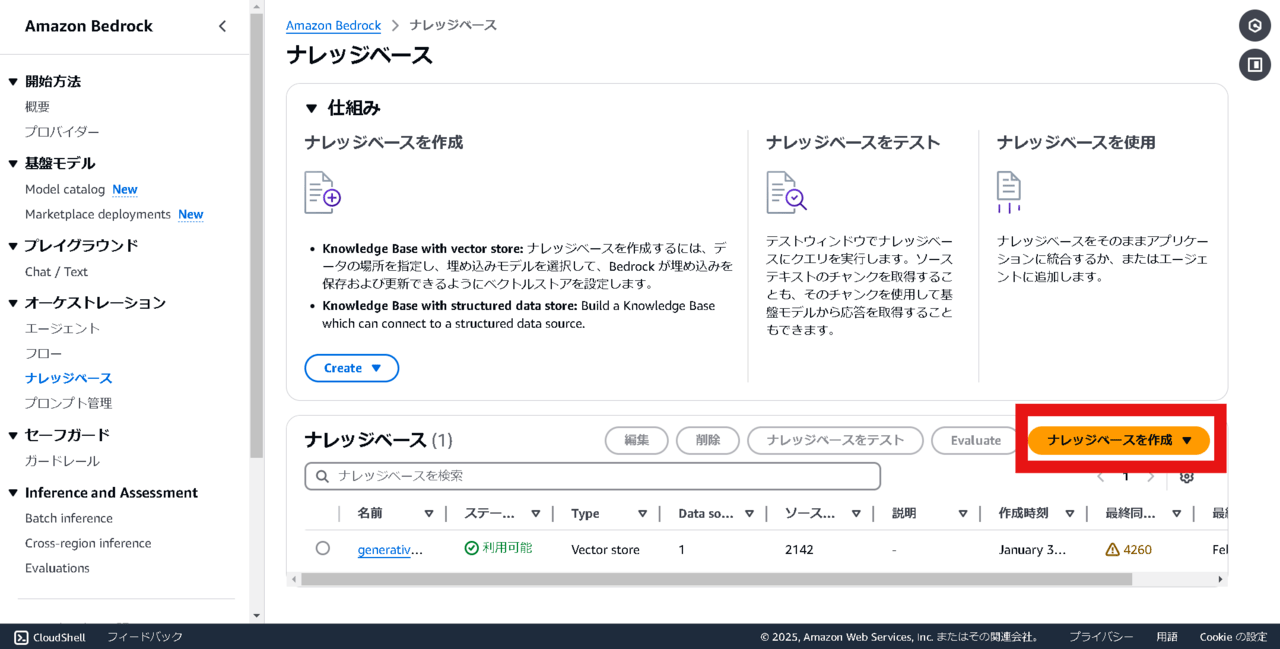
ナレッジベースの作成
Bedrock/ナレッジベースから、画像の画面へ遷移し「ナレッジベースを作成」を選択します。
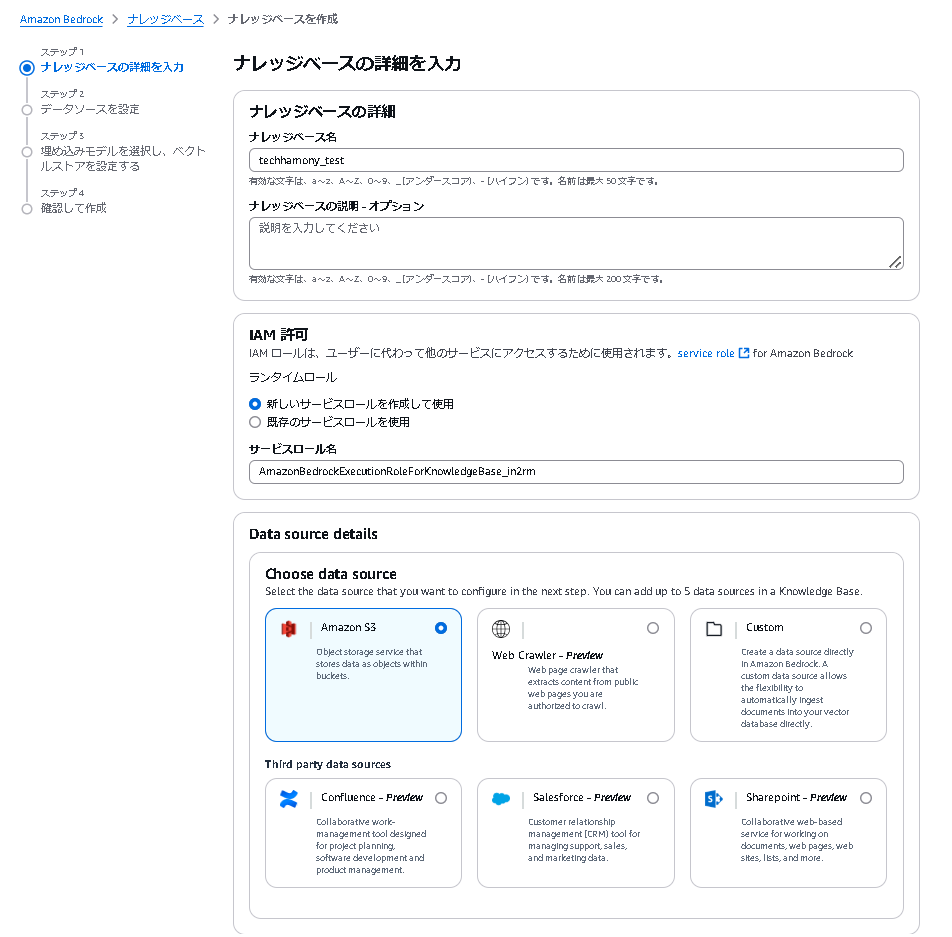
今回はデータソースをS3へ保存しているため、Choose data sourceは「Amazon S3」を選択します。
その他の選択肢はデフォルトで、「次へ」を押します。
- S3のURL
事前準備にて作成したS3バケットを選択します。 - Parsing strategy
今回はデータソースがテキストベース資料のみのため、テキストのみを解析する「default parser」を選択します。データソースに画像を含めている場合はFoundation modelsを選択することで、画像の解析が可能となります。

その他の選択肢はデフォルトで、「次へ」を押します。
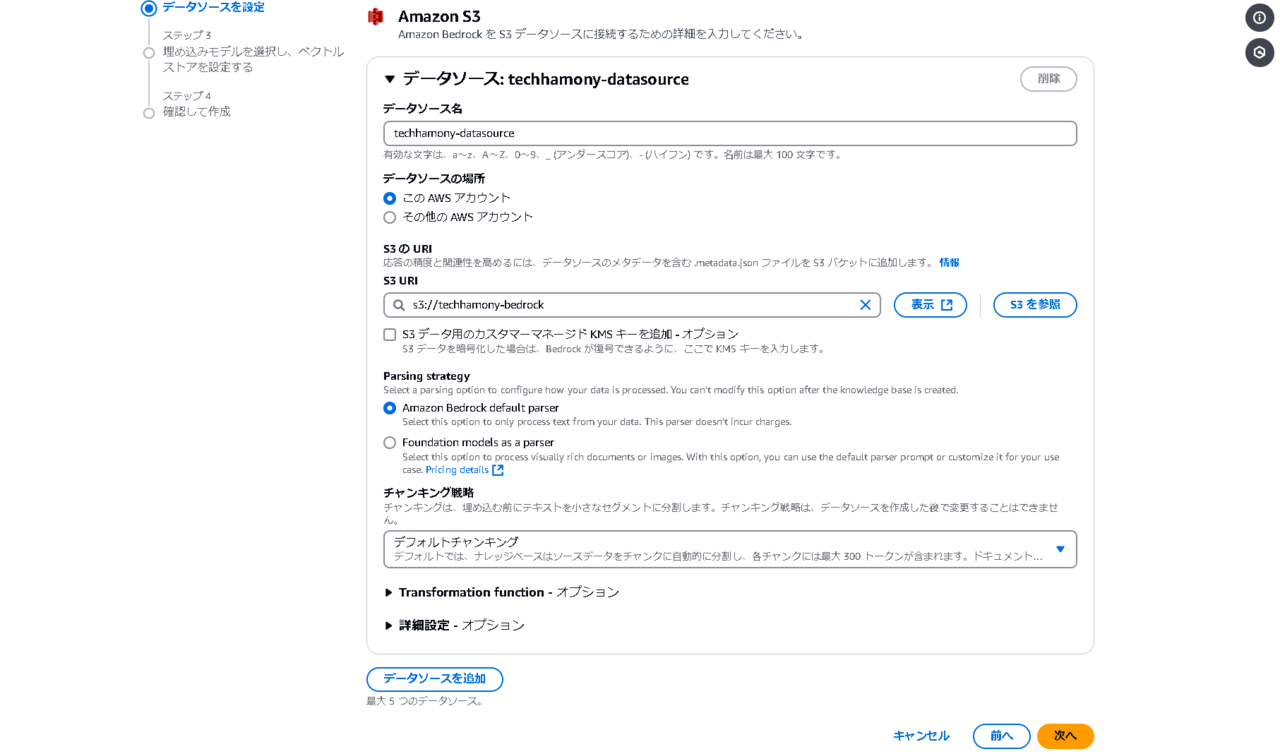
今回は埋め込みモデルの中で最も料金の安い「Titan Embeddings G1」を選択します。その他の選択肢はデフォルトで、「次へ」を押します。

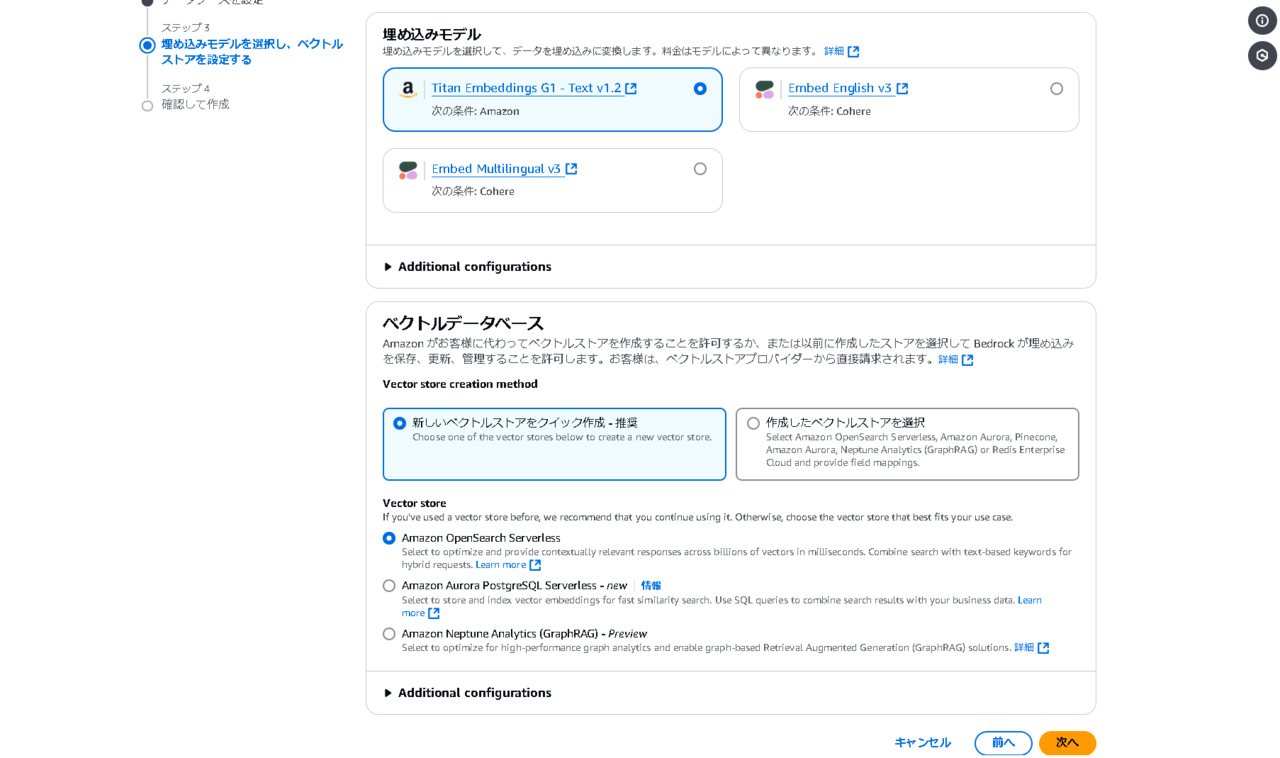
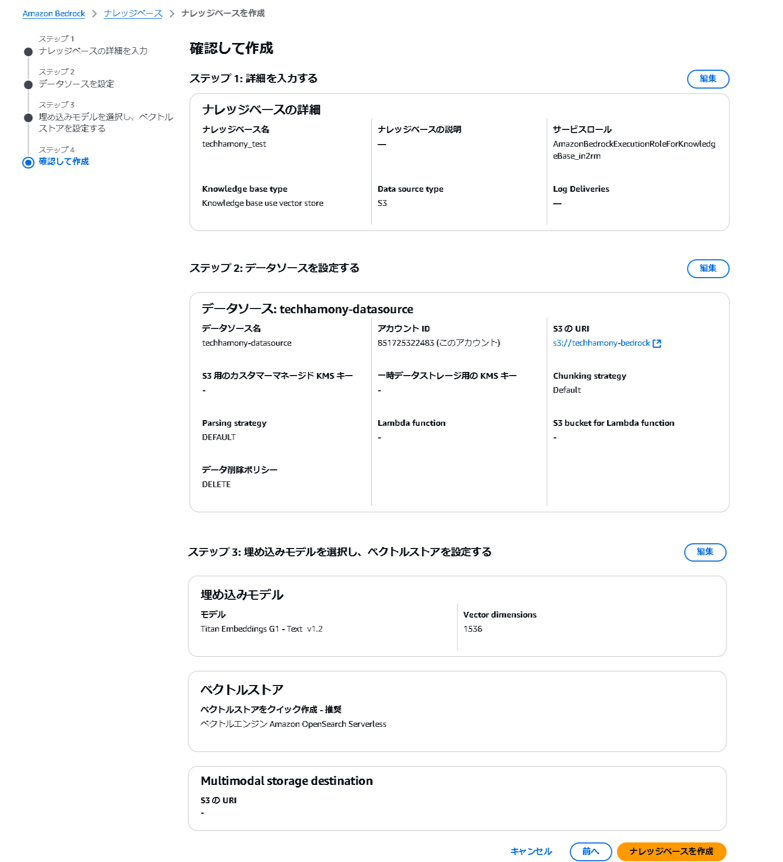
設定を確認してナレッジベースを作成します。以上で、ナレッジベースの作成は完了です。
検索
続いて、作成したナレッジベースを用いてデータソースの内容を検索していきます。
作成したナレッジベースの画面から、生成AIモデルを選択します。筆者はClaude AI推しなので今回は「Claude 3.5 Sonnet 」を選択しました。
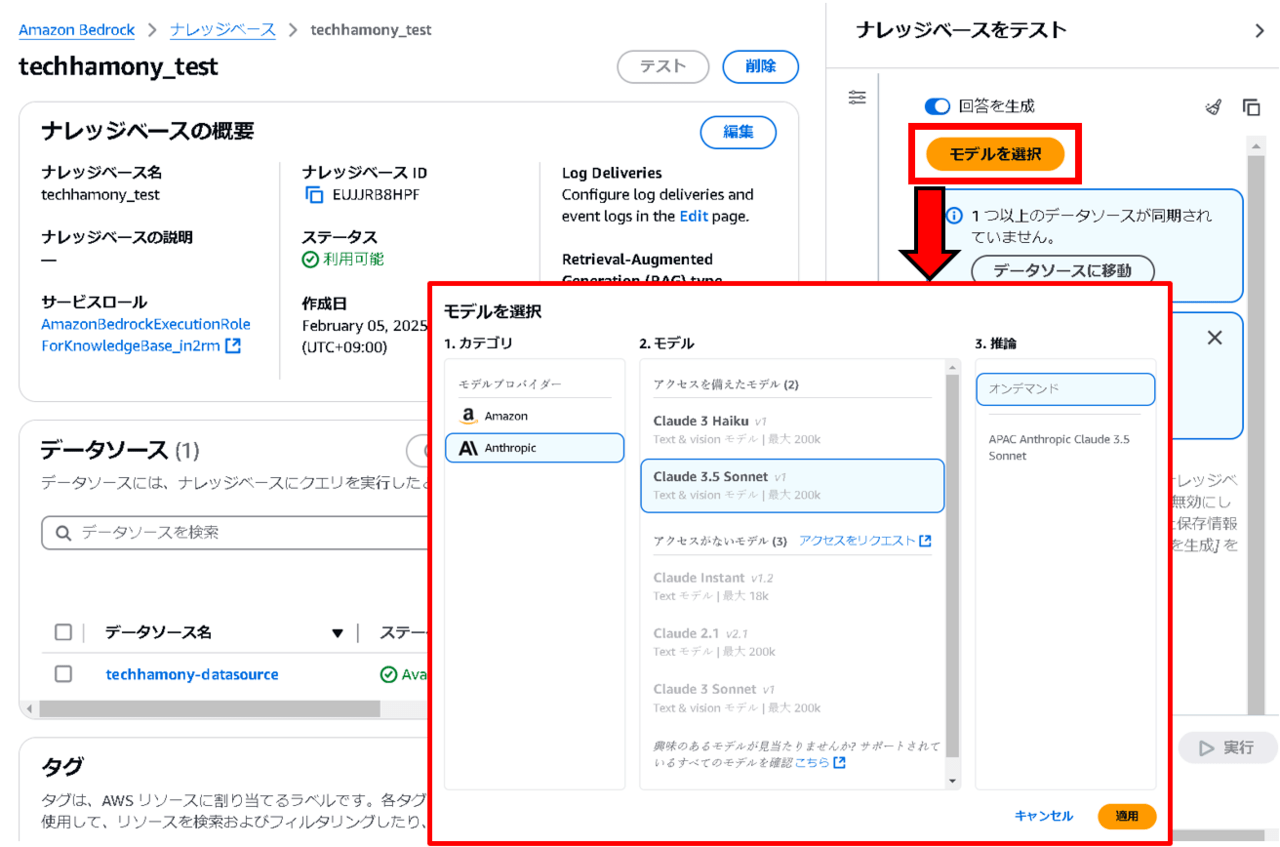
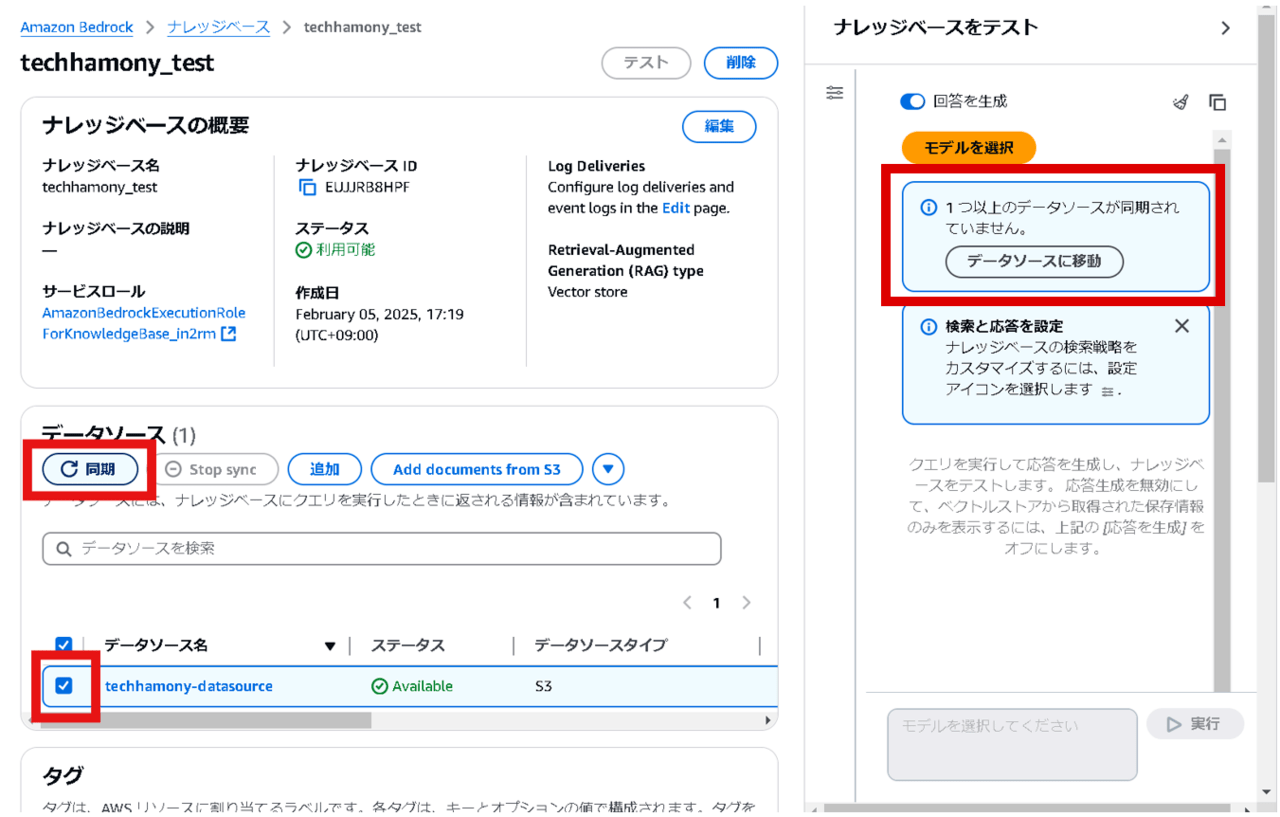
ナレッジベースを作成後、デフォルトの状態ではデータソースが同期されていません。
そのため、データソースの項目から対象のデータソース(今回の場合だと事前準備で作成したs3)を選択し、同期ボタンを押します。また、S3に追加の資料をアップロードした場合は、追加のたびに同期ボタンを押して最新のS3の状況を反映させる必要があります。
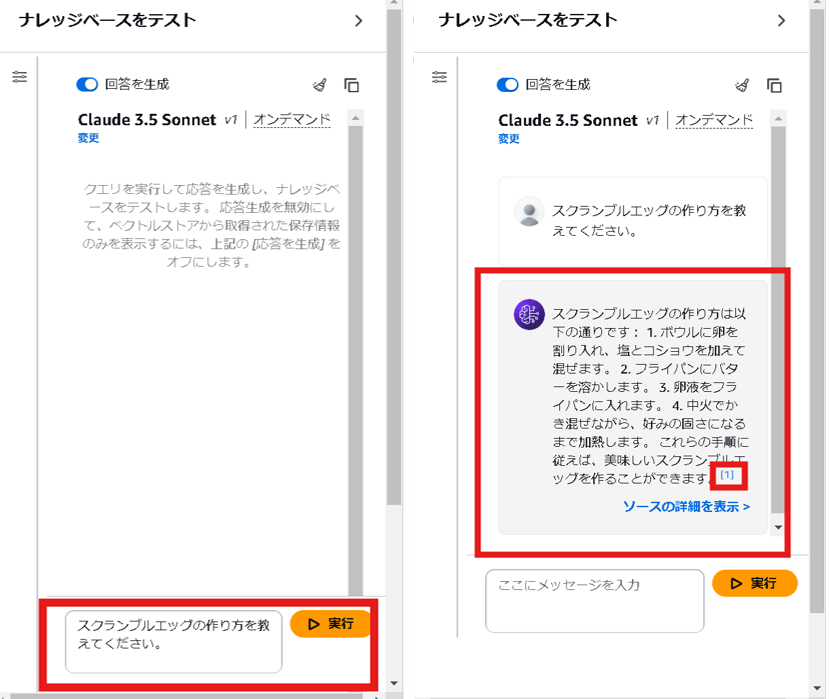
では、いよいよ検索していきます。「データ1.txt」に記載のあるスクランブルエッグの作り方について聞いてみようと思います。
データ1.txtには「ボウルに卵を割り入れ、塩とコショウを加えて混ぜる。フライパンにバターを溶かし、卵液を入れる。中火でかき混ぜながら、好みの固さになるまで加熱する。」という手順が記載されていたため、同様の回答が出力されれば成功です。
聞いてみた結果、言葉は多少違いますが概ね同じ内容の出力が得られました。また、[1]をクリックすると回答に際してどのファイルを参照したのか分かります。そのため、質問に対して回答となる社内資料をすぐに見つけられ、ファイルサーバから対象の資料を探す手間が省けます。
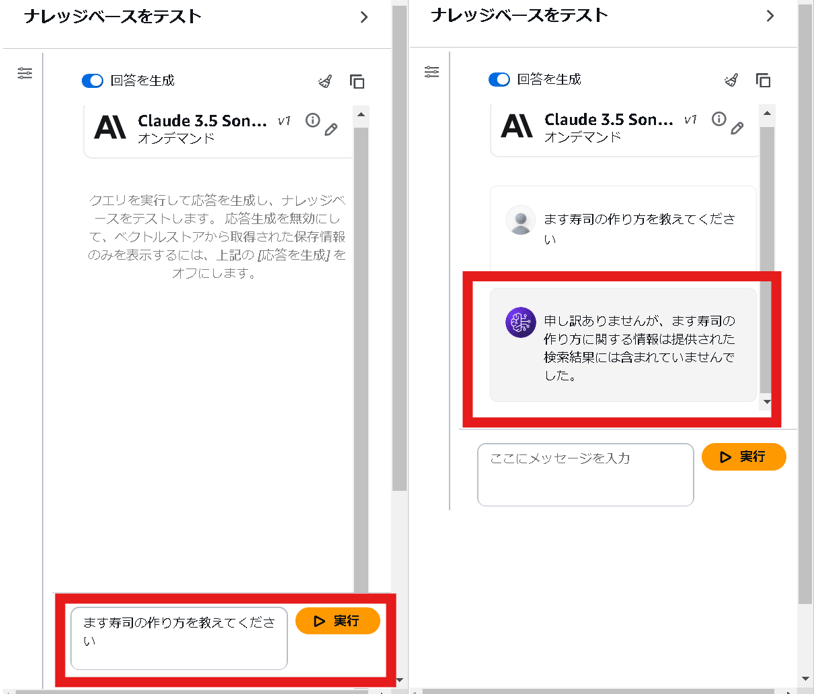
次に、データソースにない料理レシピである「ます寿司」の作り方について聞いてみようと思います。
聞いてみた結果、ます寿司の作り方はデータソースに無いと返されました。データソースにナレッジが無い場合は、web上の精度が曖昧な回答をするのではなく、データソースに無いと回答をもらえるようです。そのため、提供される情報は登録済みのデータに基づいており、 捏造や誤った情報を返すリスクが抑えられます。
まとめ
本記事ではAmazon Bedrockのナレッジベースを用いた社内資料管理方法について紹介しました。
ナレッジベースを用いることで資料を探す手間を省け、より短時間で確認したい情報へたどり着くことができます。すなわち、生産性の向上に寄与しているのではないでしょうか。
ちなみに、ナレッジベースはOpenSearch Serverlessの料金や検索ごとに料金が発生するため、生産性と一緒にコストも上がったります。要注意です。
最後までお読みいただきありがとうございました!
▼ 合わせて読みたい
AWSのスキルアップに役立つ、こちらの記事もぜひご覧ください。


