 AWS
AWS Claude Sonnet 5 公開 / Fable 5 規制解除 / Desktop on Bedrock で Chat がベータ版ほか、2026年6月まとめ
6月に発表されたAWS・Anthropicおよびその周辺の主要ニュースを「誰が知るべきか」「何が変わるのか」の観点で、Kiroに整理してもらいました。
 AWS
AWS  AWS
AWS  AWS AWS AWS AI・ML
AWS AWS AWS AI・ML  AWS AWS
AWS AWS 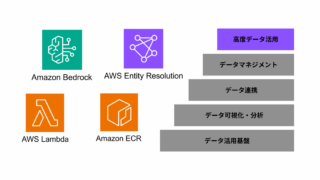 AWS
AWS 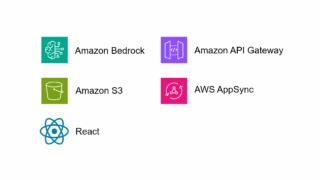 AWS
AWS