
こんにちは。SCSKの橋本です。
突然ですが、DynamoDBのデータを可視化したいことってありますよね。 AWSで可視化といえばQuickSightですが、QuickSightはデータソースとしてDynamoDBを指定することができません。
これを実現するためにはひと手間必要になるのですが、その中で比較的簡単そうな方法を試してみました。今回はその手順を紹介したいと思います。
やりたいこと
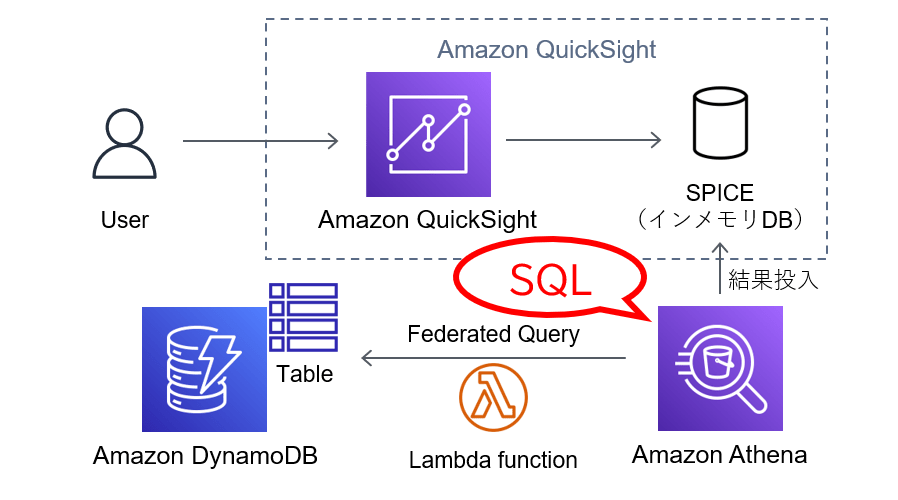
この記事ではDynamoDBのデータ可視化のため、AthenaのFederated Query機能を使います。
Federated Queryは2019年に登場し、2020年12月に東京リージョンでも使えるようになりました。この機能がにより、AthenaではDynamoDBを含む複数のデータソースに対してSQLアクセスが可能となっています。
- Amazon Web Services ブログ. 「Amazon Athenaの新しいフェデレーテッド・クエリによる複数データソースの検索」,(2019-11-28)
- Developers IO. 「[Update] Amazon Athena engine version 2がリリース、Federated queriesやGeospatial functions等の新機能、パフォーマンスが改善されました」, (2020-11-15)
そして、AthenaはQuickSightのデータソースとして使用できます。つまり、Athenaを使うことで、QuickSightからDynamoDBのデータを利用できるということですね。
実現したいもの
【実現する構成】
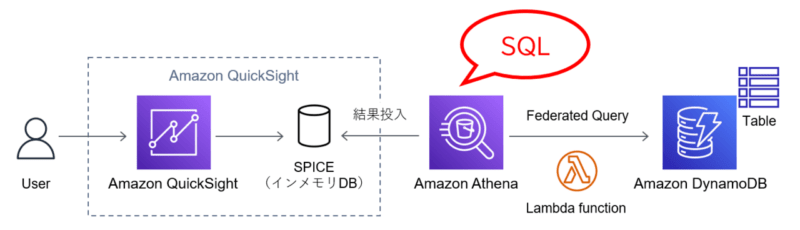
【可視化の例】
前提
以下の環境は、あらかじめ準備済みとして手順を説明します。
なお、AWSは東京リージョンを使用します。
- S3バケット
この記事では「shsamplebucket」というバケットを使用します。
構成図には記載しませんでしたが、裏でAthenaが使用します。 - QuickSight
サインインを済ませた状態とします。
【参考】Amazon QuickSight ユーザーガイド. 「Amazon QuickSight へのサインイン」. - DynamoDB(可視化対象のテーブル作成とデータロード済み)
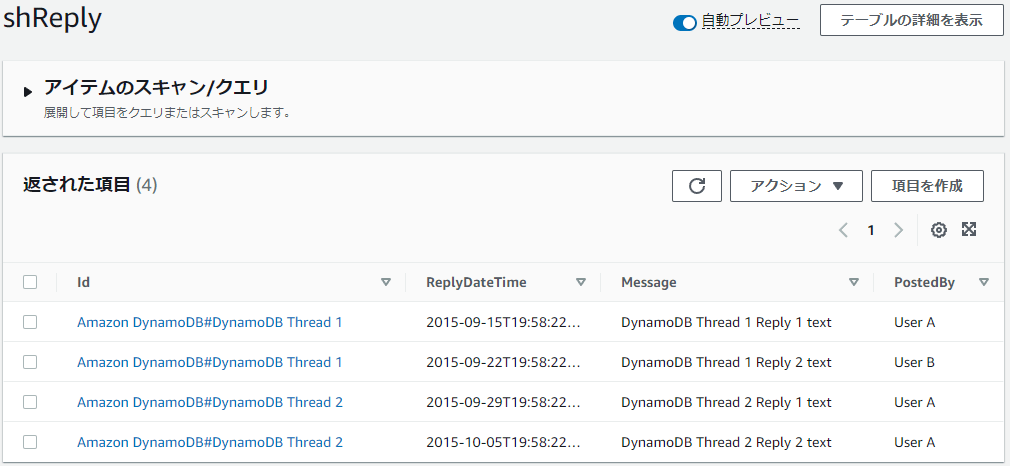
公式ドキュメントのDynamoDB用データを使用します。
以下のリンクの「ステップ2」までで作成する「Reply」と同じ構成の「shReply」テーブルを使用します。
【参考】Amazon DynamoDB デベロッパーガイド「DynamoDB でのコード例用のテーブルの作成とデータのロード」.
【「shReplay」テーブルのデータ】
手順
ここからは実際に実施した手順を紹介します。
AWSのコンソール画面へのリンクは、AWSにログインした状態でご利用下さい。
Athena データソースの作成
AthenaからDynamoDBに接続できるようにします。手順の途中でLambda関数の画面が出てきますが、コーディングは一切不要です。
- Amazon Athena のデータソース画面を開く。
- 「データソースの作成」ボタンを押す。

- ステップ1「データソースを選択」画面で「DynamoDB」を選択し、「次へ」ボタンを押す。
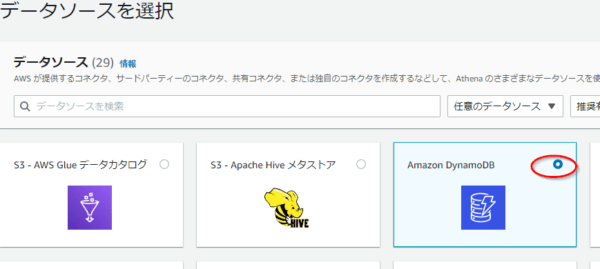
- ステップ2「データソースの詳細を入力」画面で以下を実施する。
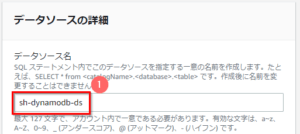
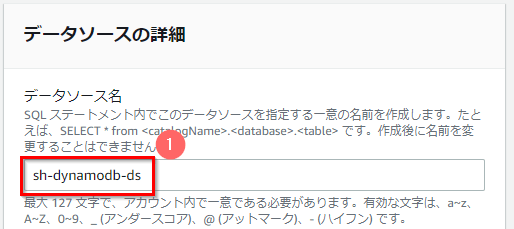
- データソース名として任意の名前(ここでは「sh-dynamodb-ds」)を入力 する。
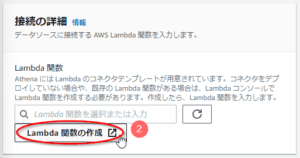
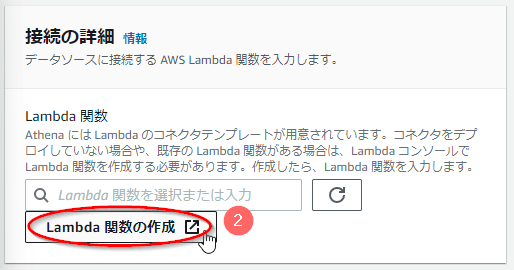
- 「Lambda関数の作成」ボタンを押す。
- データソース名として任意の名前(ここでは「sh-dynamodb-ds」)を入力 する。
- ブラウザの別タブにて開かれる、Lambdaアプリケーション「AthenaDynamoDBConnector」の「設定とデプロイ」画面で、以下を実施する。
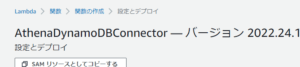
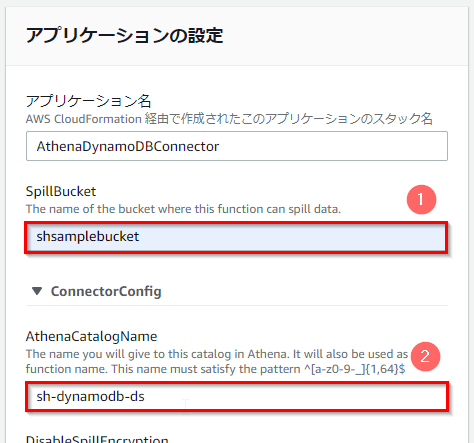
- spillBucketとして、あらかじめ用意したS3バケットの名前(ここでは「shsamplebucket」)を入力する。
- AthenaCatalogNameとして、任意の名前(ここでは「sh-dynamodb-ds」)を入力する。
※前の手順で作成したAthenaのデータソース名とは異なる名前でも可。
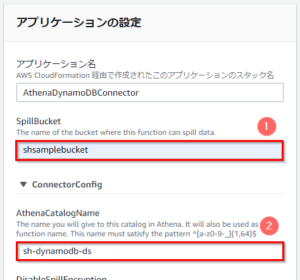
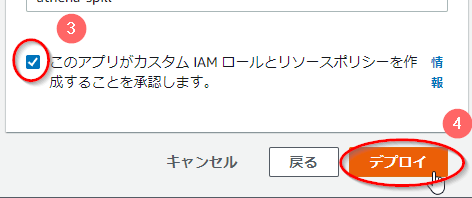
- 「このアプリがカスタムIAMロールとリソースポリシーを作成することを承認します」にチェックを入れる。
- 「デプロイ」ボタンを押す。
- 以下の画面が表示されたら、タブを切り替えてステップ2「データソースの詳細を入力」画面に戻る。
- spillBucketとして、あらかじめ用意したS3バケットの名前(ここでは「shsamplebucket」)を入力する。
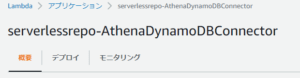
- ステップ2「データソースの詳細を入力」画面で、以下を実施する。
- Lamda関数として前の手順でAthenaCatalogNameに指定した名前(ここでは「sh-dynamodb-ds」)を選択する。
- 「次へ」ボタンを押す。
- ステップ3「確認と作成」にて設定内容確認し、「データソースの作成」を押す。



以上でAthenaデータソースの作成完了です。
Athena ワークグループの作成
Athenaには「primary」というワークグループが存在しますが、この記事では別途専用のワークグループ「sh-athena-wg」を作成することにします。
作成したワークグループは、この後のQuickSightデータセット作成手順で使用します。
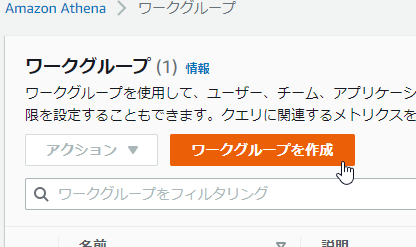
- Athenaのワークグループ画面を開く。
- 「ワークグループを作成」を押す。
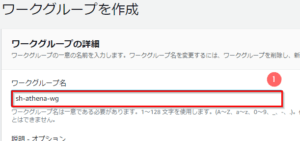
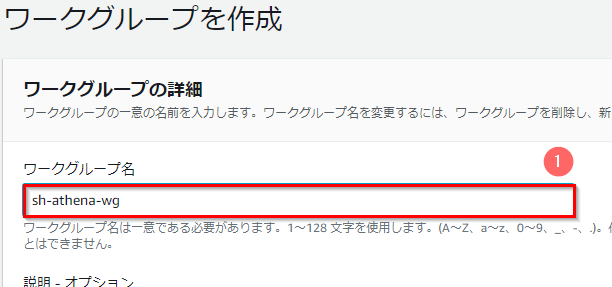
- 「ワークグループを作成」画面で、以下を実施する。
- 「ワークグループ名」に任意の名前(ここでは「sh-athena-wg」)を入力する。
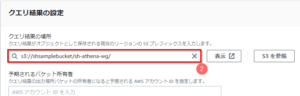
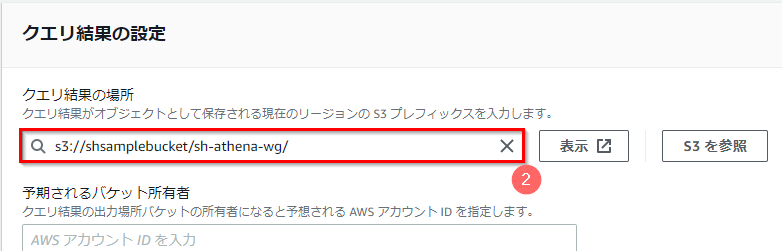
- 「クエリ結果の場所」として、あらかじめ用意したS3バケットのフォルダ名(ここでは「s3://shsamplebucket/sh-athena-wg/」)を入力する。
※フォルダ作成後であれば「S3を参照」ボタンから選択も可。S3内でのフォルダ作成手順は省略。
- 「ワークグループを作成」ボタンを押す。

- 「ワークグループ名」に任意の名前(ここでは「sh-athena-wg」)を入力する。
以上で新しいワークグループ「sh-athena-wg」が追加されました。
QuickSightのデータセット作成
QucickSightからAthenaへ接続するために、データセットの作成を行います。
- QuickSightのデータセット画面を開く。
- 「新しいデータセット」ボタンを押す。
- 「データセットを作成」画面で以下を実施する。
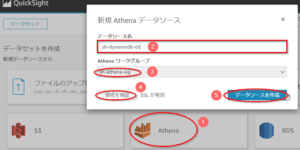
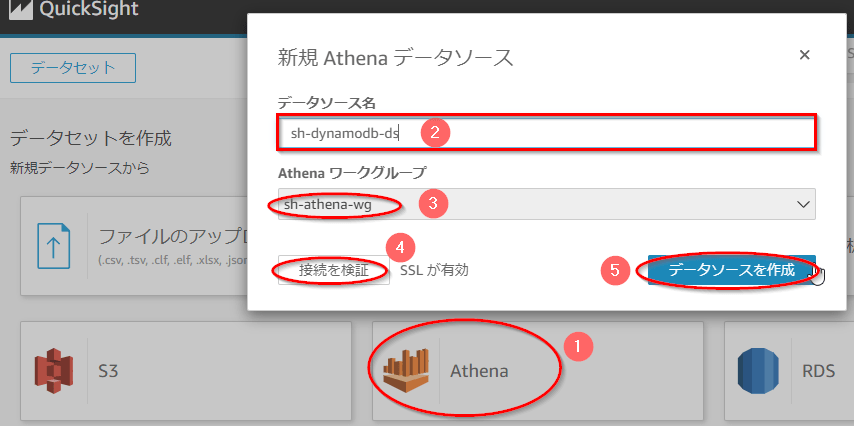
- 「新規データソースから」の中より「Athena」を選択する。
- 表示されたダイアログの「データソース名」に任意の名前(ここでは「sh-dynamodb-ds」)を入力する。
※前の手順で作成したAthenaのデータソース名とは異なる名前でも可。
- 「Athenaワークグループ」として、手順で作成したAthenaのワークグループ名(ここでは「sh-athena-wg」)を入力する。
- 「接続を検証」ボタンを押し、ボタン名が「検証済み」となることを確認する。
- 「データソースを作成」ボタンを押す。
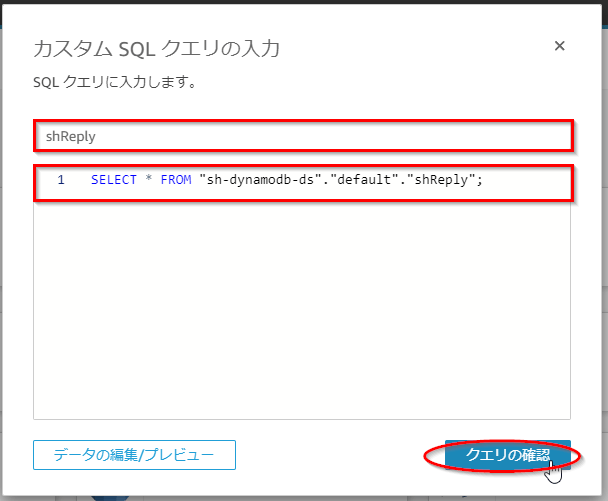
- 「テーブルの選択」画面で「カスタムSQLを使用」ボタンを押す。

- 「カスタムSQLクエリの入力」画面で、任意のクエリ名(ここでは「shReply」)と以下のSQL文を入力し、「クエリの確認」ボタンを押す。
SELECT * FROM "sh-dynamodb-ds"."default"."shReply"
DynamoDBのテーブルは、SQLのFROM句に「”<Athenaのデータソース名>”.”default”.”<DynamoDBのテーブル名>”」という形式で指定します。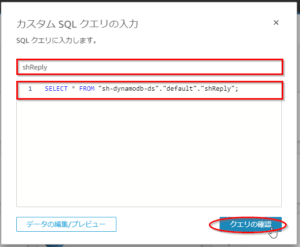
- 「データセット作成の完了」画面にて「Visualize」を押す。
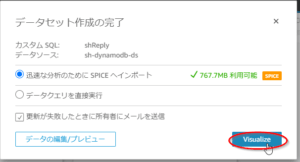
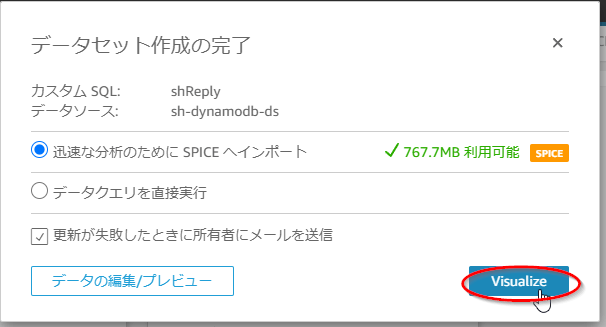
分析画面が表示されたら完了です。
QuickSightで分析
作成したデータセットを使用してグラフを作成します。
例えば、「データセット」の「フィールドリスト」より「postedby」をドラッグ&ドロップします。
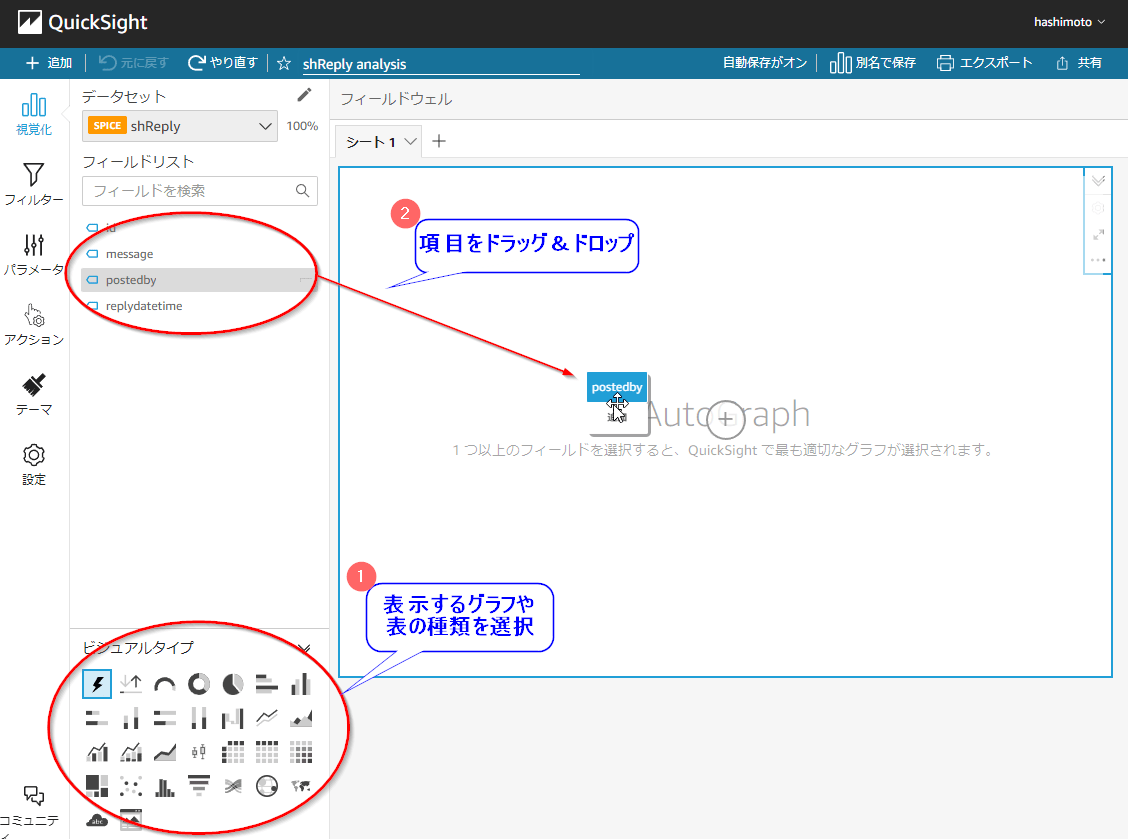
以上で可視化が完了しました!
【補足】データセットを追加する場合
ここまでの手順で可視化を完了後、別のSQLを使用してQuickSightのデータセットを作成する場合は以下を実施します。
- 「Athena データソースの作成」…… 実施不要です。作成済みのデータソースを使用します。
- 「Athena ワークグループの作成」……実施不要です。作成済みのワークグループを使用します。
- 「QuickSightのデータセット作成」…… 手順3のみ以下に読み替えます。その後SQLを変更して元の手順を実施します。
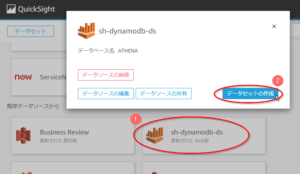
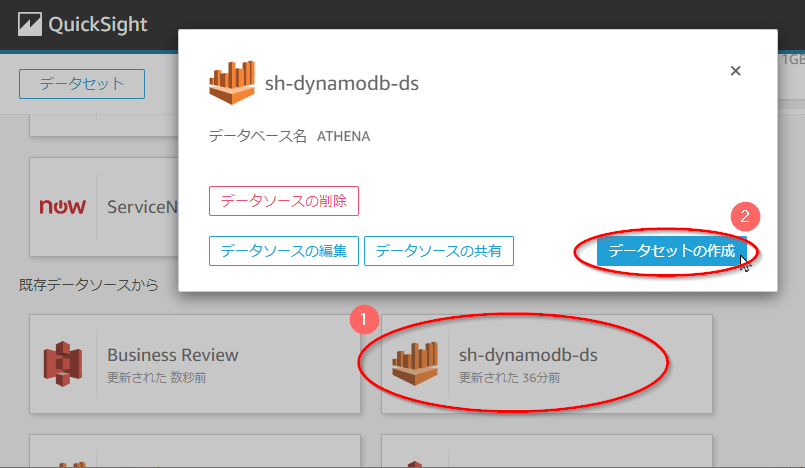
3. 「データセットを作成」画面で以下を実施する。
- 「既存データソースから」より初回の手順で作成したQuickSightのデータソース名(ここでは「sh-dynamodb-ds」)を選択する。
- 表示されたダイアログで「データソースを作成」ボタンを押す。その後手順4に進む。
おわりに
今回にQuickSightのデータセット作成時に、Athenaを経由してDynamoDBへSQLアクセスすることができました。
本格的に使用する場合はコストや命名規則なども意識する必要がありそうですが、まずはこの記事が皆様のお役に立てれば幸いです。