

こんにちは。SCSKの島村です。
Google Cloudの最新生成系AIについて前回のブログでいくつかご紹介させていただきました。
まだ読まれていない方は、下記リンクよりご一読いただけますと幸いです。

本記事では、Google Cloudの生成系AIについての第二弾といたしまして、更に掘り下げてご紹介できればと思っております。
また、Google CloudとOpenAI社から提供されている生成系AIの比較についてもまとめてみました。
*本執筆は、2023年7月04時点で公開されている情報をもとに作成しております。
最新情報については、Google Cloud公式ドキュメント
「Google Cloud ブログ| ニュース、機能、およびお知らせ | Google Cloud 公式ブログ」をご確認ください。
各社(Google Cloud / OpenAI)生成系AIの概要
Bardチャットボットを含む一連のGoogle AI製品に組み込まれているLLM
PaLM2はPaLMにおける推論、言語、コーディング能力を拡張した大規模な一般LLM

GPT-4は大規模なマルチモーダルモデル(画像とテキストの入力を受け付け、テキスト出力を出す)
GPTにて実現できること(以下、ドキュメント抜粋「GPT – OpenAI API」)
Using GPTs, you can build applications to:
- Draft documents
- Write computer code
- Answer questions about a knowledge base
- Analyze texts
- Create conversational agents
- Give software a natural language interface
- Tutor in a range of subjects
- Translate languages
- Simulate characters for games
料金体系
Generative AI support on Vertex AI
Vertex AIにおけるAPI(PaLM Text Bison等を含む)の料金体系ですが、
プロンプトにおける入力1,000文字ごと、また、レスポンスにおける出力1,000文字ごとに課金されます。
*文字はUTF-8コードポイントでカウントされ、空白はカウントから除外されます。
詳細は以下となります。
| Model | Type | 1000文字当たりの価格 |
| PaLM Text Bison | Input | $0.0010 |
| Output | $0.0010 | |
| PaLM Chat Bison (Preview) | Input | $0.0005 |
| Output | $0.0005 | |
| Embeddings Gecko | Input | $0.0001 |
| Output | No charge | |
| Code Generation | Input | $0.0005 |
| Output | $0.0005 | |
| Code Chat | Input | $0.0005 |
| Output | $0.0005 | |
| Code Completion | Input | $0.0005 |
| Output | $0.0005 |
コストシミュレーション:例)PaLM Text Bisonによる利用料金
Input:100文字
Output:200文字 の応答を 100回繰り返した場合。
■ Input: $0.010(100 × 100 = 10000文字)
■ Output: $0.020(200 × 100 = 20000文字)
Total:$0.030(4.32円 1ドル=144円)
OpenAI API

OpenAIでの生成モデルAPI利用にでは、複数のモデルがあり、それぞれ機能と価格帯が異なります。
1,000トークンあたりの価格として掲示されております。
| GPT-Model | Type | 1K(1000)トークン当たりの価格 |
|---|---|---|
| GPT-4 8K context | Input | $0.03 / 1K tokens |
| Output | $0.06 / 1K tokens | |
| GPT-4 32K context | Input | $0.06 / 1K tokens |
| Output | $0.12 / 1K tokens | |
| gpt-3.5-turbo 4K context | Input | $0.0015 / 1K tokens |
| Output | $0.002 / 1K tokens | |
| gpt-3.5-turbo 16K context | Input | $0.003 / 1K tokens |
| Output | $0.004 / 1K tokens |
| Fine-tuning models | Training | 1K(1000)トークン当たりの価格 |
|---|---|---|
| Ada | $0.0004 / 1K tokens | $0.0016 / 1K tokens |
| Babbage | $0.0006 / 1K tokens | $0.0024 / 1K tokens |
| Curie | $0.0030 / 1K tokens | $0.0120 / 1K tokens |
| Davinci | $0.0300 / 1K tokens | $0.1200 / 1K tokens |
Google Cloud(PaLM Text Bison-Input) :$0.000001 = ($0.0010/1000)
OpenAI(gpt-3.5-turbo 4K context-Input): $0.000002 = ($0.0015/750)
Vertex AI PaLM APIの利用開始方法
Google Cloud では、最新の生成モデルを「Vertex AI PaLM API」という名称で利用が可能です。(7月05時点一部機能preview)
今回は 実際にAPIを利用するまでの手順、並びに機能・出力結果について調査しました。
PaLM API利用方法
PaLM APIについては、「Vertex AI API」、「Vertex AI SDK for Python」 から利用できるだけでなくGoogle Cloud コンソールの 「Generative AI Studio」からも利用が可能です。
「Generative AI Studio」では、Google の生成AIモデルを迅速にプロトタイピングおよびテストするために用意されいています。Generative AI Studioでは以下のことができます。
・プロンプトサンプルを使ってモデルをテストする
・独自のプロンプトをデザインして保存する
・基礎モデルのチューニング
・音声とテキストの変換
APIでの利用については、サンプルプログラムもご用意されております。詳細気になる方は下記公式ドキュメントよりご確認ください。
サンプルプロンプト「Support rep chat summarization」利用してみた。
Google Cloudコンソールより「Vertex AI-Generative AI Studio-言語」を押下することです。下記画面に遷移可能です。
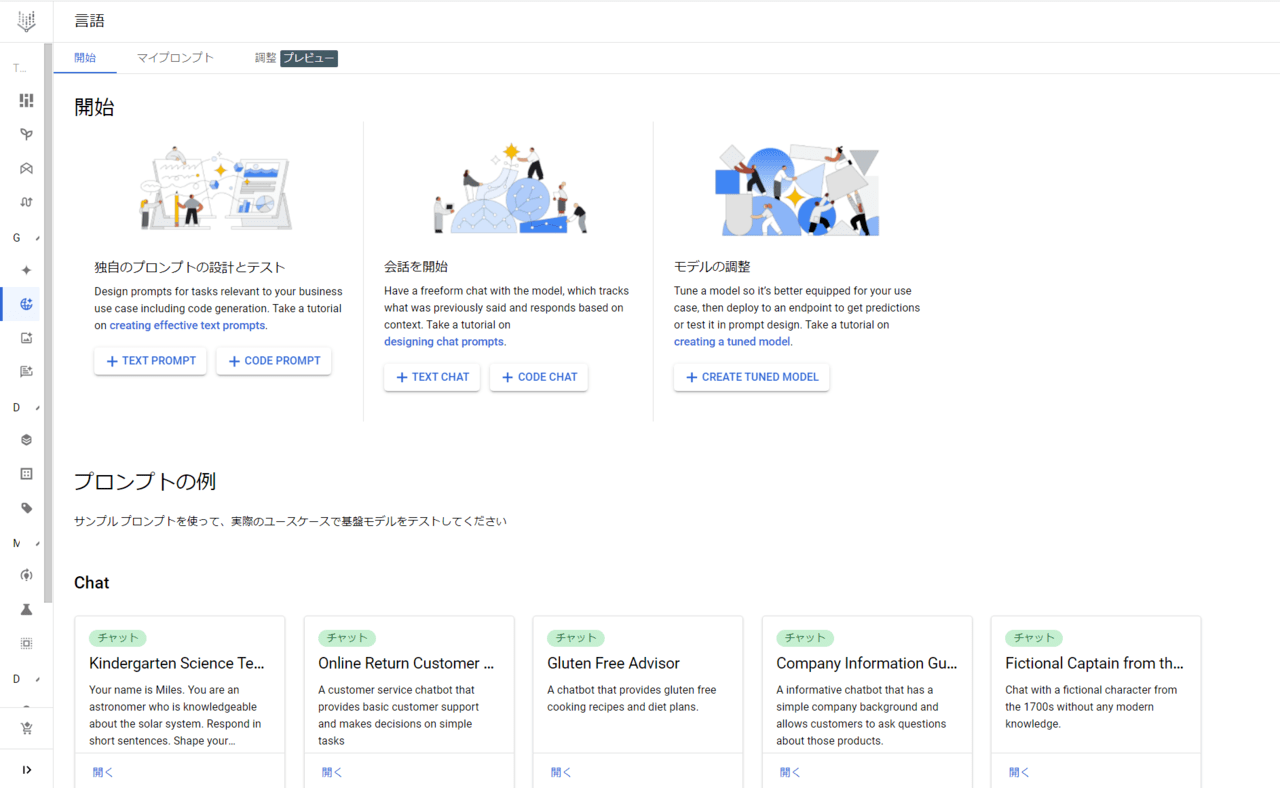
「プロンプトの例」からサンプルプロンプトをテスト可能です。
今回は、「Summarization」から「Support rep chat summarization(サポート担当者のチャット要約)」をクリックしてみます。
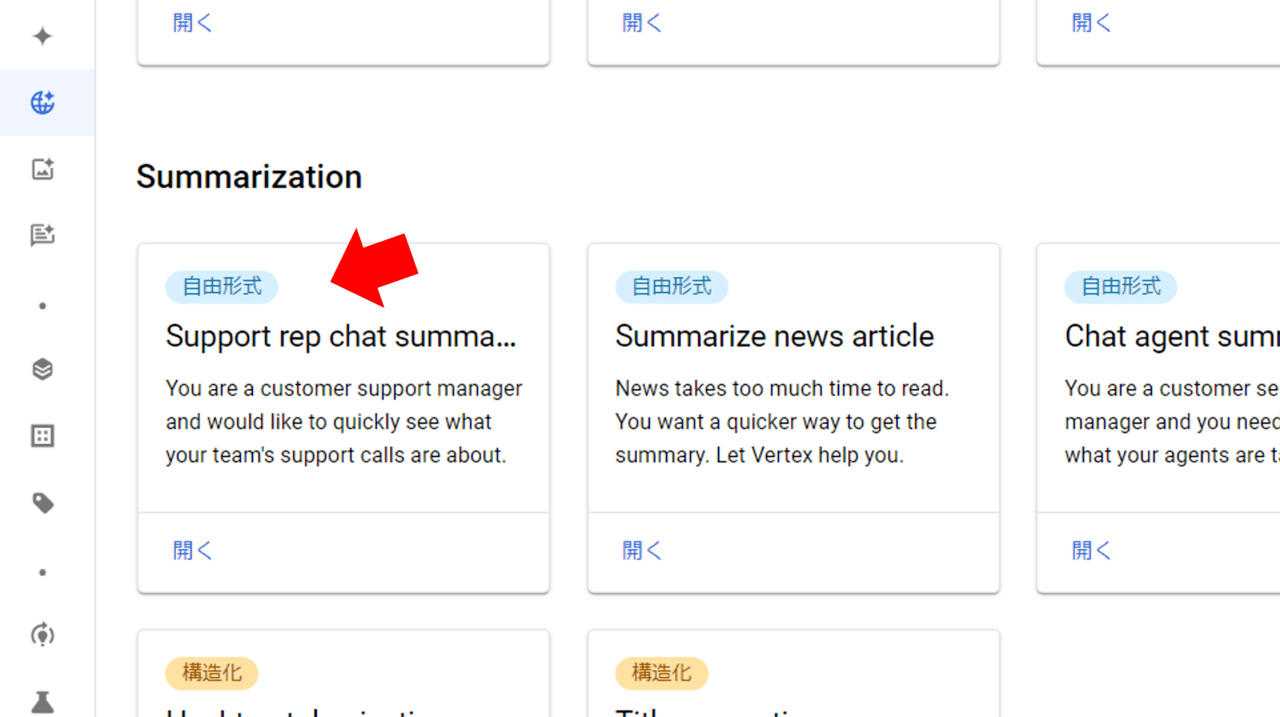
プロンプトを選択し「送信」を押下することで、
入力したサービス担当者と顧客の間の会話を数文で要約してくれます。
■入力:Promptにお客様との会話内容を入力
■出力:会話内容のサマリを出力
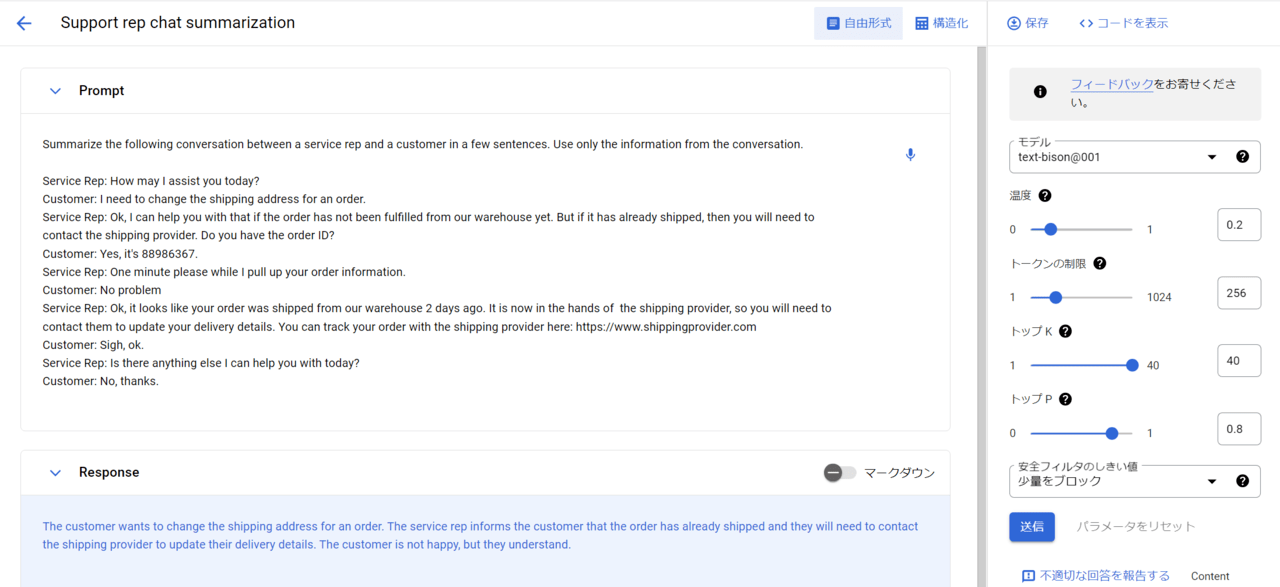
Prompt入力内容(カッコ内に日本語翻訳を記載してます。)
Summarize the following conversation between a service rep and a customer in a few sentences. Use only the information from the conversation.
(サービス担当者と顧客の間の次の会話を数文で要約してください。 会話からの情報のみを使用してください。)
Service Rep: How may I assist you today?
(サービス担当者: 今日はどの様にお手伝いさせて頂けますか? )
Customer: I need to change the shipping address for an order.
(顧客: 注文の配送先住所を変更する必要があります。 )
Service Rep: Ok, I can help you with that if the order has not been fulfilled from our warehouse yet. But if it has already shipped, then you will need to contact the shipping provider. Do you have the order ID?
(サービス担当者: わかりました。注文がまだ倉庫から出荷されていない場合は、お手伝いさせていただきます。 ただし、すでに発送されている場合は、配送業者に問い合わせる必要があります。 注文IDはありますか?)
Customer: Yes, it’s 88986367.
(顧客: はい、88986367 です。)
Service Rep: One minute please while I pull up your order information.
(サービス担当者: 注文情報を確認するまで、1 分ほどお待ちください。)
Customer: No problem
(顧客: 問題ありません)
Service Rep: Ok, it looks like your order was shipped from our warehouse 2 days ago. It is now in the hands of the shipping provider, so you will need to contact them to update your delivery details. You can track your order with the shipping provider here: https://www.XXXX
(サービス担当者: わかりました。ご注文は 2 日前に当社の倉庫から発送されたようです。 現在、配送業者の管理下にあるため、配達の詳細を更新するには配送業者に連絡する必要があります。 ここから配送プロバイダーによる注文を追跡できます:https://www.XXXX)
Customer: Sigh, ok.
(顧客: はぁ、わかりました。)
Service Rep: Is there anything else I can help you with today?
(サービス担当者: 今日は他に何かお手伝いできることはありますか?)
Customer: No, thanks.
(顧客: いいえ、ありがとう。)
Response出力内容(カッコ内に日本語翻訳を記載してます。)
The customer wants to change the shipping address for an order. The service rep informs the customer that the order has already shipped and they will need to contact the shipping provider to update their delivery details. The customer is not happy, but they understand.
(顧客は注文の配送先住所を変更したいと考えています。 サービス担当者は、注文品はすでに発送されており、配達の詳細を更新するには配送業者に連絡する必要があることを顧客に伝えます。 顧客は満足していませんが、理解しています。)
参考までに、調整可能なパラメータについても記載しておきます。
Introduction to prompt design | Vertex AI | Google Cloud
■【Temperature:温度】
温度は、トークン選択のランダム性の度合いを制御できます。。
低い温度は、正しいレスポンスや適切なレスポンスが求められるプロンプトに適しています。
一方、温度が高いと、多様な結果や想定外の結果が生じる可能性がある。
温度 0 は決定論的で、確率が最高のトークンが常に選択される。
■【Max output tokens:トークンの制限】
トークンの上限により、1 つのプロンプトから出力されるテキストの最大量が決まります。
トークンは約 4 文字です。デフォルト値は 256 です。
■【Top K】
トップ K は、モデルが出力用にトークンを選択する方法を変更できます。
トップ K が 1 の場合、選択されるトークンは、モデルの語彙内のすべてのトークンで最も確率の高いものであることになります(グリーディ デコードとも呼ばれます)。
トップ K が 3 の場合は、最も確率が高い上位 3 つのトークンから次のトークン選択されることになります。
■【Top P】
トップ P は、モデルが出力用にトークンを選択する方法を変更できます。
確率の合計が トップ P の値と等しくなるまで、最も確率が高いものから最も確率が低いものの順に、トークンが選択されます。
たとえば、トークン A、B、C の確率が 0.3、0.2、0.1 で、トップ P の値が 0.5 の場合、モデルは次のトークンとして A と B のいずれかを選択。
参考)OpenAI API利用方法
OpenAI から提供されている生成系AI API(gpt-3.5-turboなど)については、OpenAI のアカウントを作成することで、利用可能です。
また、利用に際しては、「API Key」を作成し、モジュールをインストール後にAPIをコールすることで、利用ができます。
詳細については下記公式ドキュメントをご確認下さい。
import openai
openai.ChatCompletion.create(
model=”gpt-3.5-turbo”,
messages=[
{“role”: “system”, “content”: “You are a helpful assistant.”},
{“role”: “user”, “content”: “Who won the world series in 2020?”},
{“role”: “assistant”, “content”: “The Los Angeles Dodgers won the World Series in 2020.”},
{“role”: “user”, “content”: “Where was it played?”}
])
Bard(PaLM2)とChatGPT Plus(GPT-4)でいろいろと試してみました。
実際にプロンプト色々と入力して、それぞれの回答を比較してみました。
【比較1】基本的なQA
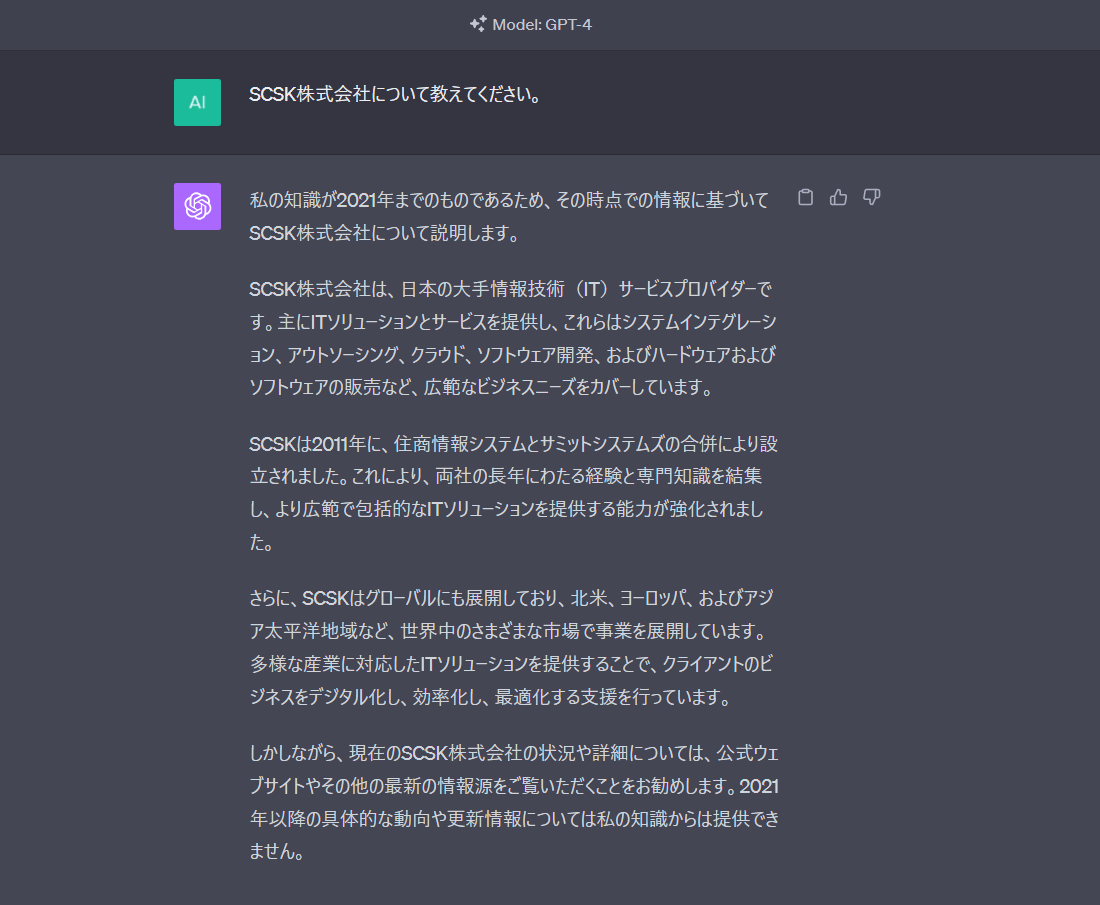
SCSK株式会社について教えてください。
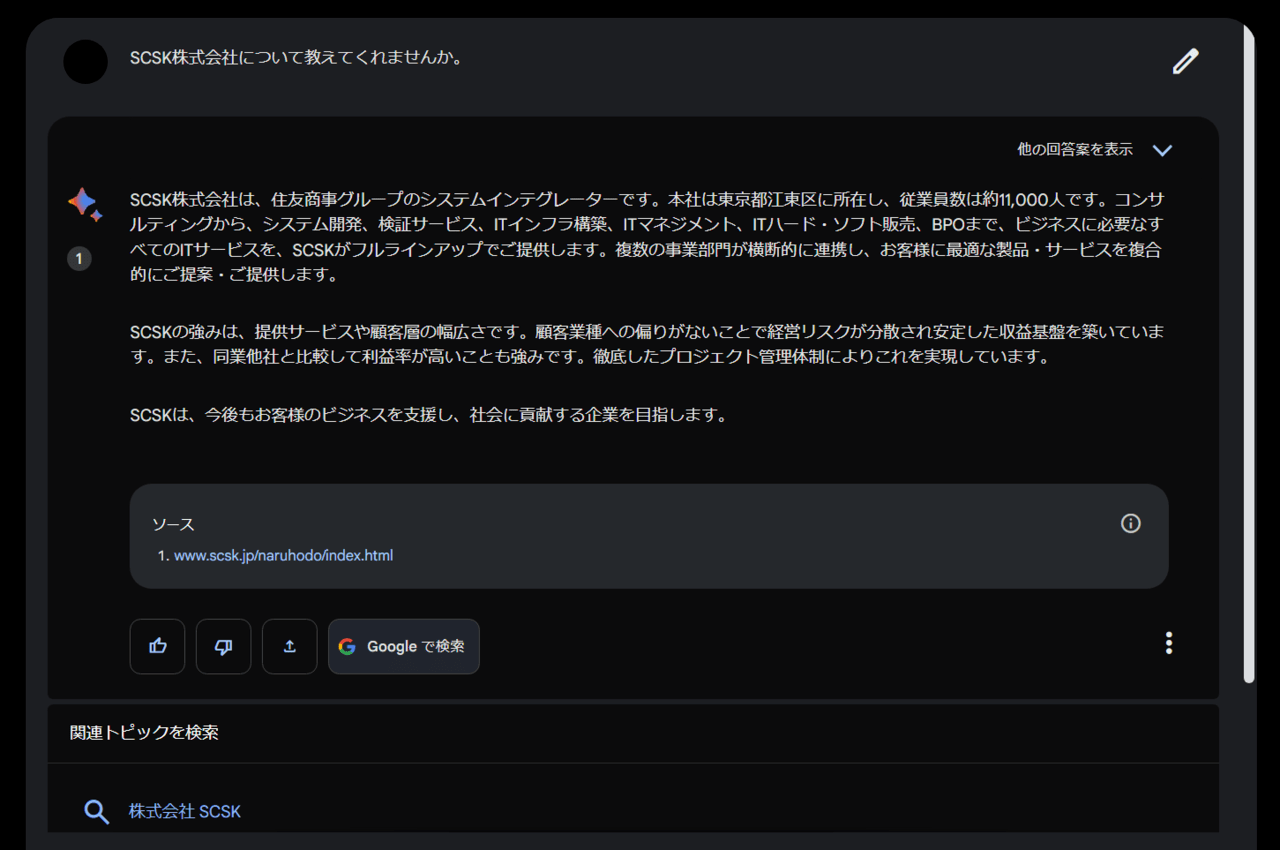
Open AI ChatGPT回答
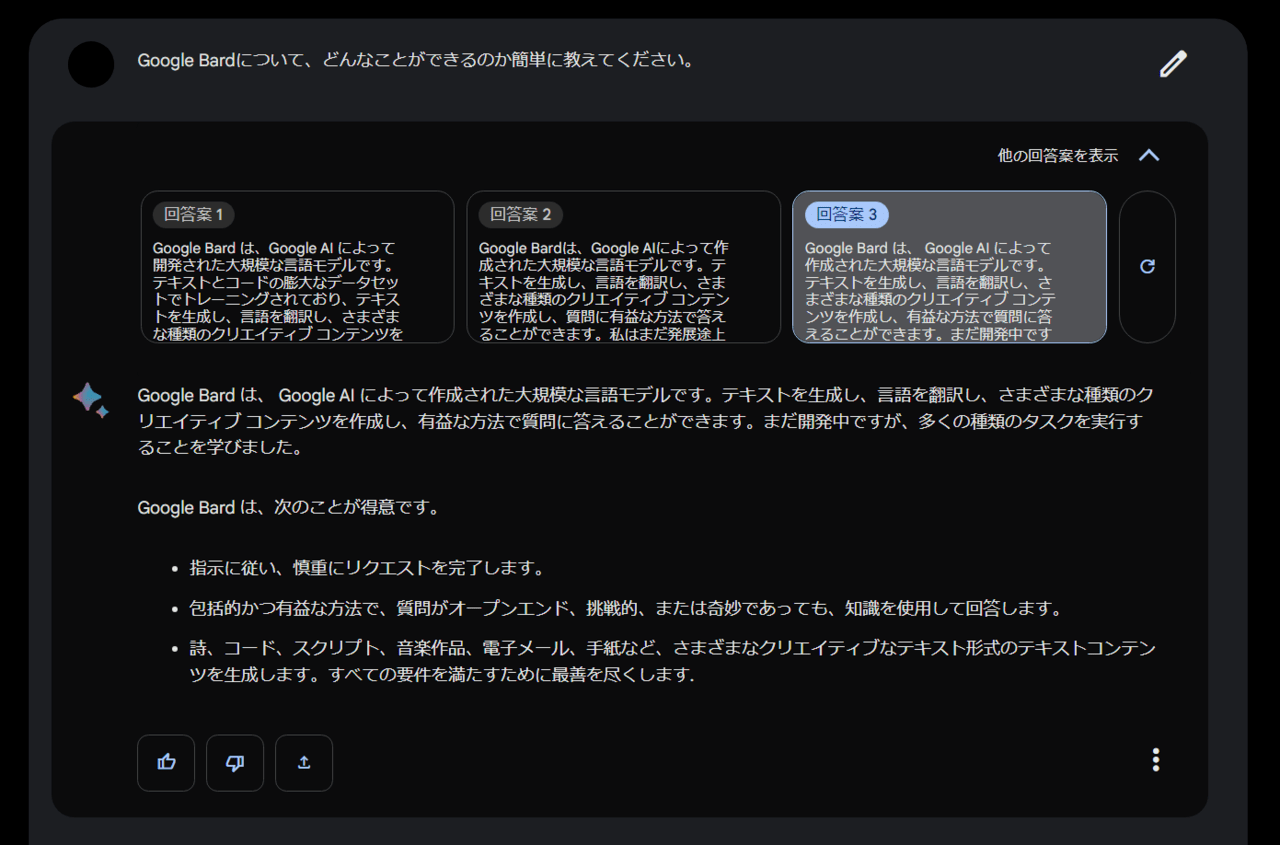
(Bard/ChatGPT)について、どんなことができるか簡単に教えてください。
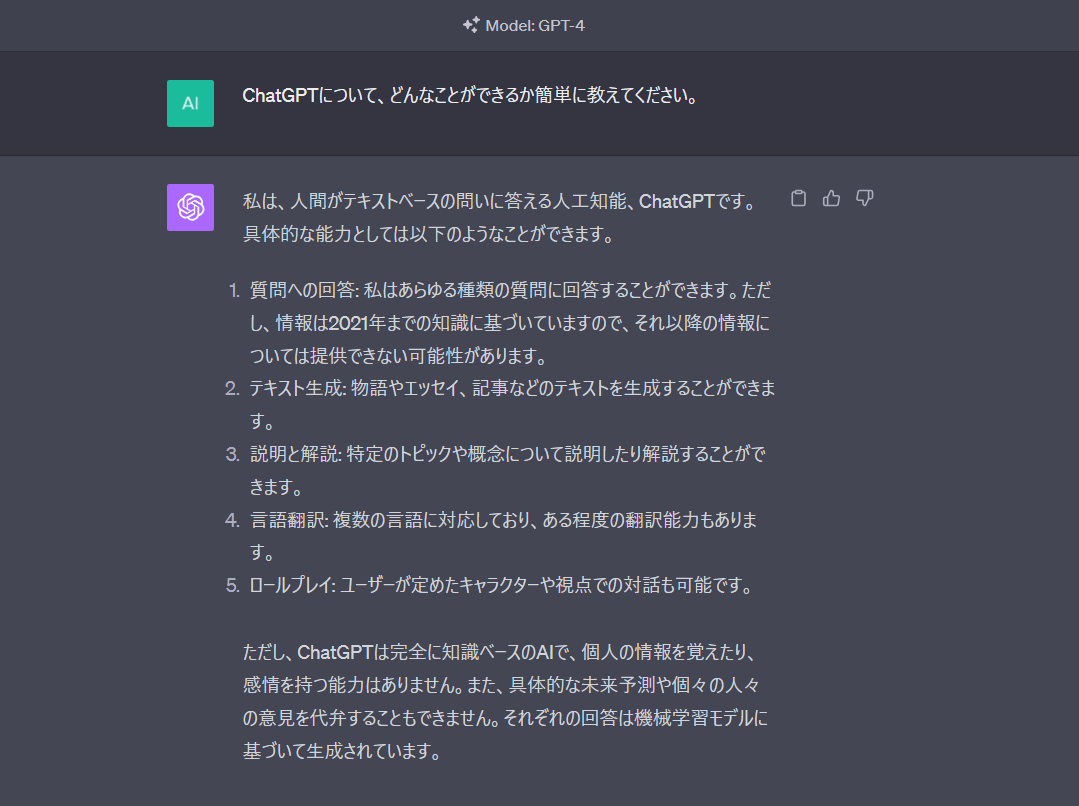
Open AI ChatGPT回答
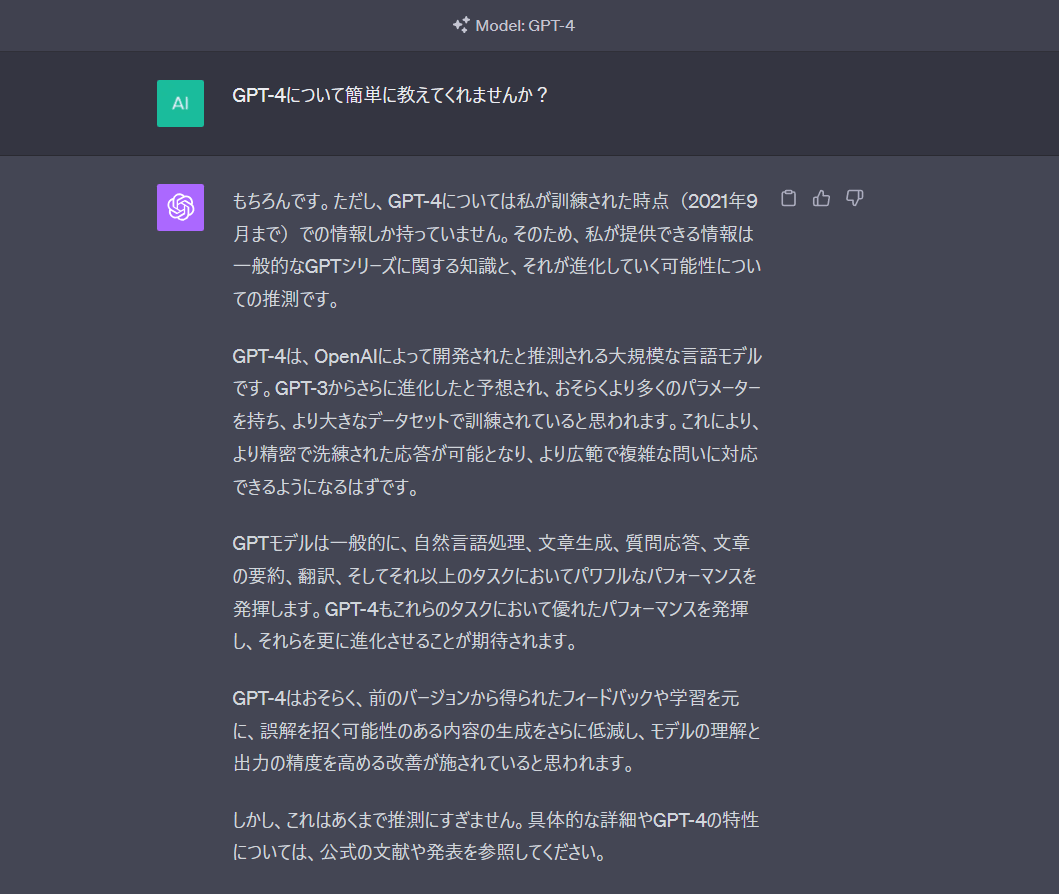
GPT-4について簡単に教えてくれませんか?
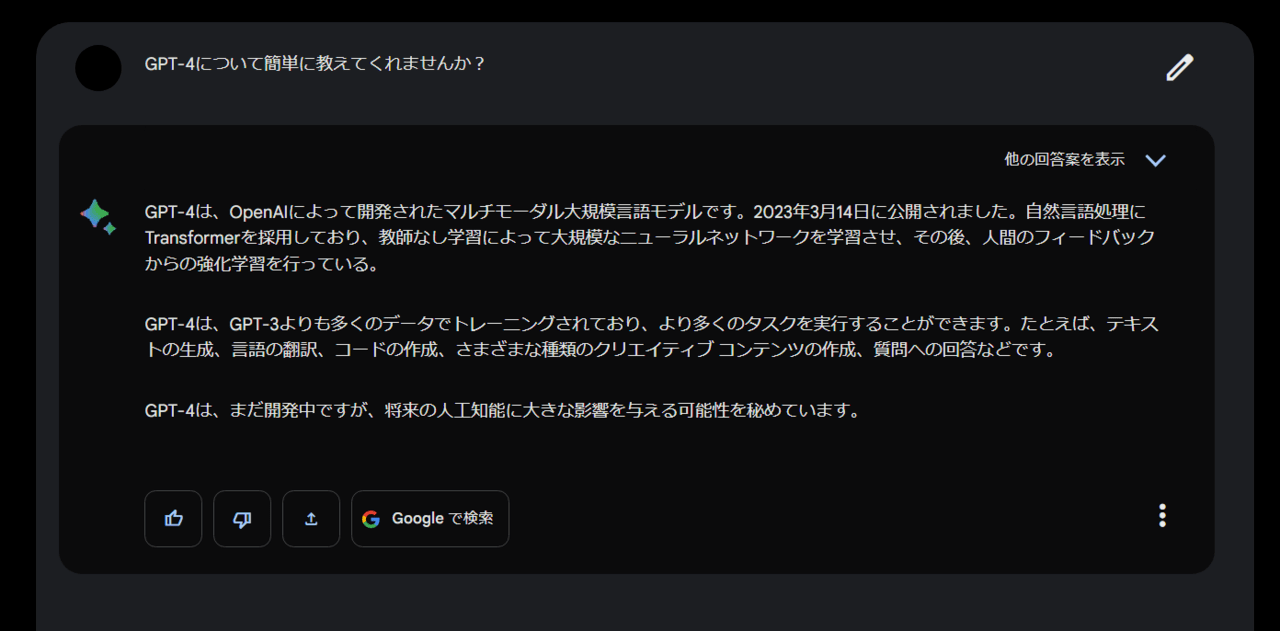
Open AI ChatGPT回答
【比較2】コードの生成
閏年を計算するためのコードを教えてくれませんか。
言語はPythonを利用します。
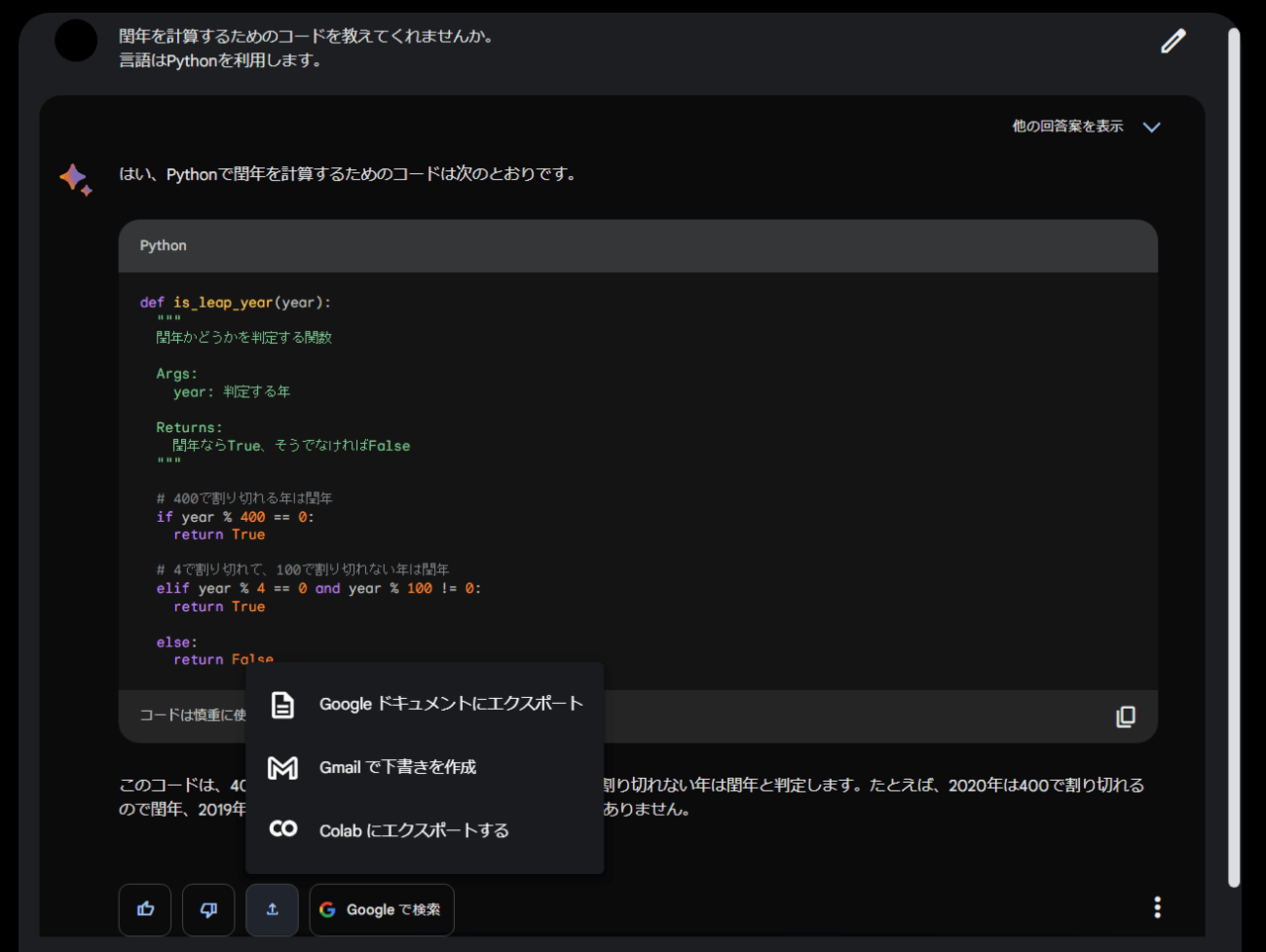
Open AI ChatGPT回答
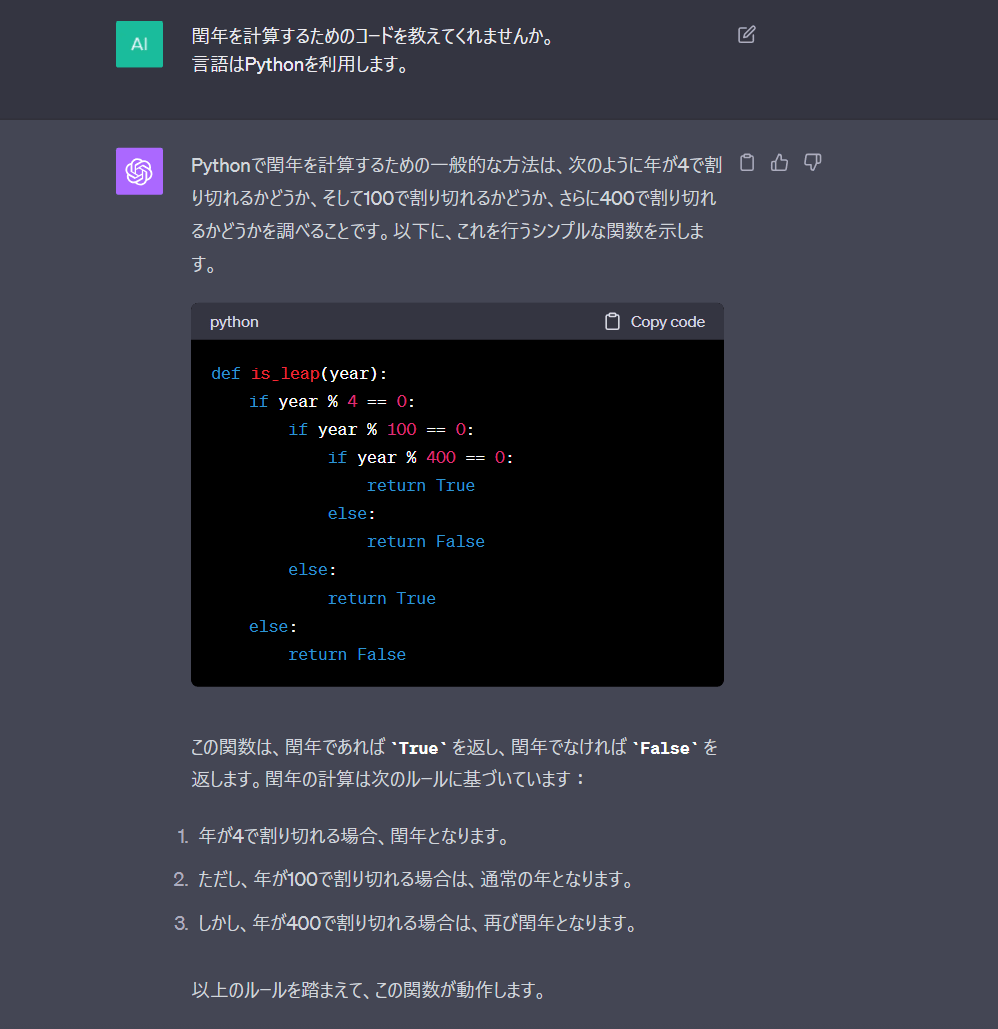
プログラムについては両社とも問題なく動きました。
Colabに連携し、すぐに検証できるのはBardの魅力だと感じます。
最後に
今回はGoogle Cloudの「生成系AI」について更に深堀してご紹介させていただきました。
今後とも、AIMLに関する情報やGoogle CloudのAIMLサービスのアップデート情報を掲載していきたいと思います。
最後まで読んでいただき、ありがとうございました!!!