
 本記事は 夏休みクラウド自由研究 8/29付の記事です。 本記事は 夏休みクラウド自由研究 8/29付の記事です。 |
こんにちは あるいは こんばんは
SCSKの猿橋です。
パリオリンピックの興奮冷めやらぬ2024年現在、AIといえば生成AIが全盛ですが、特定のユースケースではMLのカスタムモデルを活用するケースもあるかと思います。
カスタムモデルを構築するには機械学習の知識やノウハウ、実装スキルが必要になりますが、Amazon SageMaker Canvasを活用すれば、ノーコードでモデル構築が可能となります。
今回はAWSのハンズオンを通じてAmazon SageMaker Canvasを試してみました。
はじめる前に
Amazon SageMaker Canvasは使用時間課金になります。
左下にLogoutボタンがあり、使用しないときはLogoutをすることで課金を止めることができるようですので、忘れずLogoutしておきましょう。
ワークスペースインスタンス (セッション-時間) の料金
1.9 USD/時間
機械学習におけるAmazon SageMaker Canvasの活用シーン
機械学習を活用するにあたり、以下の課題があるとハンズオンの中で挙げられています。
- 機械学習の実用化には時間がかかり、コーディングと知識が必要
- 機械学習のニーズは増える一方で、データサイエンスチームはフル稼働
- ビジネスアナリストは、機械学習の知識不足で短時間での習得は困難
- ステークホルダー間でのコラボレーションは機械学習モデルの信頼性を高めるが、一般的なツールは単一ワークスペースで、機械学習テクニカル知識を求める単一ワークスペース環境
機械学習を活用するには専門的な知識が求められますが、そういった人材を育てたり確保したりすることが簡単ではない、ということも背景にありそうです。
そのような状況の中でも、ビジネス課題に対して機械学習でのソリューションを試してみたい、という場合に、ノーコードで機械学習を活用できるAmazon SageMaker Canvasがビジネスの現場で活用シーンがでてくるわけですね。
Amazon SageMaker Canvas環境作成
それではハンズオンを始めてみます。
まずは「SageMakerドメインを作成」ボタンでドメイン作成を開始します。
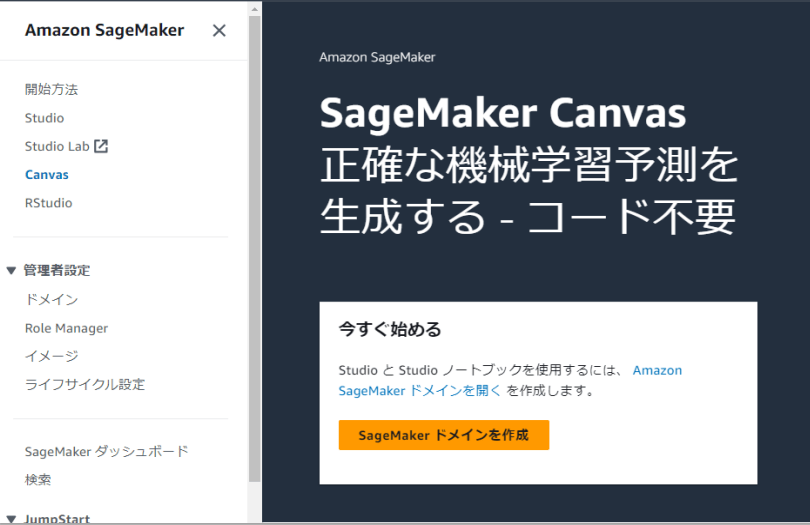
今回はクイックセットアップを活用することで、ドメインとユーザープロファイルの作成ができました。
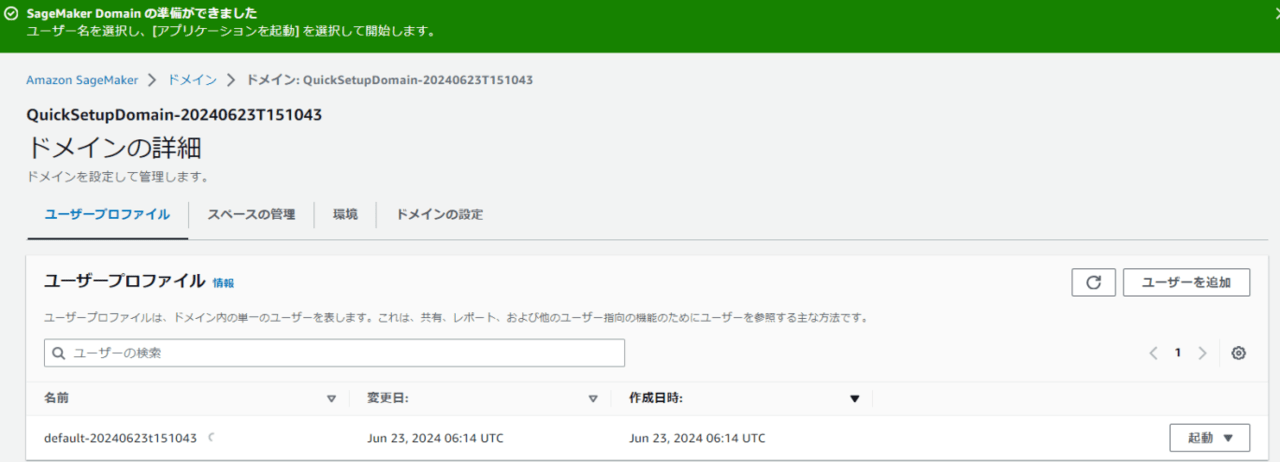
作成されたプロファイルの横にある起動ボタンでCanvasを起動します。

Canvasが起動できました
データの投入
環境構築が完了してCanvasが起動できたら、次はデータの投入です。
今回のハンズオンのユースケースとしては、以下のようなテーマ設定になっていました。
私たちは、携帯電話通信事業者のマーケティングアナリストです。
データを活用して、顧客離反の要素を判明し、お客さんの解約傾向を予測したいです。
ハンズオンのWebページに今回のユースケース用のデータダウンロードリンクがついているので、そこからデータをダウンロードしました。
このデータをCanvasに投入してみます。
左のメニューからDatasetsを選びます。
DLしたデータセットをインポートする為、右上のImport Data>Tabularを押下
表示されたダイアログにデータセット名を入力
データセットをドラッグ&ドロップでインポート、、、
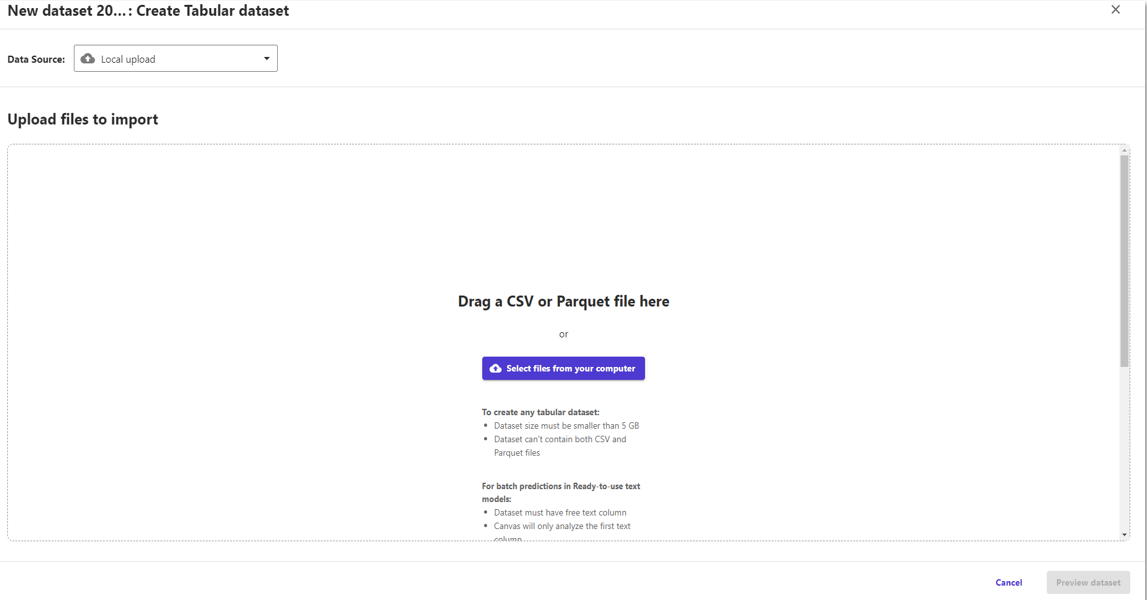
と、拡張子がtxtのままだとエラーになってしまいました。
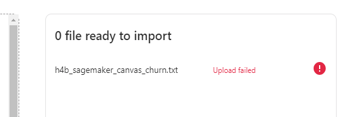
気を取り直してcsvに拡張子を変更し、アップロードしたところS3へのアップロードエラー
振り返ると、最初のドメイン作成時に自動で生成してくれたのは便利だったのですが、ハンズオン動画を見直すとドメイン作成時にIAMロールでAmazon S3への権限設定をしていました。
アップロードのエラー対策として、IAMロールにAmazon S3権限を追加することも考えられますが、今回はデータソースがAmazon S3を選べるので、手動でAmazon S3にアップロードし、Amazon S3からインポートすることとしました。
S3へのアップロードが完了したら、Data SourceでAmazon S3を選択し、データセットのインポートを実行
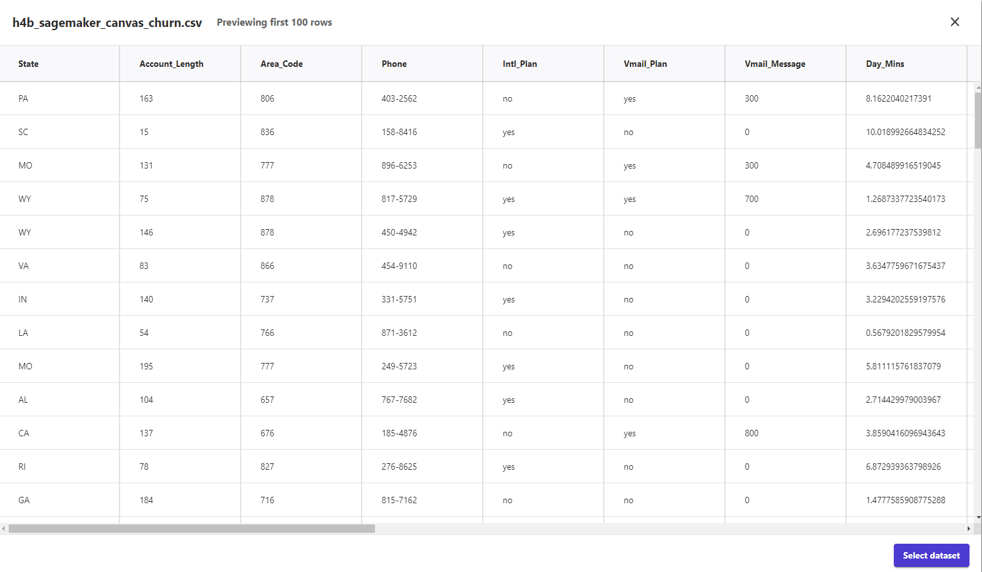
データセットを指定すると、プレビューができました
右上のCreate datasetボタンでデータセットの登録を実行
これで無事データセットのインポートが完了しました。
モデルの構築:データの探索
データセットのインポートが完了したら、次はデータの探索です。
機械学習で予測精度を上げるにはデータセットへの理解が欠かせません。
データセット内のパターンや特徴を把握し、クレンジングが必要な箇所を特定し、仮説を立ててデータ項目の相関性を分析します。
まずは左メニューのMy Modelsを選択し、モデル画面を表示します。
New modelボタンよりモデルの構築を開始します。
モデル名にハンズオンに倣って「CustomerChurn」と付けました。
「Churn」は解約を表す言葉でサブスクリプション型ビジネスモデルではチャーン率が重要な指標となります。
使用するデータセットを選択して「Select dataset」ボタン押下
Buildタブに移動し、選択したデータセットのカラム情報が表示されています。
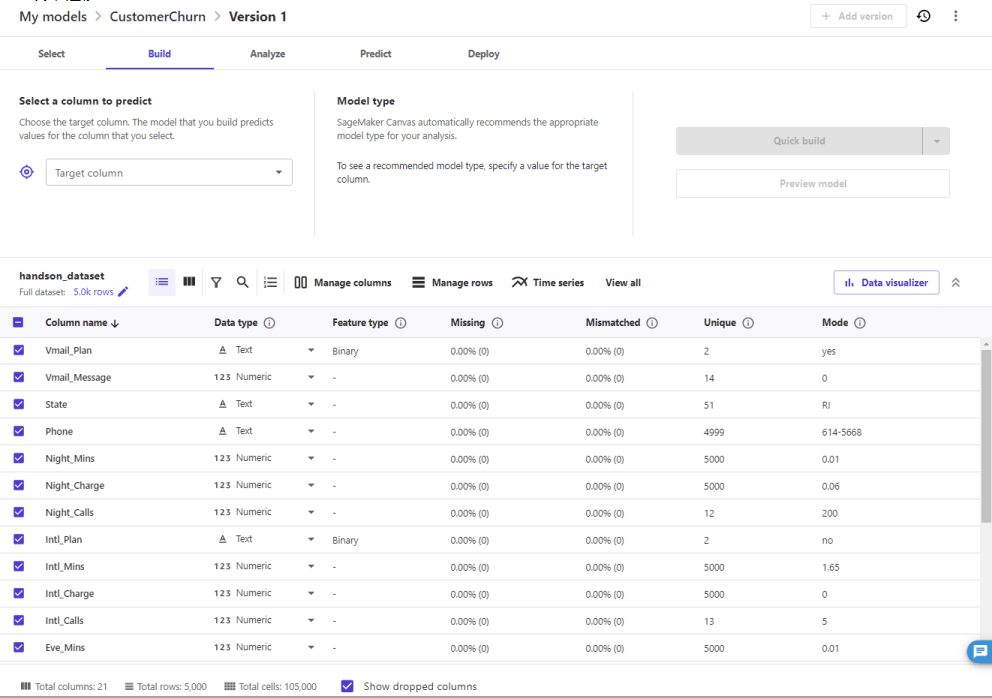
データセットに対し予測対象のカラムを指定します。
今回は「Churn」を選択します。
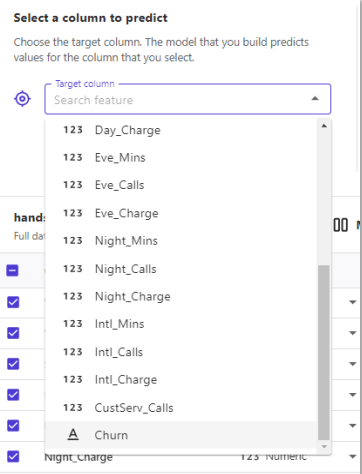
予測カラムを選択すると、お勧めのモデルがModel type欄に表示されます。
「2 category prediction」がお勧めされました。
予測列を選択したプルダウンの下にValue distributionとして予測対象カラムの値分布が表示されていますが、False/True半々のようです。
ということで、「2 category prediction」でよさそうです。
モデルを変更したい場合は以下のようにConfigure modelで変更ができます。
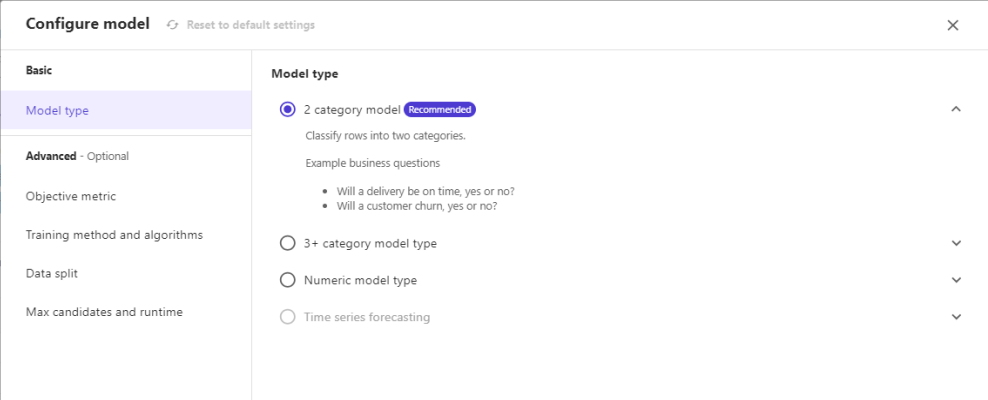
Grid viewを選択すると、各カラムの分布図がワンクリックで表示されます。
最初のカラム毎の情報を掴むのに便利な機能ですね!
さらに高度な探索をするために、「Data visualizer」を使ってみます。
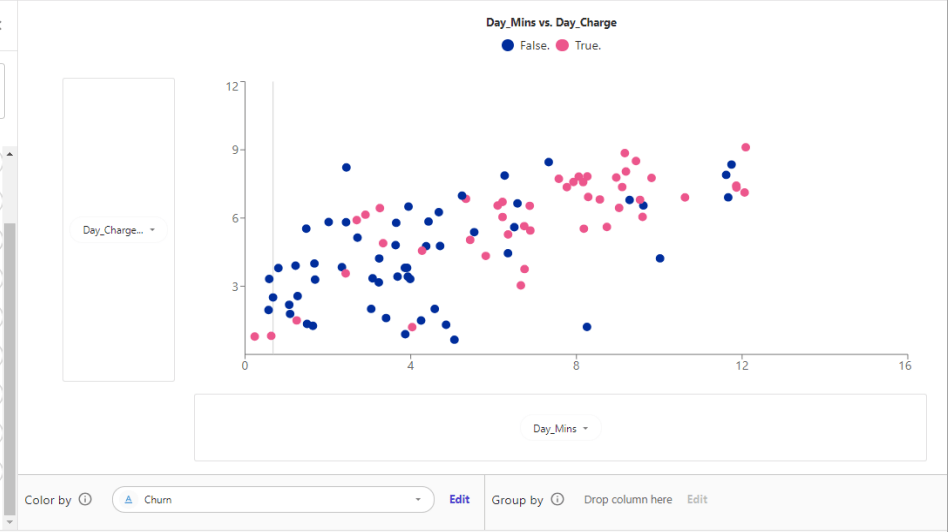
「Day_Mins」(日中の通話時間)を横軸に、「Day_Charge」(日中の課金額)を縦軸に散布図を作成してみます。
各点の色にChurnを割り当てていて、赤色が解約したユーザーになります。
傾向として、長時間電話して課金額が高いユーザーであるほど解約傾向が高そうなことが分かりました。
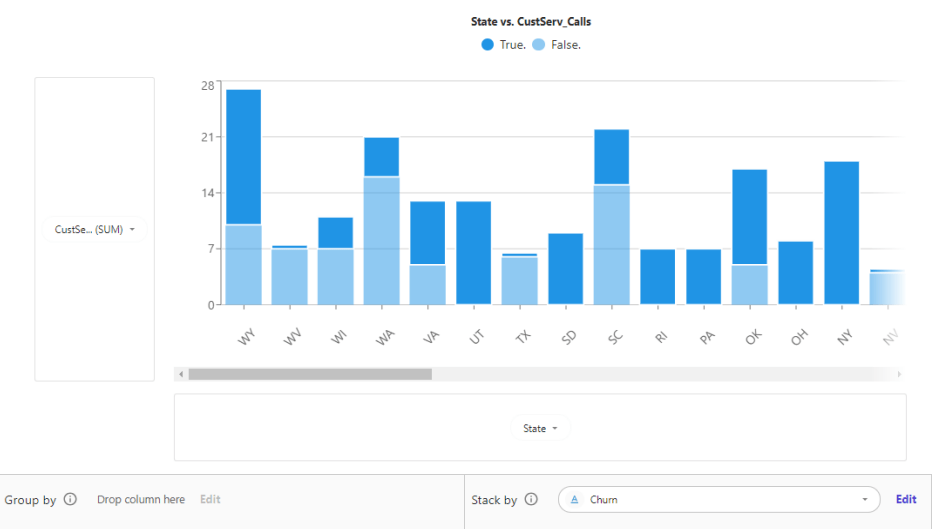
次は「State」(州)を横軸に、「CustServ_Call」(カスタマーサービスへのCall数)を縦軸に積み上げ棒グラフを作成してみます。
ChurnのTrue/Falseの割合が州毎に可視化できました。
もしかしたらChurn率が高い州はカスタマーサービスの改善の余地があるかもしれませんね。
モデルの構築:モデルのプレビューと特徴量エンジニアリング
カラムの相関関係や特徴などが掴めてきたら、特徴量エンジニアリングとモデルのプレビューに進みます。
特徴量エンジニアリングとは簡単にいうと予測に有用な説明変数を作り上げることですが、単純に1カラム、2カラムのデータを取り上げて予測を説明する変数だ、と言えるほど単純なものではありません。予測精度を上げるために複数のカラムの情報を組み合わせることになり、ドメイン知識なども活用して算出式を作ってみて、Try&Errorで精度を上げていく作業になります。実際には簡単に精度が上げられるわけではなく、多くの作業時間を費やしても思ったような結果がでにくい難易度が高い作業になりがちです。(PoC死が発生するわけですね
それでは「Preview model」をクリックし、モデルのプレビューを開始してみます。
ベースライン精度が95.6%と分かります。(95.6%の確率で正しく予測できる、という指標
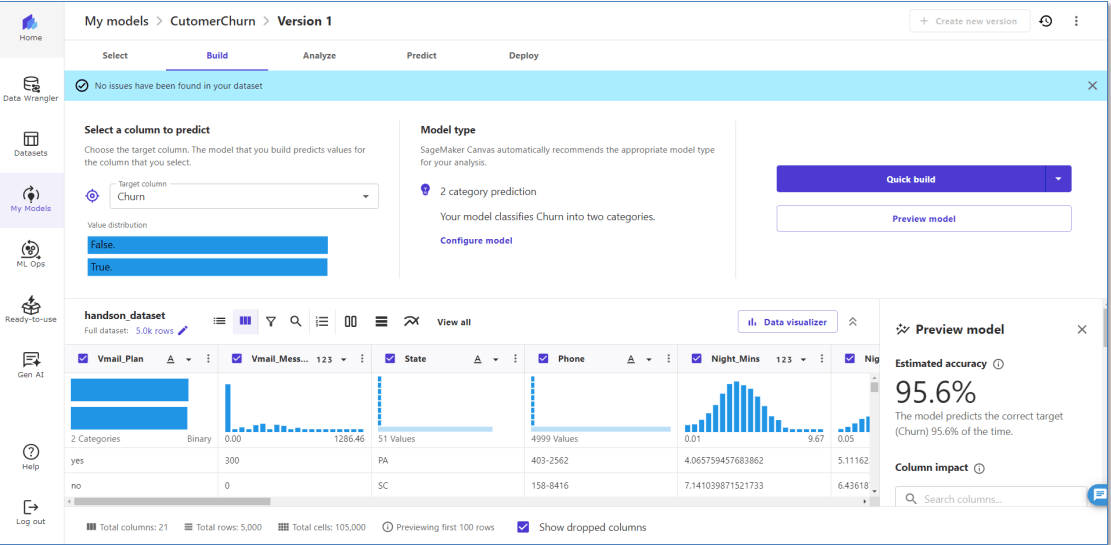
※もし、重要度があまりにも高すぎる、予測ターゲットと同意のカラムがある場合は除去するなどの注意が必要になるようです。
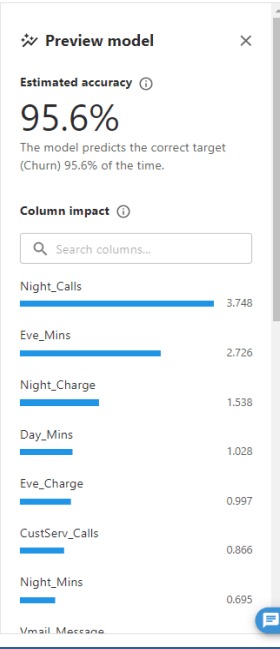
今回のユースケースを考慮し、例えば「Phone」は電話番号を表すカラムですが、解約には無関係と思われるので、ノイズとなりうるカラムは除去しておきます。カラムのチェックボックスを外すことで簡単に除去できます。
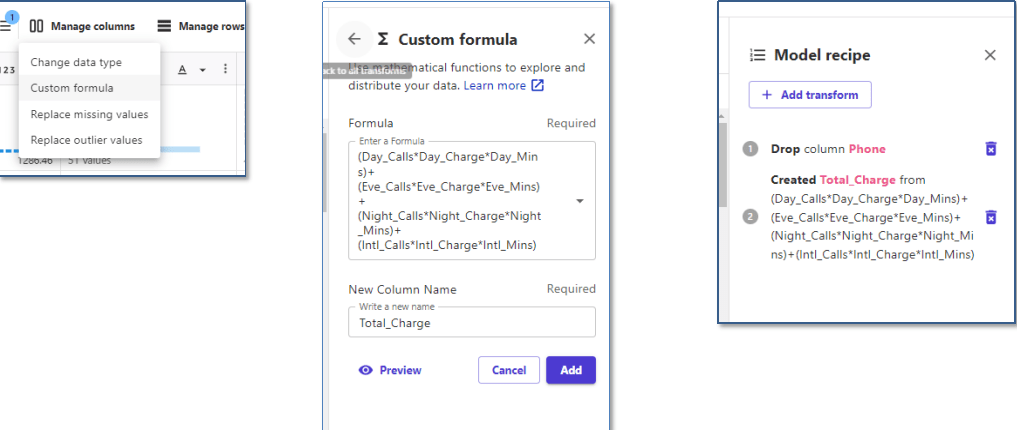
Manage columns>Custom fomula で計算式とカラム名を設定し、Addボタンで追加します。
操作履歴は「Model recipe」に記録されるようです。
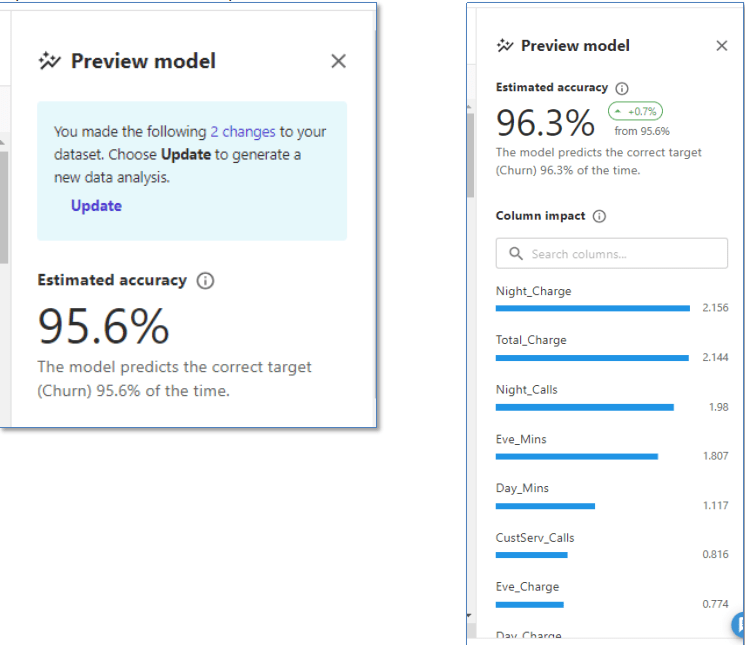
Updateするかを聞いてくるんのでUpdateをクリックして更新処理を進めます。
結果、ベースライン精度が96.3%(+0.7%)に上がりました。カラムの編集が効果があったようです。
モデルの学習と評価
データの探索を終えたらモデルの学習と評価の進みます。
モデルのビルド方法として2種類用意されています。
- QuickBuild
- 構築時間2~20分程度
- 精度より速度重視
- 最大5万行まで
- Standard Build
- 構築時間2~4時間程度
- 速度より精度重視
今回のようなPoCレベルであれば、まずはQuickBuildがお勧めのようですので、QuickBuildを進めてみます。
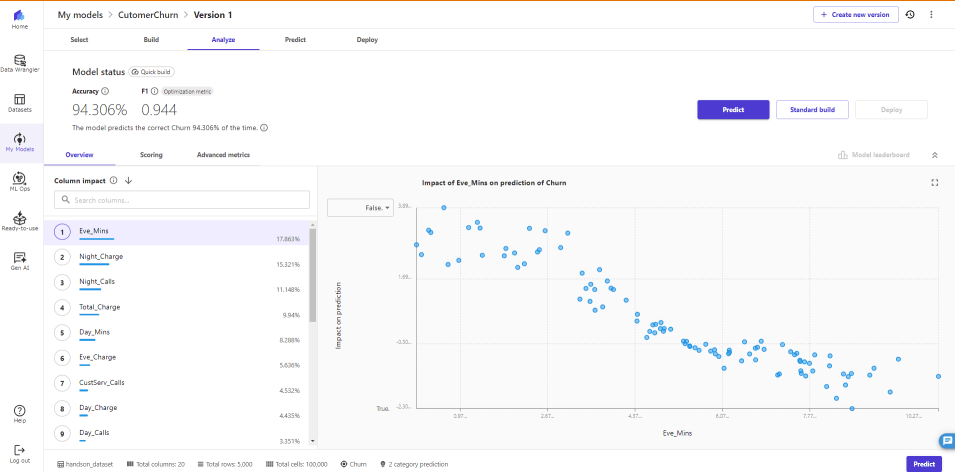
予測精度は約94.3%でPreview時より予測精度が下がってしまったようです。
今回のモデルでは「Eve_Mins」のImpcatが高いようです。
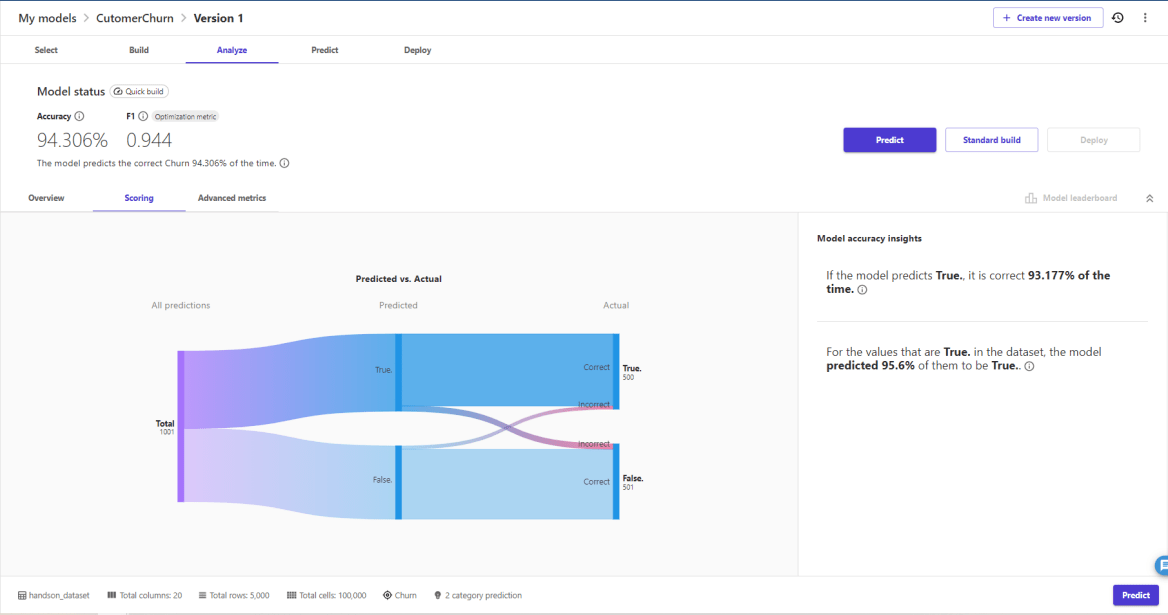
Scoringタブを確認してみます。
このViewに視覚的に予測がどれだけ正しかったかクロス集計として確認することができます。
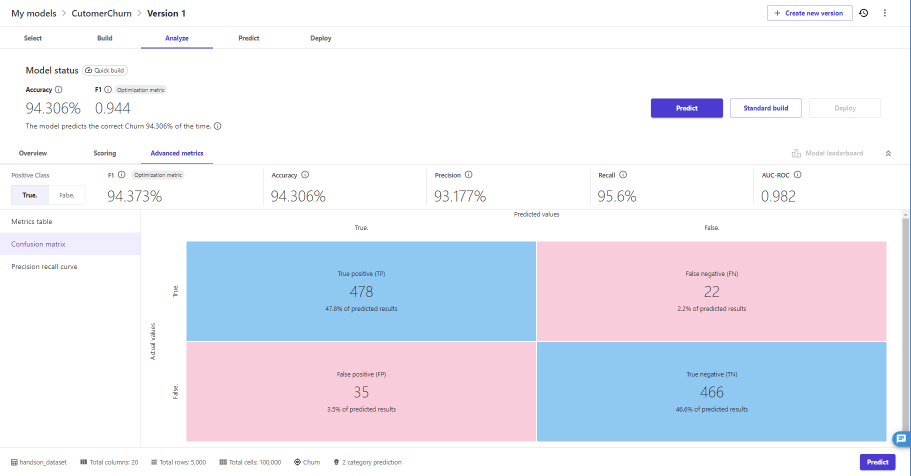
Advanced Metricsタブでは3種類のメトリクスが確認できます
メトリクステーブル
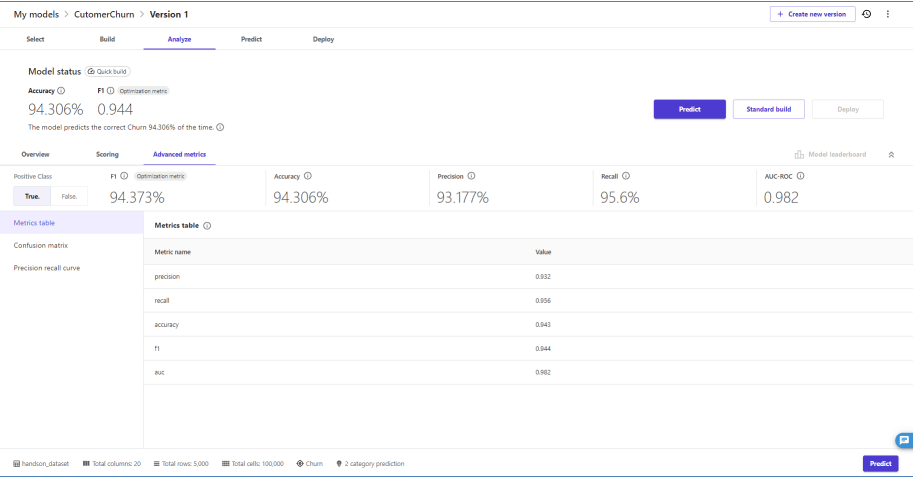
混合行列
Precision recall curve(PR曲線)
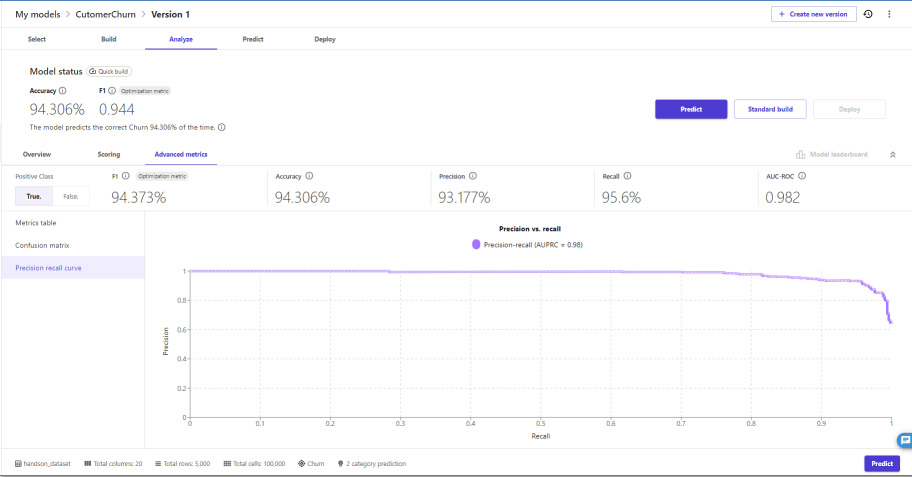
これらのメトリクスやグラフをみながらパラメータチューニングを実施していくことになります。
生成したモデルでの予測
それでは生成したカスタムモデルで予測を実施してみます。
予測には2種類用意されています。
- バッチ予測
- データセット全体を予測する場合に使用
- シングル予測
- 一つのデータに対して予測する。各パラメータを変更可能なので、仮説を立ててパラメータを変更しながら予測の変化を確認できる
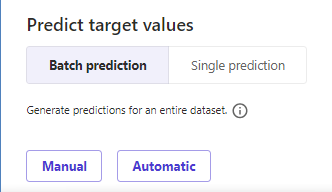
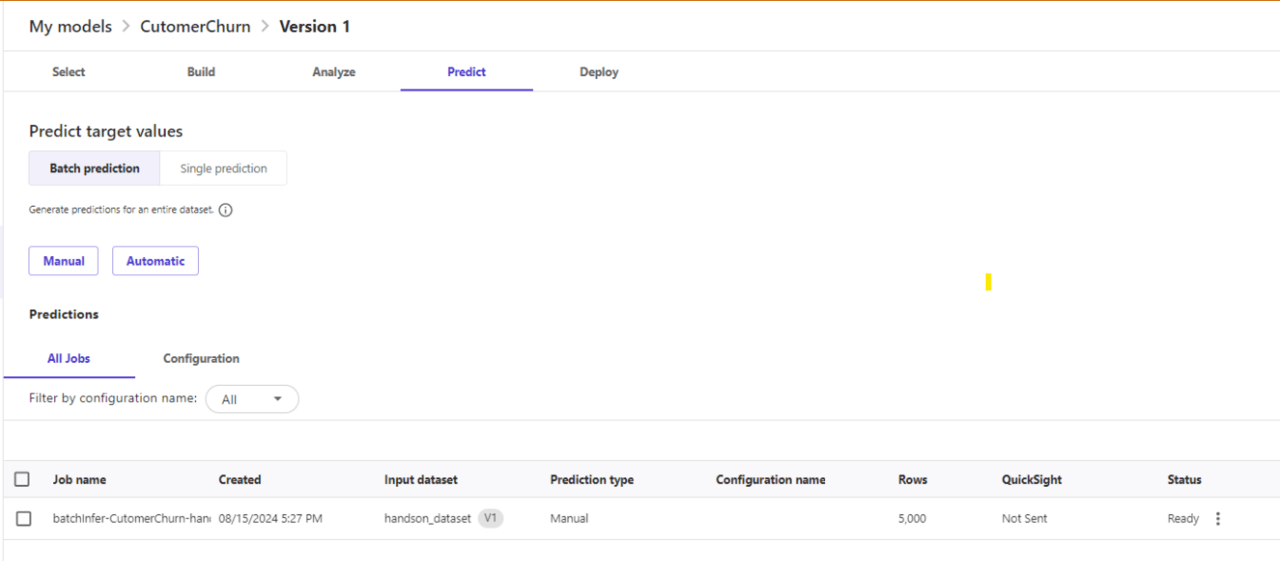
まずはバッチ予測を選択して進めてみます。
Manualボタンを押下すると予測したいデータセットを選択できます。
データセットを選択し、Generate predictionsボタンでバッチ予測を進めます。
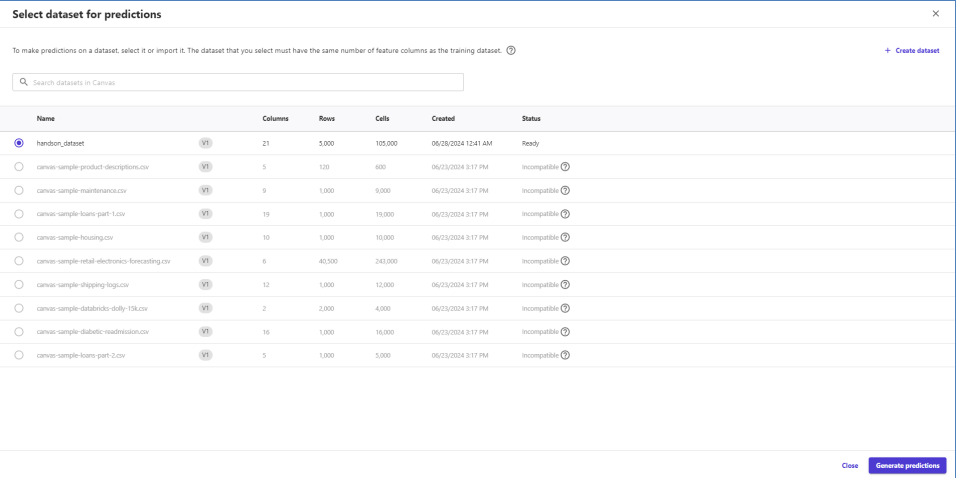
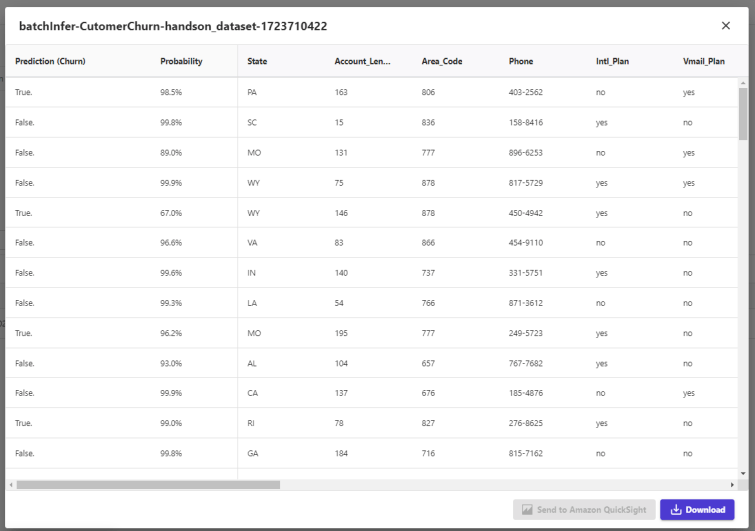
結果はDownloadボタンでcsvダウンロード可能。
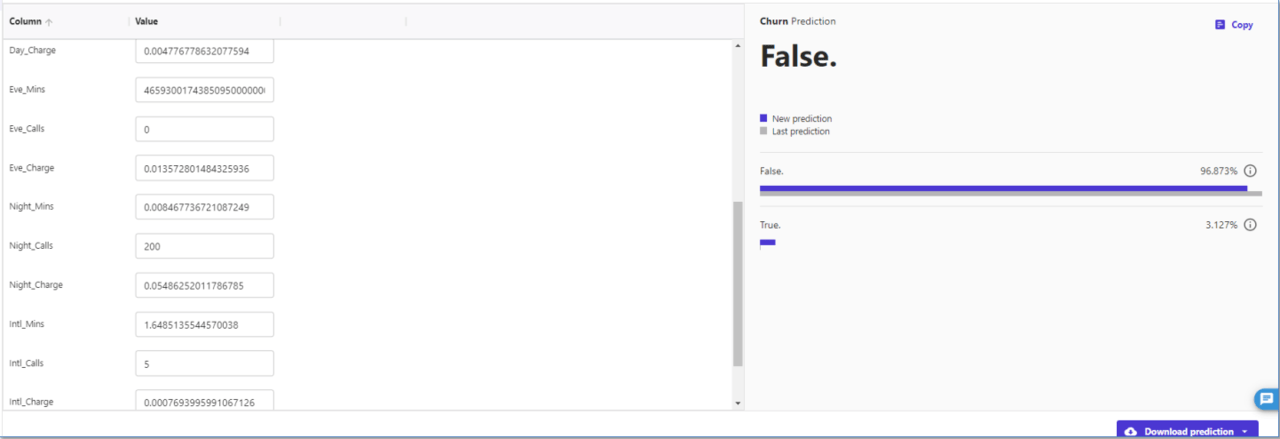
各特徴量を変更したら予測がどう変わるかをリアルタイムに確認できます。
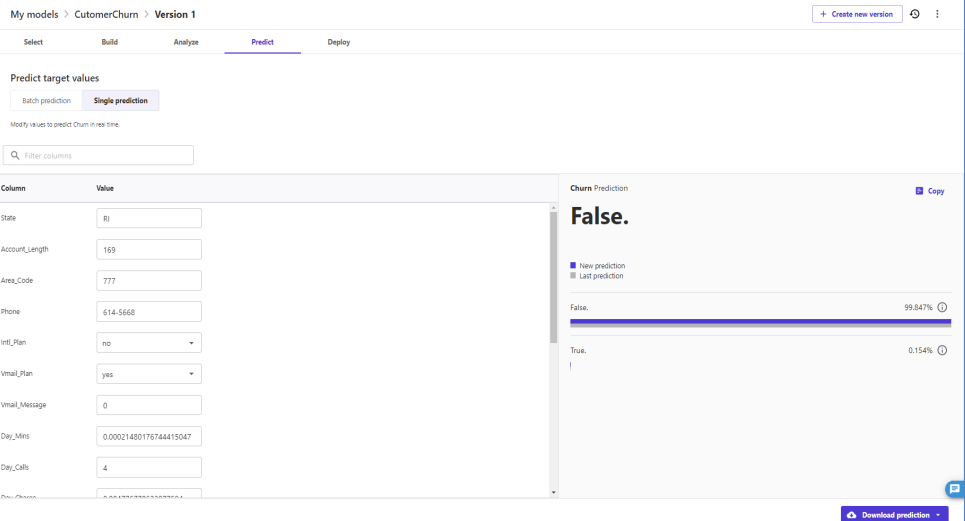
Eve_Minsの値を増やしてみます。
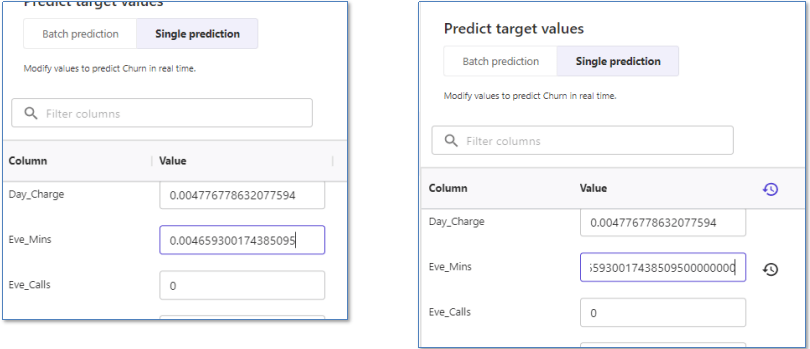
更新前の解約予測は0.154%
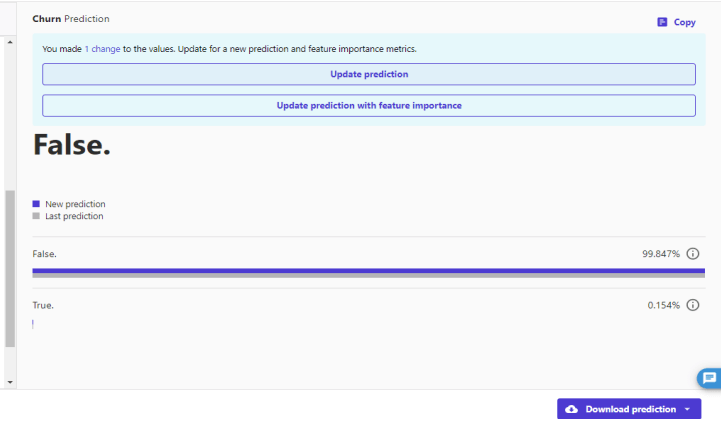
予測更新の結果、解約予測は3.127%にわずかに上がりました。
このような形でWaht-If分析を進めることができます。
おわりに
作業が終わったら忘れずにLogoutしておきましょう。
今回ノーコードで機械学習カスタムモデルを構築することができました。
また、データ探索がGUIで進められたり特徴量の重要度の一覧が自動で表示されるなど、コーディングをしなくともモデル構築を進められることを実感できました。今後、ML活用のPoCがより手軽に精度高く(PoC死しないように)進むように願っています。
あとがき:やってしまいました
冒頭に課金について記載しましたが、このハンズオンを実施する中でやらかしてしまったようで、気づいたらSageMakerの課金が続いてしまっていました。。。
※関係者の方々申し訳ありませんでしたm(_ _)m
Logoutを忘れないように気を付けていたつもりですが、他の調べものなどをしている間にブラウザに埋もれてLogoutを忘れてしまったままブラウザを閉じてしまった日があったようです。
タイミング悪く、ハンズオンを中断してしばらく作業をしていなかったうちに課金が膨らんでしまいました。
Logoutは確実に忘れないこと、また、ハンズオンも集中して1~2日で終わらせられれば無用な課金も抑えられたかと思います。
※Cloud9のように未使用30分でセッション終了する仕組みがあると助かりますね。
同じようなご経験の方のブログを参考として置いておきます。
