

はじめまして。SCSK渡辺(大)です。
シティーハンターの実写映画が面白かったので続編を熱望しています。
今回は、Amazon Bedrock の Knowledge Base で 文字変換 をやってみました。
Pythonのreplaceメソッドを使えば簡単に文字変換することが出来るのですが、敢えてBedrockのKnowledge Baseを使いました。
まだまだ修行中の身ですので間違いが多々あるかもしれませんが、暖かい目で見て頂けると幸いです!
目標
文字変換前のテキストファイルをS3にアップロードするだけで、文字変換後のテキストファイルを得ることが出来るようになる!
結果
先に結果を見たい方のみクリック!
2回目で想定通りに変換することが出来ました!
概要
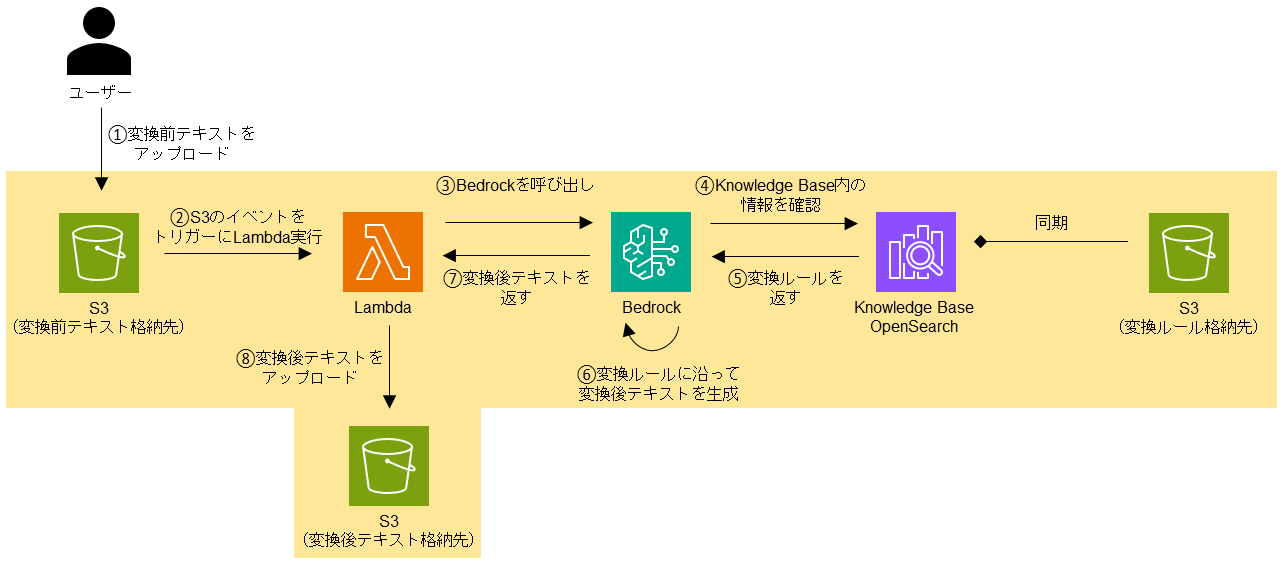
フロー図
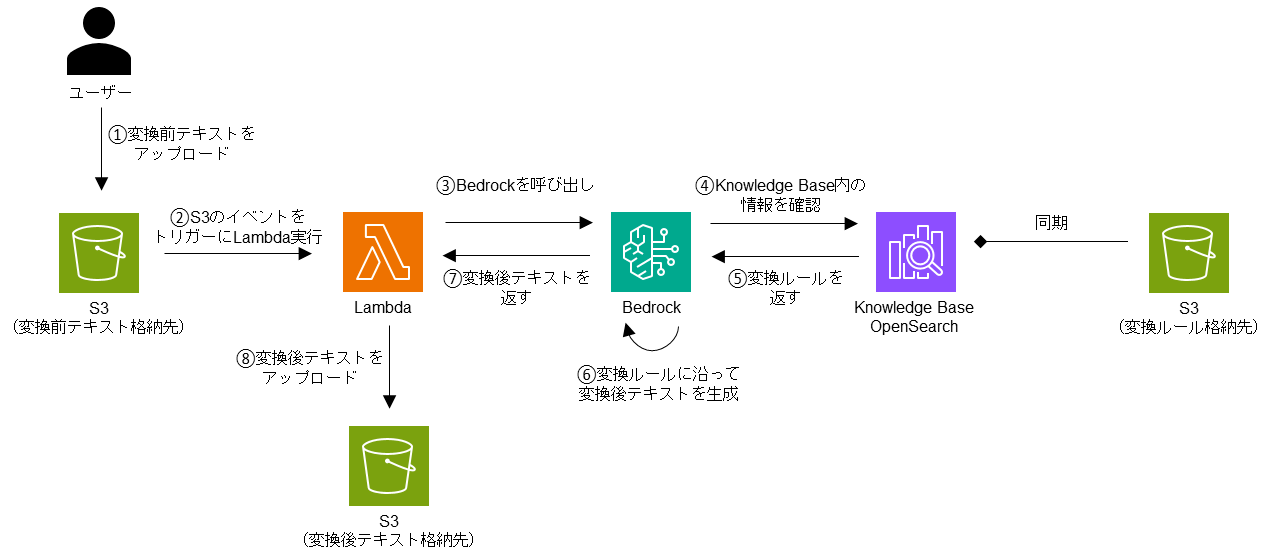
処理の流れ
①.ユーザーは変換前のテキストを所定の S3 にアップロードします。
②.Lambda は S3 にファイルがアップロードされたことをトリガーにして実行されます。
③.Lambda は Bedrock を呼び出し、変換前のテキストを渡します。
④.Bedrock は Knowledge Base OpenSearch に変換ルールの有無を確認します。
⑤.Knowledge Base OpenSearch は Bedrock に変換ルールを返します。
⑥.Bedrock は変換ルールに沿って変換前のテキストを変換することで、変換後のテキストを生成します。
⑦.Bedrock は変換後のテキストを Lambda に返します。
⑧.Lambda は変換後のテキストを所定の S3 にアップロードします。

構築手順
S3
S3バケットの作成
まずはS3バケットを3つ作成します。
バケット名を入力し、その他の設定はノールック(=デフォルト)で作成します。
変換ルールのアップロード
変換ルール格納先のS3バケットに「rule.txt」をアップロードします。
このテキストに記載されているルールに則って変換処理を行ってください。 ルール①:りんご→赤色の丸い果物 ルール②:オレンジ→オレンジ色の丸い果物 ルール③:葡萄→紫色の丸くて小さい果物 ルール④:メロン→緑色の丸くて大きい果物 ルール⑤:バナナ→我が子がこよなく愛する黄色い果物 ルール⑥:ルール①からルール⑤のどれにも当てはまらない場合は、未知の果物
Bedrock Knowledge Base
Bedrock Knowledge Base の作成

下記の記事を参考にBedrock Knowledge Baseを作成します。

続いて、下記の記事を参考に機械学習モデルの有効化を行います。
今回は流行りのClaude 3 Haikuを使用したかったので、有効化されていることを確認しました。

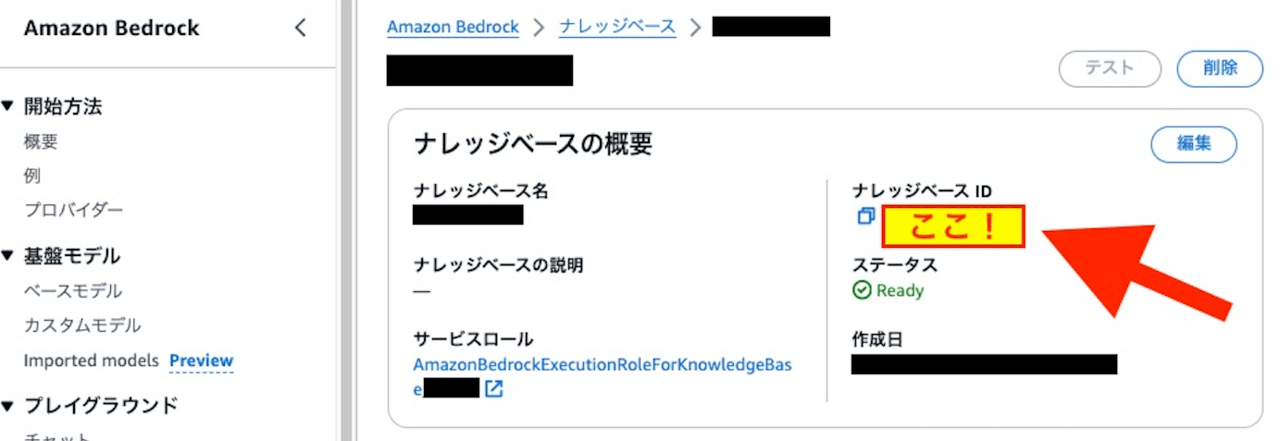
ナレッジベースIDを控える
Lambda(Python)の中でナレッジベースIDを指定する必要があるため控えておきます。
Lambda
Lambdaの作成
「関数の作成」→「設計図の使用」にて下記で作成します。
設計図名:Get S3 object(Python3.10)
実行ロール:AWSポリシーテンプレートから新しいロールを作成
ポリシーテンプレート – オプション:Amazon S3 オブジェクトの読み取り専用アクセス権限
S3トリガー
バケット:変換前テキスト格納先のバケット
イベント:PUT
ランタイム設定の変更
最新のPythonランタイムに変更します。
今回はPython3.12に変更しました。
アクセス制限の変更
LambdaがBedrockを使用できるようにする為、ロールにインラインポリシーで下記を追加します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "bedrock:*",
"Resource": "*"
}
]
}また、AWSLambdaS3ExecutionRoleがアタッチされていますが、S3からファイルを取得(Get)する権限しかない為、こちらはデタッチします。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:GetObject" ], "Resource": "arn:aws:s3:::*" } ] }
代わりにAmazonS3FullAccessをアタッチします。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:*", "s3-object-lambda:*" ], "Resource": "*" } ] }
boto3のバージョンアップ
下記の記事にある通り、boto3 ver.1.28.72が内包されているPython3.12がリリースされた為、boto3のバージョンアップは実施不要です。
コードの修正
最初に掲げた目標の通りにLambdaが動くよう、コードを修正します。
下記は私が人生で初めて書いたPythonのコードです。ご査収ください。
import json
import boto3
import urllib.parse
import sys
s3 = boto3.client('s3')
boto3 = boto3.client('bedrock-agent-runtime')
# Bedrock処理
def convert_text(knowledge_txt):
response = boto3.retrieve_and_generate(
input={"text": knowledge_txt},
retrieveAndGenerateConfiguration={
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
'generationConfiguration': {
'promptTemplate': {
'textPromptTemplate': 'あなたは、ユーザーがs3にアップロードしたテキストの内容を変換して回答するエージェントです。'\
'変換のルールは「rule.txt」に記載されています。回答は必ず日本語にしてください。'\
'ユーザーには変換後のテキストのみを回答してください。ユーザーには変換前のテキストを回答しないでください。'\
'$search_results$'
}
},
"knowledgeBaseId": "★ナレッジベースID★",
"modelArn": "arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-3-haiku-20240307-v1:0",
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"overrideSearchType": "HYBRID" # or SEMANTIC
}
},
},
},
)
return response["output"]["text"]
def lambda_handler(event, context):
# トリガーされたイベントからバケット名とオブジェクトキーを取得
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote(event['Records'][0]['s3']['object']['key'])
# 元のオブジェクトの内容を取得
response = s3.get_object(Bucket=bucket, Key=key)
original_txt = response['Body'].read().decode('utf-8')
# Bedrock処理コール
response_output = convert_text(original_txt)
# 新しいオブジェクト名を決める
new_key = ★新しいオブジェクト名★
# 書き換えた内容を新しいオブジェクトとしてS3にアップロード
bucket = ★変換後テキスト格納先S3バケット名★
s3.put_object(Bucket=bucket, Key=new_key, Body=response_output.encode('utf-8'))
print(f'Successfully uploaded {new_key} to {bucket}')
return {
'statusCode': 200,
'body': 'Object uploaded successfully'
}
sys.exit()
いざ出陣!
ついに変換前テキストが出陣する時が来ました。
今回はAWSコンソールのS3画面から、下記の「果物.txt」を変換前テキスト格納先にアップロードしました。
りんご バナナメロン 葡萄 Orange オレンジ パパイヤ ドーナツ 林檎はりんごです りんごは林檎です
エラー発生
下記のエラーとなりました。
[ERROR] ParamValidationError: Parameter validation failed: Unknown parameter in retrieveAndGenerateConfiguration.knowledgeBaseConfiguration: "generationConfiguration", must be one of: knowledgeBaseId, modelArn Unknown parameter in retrieveAndGenerateConfiguration.knowledgeBaseConfiguration: "retrievalConfiguration", must be one of: knowledgeBaseId, modelArn Traceback (most recent call last): File "/var/task/lambda_function.py", line 48, in lambda_handler response_output = convert_text(original_txt) File "/var/task/lambda_function.py", line 10, in convert_text response = boto3.retrieve_and_generate( File "/var/lang/lib/python3.12/site-packages/botocore/client.py", line 553, in _api_call return self._make_api_call(operation_name, kwargs) File "/var/lang/lib/python3.12/site-packages/botocore/client.py", line 962, in _make_api_call request_dict = self._convert_to_request_dict( File "/var/lang/lib/python3.12/site-packages/botocore/client.py", line 1036, in _convert_to_request_dict request_dict = self._serializer.serialize_to_request( File "/var/lang/lib/python3.12/site-packages/botocore/validate.py", line 381, in serialize_to_request raise ParamValidationError(report=report.generate_report())
boto3のバージョン更新履歴と思われるページを見てもいまいち分からず。
Claude 3 Haikuに聞いてみました。

認識できないAPIがある様子なので、最新のboto3をインストールしてLambdaレイヤーにセットすることにしました。
boto3インストールはAWS CloudShellから実施しました。
全量ではありませんがログは下記の通りです。
なお、最新のboto3はv.1-34-100でした。
[cloudshell-user@ip-xx-xxx-xxx-xx ~]$ mkdir boto3work
[cloudshell-user@ip-xx-xxx-xxx-xx ~]$ pip install -t ./boto3work boto3
Collecting boto3
Downloading boto3-1.34.100-py3-none-any.whl (139 kB)
|████████████████████████████████| 139 kB 3.6 MB/s
Collecting botocore<1.35.0,>=1.34.100
Downloading botocore-1.34.100-py3-none-any.whl (12.2 MB)
|████████████████████████████████| 12.2 MB 26.9 MB/s
Collecting jmespath<2.0.0,>=0.7.1
Downloading jmespath-1.0.1-py3-none-any.whl (20 kB)
Collecting s3transfer<0.11.0,>=0.10.0
Downloading s3transfer-0.10.1-py3-none-any.whl (82 kB)
|████████████████████████████████| 82 kB 413 kB/s
Collecting python-dateutil<3.0.0,>=2.1
Downloading python_dateutil-2.9.0.post0-py2.py3-none-any.whl (229 kB)
|████████████████████████████████| 229 kB 44.1 MB/s
Collecting urllib3<1.27,>=1.25.4
Downloading urllib3-1.26.18-py2.py3-none-any.whl (143 kB)
|████████████████████████████████| 143 kB 49.3 MB/s
Collecting six>=1.5
Downloading six-1.16.0-py2.py3-none-any.whl (11 kB)
Installing collected packages: six, urllib3, python-dateutil, jmespath, botocore, s3transfer, boto3
Successfully installed boto3-1.34.100 botocore-1.34.100 jmespath-1.0.1 python-dateutil-2.9.0.post0 s3transfer-0.10.1 six-1.16.0 urllib3-1.26.18
[cloudshell-user@ip-xx-xxx-xxx-xx ~]$ mv ./boto3work ./python
[cloudshell-user@ip-xx-xxx-xxx-xx ~]$ zip -r boto3-1.34.100.zip ./python
以下省略
zipファイルをダウンロード後、レイヤーを作成し、Lambdaにセットしました。
ということで、再度「果物.txt」をアップロードしてみました。
タイムアウト発生
エラーは解消されましたが、タイムアウトが発生しました。
2024-XX-XXXXX:XX:XX.XXXX XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX Task timed out after 3.02 seconds
Claude 3 Haikuから回答を得るまでに3秒以上掛かっているようなので、タイムアウトを30秒に変更してみました。
ということで、再々度、「果物.txt」をアップロードしてみました。
成功?
変換後テキストが作成されました!
中身を確認してみます。
りんご 黄色い果物メロン 紫色の丸くて小さい果物 オレンジ色の丸い果物 オレンジ 未知の果物 未知の果物 りんごはりんごです りんごはりんごです
惜しいですね。
質問するたびに回答精度が上がるかもしれないので、もう一度、変換前テキストをアップロードしてみました。
成功!
赤色の丸い果物 我が子がこよなく愛する黄色い果物、緑色の丸くて大きい果物 紫色の丸くて小さい果物 オレンジ色の丸い果物 オレンジ色の丸い果物 未知の果物 未知の果物 赤色の丸い果物 赤色の丸い果物
空白行を詰められてしまいましたが、、、
2回目で想定通りに変換することが出来ました!
まとめ
良かった点は、新技術に触れることが出来たことは勿論として、業務経験が浅くても頑張ればモノづくりが出来ることに気づけたことです。
反省点としては、エラーとなってしまったboto3バージョン不足については事前に気づくべきでした。
また、後から気づいたのですが、今回のやってみたをやってみる前に下記の記事を見ておくべきでした。
ガイドラインに則ったプロンプトであれば、1回目で想定通りに変換することが出来たかもしれませんね。