

こんにちは。SCSKの島村です。
AIMLの勉強をしていると、「機会学習モデルを評価してみよう!!」「でもどうやってモデルを評価するの??」「そもそも良いモデルってなに??」 そんな風に思われる方も多いと思います。
作成した機械学習モデルを評価する際には、単純な正答率や精度のみを観察するのではなく、各々の問題に対して、それに即した適切な評価を行うことがとても重要です。
本ブログは、こんな方に是非読んでいただきたい内容となっております。
今回は、機会学習モデルの中でもよく利用される「回帰」「分類」におけるモデルの評価方法・評価指標についてご紹介いたします。
回帰問題の評価指標
回帰問題の評価指標は、予測精度を客観的に評価する必要があります。
実際の回帰問題のモデル性能評価の際には、1つの評価指標だけではなく複数の評価指標を用いることで、できるだけ多面的な分析を行います。
以下に、回帰における評価指標の一部を記載します。
|
評価指標(一部)
|
説明
|
式
|
|---|---|---|
| MAE(Mean Absolute Error)
:平均絶対誤差 |
正解値と予測値との間の平均絶対値のこと。この指標の範囲はゼロから無限大までで、値が小さいど高品質のモデルである。
*誤差の幅に比例して重要視する |
|
| MSE(Mean Squared Error)
:平均二乗誤差 |
正解値と予測値の二乗和の平均のこと。0に近いほどよく、外れ値に過剰に反応してしまう。 |
|
| RMSE(Root Mean Squared Error)
:平均平方二乗誤差 |
正解値と予測値の平均二乗誤差の平方根 MAEよりも外れ値の影響を受けやすいため、大きな誤差が心配なあ場合はRMSEのほうがより便利な評価指標
*大きな間違いをより重要視する |
|
| RMSLE(Root Mean Squared Logarithmic Error)
:対数平均平方二乗誤差 |
*幅ではなく、誤さの割合を重要視かつ上振れよりも下振れを重要視
*小規模のレンジの誤差を重要ししたい場合かつ下振れを抑えたいケース |
|
| MAPE(Mean Absolute Percentage Error)
:平均絶対パーセント誤差 |
各データに対して、正解値と予測値との差を、正解値で割った値の絶対値を計算し、その総和をデータ数で割った値
*誤差の割合に比例して重要視 *正解値に値が小さいものが含まれているケースには考慮が必要 |
|
| R Square
:決定係数 |
正解値にどれぐらい当てはまるかの割合(通常は0~1.0=100%)
*全データが正確に捉えられている場合に、そのままモデルの性能を表すパラメータ *データにノイズが多いと勝手にスコアが良くなる傾向 |
|
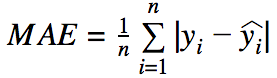
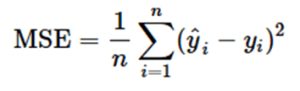
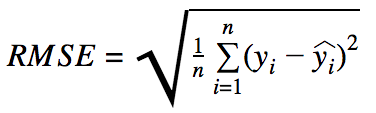
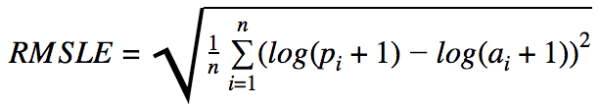
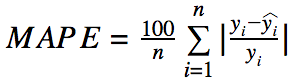
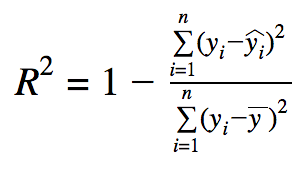
回帰における評価指標の一部をご紹介しました。今回紹介したもの以外にも評価指標は多数存在しています。
重要なポイントとしては「評価したいモデルに対して、目的に応じて適切に使い分ける必要がある」ということです。
例えば)大きな誤差(正解値と予測値の差)を出すサンプルをできるだけ少なくしたい場合はRMSEを使用するが、全サンプルの誤差を平等に評価して、サンプル全体の誤差をできるだけ小さくしたい場合はMAEを使用するなど。
また、評価指標は入力データに基づいて計算されるためデータそのものについても重要となります。これらのことに気を付けて、モデルの評価を行うことが大切です。
分類問題の評価指標
分類問題の評価指標としてよく用いられる「混合行列」について紹介します。混合行列は予測精度を客観的に評価することが可能となります。
混同行列(Confusion Matrix):2値分類問題において、予測(推定値)と実際の結果(真の値,実測値)を行列形式にまとめたもの。
昨今のパンデミック(PCR検査)を例に混合行列を考えてみます。
なお、PCR検査における「予測」とは、検査結果のことで、「実際の結果」とは、実際にその人が陽性であるか陰性であるかを指す。
- 真陰性(True Negative:TN):検査で陰性とされ、実際に陰性である場合
- 偽陰性(False Negative:FN):検査で陰性とされたものの、実際には陽性である場合
- 偽陽性(False Positive:FP):検査で陽性とされたものの、実際には陰性である場合
- 真陽性(True Positive:TP):検査で陽性とされ、実際に陽性である場合
| 混合行列
(Confusion Matrix) |
予測(推定値) | ||
|---|---|---|---|
| 負(Negative) |
正(Positive) |
||
| 実際の結果
(真の値,実測値) |
負(Negative) |
真陰性 (True Negative:TN) |
偽陰性
(False Negative:FN) |
| 正(Positive) |
偽陽性 (False Positive:FP) |
真陽性
(True Positive:TP) |
|
正答率(Accuracy):「すべての予測のうち、正解した予測の割合」
= TP +TN / TP + FP + TN + FN
適合率(Precision):「陽性と予測したもののうち、実際に陽性である割合」
= TP / TP + FP
再現率(感度,Recall,True Positive Rate,TRP):「実際に陽性であるもののうち、正しく陽性と予測できたものの割合」
= TP / TP + FN
F値(F-measure,F1値,F1-measure):対照的な特徴を持つ適合率と再現率の調和平均
= 2 × Precision × Recall / Precision + Recall
特異度(Specificity,True Negative Rate,TNR):「実際に陰性であるもののうち、正しく陰性と予測できたもの」
= TN / TN + FP
偽陰性率(False Positive Rate,FPR):「実際に陰性であるもののうち、誤って陽性と予測したものの割合」
= FP / TN + FP
** 何を重視するかによって選択する指標が変わります。
例えば、PCR検査の例では陰性患者を要請と誤診するより、陽性患者を陰性と誤診してしまう方が一大事に繋がりかねません。そのため、陽性患者を見逃さずどれだけ検出でき高野指標を選択する必要があります。
このように、目的に応じて評価指標を適切に選択することが重要となります。
最後に
今回は「回帰」「分類」における機会学習モデルの評価方法・評価指標についてご紹介させていただきました。
今後とも、AIMLに関する情報やGoogle CloudのAIMLサービスのアップデート情報を掲載していきたいと思います。
最後まで読んでいただき、ありがとうございました!!!