

 本記事は TechHarmony Advent Calendar 2024 12/22付の記事です。 本記事は TechHarmony Advent Calendar 2024 12/22付の記事です。 |
こんにちは。今回がTechHarmony初投稿の、SCSK新人の さと です。
「TechHarmony Advent Calendar 2024」および「新人ブログマラソン 2024」のダブルエントリーでお届けします。
突然ですが、皆さんが初めて出会ったAIはなんでしょうか?何をもってAIとするか(あるいは、そもそも知能とは何か)は議論の余地はありますが、私が人生で初めて触れた「AIらしいAI」といえばSiriですね。アプリを開いたりタイマーをセットしたり、ジョークも言える、そんなアシスタントが電話の中にいるのが面白くて、家電量販店に入り浸っていた小学生時代を思い出します。
時は流れて2022年の末にはChatGPTが登場し、世間に衝撃を与えました。あれからさらに2年が経ち、モデルを大きくすることによる性能向上に限界が見えてきたなどもと言われている生成AIの技術ですが、今もなおRAG(検索拡張生成)や組み込みによるCoT(思考の連鎖)などによる機能強化が続いていますね。
そんな中、先日のre:Invent 2024においてAmazon Bedrockから新たにAIエージェント同士を連携させるという機能が発表されましたので、今回はそのご紹介です。
新発表!Amazon Bedrock Multi-Agent Collaborationの概要
そもそもAIエージェントって…?
とはいえ、そもそもエージェントって何でしょう?私自身、それが具体的に何を指すかなどかは考えたことがありませんでした。いろいろと定義はあるようですが、ここでは説明にあたり、AWSの言葉を借りようと思います。
人工知能 (AI) エージェントは、環境と対話し、データを収集し、そのデータを使用して自己決定タスクを実行して、事前に決められた目標を達成するためのソフトウェアプログラムです。目標は人間が設定しますが、その目標を達成するために実行する必要がある最適なアクションは AI エージェントが独自に選択します。
エージェントでないAIと大きく違うところというと、自律的に環境と相互のやり取りができる点でしょうか。Bedrockのエージェントでは、これらはLambda関数の実行やRAGによるデータ取得といった仕組みによって実現されています。
新機能でできるようになったこと

さて、今回の発表ではMulti-agent collaboration(複数エージェントによる協調)機能が発表されました。その概要は以下の通りです。
* 画像はAWS公式ブログに掲載のものを基に作成
- スーパーバイザーエージェントとサブエージェントによる分担
- ユーザーから受けとったリクエストをスーパーバイザーがタスクへと切り分け、サブエージェントに割り当てて指揮をとる。
- サブエージェントは各領域の専門家として振る舞い、データ取得や分析の結果をスーパーバイザーへ返す。
- スーパーバイザーは各サブエージェントから受け取った結果をまとめ直し、ユーザーへの回答とする。
- 設定の容易さ
- 数クリックで既存のエージェントをサブエージェントとして設定し、より複雑なワークフローに対応可能
- ルーティング付きスーパーバイザーのオプション
- このオプションをオンにすると、スーパーバイザーは単純なリクエストが来た場合、これを直接サブエージェントへ受け渡すことで処理効率を最適化する。複雑な処理に対しては、スーパーバイザー側で切り分け処理を行ったうえでサブエージェントへ割り当てる。
実際に動かしてみる
それでは、早速このMulti-agent collaboration機能を使っていきましょう。
今回は、上で紹介したAWSの公式ブログでのデモンストレーションを参考に、エージェントを作成します。
エージェント構成
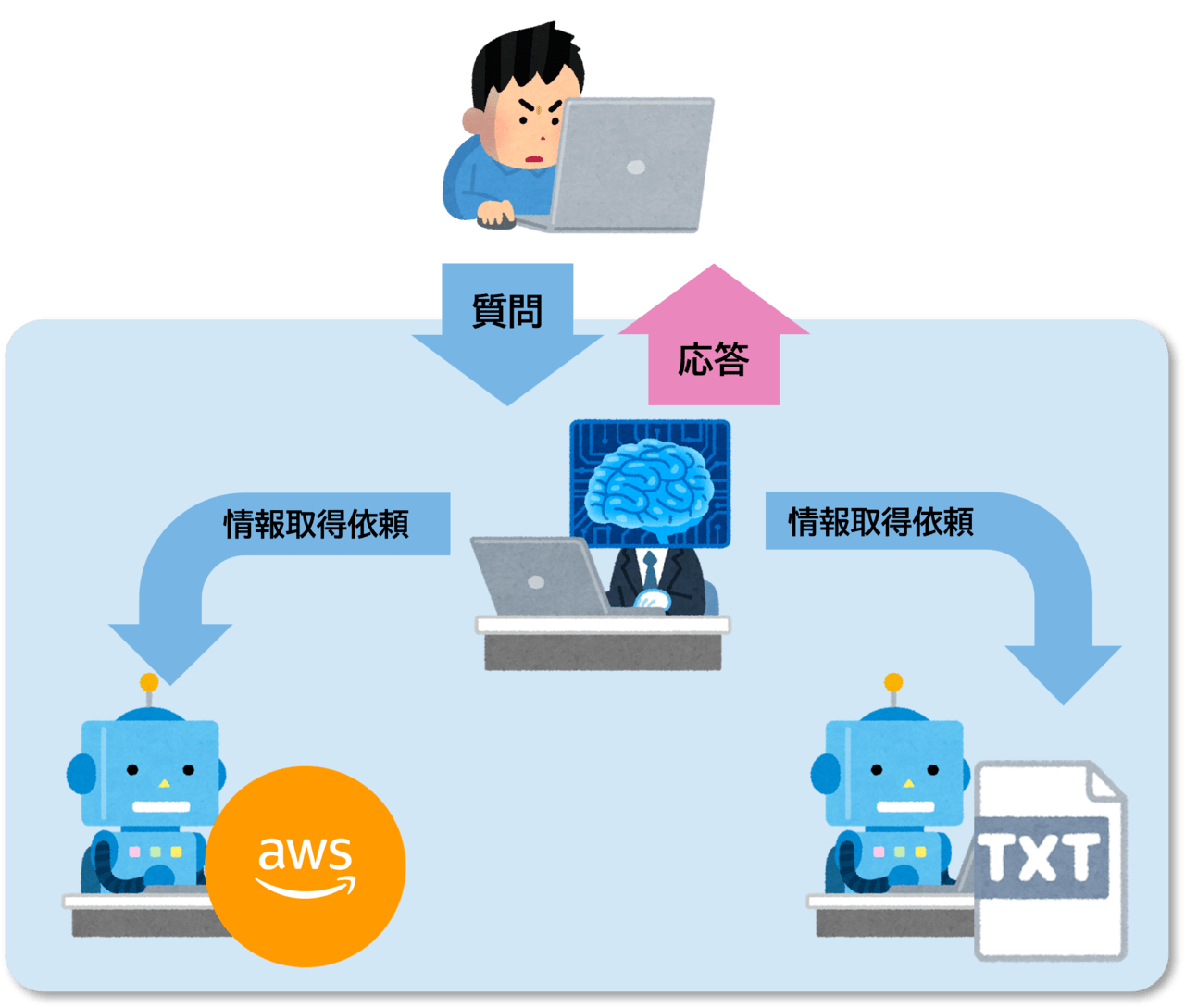
今回は、複数のエージェントで協調してBedrock質問回答ボットを実現します。
右図のように、一方のサブエージェントがWebからAmazon Bedrockに関する情報を取得、もう一方のサブエージェントは予め登録した対象読者の年齢別スタイルガイドから文章の書き方に関する情報を提供し、それらをスーパーバイザーエージェントがとりまとめるという構成です。
サブエージェントの作成
まずは、専門家として働くサブエージェントを2つ設定していきましょう。この作業は、これまでの単独で動くエージェントを設定するときと同じものです。
AWSナレッジ取得エージェント
ナレッジベースの設定
情報を取得するエージェントを作成するにあたり、先にナレッジベースを設定する必要があります。ナレッジベースの設定画面からデータソースとしてWeb Crawlerを選択します。
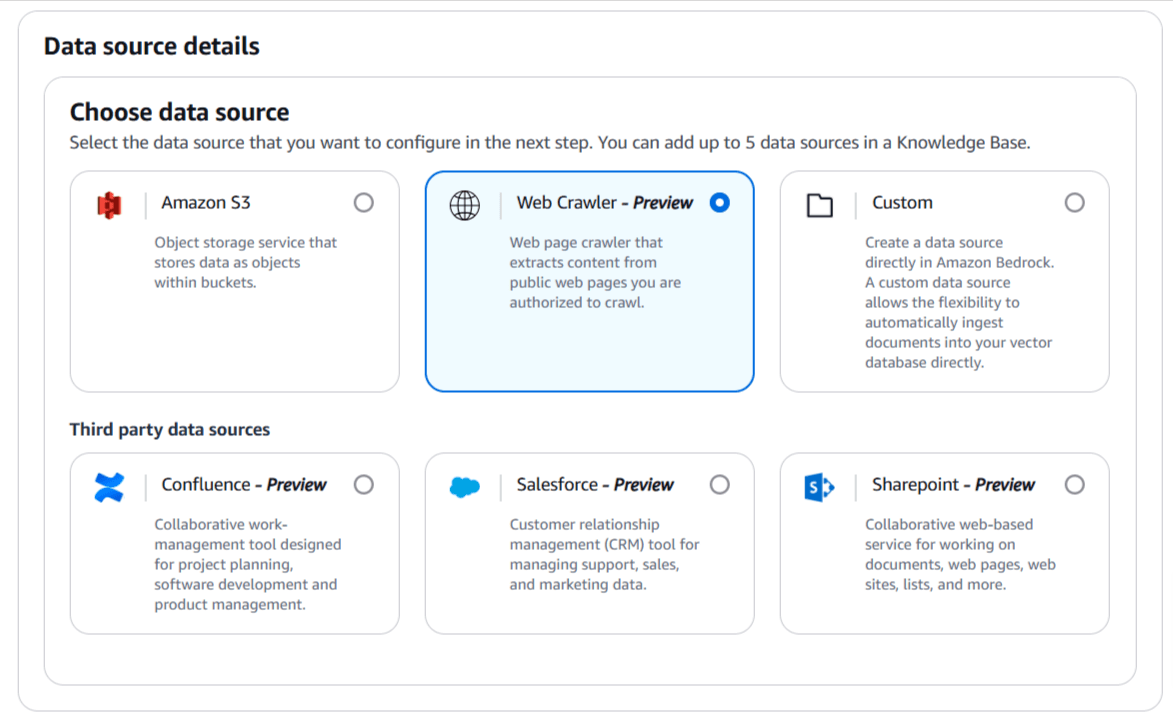
次に、クローリングを行うURLを入力します。今回は、Amazon Bedrockのユーザーガイドのページを指定しました。埋め込みモデルにはAmazonのTitan Embeddings G1を選択し、その他の設定はデフォルトのままとします。
データソースを登録したら、同期処理(データをベクトル埋め込みに変換し、クエリ可能な状態にする処理)を行う必要があります。データソース一覧から「同期」ボタンを押し、しばらく待ちます。数分から数時間かかるという表示が出ますが、今回は10分弱で完了しました。
ナレッジベースをエージェントに追加
ナレッジベースの作成が完了したので、次はこれをエージェントに追加します。「Amazon Bedrock」>「エージェント」から「エージェントを作成」ボタンを押し、エージェントビルダーを開きます。

ナレッジベースの設定項目から、作成したナレッジベースを登録して完了…かと思いきや、次のような表示が出てしまいました。
どうやら、一旦エージェントの設定を保存してからナレッジベースを設定する必要があるようです。保存ボタンを押し、その後再度ナレッジベースを登録することでエラーは解消しました。その他の設定はデフォルトのままにしました。
エージェントを単独で試してみる
AWSの情報を取得するエージェントの設定が終わったので、一旦ここで検索機能が正しく働いているか試してみましょう。画面上部の「準備」ボタンを押すと、チャット形式でエージェントを試すことができるようになります。
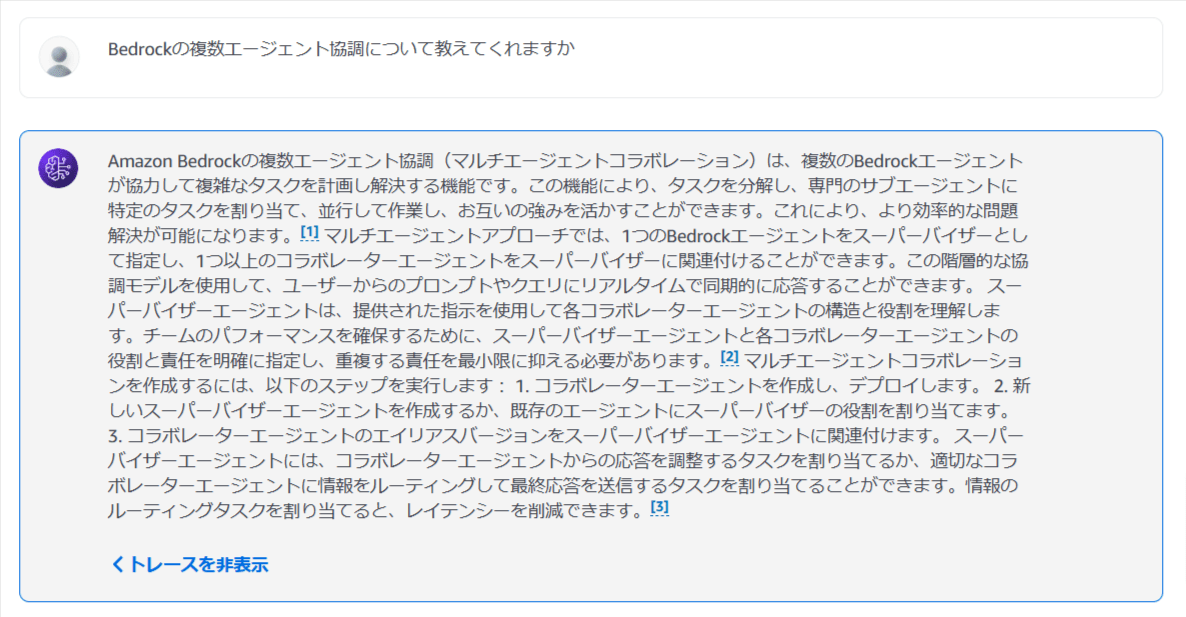
元のモデルにないはずの最新の機能に関する回答が、ソース付きで返ってきました。バッチリですね。
 マルチエージェントに関しては知らないものの、学習時点の知識でマルチエージェント機能を実現する方法について教えてくれました。
マルチエージェントに関しては知らないものの、学習時点の知識でマルチエージェント機能を実現する方法について教えてくれました。スタイル取得エージェント
同様に、スタイルを取得するエージェントの設定を進めます。読み込ませるスタイルガイドはChatGPTに書いてもらいました。
年齢別説明スタイルガイド(抜粋)
1. 小学生(6~12歳)
難易度: 初級
目指すスタイル: シンプルで具体的な言葉を使い、短い文で説明する。興味を引く比喩や例を活用。
ポイント:
– 難しい言葉は避け、もし使用する場合は必ずその意味を説明する。- 親しみやすい例を挙げる(例: 「S3バケットはデータを保存するための大きな箱みたいなもの」)。
– 1つの文で1つのアイデアだけを伝える。
具体例:
– 「コンピューターにデータを保存する場所をバケットと呼びます。バケットはたくさんのファイルをしまえる箱のようなものです。」
– 「バケットを作るには、名前を決めてクリックするだけです!」
2. 中学生(13~15歳)
難易度: 初級~中級
目指すスタイル: 少し複雑な言葉を使いながらも、文を短めに保ち、具体例や現実世界との関連を強調する。
ポイント:
– 少し抽象的な概念も具体例とセットで説明。
– 「なぜその作業が必要なのか」を簡単に補足。
– 手順を順序立てて、明確な指示を出す。
具体例:
– 「Amazon S3は、データを安全に保存できるオンラインの倉庫のようなものです。例えば、写真や動画を保管するために使えます。」
– 「バケットを作るには、まず名前を決めます。その名前は、ほかの誰とも同じではないユニークなものにしてください。」
[…]
残りの手順は基本的にAWSのナレッジを取得するエージェントと変わらないため詳しい説明は割愛しますが、こちらのデータはテキスト形式で保存し、カスタムデータソースとして直接取り込むことでナレッジベースに登録しました。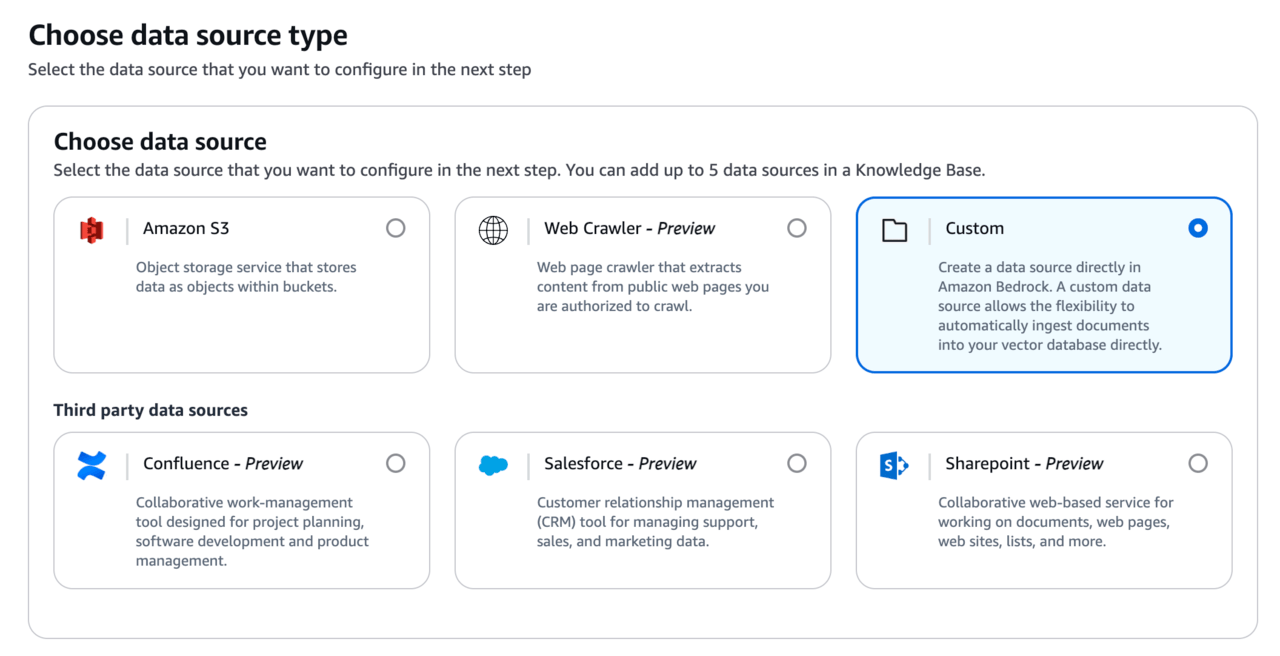
スーパーバイザーエージェントの作成
最後に、これらのエージェントを取りまとめるスーパーバイザーエージェントを設定していきましょう。エージェントビルダーからMulti-agent collaborationをオンにし、Agent Collaboratorとしてサブエージェントを追加していきます。今回は、ルーティング機能はオフとしています。

エージェントを追加する設定画面は上の通りです。協調するエージェントのほかに、Agent alias(エージェントの特定のバージョン)、 Collaborator Name(スーパーバイザー側で用いる呼び名)がすべて必須項目となっており、このため一度それぞれのサブエージェント側の設定に戻り、エイリアスを作成する必要がありました。2つのサブエージェントの呼び名はそれぞれaws-expert, style-coachとしました。
最後に、エージェントのプロンプトを入力して完成です。
完成!果たして…
エージェントが完成したので、試してみましょう。まずは、年齢を指定せずに質問をしてみます。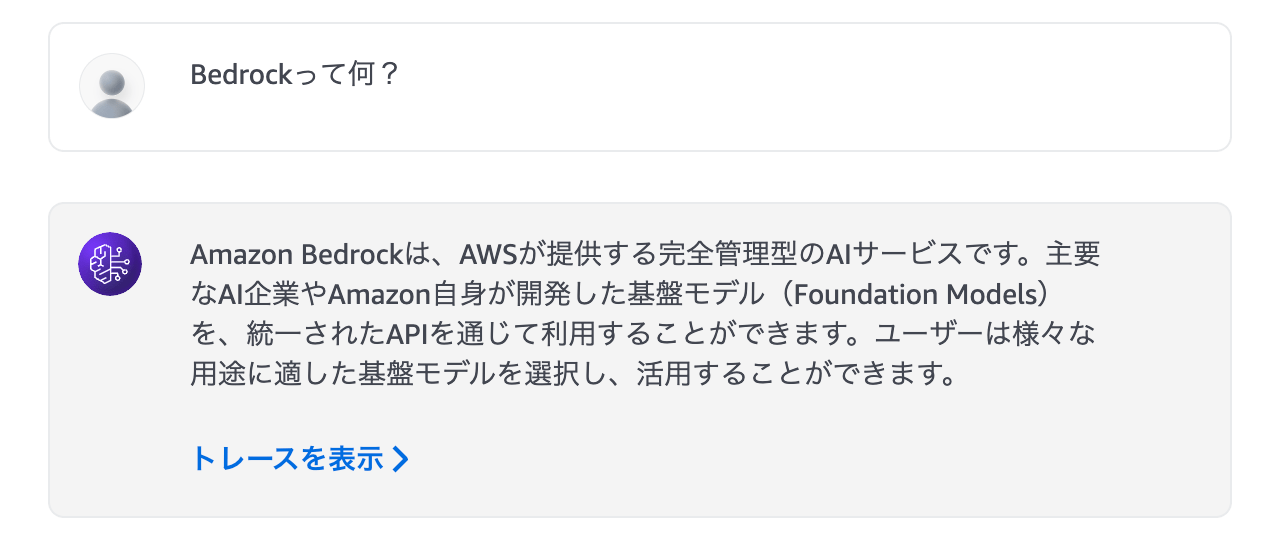
スーパーバイザー、サブエージェントを通じて、情報が返ってきました。回答の下部にある「トレースを表示」から、どのようにエージェントが動いたのかタイムライン形式で見てみましょう。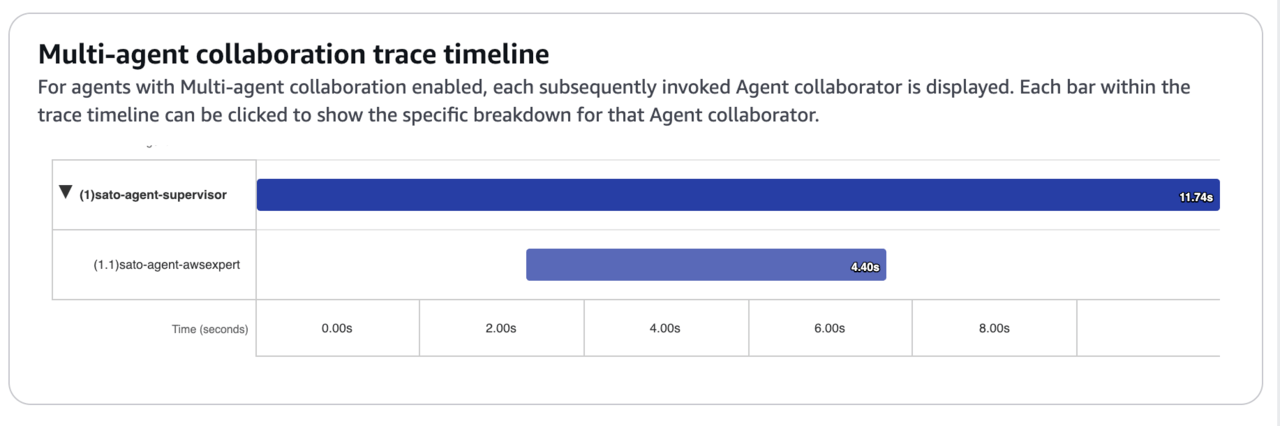
上のように、サブエージェントはAWSの情報を取得するエージェントだけが稼働していたことが確認できます。では、年齢層を指定して質問した場合はどうなるでしょうか。

読み込ませたスタイル通り、比喩や例が多く用いられていることが確認できます。こちらでも、トレースを見てみましょう。

ちゃんと、2つのサブエージェントが起動しています。スーパーバイザーエージェントによって、タスクに応じた適切な振り分けがなされていることが分かります。ついでに、中学生向けの説明もお願いしてみましょう。

説明を通して比喩を多く使っていた小学生向けの説明に対し、より具体的な説明になりました。
おわりに
いかがでしたか?Bedrockに触れるのは今回が初めてでしたが、GUIでシンプルに設定を進められる印象でした。今回は簡単のためにLambdaとの連携は行いませんでしたが、工夫次第では単独のエージェントよりもずっと複雑なタスクを実行できる可能性を感じました。
最後までお読みいただき、ありがとうございました。良いクリスマス&新年をお迎えください!