

こんにちは、SCSKの梅沢です。AWSが公開しているAmazon SageMaker(アマゾンセージメイカー)のチュートリアルを実施してみました。チュートリアルをより深く理解するために、手順の裏で何が行われているのか学習・整理したことを記事にしてみます。
Amazon SageMakerとは
機械学習モデルを迅速に構築、トレーニング、デプロイできるフルマネージド型サービスです。インターネット上に多くの良い紹介記事がありますが、まずはAWSが公開しているチュートリアルを実施して、使い方を一通り把握してみました。
Amazon SageMaker | AWS を使用した機械学習モデルの構築およびトレーニング、デプロイの方法
内容は、SageMakerで機械学習の一つであるXGBoostアルゴリズムを使用して、機械学習モデルを構築するチュートリアルになっています。まず、一連の流れをする前に、今回のチュートリアルで作るアーキテクチャの概要を下記に引用します。
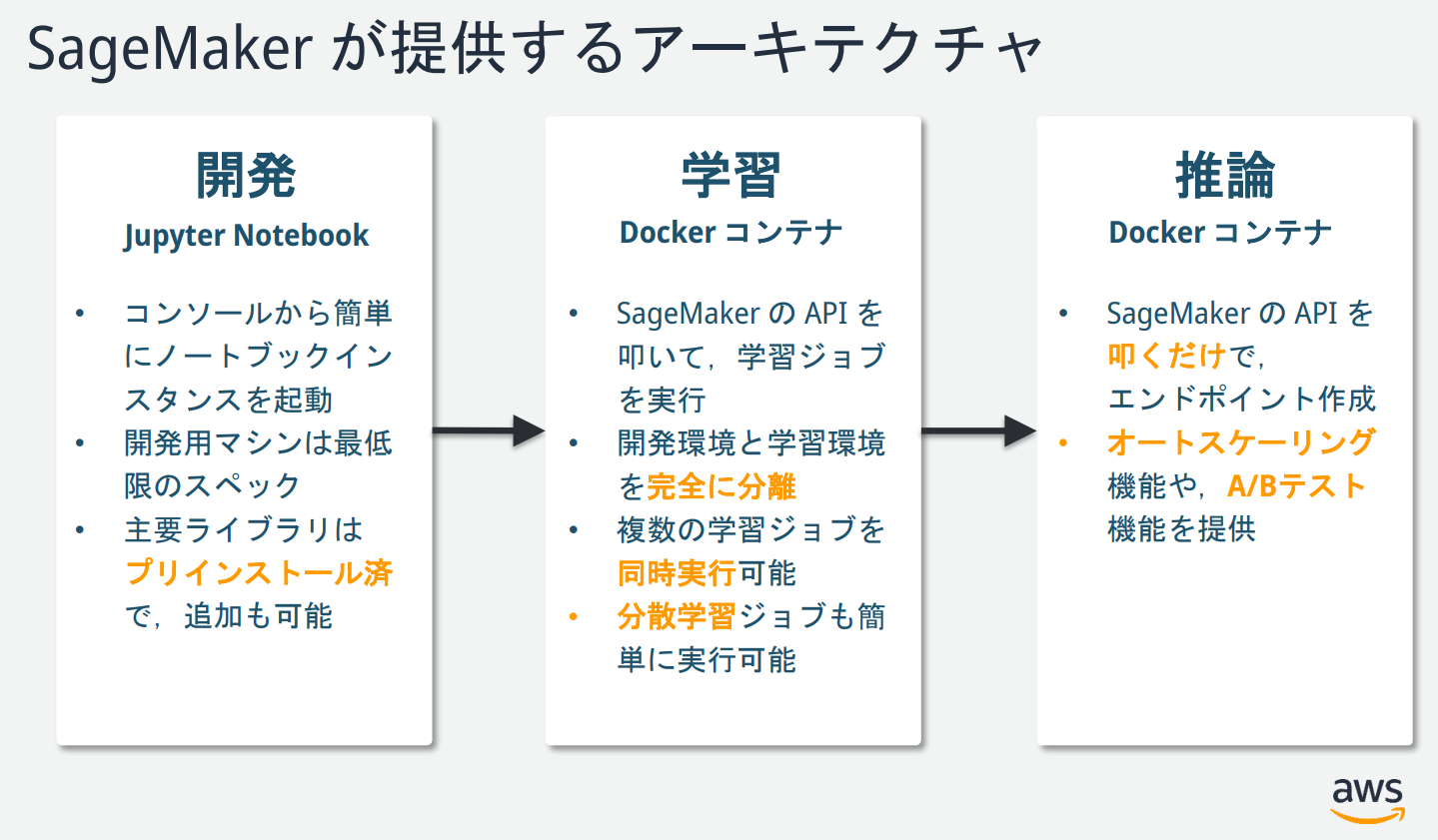
引用:(https://blog.usize-tech.com/contents/uploads/2021/08/20190515SageMaker_handson.pdf)
ステップ 1.データ準備用の Amazon SageMaker ノートブックインスタンスを作成する
データのダウンロードと処理に使用するAmazon SageMaker ノートブックインスタンスの作成、学習データ等を配置するAmazon Simple Storage Service(Amazon S3)、ノートブックインスタンスがS3にアクセスするためのAWS Identity and Access Management (IAM) ロールを作成しています。
※詳細は上記URLのAWSのチュートリアルをご確認し、手順通りに実施ください。
ステップ 2.データの準備
このステップでは、”機械学習モデルのトレーニングに必要なデータを前処理し、そのデータを Amazon S3 にアップロードします”と記載されています。作成したJupyter ノートブックで、指定したコマンドを実行する手順になっています。
ライブラリのインポート
このステップで、コードを張り付けて実行する手順になっていますが、コードの中身は何をしているのか一部見てみます。まずライブラリのインポートの部分です。(言語はpythonです)
>c.Jupyter ノートブックの新しいコードセルで、以下のコードをコピーして貼り付け、[Run] (実行) を選択します。
# import libraries import boto3, re, sys, math, json, os, sagemaker, urllib.request from sagemaker import get_execution_role import numpy as np import pandas as pd import matplotlib.pyplot as plt from IPython.display import Image from IPython.display import display from time import gmtime, strftime from sagemaker.predictor import csv_serializer
最初に,”boto3″とは何でしょうか。ローカルマシン内で、Jupyter ノートブックを使用して学習するだけですと必要のないライブラリです。検索してみると”boto3 を使用することで、Python のアプリケーション、ライブラリ、スクリプトを AWS の各種サービスと容易に統合できる。”(AWS SDK for Python | AWS (amazon.com)) とあります。boto3とはPythonからAWSを操作するためのライブラリとなっています。
一部省略しますが、次に”sagemaker”とは何でしょうか。これはAmazon SageMaker で機械学習モデルをトレーニングおよびデプロイするためのオープンソースライブラリです。SageMaker ノートブックインスタンスなるものをステップ1で作成したのに、なぜ改めてsagemakerのライブラリをimportしているのか?と思いますが、SageMaker ノートブックインスタンスとは、あくまでJupyter ノートブックがインストールされたインスタンスのようです。
IAMロール及び、前処理したデータを配置するS3の定義
次のコマンドでIAMロールの定義及び、前処理したデータを配置するS3のprefixを定義等をしています。IAMロールは後の”ステップ 3.ML モデルをトレーニングする”で、sagemaker.estimator.Estimatorクラスで使用するロールです。SageMaker がトレーニング結果の読み取り、推論の際にモデルアーティファクトを Amazon S3 から呼び出す、トレーニング結果を Amazon S3 に書き込む等をするために使用するロールとなっています。
# Define IAM role role = get_execution_role() prefix = 'sagemaker/DEMO-xgboost-dm' my_region = boto3.session.Session().region_name # set the region of the instance
XGBoost containerの作成
次にXGBoost containerの作成をしています。あくまでSageMaker では、ノートブックインスタンスは開発で利用し、学習や推論にはDockerコンテナを用いるという構成になっています。sagemaker.image_uris.retrieve(“xgboost”, my_region, “latest”)で、指定された引数に一致するDockerイメージのECRのURIを取得し、コンテナをビルドしています。
# this line automatically looks for the XGBoost image URI and builds an XGBoost container.
xgboost_container = sagemaker.image_uris.retrieve("xgboost", my_region, "latest")
print("Success - the MySageMakerInstance is in the " + my_region + " region. You will use the " + xgboost_container + " container for your SageMaker endpoint.")
ちなみに、Amazon SageMaker が提供する各アルゴリズムのDockerイメージのURIは下記の通り決まっているようです。
Dockerレジストリパスとサンプルコード – Amazon SageMaker
リージョン毎、アルゴリズム毎に用意されたDockerイメージのURIを見に行っているのですね。私は東京リージョンを指定したので、jupyter上でxgboost_containerの中身をみると、
'501404015308.dkr.ecr.ap-northeast-1.amazonaws.com/xgboost:latest'
が返されました。
学習データや、推論結果を格納するS3バケットの作成
下記でS3の任意の名前を指定して、boto3を使ってS3バケットを作ります。こちらに学習データや、推論結果が格納されることになります。チュートリアルは’us-east-1’指定でしたが、東京リージョン’ap-northeast-1’でもチュートリアル実施可能です。
bucket_name = 'your-s3-bucket-name' # <--- CHANGE THIS VARIABLE TO A UNIQUE NAME FOR YOUR BUCKET
s3 = boto3.resource('s3')
try:
if my_region == 'us-east-1':
s3.create_bucket(Bucket=bucket_name)
else:
s3.create_bucket(Bucket=bucket_name, CreateBucketConfiguration={ 'LocationConstraint': my_region })
print('S3 bucket created successfully')
except Exception as e:
print('S3 error: ',e)
ステップ 3.ML モデルをトレーニングする
データの再フォーマットを手順aに従い実施した後、下記で学習のセッションを開始してsagemaker.estimator.Estimatorクラスのインスタンスを作成し、モデルのハイパーパラメーターを定義しています。
sess = sagemaker.Session()
xgb = sagemaker.estimator.Estimator(xgboost_container,role, instance_count=1, instance_type='ml.m4.xlarge',output_path='s3://{}/{}/output'.format(bucket_name, prefix),sagemaker_session=sess)
xgb.set_hyperparameters(max_depth=5,eta=0.2,gamma=4,min_child_weight=6,subsample=0.8,silent=0,objective='binary:logistic',num_round=100)
そして、学習させます。
xgb.fit({'train': s3_input_train})
ステップ 4.モデルのデプロイ
モデルをAmazon Elastic Compute Cloud (Amazon EC2) にデプロイし、アクセスできる SageMaker エンドポイントを作成しています。
xgb_predictor = xgb.deploy(initial_instance_count=1,instance_type='ml.m4.xlarge')
チュートリアルでは、その後、作成したxgb_predictorを指定してのモデル予測、ステップ 5.モデルの性能評価を進める手順になっております。
【まとめ】
ここまでで、SageMakerを使用して学習する際に裏で何が行われているのかを簡単に見てみました。チュートリアルに沿ってコマンドを実行するだけよりかは、記憶に残りやすいかと思います。
次は、SageMakerのCI/CDについて記事を書いてみようと思います。