

どうも、子育て支援猫型ロボットの実現を心待ちにしている寺内です。
ついにAmazon Bedrock が2023年9月29日に一般公開されました。

Amazon Bedrockは、複数の機械学習モデルを共通的なAPIでアクセスできるサービスです。いわば機械学習モデルのエコシステムをAWSは構築しようとしていると考えられます。
さっそくboto3を使って、APIアクセスをしてみましょう。
準備
Amazon BedrockのAPIを使い始める前に以下の準備を行います。
IAMポリシーでの権限設定
APIアクセスに使用するアクセスキーの所有IAMユーザに、以下のポリシーをアタッチします。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "bedrock:*",
"Resource": "*"
}
]
}
機械学習モデルの有効化
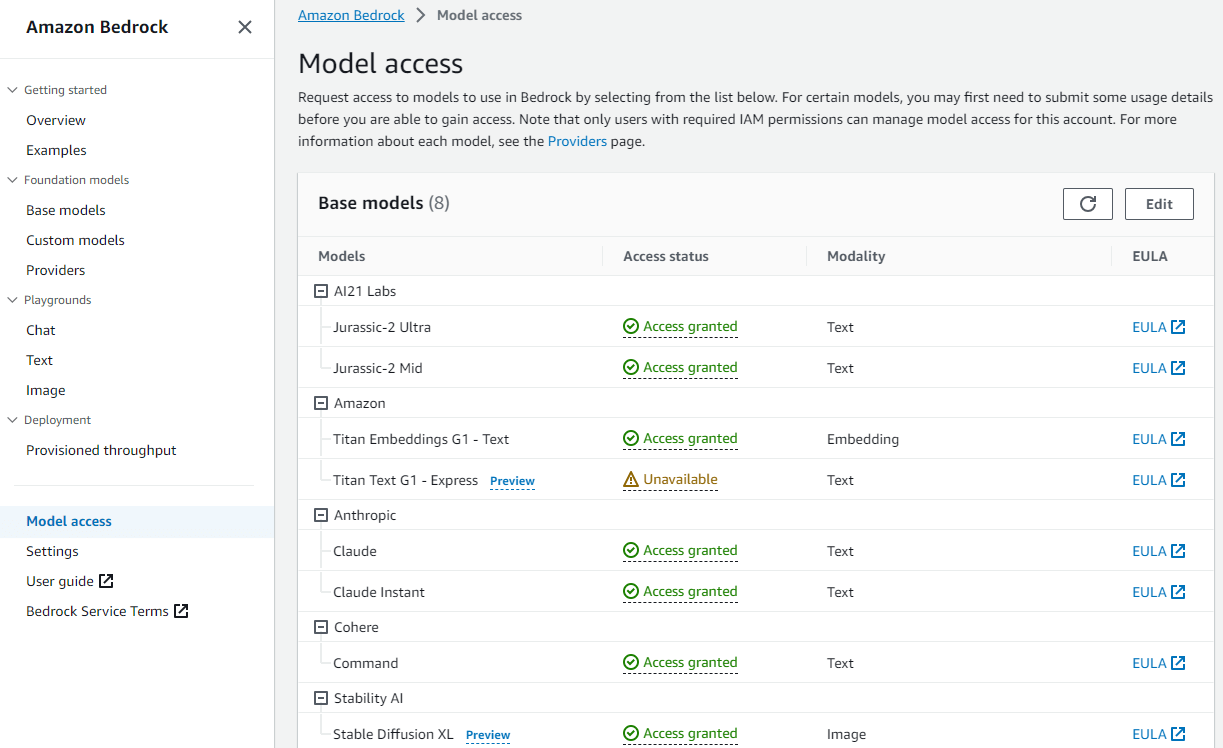
AWSマネジメントコンソールでAmazon Bedrockサービスの管理画面を出し、使用したいモデルの有効化を行います。
- 左のメニューから、”Model access” を選びモデル一覧を出します。
- 各モデルのEULA(End-User License Agreement:使用許諾契約)を確認します。
- 右上のEditボタンで、使用したいモデルを選択し有効化します。
- 以下のように、”Available” から “Access granted” に変われば、利用可能となります。
boto3のバージョンアップ
pythonプログラムを実行する環境において、boto3をバージョンアップもしくはインストールします。
Amazon Bedrockのサポートをしているboto3バージョンは、1.28.57 以上となります。
既にboto3がインストール済であれば、以下のコマンドでバージョンアップします。
$ pip install --upgrade boto3新規にインストールする場合は、以下の手順をご参照ください。

実行
では早速使ってみましょう。使用するモデルは、以下の2つです。
- AI21 Labs の Jurassic-2 Ultra v1
- Anthropic の Claude v2
Amazon Titanは、Titan Embeddings Generation 1 (G1) については公開済ですが、Titan Text Generation 1 (G1) は2023年10月1日時点でまだ未公開です。Titan Embeddings Generation 1 (G1) はテキストでの回答はせず、ベクトルデータのみ返すため、LangChainとの連携が必須となりますので、今回は試しませんでした。
ここで紹介するプログラムは、Amazon Bedrock ドキュメントのサンプルプログラムをベースにして若干の修正をしています。
- アクセス権はSTS一時認証のプロファイルを使用
- リージョンは、全てのモデルが揃っているバージニア(us-east-1)を使用
Jurassicの実行プログラム
import boto3
import json
session = boto3.Session(profile_name='sts')
bedrock = session.client(service_name='bedrock-runtime',
region_name='us-east-1')
body = json.dumps({
"prompt": "ブラックホールの構造を教えてください。",
"maxTokens": 200,
"temperature": 0.5,
"topP": 0.5
})
modelId = 'ai21.j2-ultra-v1'
accept = 'application/json'
contentType = 'application/json'
response = bedrock.invoke_model(
body=body,
modelId=modelId,
accept=accept,
contentType=contentType
)
response_body = json.loads(response.get('body').read())
# text
print(response_body.get("completions")[0].get("data").get("text"))
Jurassic実行結果
$ python jurassic.py
ブラックホールは宇宙にある暗黒の巨大な結晶の中に閉じ込められた場所です。 宇宙には数多くのブラックホールが存在しますが、最も重要なのは、銀河の中心にある「銀河のブラックホール」です。 銀河のブラックホールは、銀河の中心にある巨大な結晶の中に閉じ込められています。 この結晶は銀河の中心にある超重力の場所です。 銀河のブラックホールは、銀河の中心にある超重力の場所で、銀河の中心にある巨大な結晶の中に閉じ込められ
Claudeの実行プログラム
import boto3
import json
session = boto3.Session(profile_name='sts')
bedrock = session.client(service_name='bedrock-runtime',
region_name='us-east-1')
body = json.dumps({
"prompt": "\\n\\nHuman:ブラックホールの構造を教えてください。\\n\\nAssistant:",
"max_tokens_to_sample": 300,
"temperature": 0.1,
"top_p": 0.9,
})
modelId = 'anthropic.claude-v2'
accept = 'application/json'
contentType = 'application/json'
response = bedrock.invoke_model(
body=body,
modelId=modelId,
accept=accept,
contentType=contentType
)
response_body = json.loads(response.get('body').read())
# text
print(response_body.get('completion'))
Claude実行結果
$ python claude.py
ブラックホールの基本的な構造は以下の通りです。
- ブラックホールの中心には重力が非常に強い「奇点」がある。この奇点では、物理法則が破綻する。
- 奇点を取り囲む「事象の地平面」という球状の境界がある。この内側では光さえも脱出できない。事象の地平面の内側がブラックホールそのもの。
- 事象の地平面のすぐ外側には「アククレーションディスク」がある。これはブラックホールに吸い込まれたガスが高速で回転する円盤状の構造。
- さらに外側には強力な磁場と、ブラックホールの両極から噴出する相対論的ジェットがある。
- ブラックホールに落ちていく物質は、スパゲティ化現象に
Amazon Bedrockの良いところ
さて、上記2つのプログラムを見比べてください。違いは以下3つです。
1. 10行目のプロンプトの文字列。同じ質問をしていますが、その書式が違います。
[Jurassic] "prompt": "ブラックホールの構造を教えてください。",
[Claude] "prompt": "\\n\\nHuman:ブラックホールの構造を教えてください。\\n\\nAssistant:",
2. 11行目の推論パラメータです。同じパラメータですが、名称が異なります。
[Jurassic] "maxTokens": 200,
[Claude] "max_tokens_to_sample": 300,
3. 30行目の出力文章の取得方法です。
[Jurassic] print(response_body.get("completions")[0].get("data").get("text"))
[Claude] print(response_body.get('completion'))
それ以外は同じコードになっています。これは、API呼び出し方法が全く同じであることを意味します。
このように、Amazon Bedrockは機械学習モデルへのアクセスを統一します。
モデルに入力する文章構造と出力されるデータ構造が異なるところがあるので、そこはモデルに合わせなければなりませんが、現状のChatGPTやBard毎にAPIや依存ライブラリが異なるよりは開発効率は上がります。
現状ですとLangChainのようなLLMヘルパーライブラリを使うほうが便利な面もまだあると思いますが、今後こうしたモデルの使い分けをワンタッチで行えるようになる利便性の向上に期待したいと思います。