

膨大な構造化データ、半構造化データを抱え、その中から必要な情報を素早く分析したい。でも、システムに組み込むような本格的な分析ではなく、アドホックに分析したい。そんな時、一体何から始めたら良いのか途方に暮れた事はありませんか?
- 原因調査・仮説検証などスポット的なデータ分析を効率化したい
- データ量が多く処理時間・コストを短縮するためにデータを圧縮したい
- 可視化ツールを活用してレポートを作成したい
本記事では、 上記のような課題を解消するために、Amazon Athenaを用いて効率的にデータ化し、実行時間とスキャンデータ量を削減する方法と、Amazon Managed Grafanaを活用したデータ可視化方法をご紹介します。具体的な手順やサンプルを交えながら、Athenaでのクエリ作成からGrafanaでのダッシュボード構築までを解説します。データ可視化にお困りの方は、ぜひ読んでみてください。
アドホックなデータ分析をAWSで実現する3つのステップ
アドホックデータ分析は、従来のデータウェアハウス構築・運用では時間やコストがかかりすぎるという課題があります。 Amazon AthenaではSQL文により、これらのデータを直接分析できるため、迅速なデータ分析が可能です。
- Athenaに対応するファイル形式のデータをAWS S3に保存します。
- データ変換やパーティショニングなどの前処理が必要な場合はAmazon Athenaを用いてSQLベースで実行し、分析に適した形式に整えます。
- 整形されたデータをAmazon Managed Grafanaに接続し、動的なダッシュボードと可視化ツールを用いて分析、洞察の抽出を行います。
どのようなデータ構造に対応しているの?
構造化データと半構造化データは、Athenaでのクエリが可能です。CSVやParquetなどの形式は構造化データとして、JSONやAvroは半構造化データとして扱われます。これらのデータ形式はAthenaで容易に分析が行えます。一方で、非構造化データは、Athenaで直接分析するのが難しく、別途構造化や前処理が必要です。
| データ形式 | 概要 | Amazon Athena対応 |
| 構造化データ | スキーマを持つデータ 例:CSV、Parquet、ORCなど |
〇 |
| 半構造化データ | 部分的にスキーマを持つデータ 例:JSON、Avroなど |
〇 |
| 非構造化テキストデータ | 明確なスキーマを持たないデータ 例:Logstashログなど |
〇 |
| 非構造化データ | 明確なスキーマを持たないデータ 例:PDF、画像、動画 |
× |
どのようなファイル形式に対応しているの?
Amazon Athenaで取り扱い可能なファイル形式は、構造化データ形式(CSV、TSV、カスタム区切り、 Apache Parquet、ORC )、半構造化データ形式(JSON、Apache Avro、Amazon Ion、CloudTrailログ)、ログファイル形式(Apache WebServerログ、Logstashログ)です。
| ファイル形式 | 説明 |
| Amazon Ion | JSONと互換性のあるデータ形式 |
| Apache Avro | データシリアライズフレームワーク |
| Apache Parquet | 列指向ストレージ形式 |
| Apache WebServer ログ | パターンマッチングが可能なテキストデータ形式 |
| CloudTrail ログ | JSON形式 |
| CSV | カンマ区切り値 |
| カスタム区切り | ユーザー定義の区切り文字で分けられたテキストデータ形式 |
| JSON | 階層型データフォーマット |
| Logstash ログ | パターンマッチングが可能なテキストデータ形式 |
| ORC | 列指向ストレージ形式 |
| TSV | タブ文字で区切られたテキストデータ形式 |

データの可視化は簡単にできますか?
Athenaのクエリ結果をAmazon Managed Grafanaのデータソースとして設定することで、簡単に連携が可能です。 Amazon Managed Grafanaは、複数のビルトインデータソースをサポートしており、さまざまなAWSサービスやその他のデータソースを可視化できます。Athenaのクエリ結果を動的なダッシュボードで表示し、多様な可視化オプションによりカスタマイズすることができます。

データ保管場所
分析対象のデータとクエリ実行結果は以下のようにS3バケット内の別々のフォルダに保存します。
クエリなど実行結果の保管場所: s3://<バケット>/athena/query/

Athenaによるデータ分析の準備
Athenaを用いたアドホック データの取り込み、データ形式の変換、パーティショニング、アクセス用テーブルについて解説し、それぞれのテーブルの実行時間とスキャンデータ量を比較します。
データ取込みテーブル作成
本ステップでは、S3に保存されたデータ(今回はCSVファイルを使用)を読み込むための外部テーブルを作成します。データ構造をAthenaに伝え、データを読み込めるように準備します。
CREATE EXTERNAL TABLE IF NOT EXISTS csv (
中略
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
"separatorChar" = ",",
"quoteChar" = "`",
"escapeChar" = "\\"
)
LOCATION 's3://<bucket>/athena/orgdata/'
TBLPROPERTIES ('skip.header.line.count' = '1');

データ変換とパーティショニング
本ステップでは、各種変換処理を行い、新しいテーブルを作成します。例えば、Unixタイムスタンプは使いやすいデータに変換してカラムを追加します。テキスト形式からParquet形式への変換は、列指向フォーマットによる特定カラムへのアクセス高速化、効率的な圧縮によるスキャンデータ量の削減、そして各種データセットへの適合性から、クエリパフォーマンスが向上します。特に、SNAPPY圧縮は高速な圧縮と解凍により、クエリ実行速度向上に効果的です。また適切なパーティショニングにより、クエリ対象のデータが絞り込まれ、スキャンデータ量の削減によるパフォーマンス向上とコスト削減を実現します。
CREATE TABLE enhanced_csv_data
WITH (
format = 'PARQUET',
parquet_compression = 'SNAPPY',
external_location='s3://<bucket>/athena/parquet/',
partitioned_by = ARRAY['year', 'month', 'day']
)
AS SELECT *,
CAST(date_format(from_unixtime(CAST(timestamp AS BIGINT) / 1000), '%Y%m%d%H%i%s') AS VARCHAR(14)) AS datetime_ymdhhmmss,
year(from_unixtime(CAST(timestamp AS BIGINT) / 1000)) AS year,
month(from_unixtime(CAST(timestamp AS BIGINT) / 1000)) AS month,
day(from_unixtime(CAST(timestamp AS BIGINT) / 1000)) AS day
FROM csv;


アクセス用テーブル作成
前ステップで作成したパーティション付きデータへアクセスするための外部テーブルを作成します。テーブル名やカラム名などのメタデータ定義、LOCATION句によるデータ指定、パーティション情報の取得、tblpropertiesによるデータフォーマットと圧縮形式の指定といった役割を担います。
CREATE EXTERNAL TABLE IF NOT EXISTS parquet_csv_data (
中略
)
STORED AS PARQUET
LOCATION 's3://<bucket>/athena/parquet/'
tblproperties ("parquet.compression"="SNAPPY");

各テーブルの実行時間とスキャンデータ量の比較
3つのテーブルに対して同一のクエリを実行して、実行時間とスキャンデータ量を比較すると以下となりました。
| 対象テーブル | 実行時間 | スキャンデータ量 |
| CSVデータ取込みテーブル | 6.29sec | 127.96MB |
| データ変換テーブル | 6.71sec | 12.69MB |
| アクセス用テーブル | 3.84sec | 9.99MB |
Grafanaによるデータ可視化
本章では、AthenaデータソースをGrafanaに設定し、Grafana Exploreでクエリを実行、ダッシュボードを作成する方法を紹介します。
アクセス制御
GrafanaからAthenaのデータ取得とS3へのログ書き込みについて、以下を参考にIAM 権限の付与を行います。

GrafanaにAthenaデータソース設定
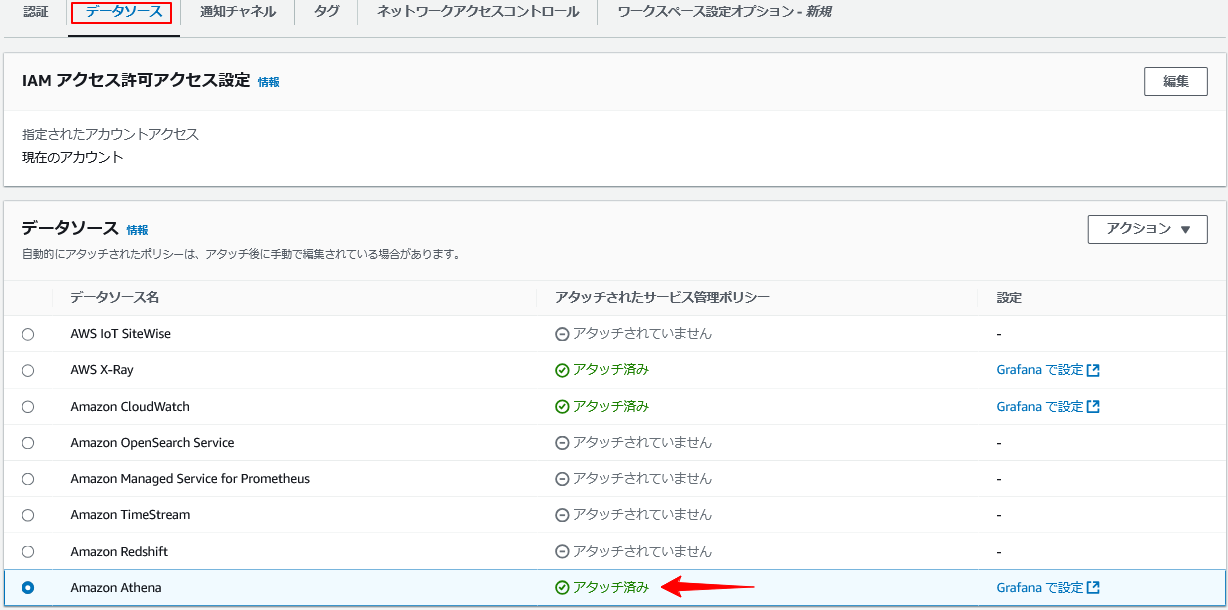
データ転送を行うGrafana ワークスペースの[データソース]タブでAthena のデータソースを有効化し、アタッチ済みとなる事を確認します。
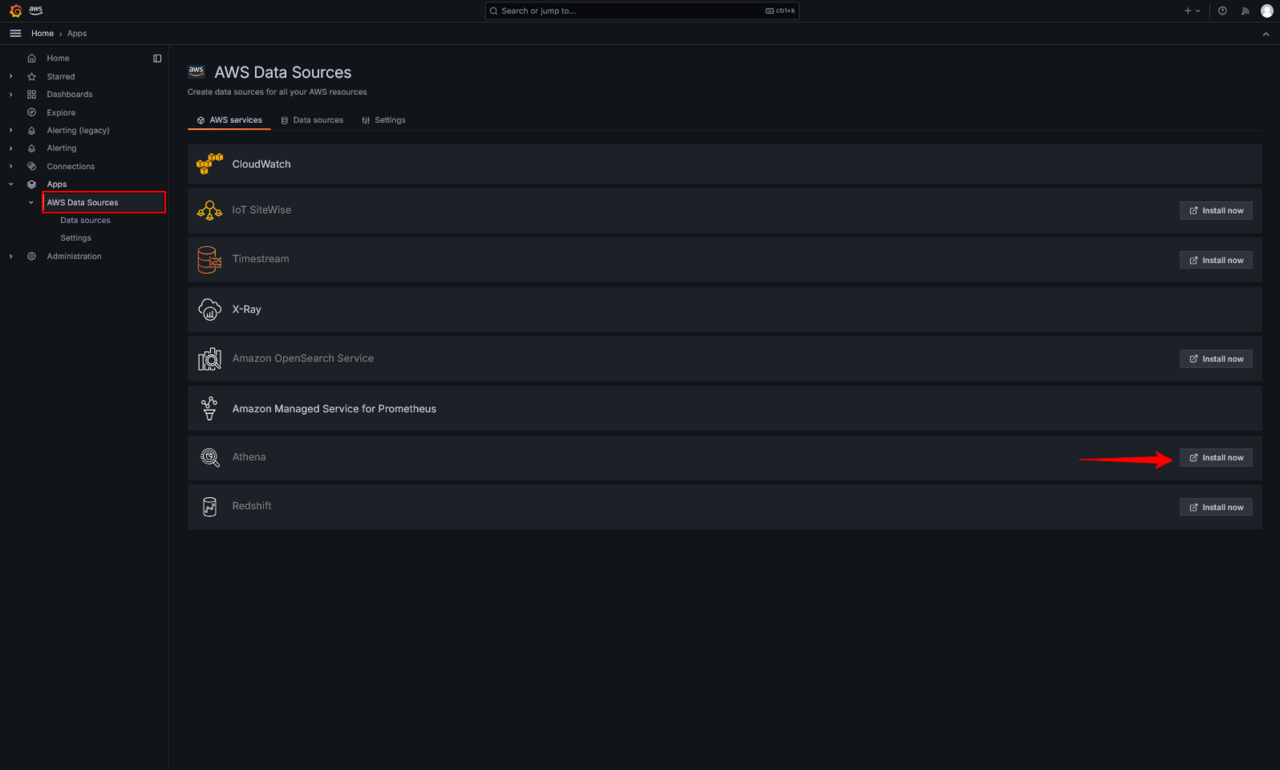
次にGrafanaのコンソールにログインし、データソースにAthenaが利用可能となっているか確認します。未利用の場合はinstall nowをクリックします。
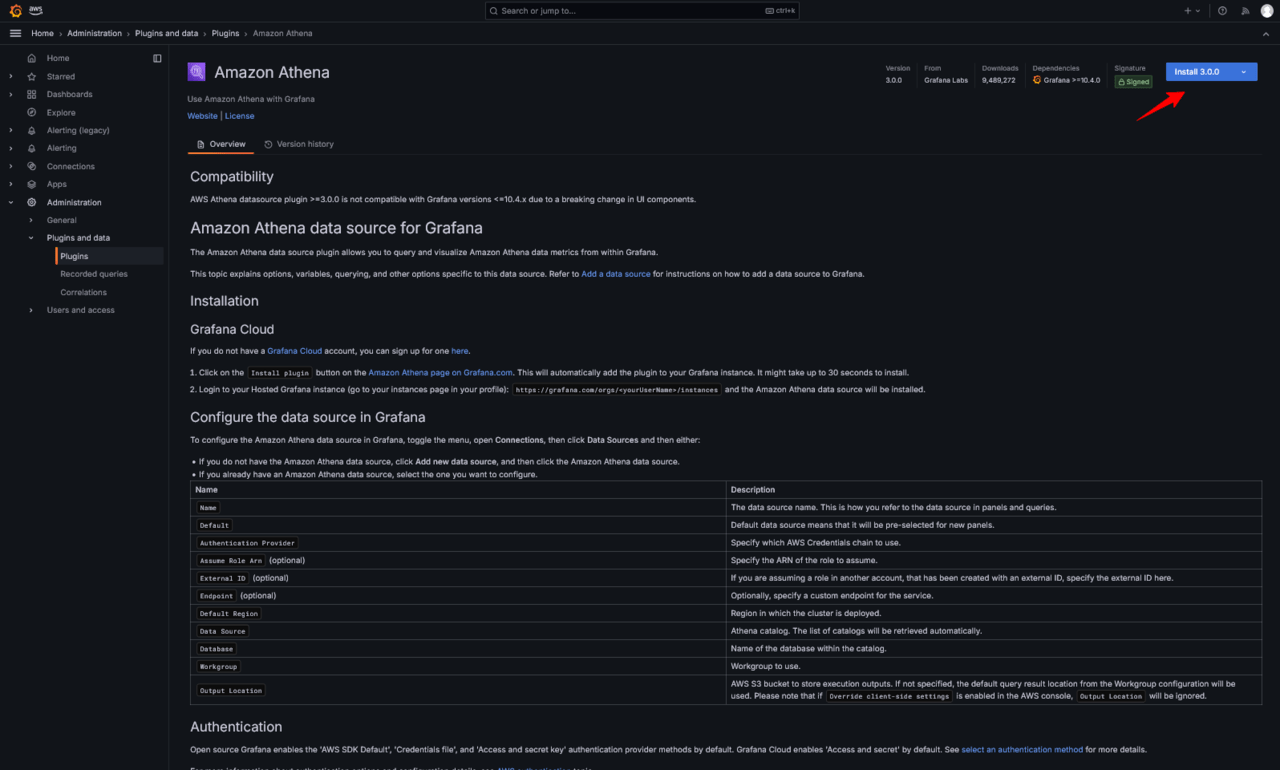
Amazon Athenaに関するプラグイン説明画面が表示されるので、右上よりインストールします。
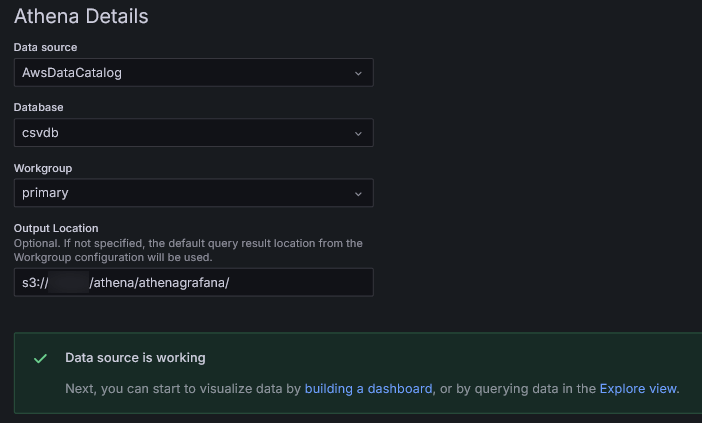
プラグインのインストールが完了するとAdd new data sourceと表示されるのでクリックします。
ここでは主にAthena Detailsの設定をします。
Grafana Exploreにてクエリ実行
Athenaとの接続が完了するとData Sourcesに新たに追加されるので、Exploreをクリックします。
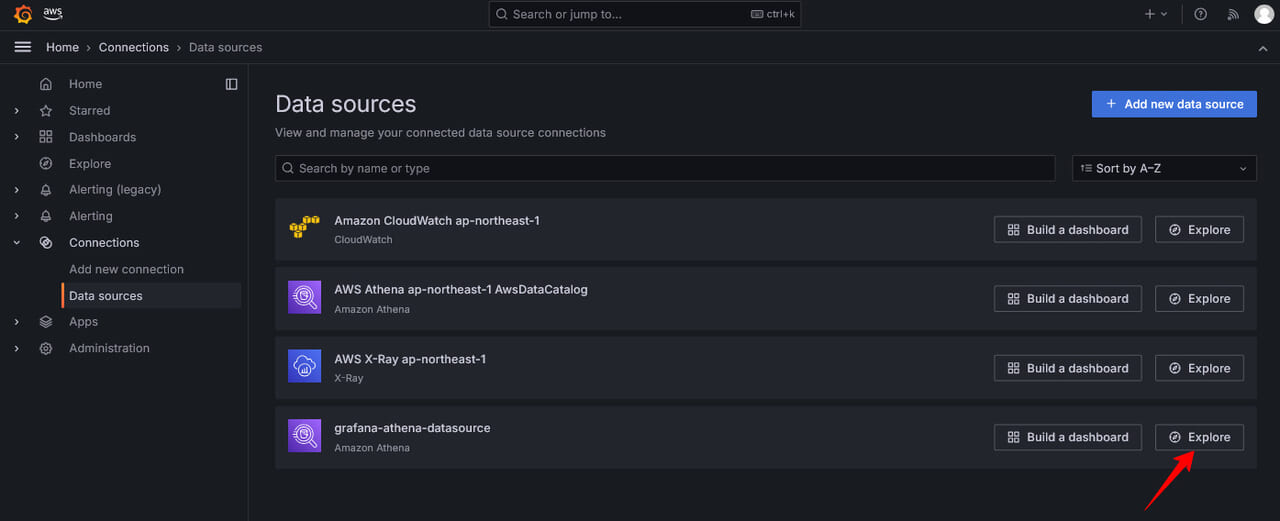
Grafana Dashboardの作成
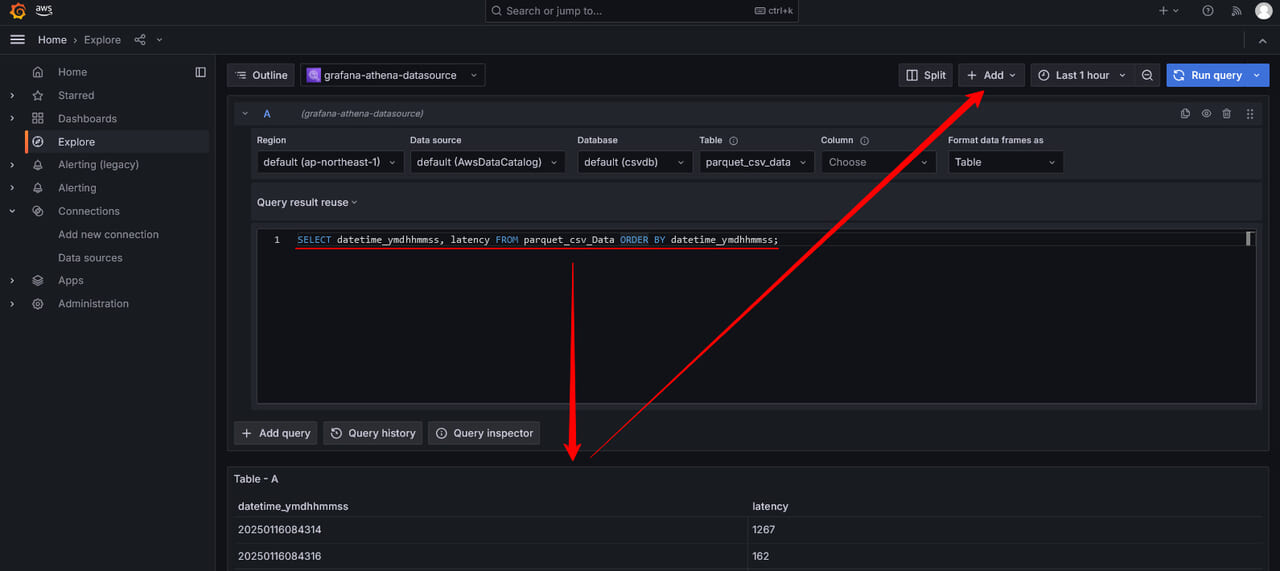
ここではGrafanaのデータソースとしてAthenaからの応答が正しい事をテストクエリを実行して確認します。特に問題なければ画面右上の+Addを展開してAdd to dashboardをクリックします。
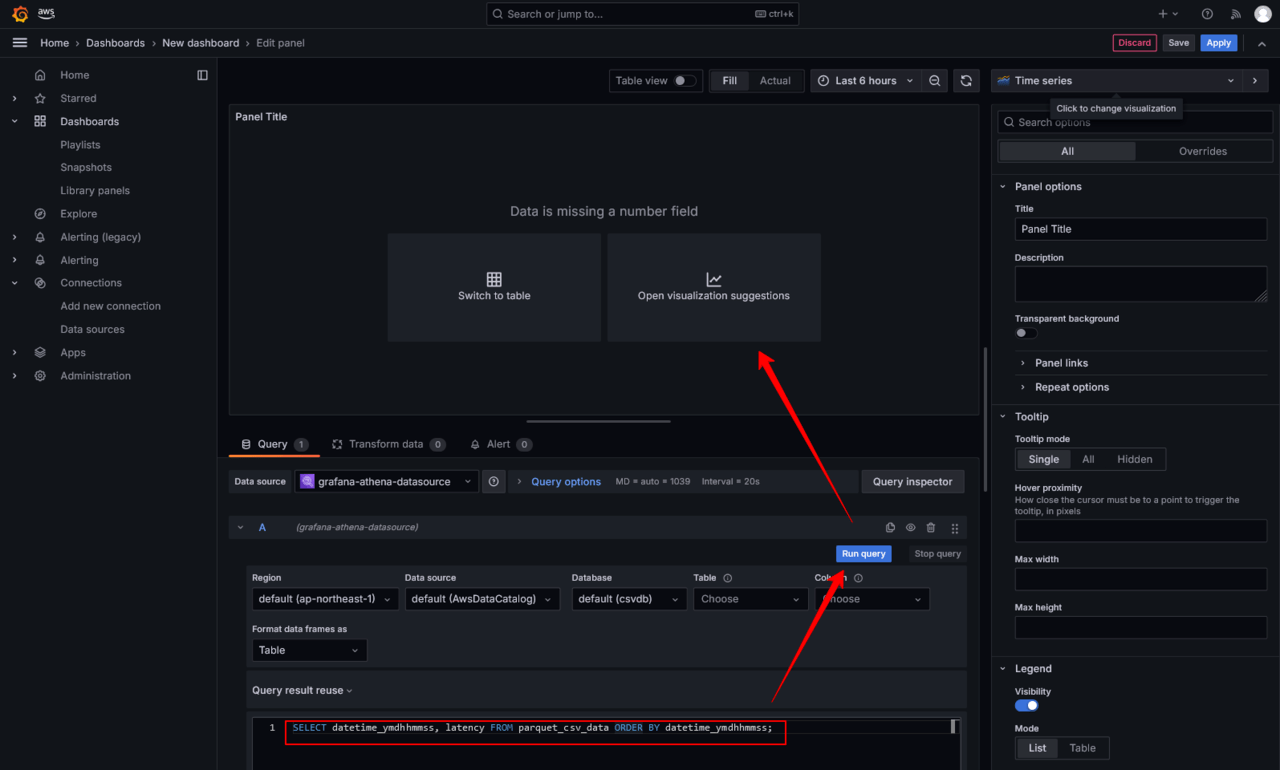
次にOpen dashboard、Add visualizationをクリックするとダッシュボードのエディット画面が表示されるので、可視化を行いたいクエリを実行します。この時点では期待する結果とならない場合もありますので、Open visualization suggestionsからお好みの視覚化オプションを選択します。
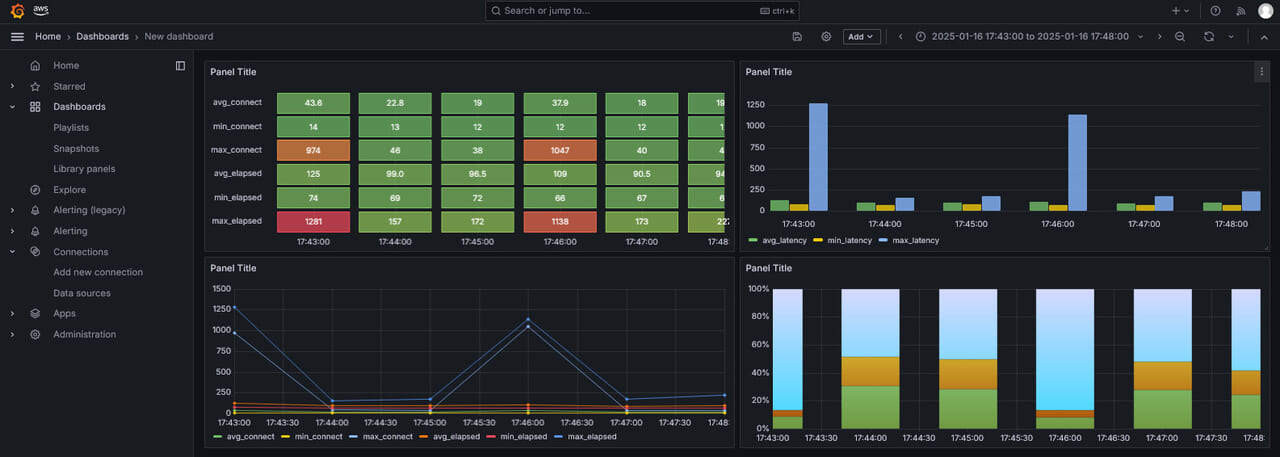
視覚化オプションは多数あり、ダッシュボード上に異なるパネルを作成する事ができます。
さいごに
Amazon S3、Amazon Athena、Amazon Managed Grafanaを使ったデータ分析ワークフローを3つのステップで解説しました。本記事が皆様のデータ活用にお役立ていただければ幸いです。