

こんにちは。最近Google CloudのDataシリーズにはまっている林です。
Google Cloud Day: Digital ’22の2週目に開催されたハンズオン祭のうち、『データエンジニア向けBigQuery + Dataplex 編』を受講してきました。

”Dataplex”は聞いたことがあったもののどのようなサービスか全く理解していなかったため、非常に勉強になる内容でした。
Dataplexって?
分散したデータを一元化して、 データ管理を自動化し、より強力な大規模な分析を可能するインテリジェントなデータファブリック
(ハンズオン資料より抜粋)
なるほど、わかったようなわからないような。私はこれだけでは具体的なイメージがさっぱりでした。
なので具体的にできることを見ていきます。
| Dataplexが解決する課題(資料より抜粋) | できること |
|---|---|
| インテリジェントなデータ管理・処理 | Cloud Storageバケット内のファイルのメタデータの自動検出ができる。
データのキュレーションができる。 データ品質(※)の管理・運用ができる。 |
| サイロ化されたデータの一元管理 | BigQueryデータセット、Cloud Storageバケットをグループ化しまとめて管理(アクセス制御等)できる。 |
| 効率的なデータの探索と分析ツールの柔軟な選択 | データ内での探索やクエリなど分析を統合された画面からできる。(プレビュー版) |
要するに、
Dataplexを使うと大規模なデータの管理がしやすくなるよ。(※ただしBQ、GCS上のデータに限る)
というサービスのようです。
Google Cloudコンソールの切り口で見ていきます。
管理
『サイロ化されたデータの一元管理』に該当する部分です。
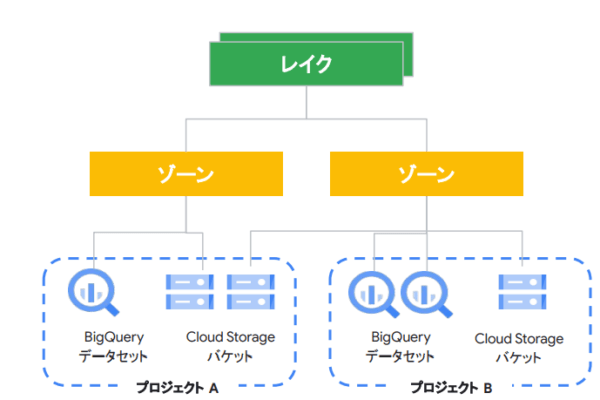
以下はデータ管理に関連する用語整理です。
| レイク | 論理グループ 分析対象データ(BQ、GCS)をまとめることができる |
||||
|---|---|---|---|---|---|
| ゾーン | 論理グループ 分析対象データ(BQ、GCS)をまとめることができる
|
||||
| アセット | BigQueryデータセット、Cloud Storageバケット
※2022/04時点では上記2つのみ対応。今後拡張予定。 |
図にすると以下のイメージです。
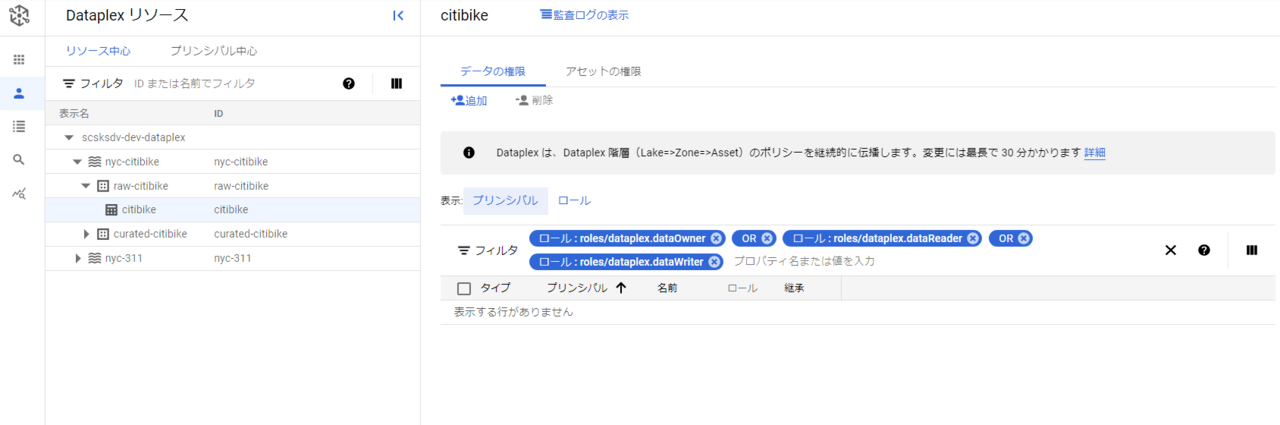
安全
レイクやゾーン単位でのユーザーのアクセス権管理がここからできます。
処理
データのキュレーションやデータの品質チェックなど、色々な処理(タスク)が作成可能です。

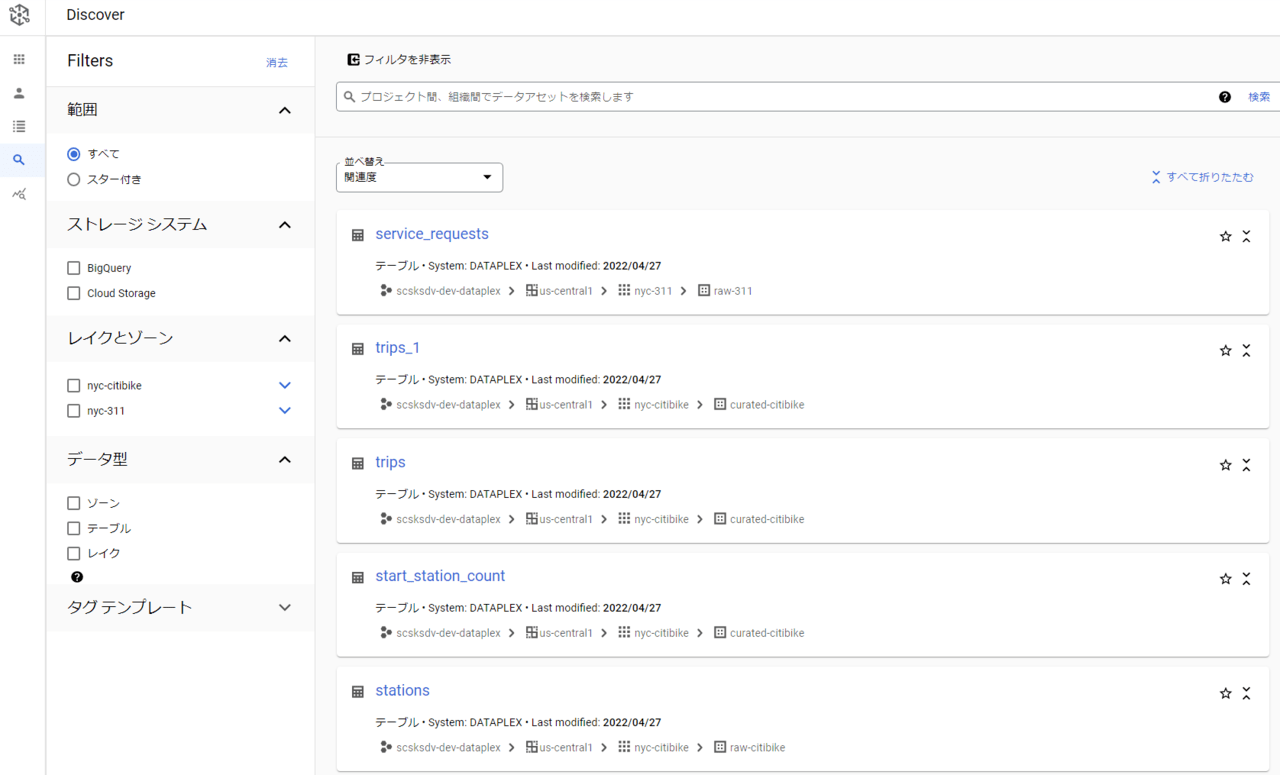
探索
アセットに登録されているデータを探索することができます。ここからデータを選んでタスクを作成することもできます。
今回はハンズオンのクーポンがあったので無料でしたが、最後に料金も見ておきます。
レイク/ゾーン/アセットの設定やセキュリティポリシーの適用は無料です。
主に『処理』と『探索』に料金がかかるようですが、無料枠が用意されているので、小規模な利用でしたら無料枠に収まるかもしれないです。
また、別途裏で稼働するDataproc、BigQuery、Dataflowなどの料金もかかります。

ハンズオン
シナリオは以下の通りです。
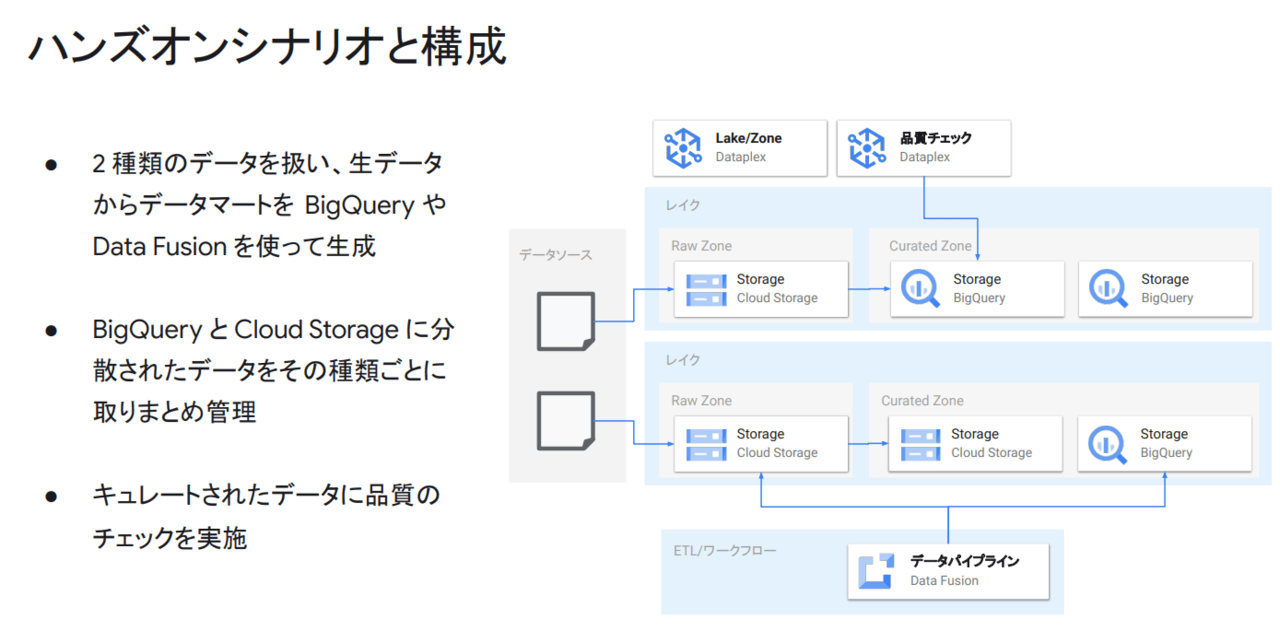
ハンズオンでやったことのざっくりとした流れです。
ハンズオン事前準備
- サンプルデータ用GCSバケット作成
- サンプルデータをGCSバケットにコピー
- Dataplex APIの有効化
- Data Fusionの起動(API有効化、インスタンス作成)
BigQueryを使った分析の基本
- GCSからBigQueryへのデータのロード
- BigQueryへのクエリの実行
- BigQueryで外部テーブルを定義し確認
- BigQueryでビューを作成
- BigQueryでマテリアライズドビューを作成
- BigQueryでスケジュールされたクエリを設定
Data Fusionでデータパイプライン構築
- パイプラインの定義ファイルを準備
- パイプラインのインポート
- パイプラインの実行
- 生成されたデータの確認
Dataplexでデータを集約管理
- レイクの作成
- 未加工ゾーンの作成
- GCSバケットをアセットとして追加
- キュレートされたゾーンの作成
- BigQueryデータセットをアセットとして追加
- アセットのデータ自動検出の確認
- キュレートされた形式に変換するタスクの作成
- Parquetファイルへの変換を確認
Dataplexでデータ品質チェック
- データ品質のチェック仕様定義ファイルの作成
- Dataplexで品質チェックのタスクを作成
- 品質チェック結果の確認
環境削除
最後に
Dataplexって何?という疑問は晴れて解決しました。
タスクが簡単に作成できる部分や、グループ化して権限管理ができる部分はとても使い勝手が良く、サービスとして使う価値は十分にありそうだと感じました。
あとやはりノンコーディングで完結するのはうれしいポイントですね。
現在はデータソースがBigQueryとCloud Storageに限られているので、そこは今後拡張してくれたらなーといったところでした。
次のブログはこのハンズオンでも使用したData Fusionについて書こうと思います!