

 本記事は TechHarmony Advent Calendar 2024 12/21付の記事です。 本記事は TechHarmony Advent Calendar 2024 12/21付の記事です。 |
どうも。現在の生成AIの流行を踏まえたAIもののSF小説を面白がって読んでいる寺内です。
re:invent 2024 で発表されたAmazon SageMaker Unified Studio の紹介記事の続きとなります。

この記事で書くこと
SageMaker は機械学習モデルを作成するための統合IDE環境を提供します。機械学習モデルの作成のためには、その学習データや学習アルゴリズムの選択のためにデータ分析を行う準備段階があります。そのため、データ分析ツールとして使ってみるということをやります。 分析を行うことが目的ではなく、この新しいSageMaker Studio でどのような作業の流れになるのかを把握することが目的です。
この記事は前編として、データの準備をして、Amazon SageMaker Unified Studio でSQLクエリを実行してみるところまで行います。
後編では、JupyterNotebookを使った実際の分析を行います。
分析シナリオ
世の中には多くのデータセットが官公庁や大学などの研究機関で公開されています。また機械学習学習者向けのデータセットも公開されています。しかしこの記事では、SageMaker Unified Studio を使った流れを把握することを目的としているため、難しいデータセットは使わず、簡単なCSVを作りそれを使います。
データセットは、生徒の5教科のテスト結果のリスト500人分を乱数から作ります。そのCSVをSageMaker に読み込ませて教科間の相関があるかを分析します。
作業の流れ
大雑把な作業な流れは以下となります。
- CSVデータの作成
- SageMaker Lakehouse にCSVデータのアップロード
- クエリエディタの起動
- SQLを実行
では順番にやっていきましょう。
CSVデータの作成
以下のpython プログラムを create_score.csv というファイル名で保存して実行します。実行場所は、ローカルPCでもCloudShellでもJupyter notebook でもかまいません。
import random
import csv
def generate_normal_random(mu, sigma, lower_bound, upper_bound):
while (True):
x = random.gauss(mu, sigma)
if lower_bound <= x <= upper_bound:
return int(x)
# 作成する生徒の人数
n=500
# 生徒の名前のリストを作成します。
names = []
for i in range(n):
name = c h r(65 + (i//26)//26 ) + c h r(65 + (i//26) ) + c h r(65 + (i%26) ) # c h r() とスペースを入れています。実行する時は文字間のスペースを除去してください。
names.append(name)
# テストの点数のリストを作成します。
subjects = ["Japanese", "Math", "Science", "Social", "English"]
scores = []
for i in range(n):
japanese=generate_normal_random(50, 15, 1, 100)
math=generate_normal_random(50, 15, 1, 100)
science=generate_normal_random(50, 15, 1, 50)+math//2
social=generate_normal_random(50, 15, 1, 100)
english=generate_normal_random(50, 15, 1, 50)+japanese//2
score = [japanese,math,science,social,english]
scores.append(score)
# CSV ファイルにデータを書き込みます。
with open("test_scores.csv", "w", newline="", encoding="utf-8") as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["Name"] + subjects)
for i in range(n):
writer.writerow([names[i]] + scores[i])
すると exam_scores.csv というファイルが create_score.csv と同じディレクトリに作られます。 exam_scores.csv をローカルPCにダウンロードしてください。
生徒の名前は、AAA、AAB、AACと変わり、AAZまでいくと次の人はABAという名前になります。
テストの点数は、国語、数学、理科、社会、英語と並んでおり、1点から100点の範囲です。
24行目から28行目が各教科の点数を作っているところです。 単純な乱数になっていないことがわかります。
テストの点数分布は、多くの生徒を集めるとおおよそ正規分布になると思います。24行目の国語の点数のところをみていただく、一様分布の乱数ではなく、正規分布に則った乱数としています。 最初の引数の50は平均値、次の15は標準偏差、そして点数の最小と最大を指定しています。
そして28行目の英語の点数の生成では、乱数を50点までとし残りの50点を国語の点数の半分を与えるとしています。これは相関分析した時に国語と英語に相関を出すためです。同様に数学と理科を同じ関係にしています。
非常に恣意的なデータですが、学習用としてご容赦ください。
SageMaker Lakehouse にCSVデータのアップロード
ローカルPCにダウンロードした exam_scores.csv をAWSマネージメントコンソールを使ってSageMaker Lakehouse にアップロードします。
マネージメントコンソールのサービス検索で、SageMaker platform にアクセスします。そこでドメイン作成、プロジェクト作成を行います。この手順については、前回のブログ『【re:Invent 2024発表】次世代 Amazon SageMaker Unified Studio に触ってみた』に記載していますので、ここでは省略します。
プロジェクトを作成したあと、そのプロジェクトポータルの画面になります。その左にあるサイドメニューから「データ」を選択します。
すると真ん中のデータ一覧のカラムに「Lakehouse」「Redshift」「S3」の3つのカテゴリがあり、「Lakehouse」が展開されているはずです。「Lakehouse」の中には「AwsDataCatalog」があります。
ファイルをアップロードするには、検索窓の右にある+ボタンを押します。
すると「add data」のインタラクティブウィンドウが開きますので、「Upload data」を選択します。
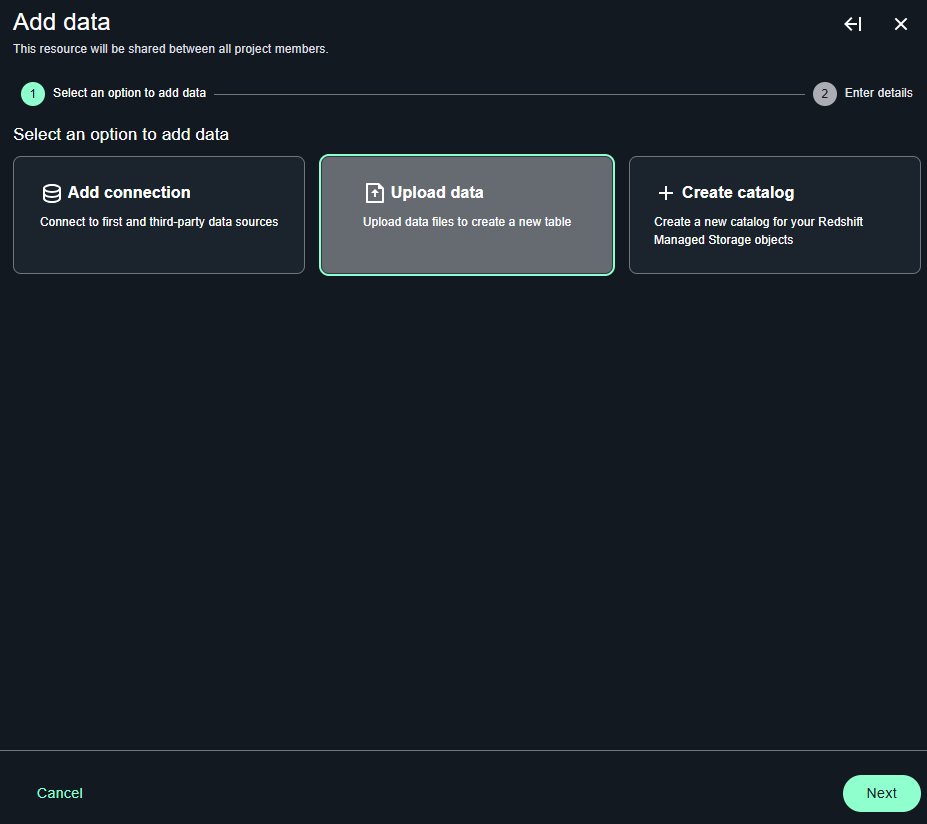
そしてアップロードするファイルをドラッグ・アンド・ドロップで指定すると、データフォーマットなどのパラメータを良しなに決定してくれます。そのままUploadボタンを押します。
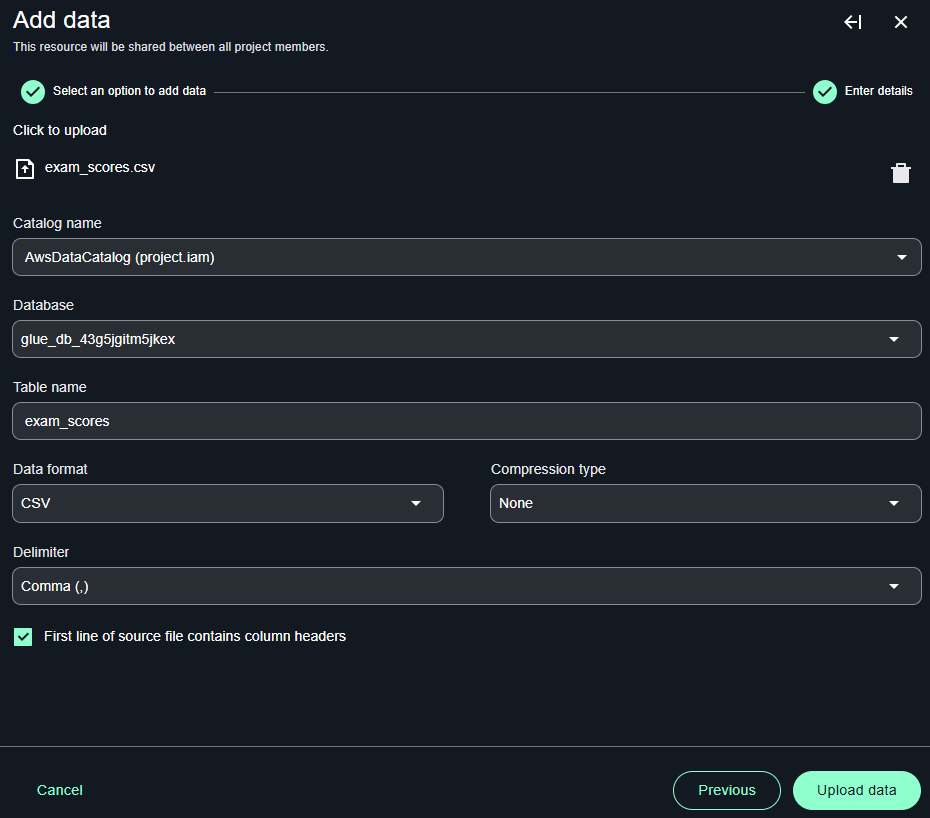
完了すると、CSVファイルがLakehouseに取り込まれています。
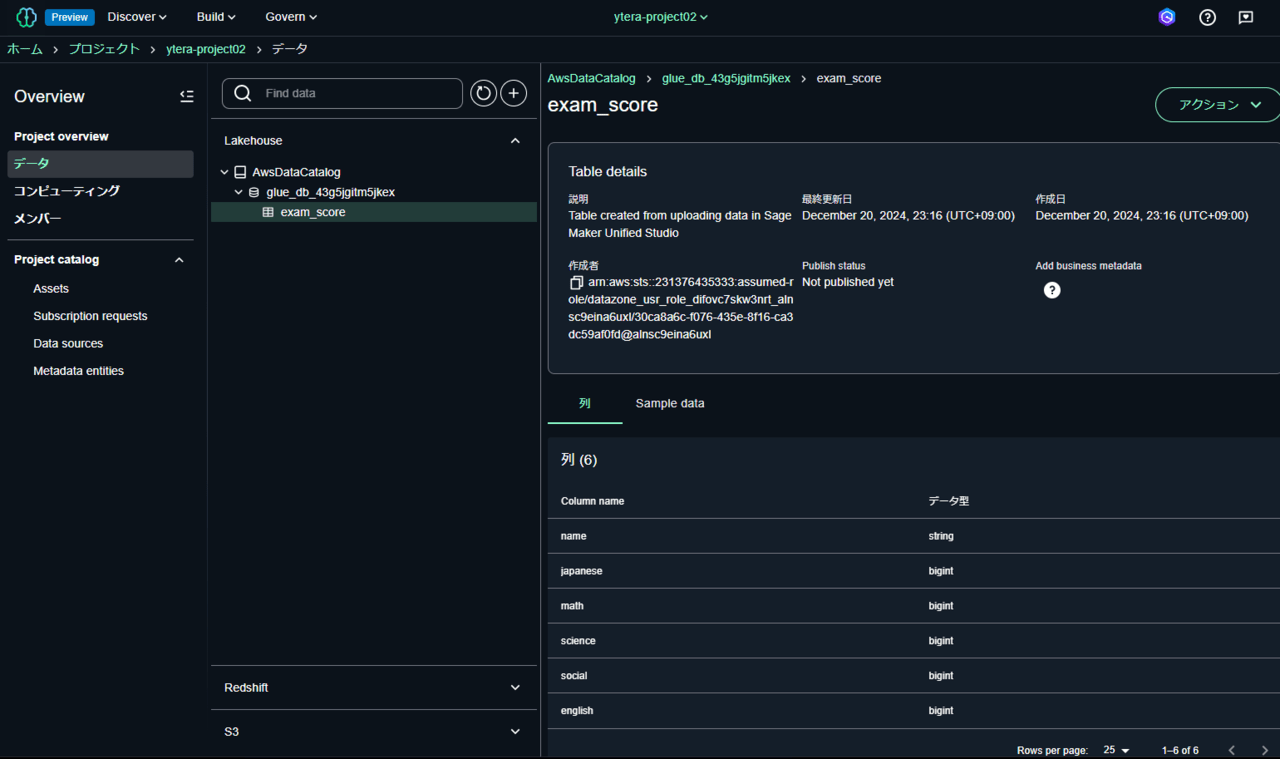
これでデータのアップロードが完了です。
クエリエディタの起動
このCSVデータにSQLを発行します。そのためにクエリエディタというものが提供されています。
クエリエディタの開き方は複数あり、以下の2つが主たるところです。
データベースを指定して開く
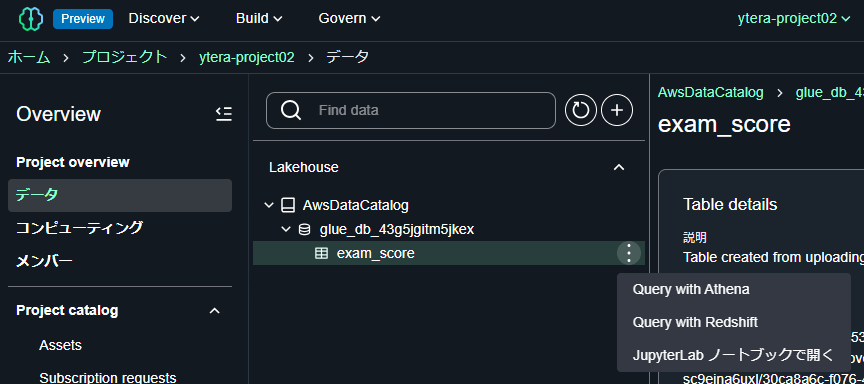
さきほどのデータ一覧のツリーを展開し、 exam_scores テーブルを選択します。右の三点メニューを押すと以下のように開き方の選択肢が出ます。
- Query with Athena
- Query with Redshift
- JupyterLab ノートブックで開く
Lakehouse にあるデータは、S3 にあろうがRedshift にあろうが統一的にアクセスできるのが、Unified Studio の特徴です。
ここでは「Query with Redshift」で開きましょう。
すると以下のように行頭10行を自動で検索してくれます。
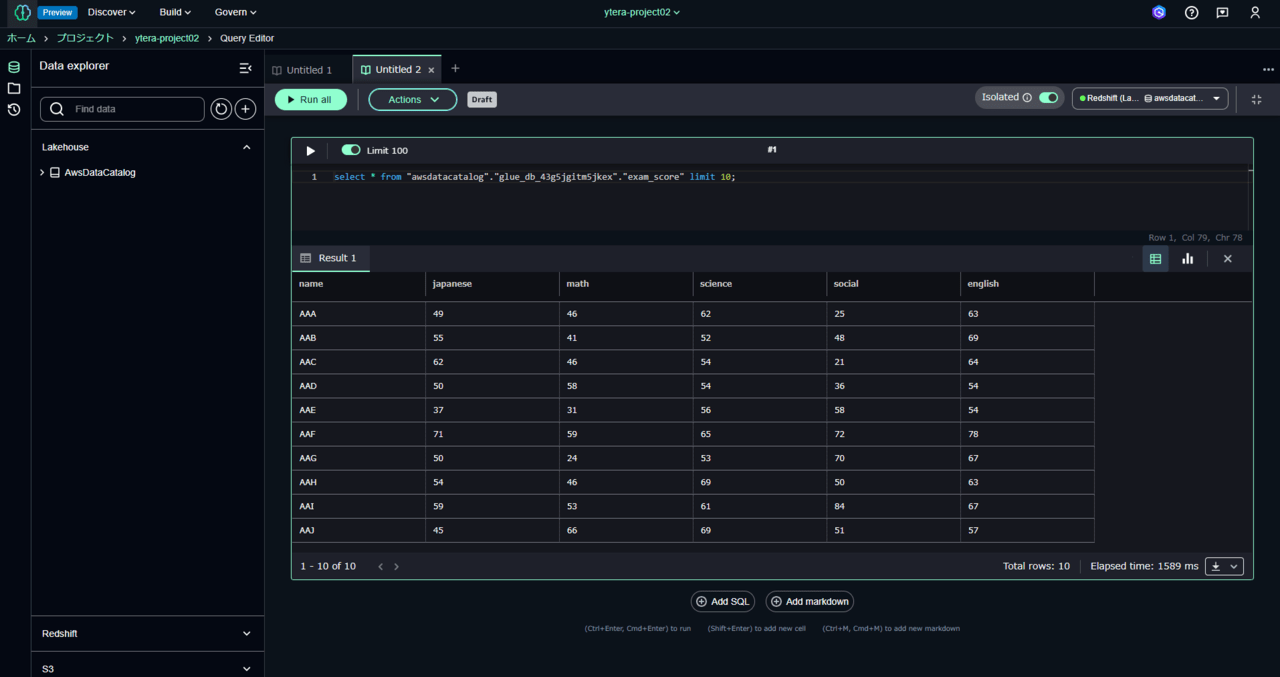
クエリエディタもノートブックと同じセル形式の入力と出力を繰り返すインターフェースです。
SQLを書き換えるなり、「Add SQL」をしてセルを追加するなりして作業をしていきます。
メニューからクエリエディタを起動する
次に、テーブルを指定するのではなく直接クエリエディタを起動するやり方です。
プロジェクトポータルにある上部のメニューから「Build」を開きます。すると、真ん中の列に「Query Editor」というのがあるので、それを選択します。
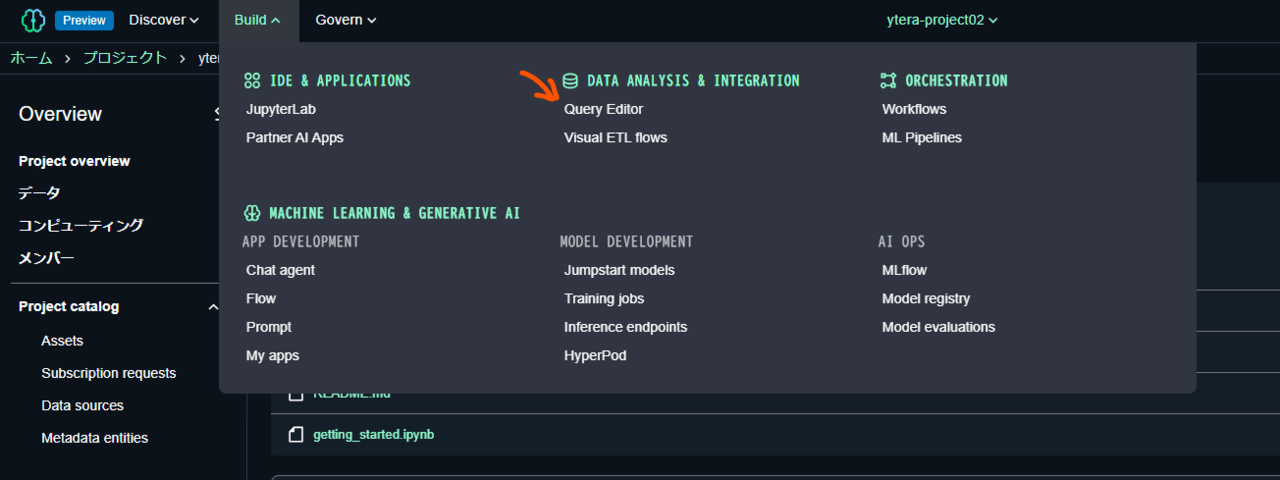
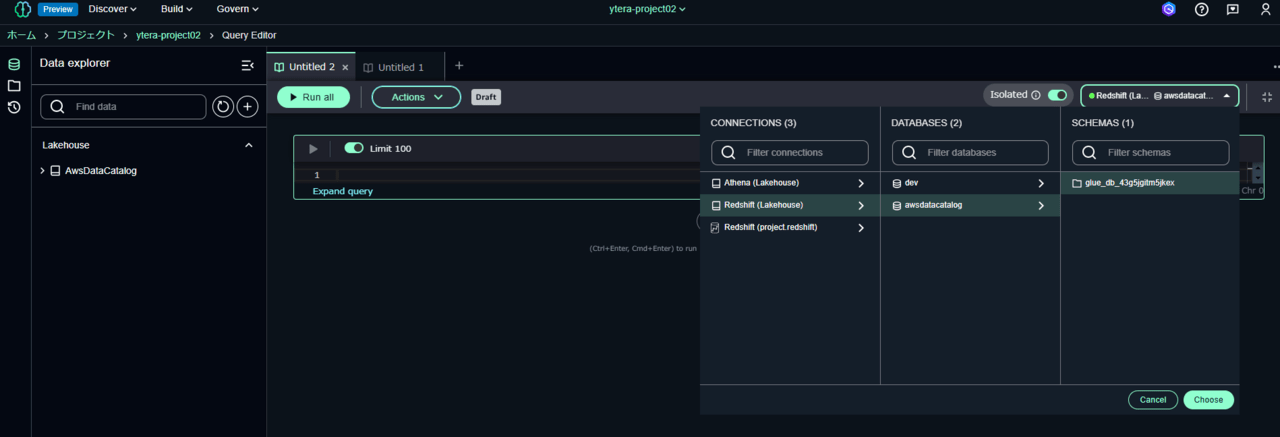
初めてクエリエディタを起動したら、データベースが選択されていません。右上にある「Chose database」のプルダウンを押し、以下のようにデータベースを選択します。
ここでは以下を選択しています。
- CONNECTIONS: Redshift (Lakehouse)
- DATABASES: awsdatacatalog
- SCHEMAS: glue_db_XXXXXXXXX
そして入力セルにSQLを入力し、セルの左上にある三角マーク(再生ボタン)を押すことで、SQLを実行できます。
SQLの実行
単純な検索と可視化
ではまず単純にデータを表示してみましょう。
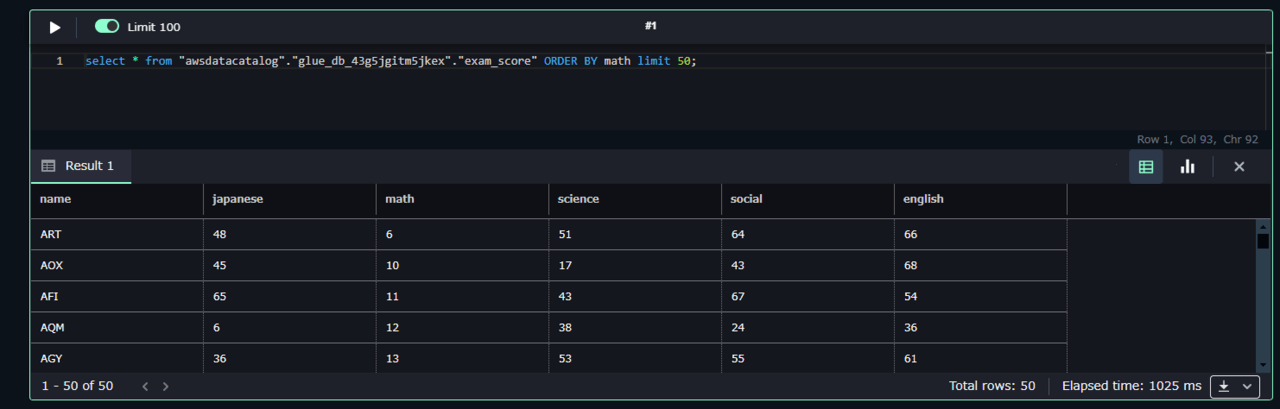
select * from "awsdatacatalog"."glue_db_43g5jgitm5jkex"."exam_score" ORDER BY math limit 50;
すぐに検索結果が出たと思います。RedshiftといってもRedshift Serverlessですので、料金面ではあまり心配がありません。
ではこの結果をグラフで可視化してみます。
結果の右上にある棒グラフボタンを押します。
こんな画面が出ると思います。
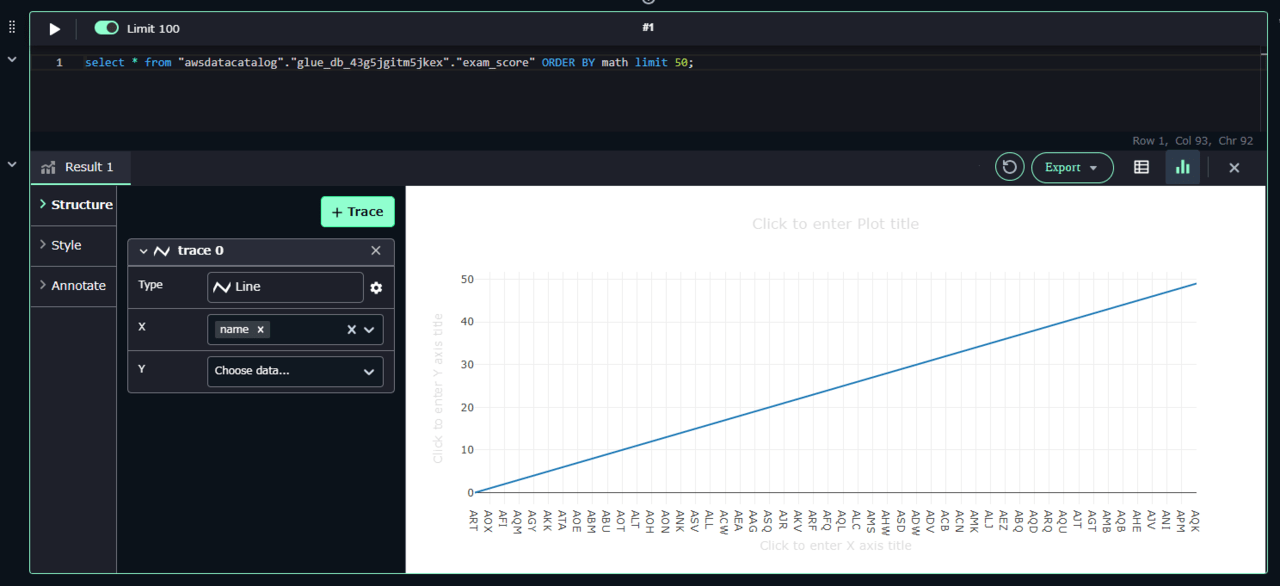
グラフのX軸は name が指定されています。Y軸は指定されていません。数学の点数 math を選択してみましょう。SQLでは、 ORDER BY でソートしているので昇順で50人分の結果が出ています。
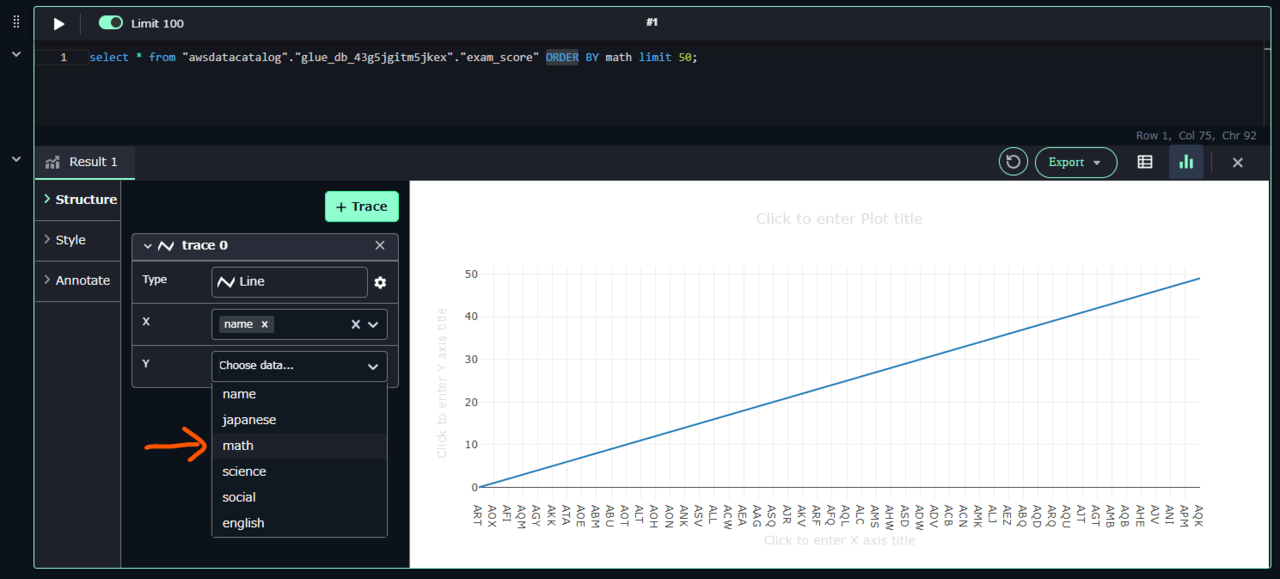
グラフがリアルタイムに描画されたと思います。
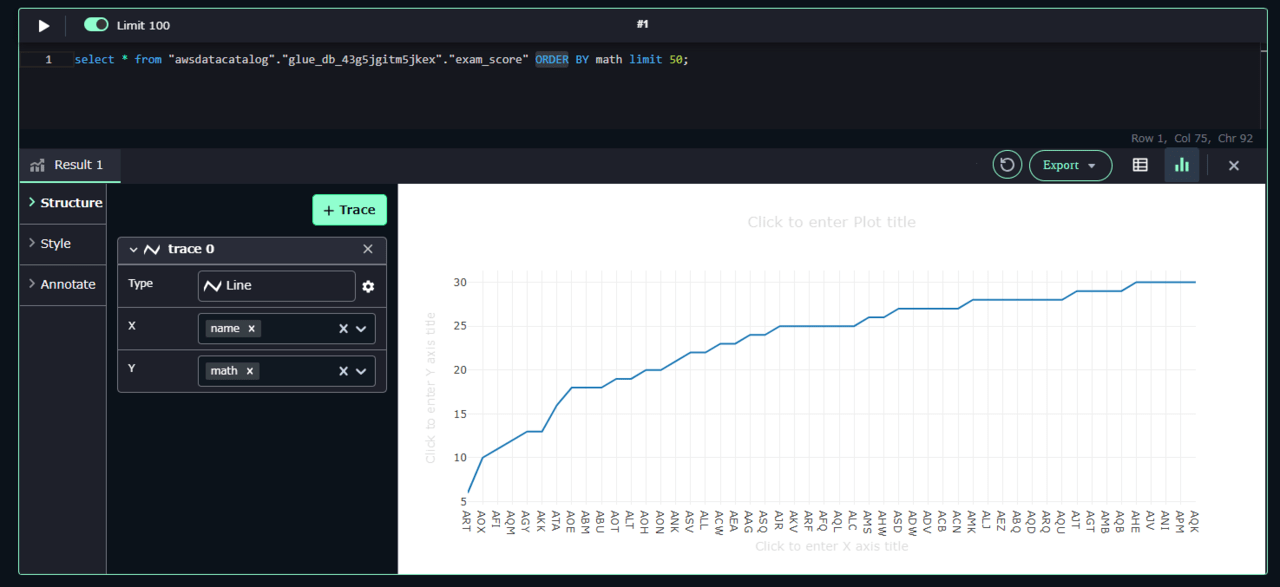
「Type」を変えると、いろいろなグラフを描くことができます。
ちょっと複雑なSQL
では、この数学の点数の分布を見てみます。
点数の範囲を10点ごとに人数を数え、それを棒グラフにしてみましょう。
以下のSQLを実行します。
SELECT
CASE
WHEN math between 1 AND 10 THEN ' 1-10'
WHEN math between 11 AND 20 THEN '11-20'
WHEN math between 21 AND 30 THEN '21-30'
WHEN math between 31 AND 40 THEN '31-40'
WHEN math between 41 AND 50 THEN '41-50'
WHEN math between 51 AND 60 THEN '51-60'
WHEN math between 61 AND 70 THEN '61-70'
WHEN math between 71 AND 80 THEN '71-80'
WHEN math between 81 AND 90 THEN '81-90'
WHEN math between 91 AND 100 THEN '91-100'
END AS 範囲,
Count(*) AS 人数
FROM
awsdatacatalog.glue_db_43g5jgitm5jkex.exam_score
GROUP BY 範囲
ORDER BY 範囲
以下のように実行できました。
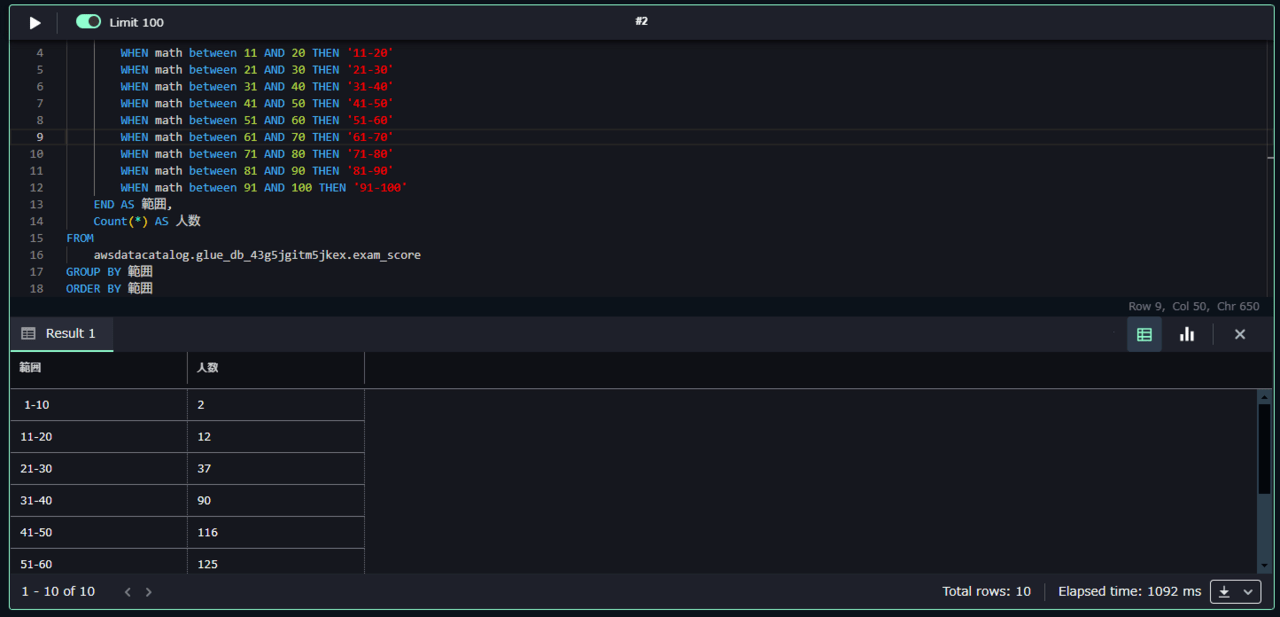
グラフで可視化してみます。
グラフの「Type」を棒グラフ「Bar」を選択します。Y軸には「人数」を選択します。
すると以下のようになります。
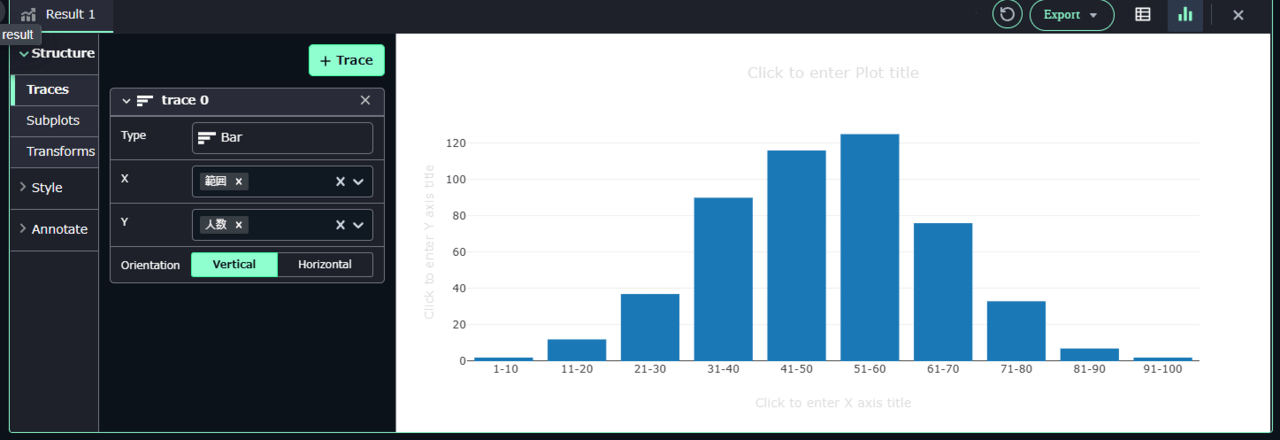
数学の点数の人数分布が正規分布になっていることがわかります。これはデータ作成時に以下のように指定していたためです。
math=generate_normal_random(50, 15, 1, 100)
では同じく理科についても分布をみてみましょう。SQLは以下です。
SELECT
CASE
WHEN science between 1 AND 10 THEN ' 1-10'
WHEN science between 11 AND 20 THEN '11-20'
WHEN science between 21 AND 30 THEN '21-30'
WHEN science between 31 AND 40 THEN '31-40'
WHEN science between 41 AND 50 THEN '41-50'
WHEN science between 51 AND 60 THEN '51-60'
WHEN science between 61 AND 70 THEN '61-70'
WHEN science between 71 AND 80 THEN '71-80'
WHEN science between 81 AND 90 THEN '81-90'
WHEN science between 91 AND 100 THEN '91-100'
END AS 範囲,
Count(*) AS 人数
FROM
awsdatacatalog.glue_db_43g5jgitm5jkex.exam_scores
GROUP BY 範囲
ORDER BY 範囲
こうなります。
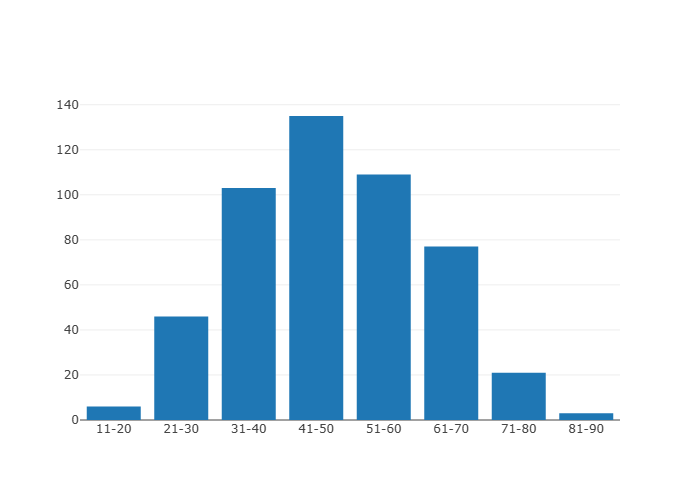
数学と比べると明らかに中央値が下がっています。
これはデータ生成にて、理科の点数は25点を平均となる50点までの乱数に、数学の半分の点数を足した構成になっているからです。
science=generate_normal_random(25, 15, 1, 50)+math//2
以上がSQLでの簡単なデータ分析でした。
可視化ツールのほうでヒストグラムのグラフを作ることもできるので、もっと簡単なSQLで行けそうな気もします。
ということで、データの作成からLakehouse へのアップロード、そしてSQL実行と可視化の手順を見てきました。
慣れると非常に早くデータを取り扱うことのできるツールです。機械学習をやらないから、ということで使わないのは勿体ないくらいです。
次回は、Jupyterノートブックとの連携にトライします。
ではまた。