

GCPのCloud Data Fusionはデータパイプラインを作成、管理できるサービスです。Data FusionとCloud Pub/Subを組み合わせることで、日々発生するデータをリアルタイムにDWHへ格納することができます。
今回はデータをリアルタイムにDWHへ連携するパイプラインを、Cloud Data Fusion上に構築してみたいと思います。
作成方法と作成時のポイントを記載します。
使用するサービスの概要
Cloud Pub/Sub
アプリケーションとデータ統合用の Pub/Sub | Google Cloud
Pub/Subは非同期メッセージサービスです。
リアルタイムデータはスマホやIoT機器などから生成されますが、Cloud Pub/Subを中継するように設計することで、
より便利によりセキュアになります。
また、GCPのリソースと連携がしやすく、フルマネージドサービスのため簡単に作成ができます。
今回はPub/Subにデータ発生元からデータが連携された想定でパイプラインの構築と検証を行います。
BigQuery
BigQuery エンタープライズ向けデータ ウェアハウス | Google Cloud
BigQueryはフルマネージドのデータウェアハウスサービスです。
今回はこのBigQueryにデータを格納できることをゴールとします。
Cloud Data Fusion
Cloud Data Fusion | Google Cloud
Data Fusionはコードを意識せずにデータパイプラインを作成、管理できるフルマネージドサービスです。
作成できるパイプラインは、実行するごとに処理が流れるバッチパイプラインと、パイプラインを実行し続けトリガーがあった際に都度処理が走るリアルタイムパイプラインの2種類あります。
今回はリアルタイムパイプラインを使用して構築していきます。
なお、バッチパイプラインの作成方法については、下記の記事をご確認ください。
下記の記事ではGCS上のファイルからデータを連携する方法が記載されています。
【GCP】Cloud FunctionsのCloud StorageトリガーでDataFusionパイプラインを起動 – TechHarmony
実際に作ってみる
実現したい事
今回実現したいことは下記です。
ゴール
Cloud Pub/Subに投入したデータがBigQueryに格納される
フロー
- Cloud Pub/Subにて「1111 aaaa」という文字列を公開する
- Pub/Subでデータが公開されたら、DataFusionリアルタイムパイプラインにてPub/Subからデータを受け取り、データを修正した後BigQueryに格納する
- BigQueryにて「1111」と「aaaa」が異なるカラムに入る
IAMの設定
まず、本検証を実行するのにあたって必要な権限を各サービスアカウントに付与します。
GCPのIAMのページを開き、画面右上にある「Include Google-provided role grants」にチェックを入れます。

「Cloud Data Fusion Service Account」に「Pub/Sub編集者」のロールを付与します。
Cloud Pub/Sub作成
GCPのPub/Subページからトピックを作成します。
「デフォルトのサブスクリプションを追加する」にチェックを入れると自答的にサブスクリプションが作成されます。
- トピック:userlist
- サブスクリプション:userlist-sub(自動で作成)

BigQuery作成
GCPのBigQueryページから以下のネーミングにてデータセットとテーブルを作成します。
- データセット:user
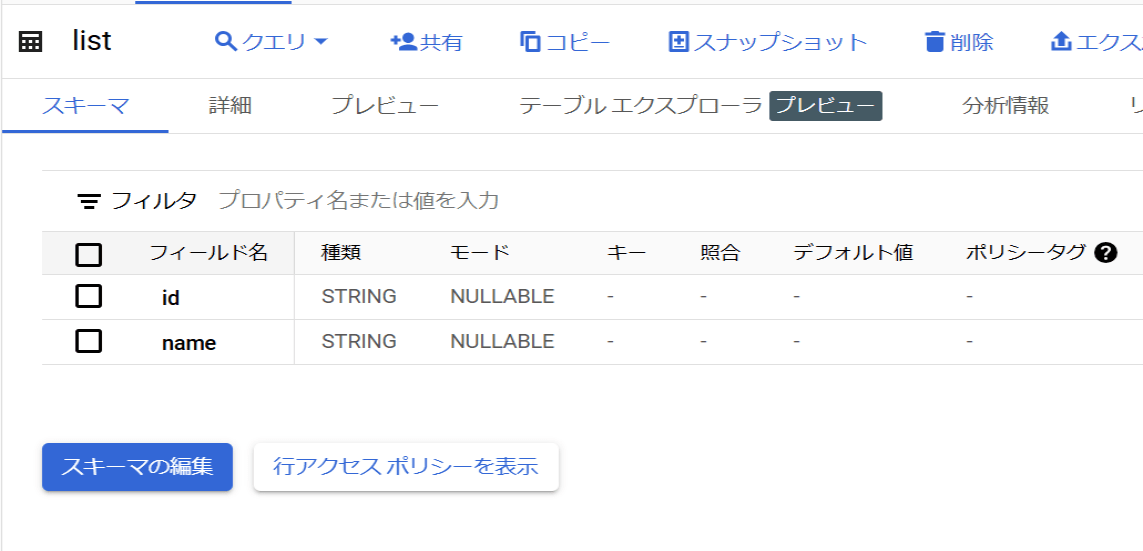
- テーブル:list
- スキーマ:id、name
パイプライン構築
Data Fusionインスタンス作成
Data Fusionインスタンスが作成されていない場合は、まずはGCPのData Fusionページからインスタンスを作成します。
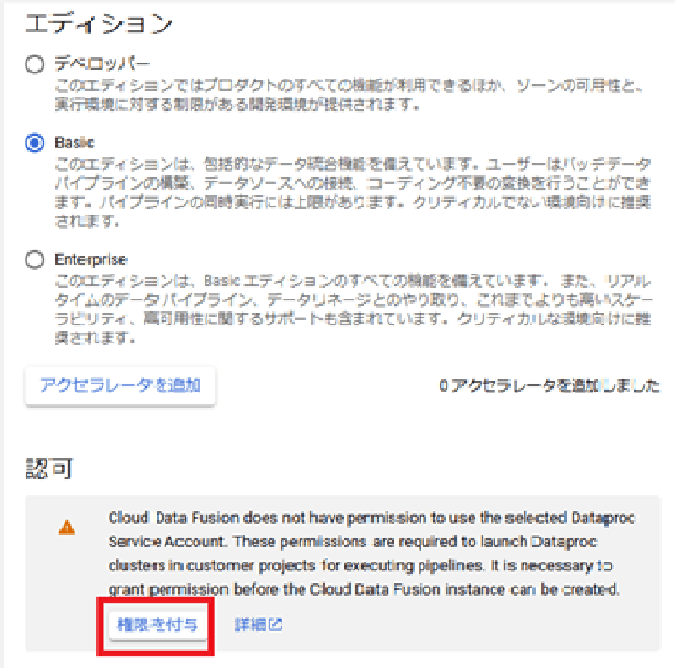
作成時のポイントとして、「認可」項目に以下の警告が出た場合は「権限を付与」ボタンをクリックしないと後続のパイプラインを実行する際にエラーがでたため、許可を押しています。
また、インスタンスの作成には数十分時間がかかるので注意が必要です。
リアルタイムパイプライン作成
インスタンスが作成されたら、インスタンス一覧の「インスタンスを表示」を押します。
以下の画面になるので、「List」を押します。

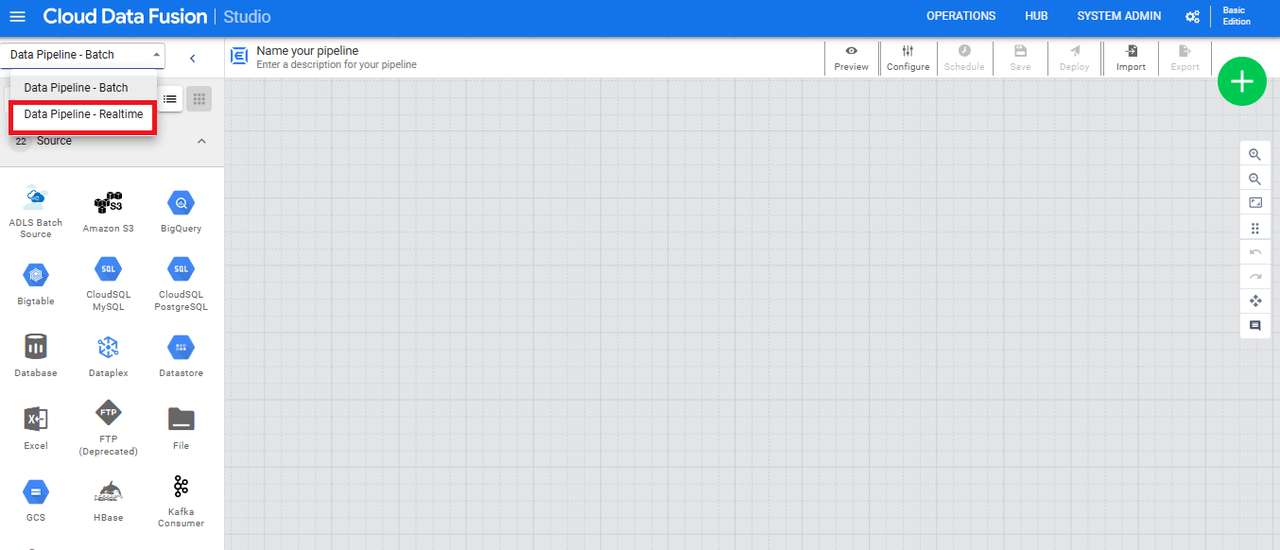
画面右上の+マークから「CREATE」を押します。

パイプラインの作成画面が出るので、左上部にある「Data Pipeline – Batch」を「Data Pipeline – Realtime」に変更します。
画面上部の赤枠の部分から、名前を任意の値に変更します。(今回は「Realtime-userlist」と命名)
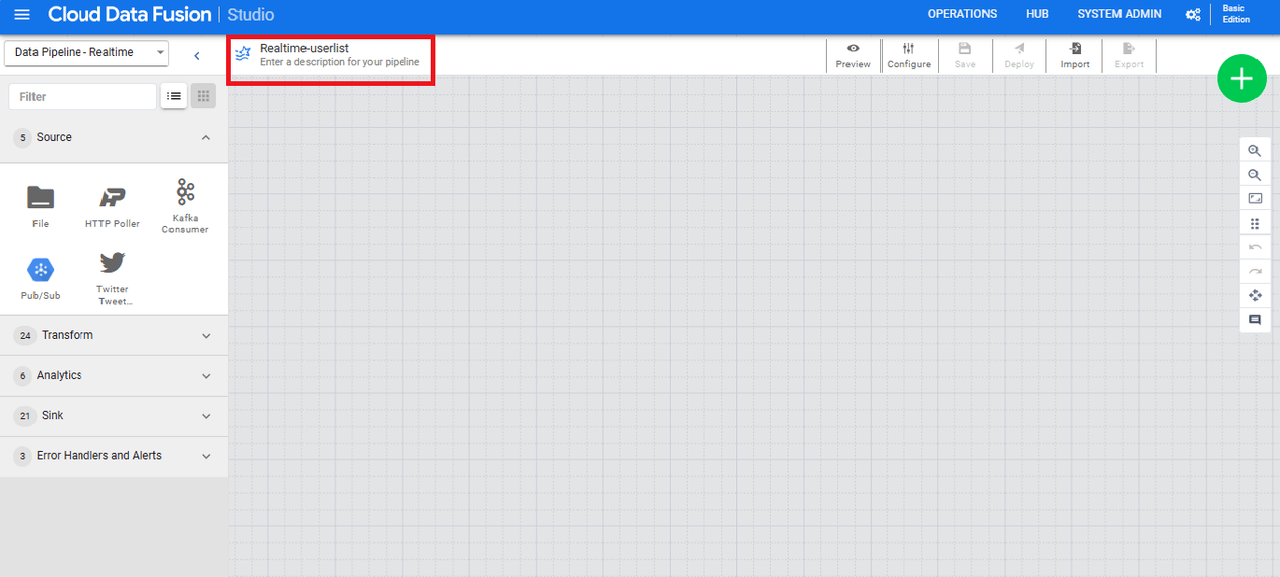
ここから先は、各プラグインを選択していきます。
Source:Pub/Sub
Sourceでは、データの投入元情報を設定します。
今回はデータ投入元はPub/Subのため、左側の「Source」項目から「Pub/Sub」をクリックします。
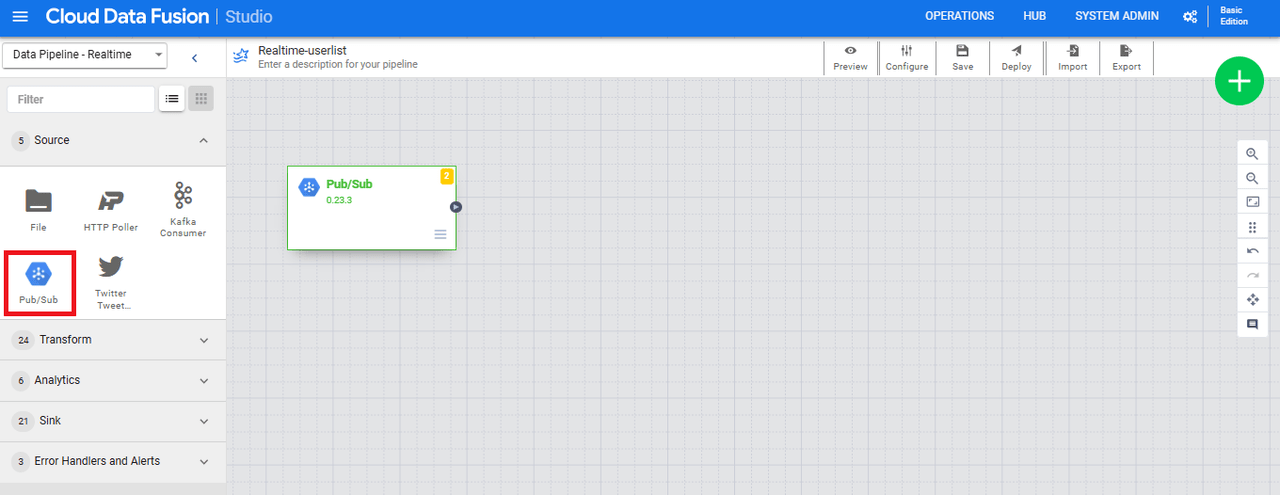
表示されたPub/Subプラグインにマウスカーソルを合わせると、「Properties」ボタンが表示されるのでクリックします。
表示された画面で、以下の情報を入力します。
- Reference Name:pubsub
- Subscription:userlist-sub
- Topic:userlist
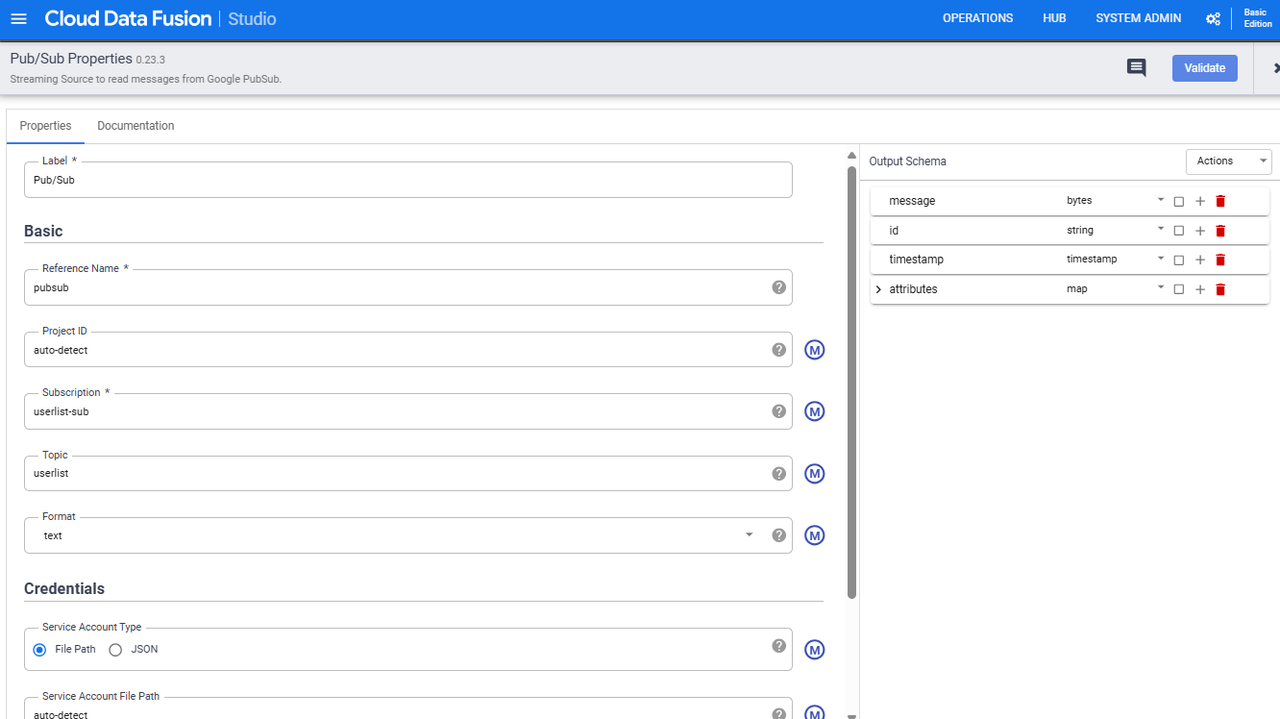
これでSourceの設定は完了です。
入力後、右上の×マークをクリックし、元の画面に戻ります。
Transform:Wrangler
次に入ってきたデータを変換するTransformの設定を行います。
「Transform」から「Wrangler」を選択します。
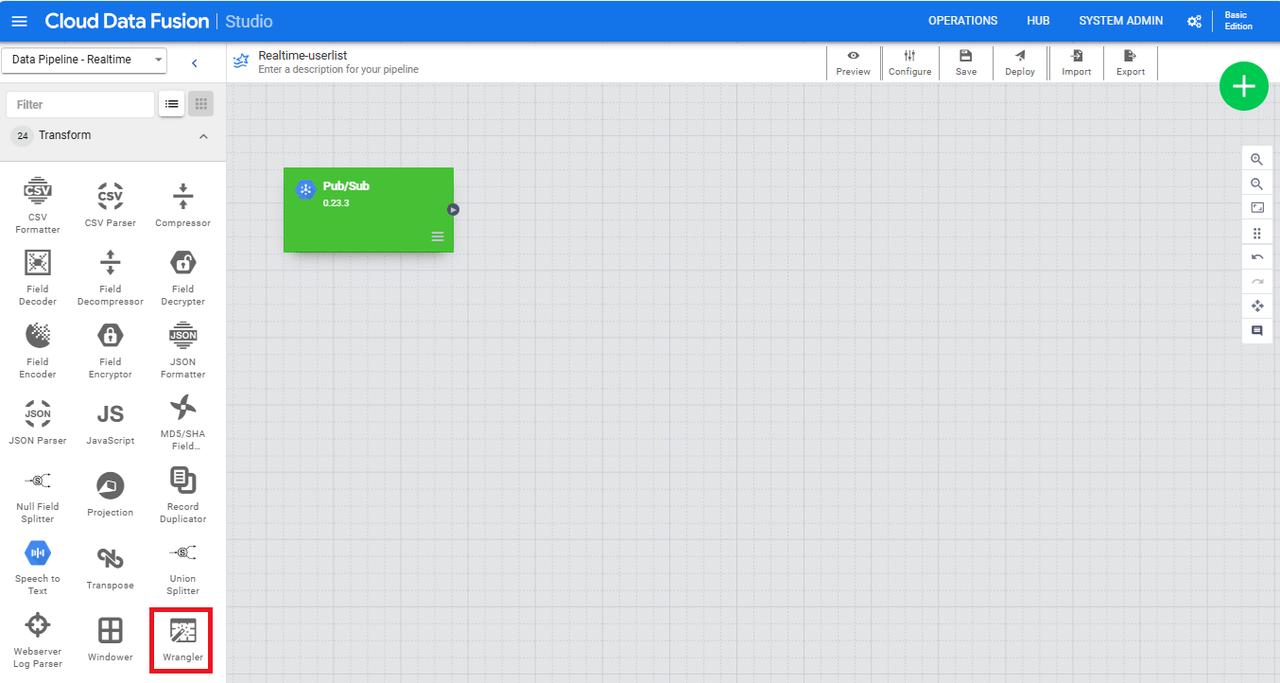
表示されたら「Pub/Sub」から矢印を引っ張ります。

WranglerのPropertiesの中身は以下にて設定します。
- Recipe:
keep :message
set-type :message string
split-to-columns :message \s+
drop :message
rename message_1 id
rename message_2 name
- Output Scema:id (string)、name (string) に設定し、チェックボックスにチェックを入れる
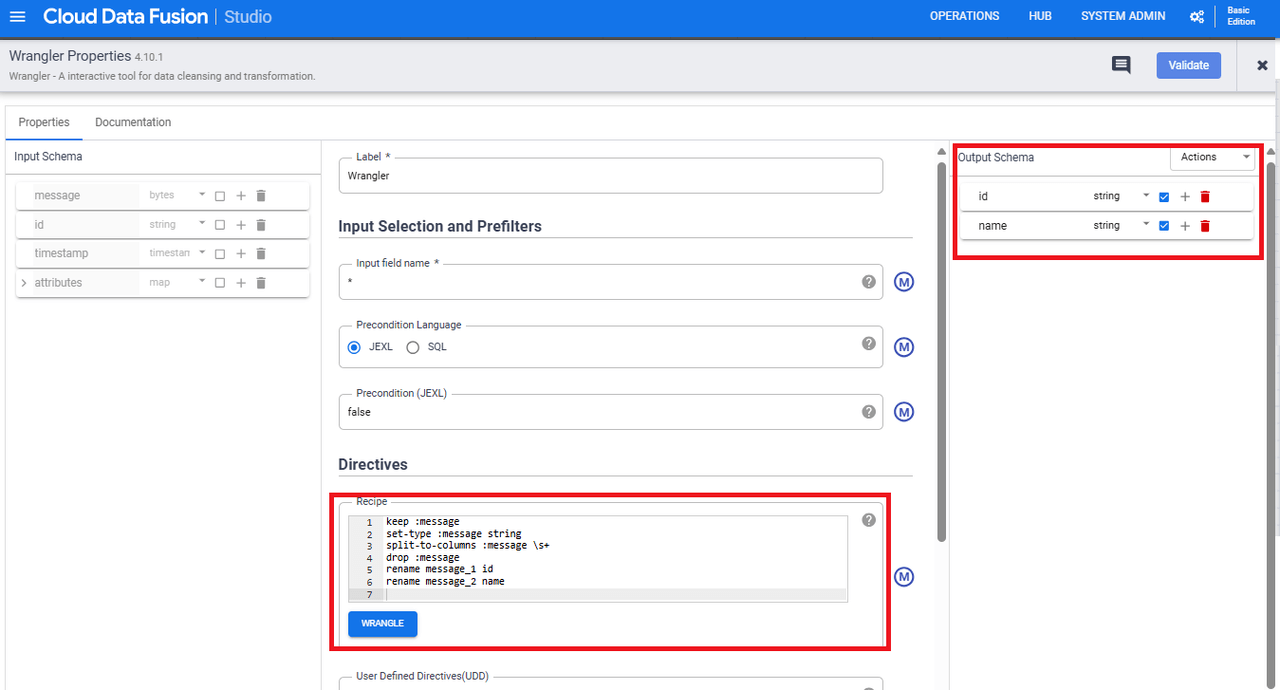
Recipeではデータを変換する処理を記述しています。
詳細な作成方法は割愛しますが、Pub/Subから連携されるデータは、JSON形式のmessageキーの値として引き渡されるため、受け取った値をBigQueryのスキーマに合わせて「id」と「name」に分割しています。
Output Scemaでは次のプラグインに引き渡すスキーマ情報を設定しています。
Sink:BigQuery
最後にデータを別リソースに引き渡すSinkを設定します。
今回はBigQueryにデータを投入したいため、「Sink」から「BigQuery」を選択します。
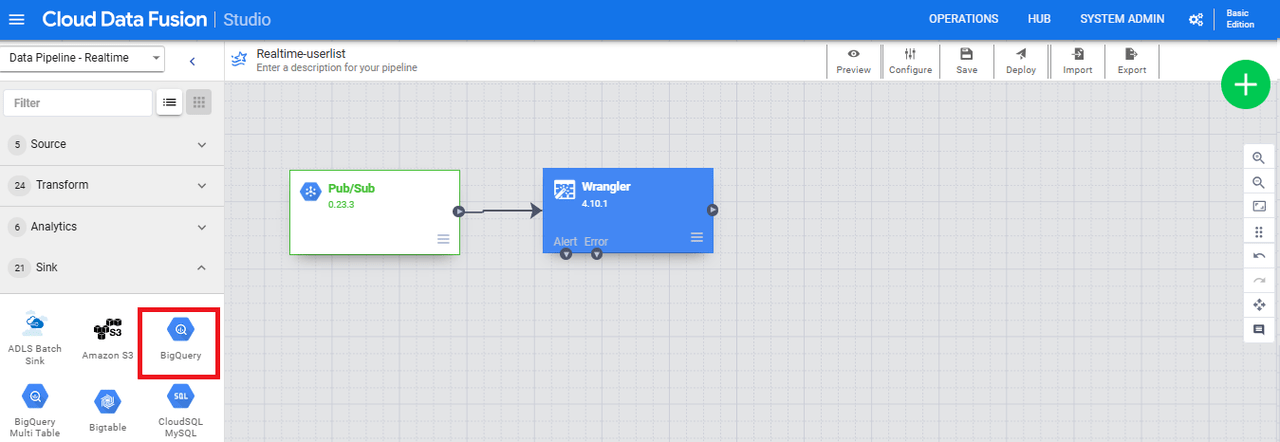
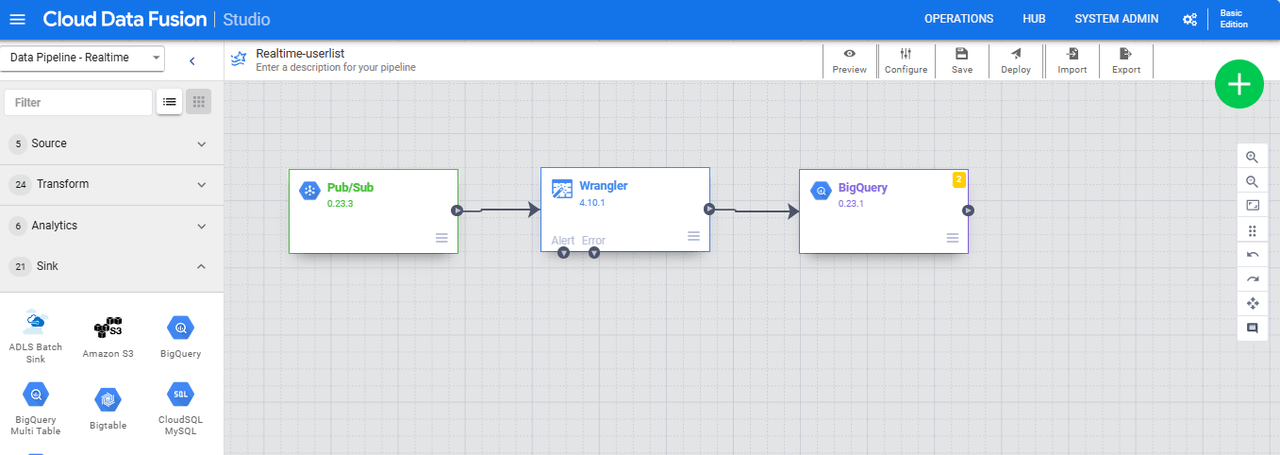
表示されたら「Wrangler」から矢印を引っ張ります。
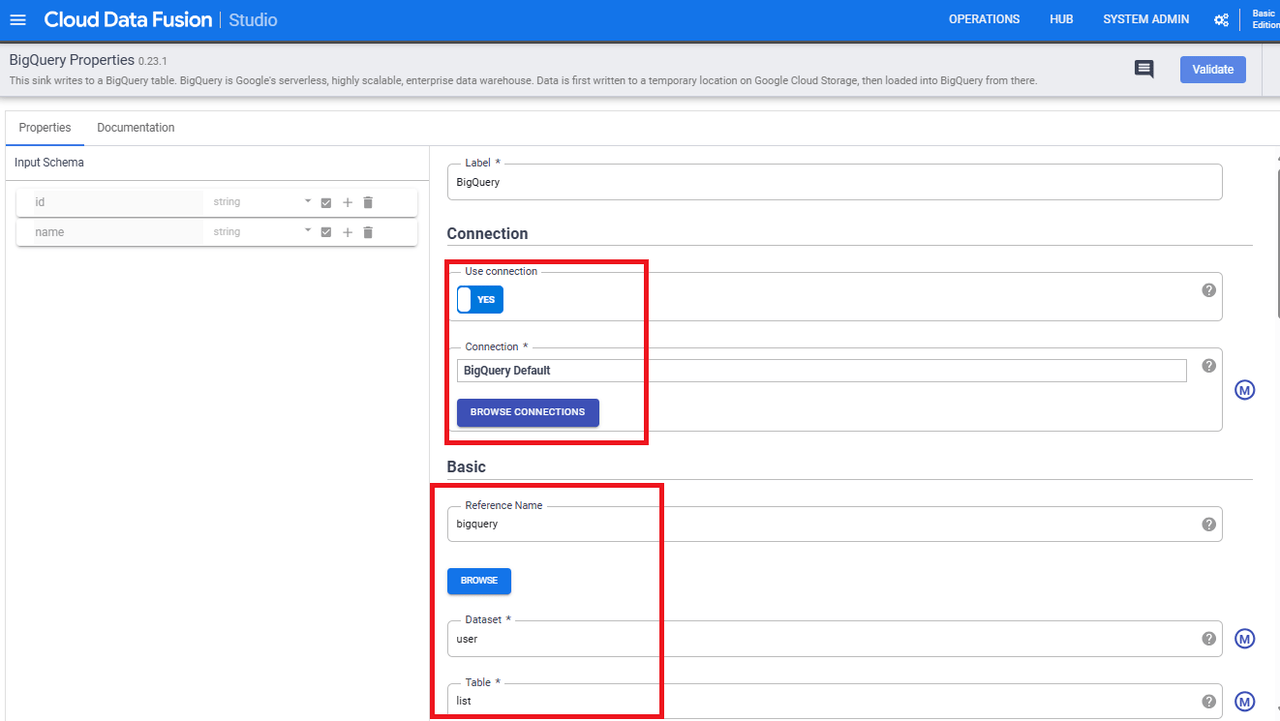
BigQueryのPropertiesの中身は以下にて設定します。
- Use connection:YES
- Connection:(BROUSE CONNECTIONSをクリックして選択)BigQuery Default
- Reference Name:bigquery
- Dataset:user
- Table:list
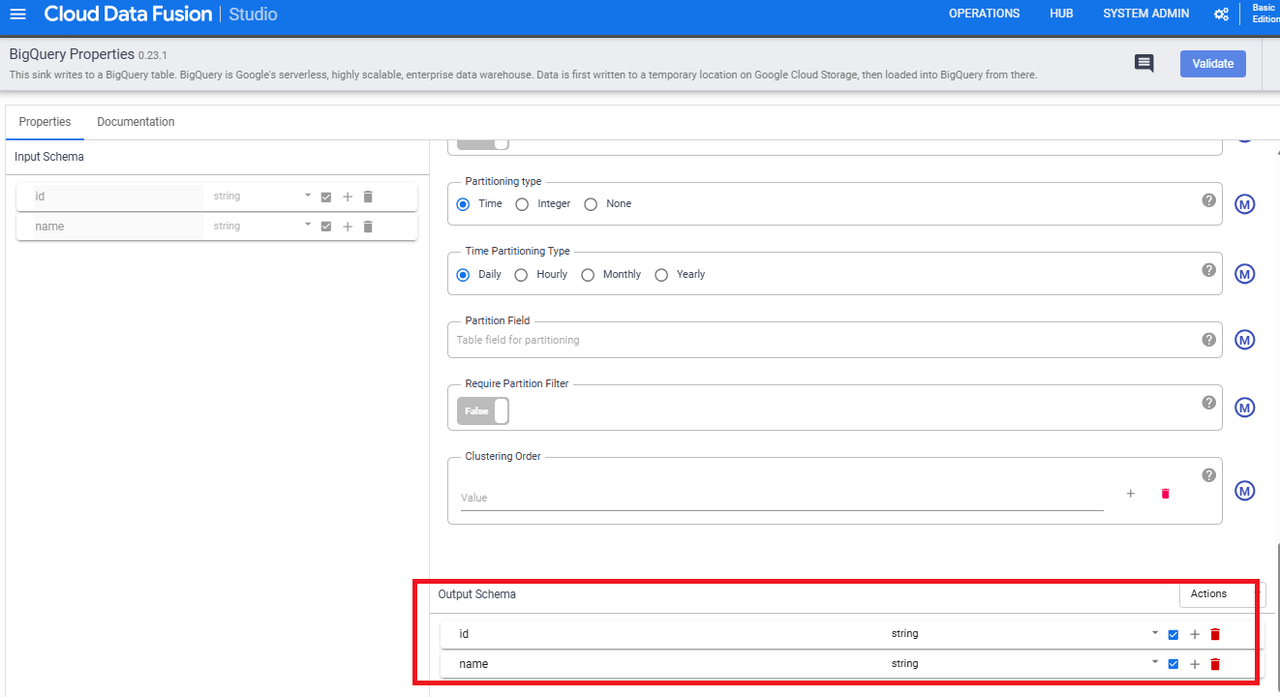
また、画面最下部にある「Output Scema」がWranglerと同様に「id」「name」と設定されていることを確認します。(されていなければWrangler同様に設定します)
Configure設定
Sinkの設定まで終わったら、パイプライン画面上部の「Configure」をクリックします。
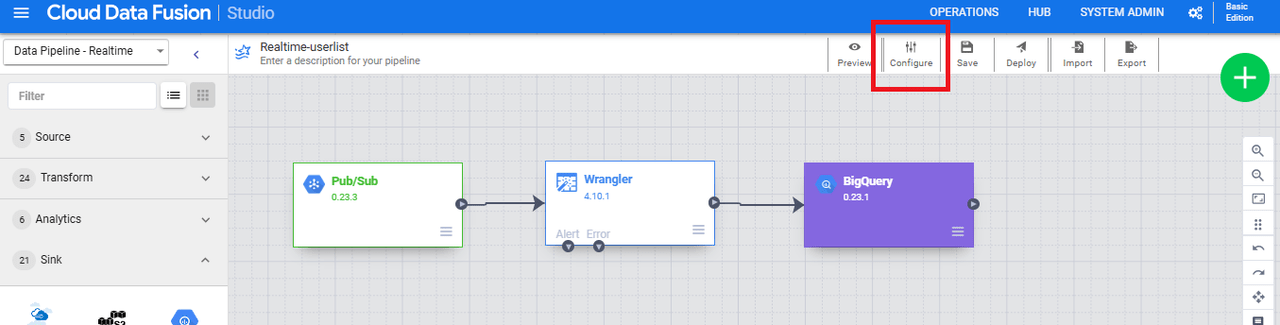
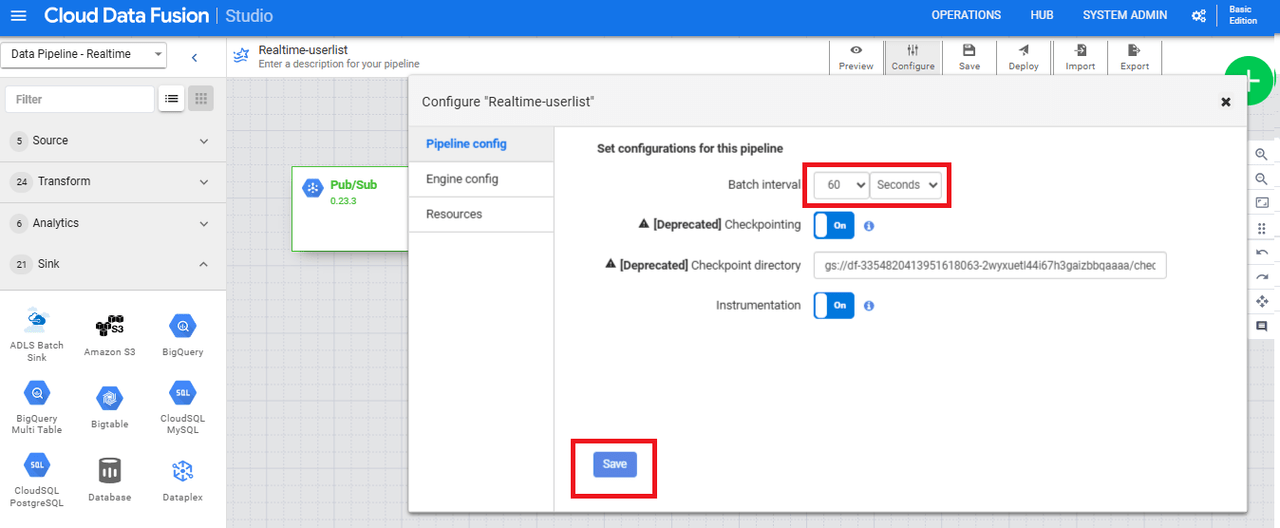
「Pipeline config」の「Batch Interval」を60秒に変更(デフォルトは10秒)後、Saveします。
パイプラインのデプロイ、実行
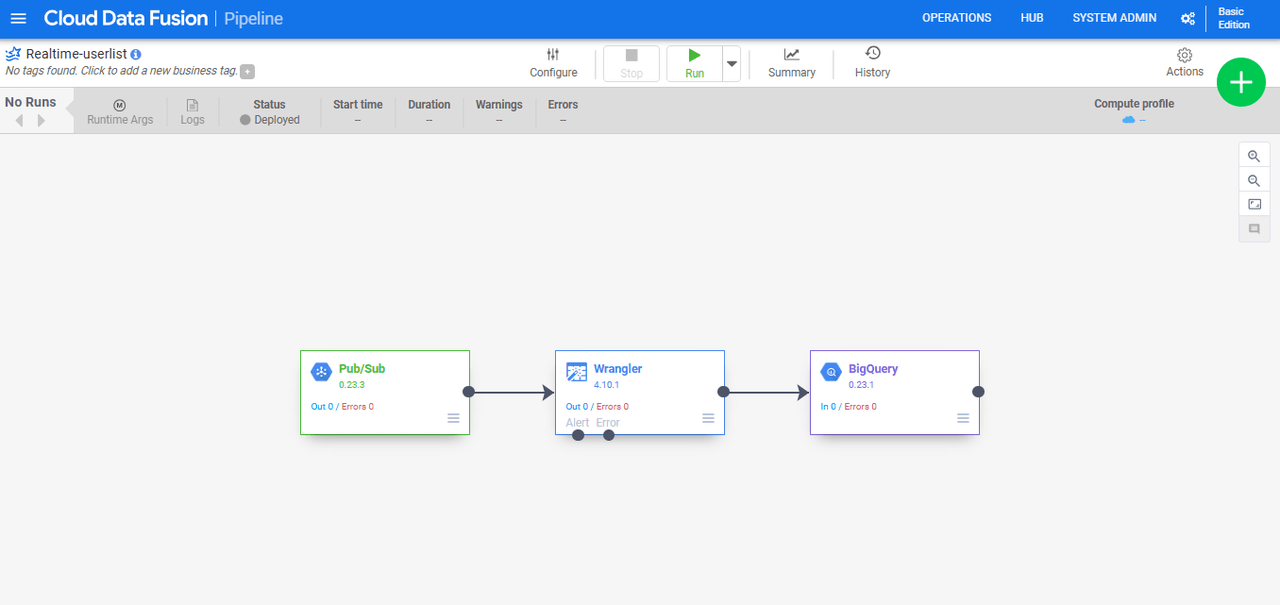
画面上部の「Save」ボタンをクリックします。

Saveが完了したら、隣の「Deploy」ボタンをクリックします。

編集画面から遷移したら、デプロイ完了です。
※注意点
リアルタイムパイプラインは、一度デプロイしたパイプラインは編集ができません。
そのため、設定値などを修正したい場合はコピーして新たに作り直し、再度デプロイする必要があります。(バッチパイプラインはデプロイ後も編集が可能です)
パイプラインを実行、データを投入してみる
デプロイしたパイプラインを実行します。
画面上部の「Run」ボタンをクリックします。

※実際に実行してみると、パイプラインが起動してデータをリアルタイムに受け付けるまではおよそ8分程度かかりました。
起動から8分程度経過し、「Status」が「Running」となっていたら、データ投入を開始します。
作成したPub/Subトピック内メッセージタブから「メッセージをパブリッシュ」をクリックします。
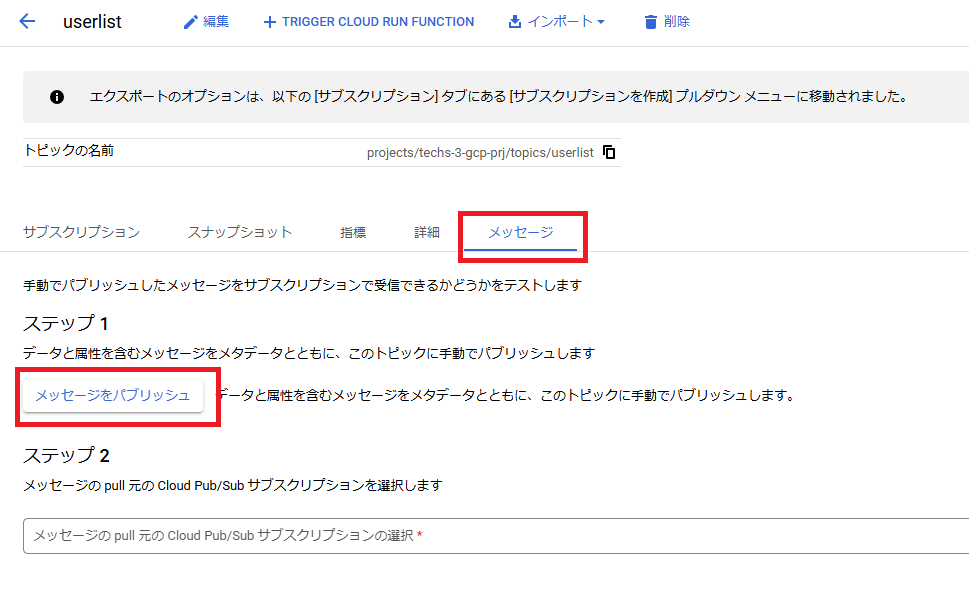
メッセージ本文に「1111 aaaa」と入力、「公開」ボタンをクリックします。

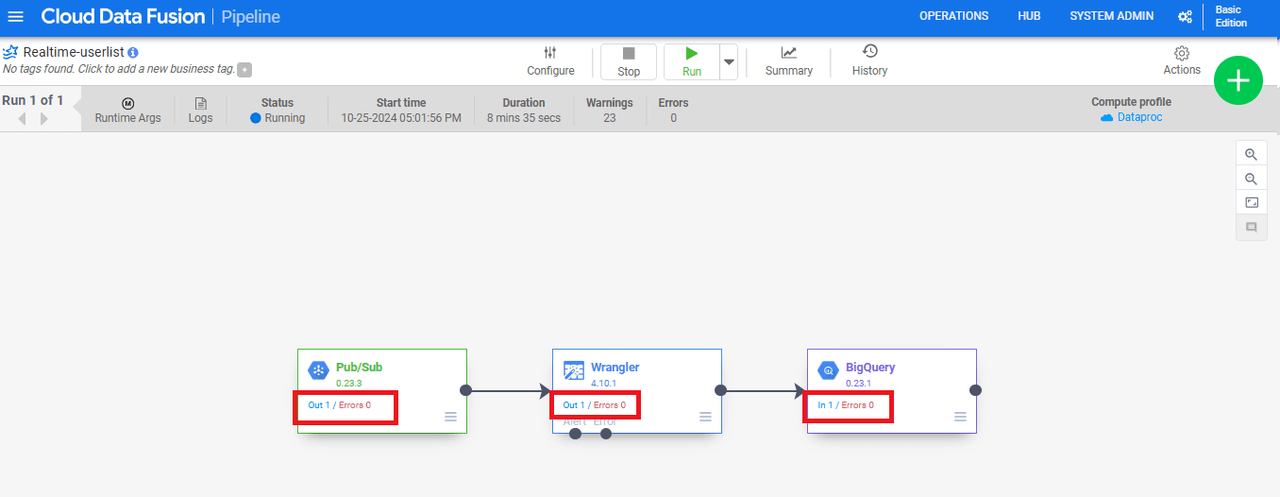
作成したBigQueryテーブルのプレビュータブに以下の通りにデータが格納されました!

パイプラインを見に行くと、各プラグインのIn/Outに流れたデータの数が表示されていました。
作成時の注意点
パイプライン構築にあたって、個人的に引っかかったポイントや注意点を以下に記載します。
- 権限周り
インスタンス作成時に、Data FusionにDataprocサービスアカウントへの権限を付与しないと、パイプライン実行がエラーとなりました。また、IAM周りも適切に設定してあげないとリソース間でうまくデータが流れないようです。
各環境と使用リソースに合わせて設定する必要があります。
- リアルタイムパイプラインはデプロイ後修正ができない
修正ができないので、都度値を変更して検証するには時間がかかりました。パイプライン内歯車マークから「Duplicate」をクリックするとパイプラインのコピーが出来上がるので、この方法で修正⇒再デプロイを実施する形となります。
- Batch Intervalを10秒から60秒に変更しないとパイプラインがうまく動かない
本記事内「Configure設定」にて記載しましたが、Batch Intervalを変更しなければ本パイプラインはうまく処理が進みませんでした。
Configure設定
Sinkの設定まで終わったら、パイプライン画面上部の「Configure」をクリックします。
「Pipeline config」の「Batch Interval」を60秒に変更(デフォルトは10秒)後、Saveします。
Batch IntervalはBigQueryへの書き込み時間の間隔となりますが、デフォルトの10秒だと書き込みの間隔が短く過剰アクセスが発生していると考えられ、GCPサポートからはBatch Intervalを60秒以上に設定して検証するように推奨されました。
また、本項目を変更するのはデプロイ前である必要があります。パイプラインデプロイ後は、画面上はBatch Intervalの変更をすることができますが、実際には設定が反映されずエラーとなってしまいました。
GCPサポートに問い合わせたところ、
リアルタイムパイプラインの内容は途中で編集ができず再作成と再デプロイが必要であり、エンジン側のパラメータ設定などについても再作成と再デプロイによって反映させる必要がある。
とのことで回答がありました。
なお、デプロイ後に同項目を編集してしまった場合は、実際に設定されている値と画面上の値の乖離が起きてしまいますが、実際に設定されている値については、パイプラインを実行した際のログ内以下項目にて確認ができます。
「 – INFO〜 Remember interval = 〜 ms」
- Data Fusionのコスト
Data Fusionは作成したインスタンスごとに課金がされるため、インスタンスを複数作成するとその分コストがかかります。
また、Data Fusionのインスタンスは停止再開ができないため、一度作成したら削除するまで課金され続ける点に注意が必要です。
インスタンスを削除すると作成していたパイプラインも同時に削除されてしまうため、インスタンスを削除する場合はパイプラインをJSON形式でエクスポートなどしておくと良いかもしれません。
詳しい料金は公式の料金ページをご確認ください。
料金 | Cloud Data Fusion | Google Cloud
最後に
今回はPub/SubをトリガーとしたData Fusionのリアルタイムパイプラインを構築してみました。
今回作成したパイプラインを使用すれば、発生したデータをCloud Pub/Subに向けて流すように設定するだけで、リアルタイムにBigQueryにデータを格納することができ、データ活用に役立ちそうですね。
今回の構築で初めてGCPを触ったのですが、Data Fusionはコードを書かずにパイプラインを構築できるため非常に扱いやすかったです。
ただGCPの権限周りについては、サービスアカウントに権限を追加しないと他リソースとの連携ができない場面があり、リソース作成時には都度勉強が必要だと思いました。
皆さんもData Fusion使ってみてはいかがでしょうか。