

こんにちは、広野です。
先日、React アプリに Amazon Bedrock に問い合わせる画面をつくってみた系の記事を公開いたしました。

今回は、Agents for Amazon Bedrock に問い合わせる画面をつくってみましたので紹介します。前回の記事の内容と似ていますが、一部アーキテクチャと API の仕様が異なります。
Agents for Amazon Bedrock についてはこちら。簡単に説明しますと、複数のデータソースの情報をもとにユーザからの問い合わせに自然言語で回答してくれるオーケストレーションサービス?のようなものです。今流行りの RAG 構築にも使われます。

それでは、目次です。
つくったもの
一般的な質問はテキスト生成系 AI モデルから、当社 (SCSK 株式会社) に関する質問は別途用意したナレッジベースから情報を取得し、自然言語で返してくれます。最小構成の RAG という感じです。
- 一般的な質問(京都のお勧め観光地)
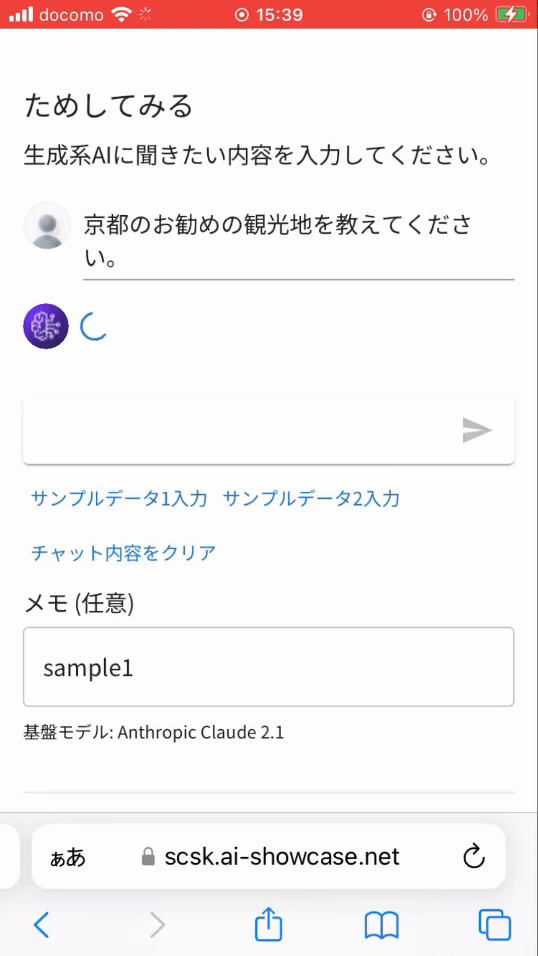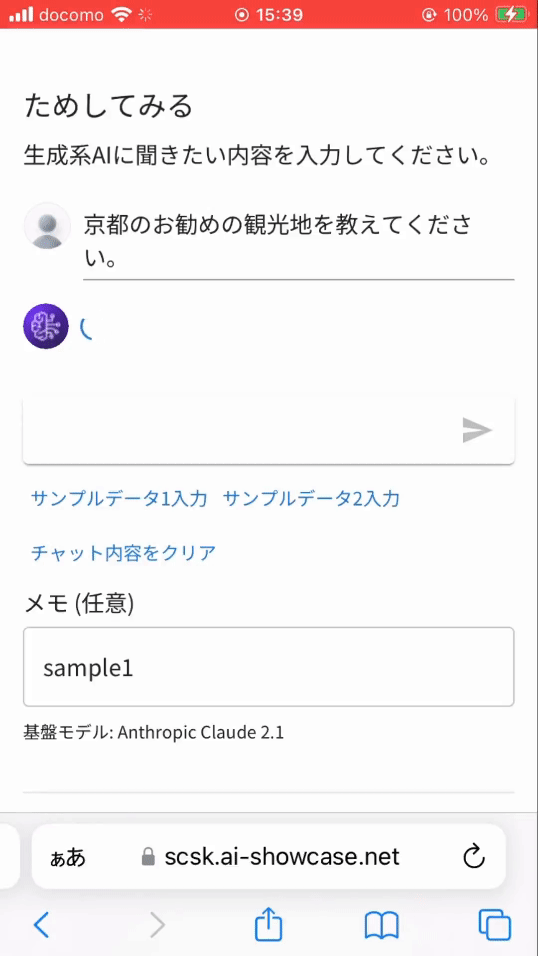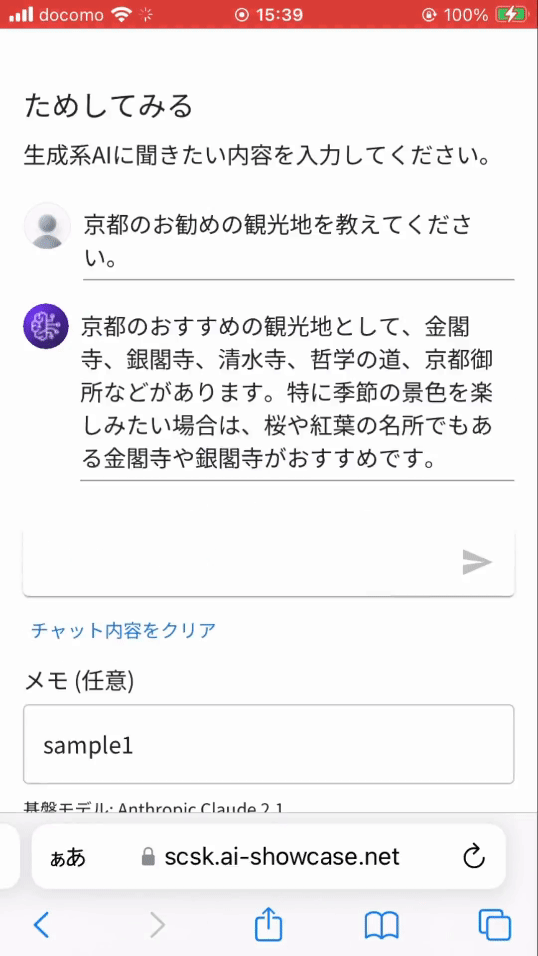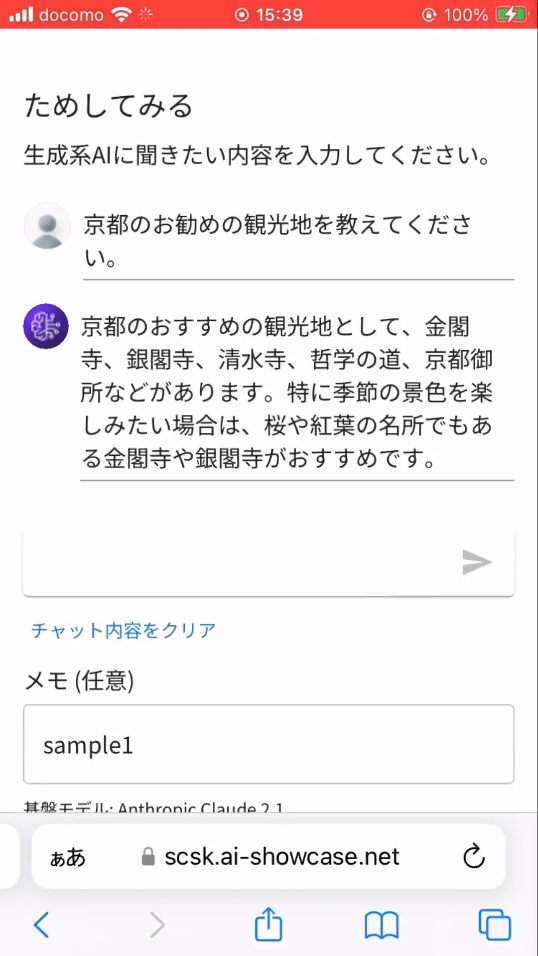
- 当社に関する質問
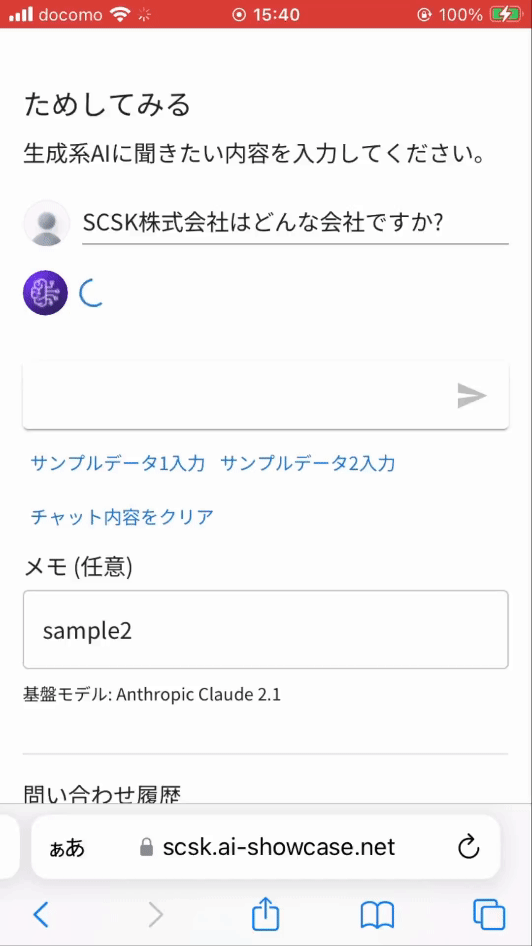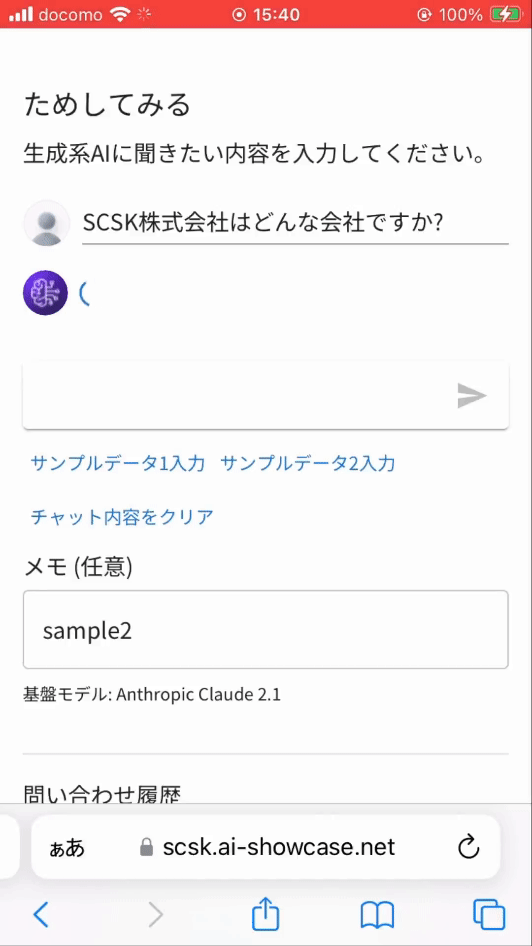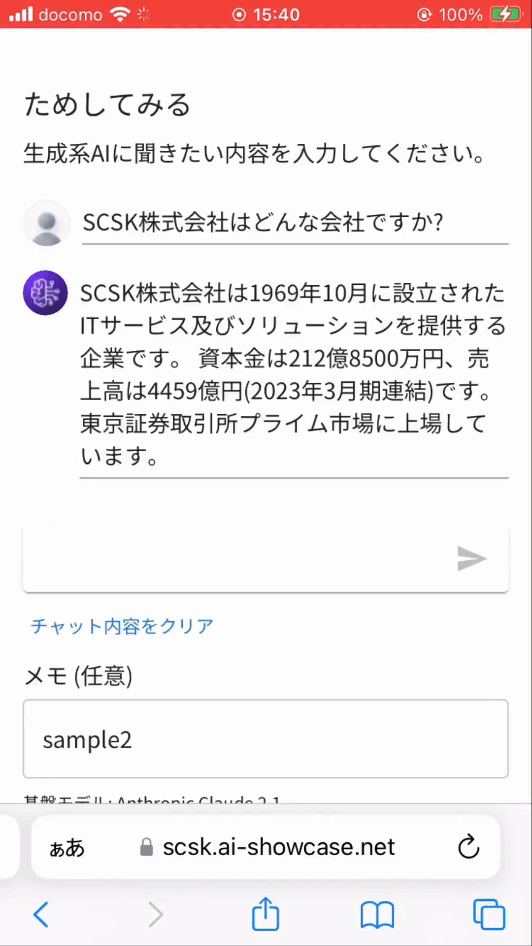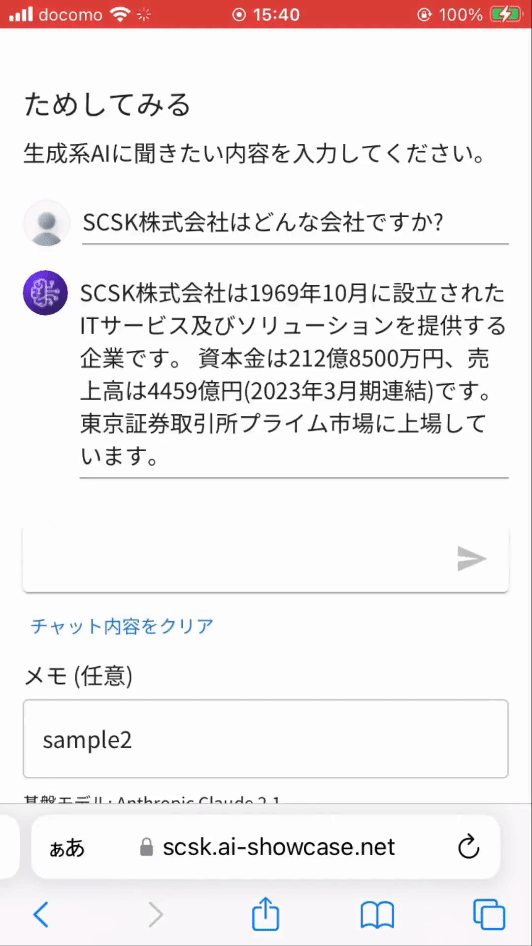
※ 実は当社に関する質問を一般的な質問としてテキスト生成系 AI に投げると、残念なことに誤った回答を返します。(ハルシネーションと言われる現象)そのため、当社に関する質問は独自データベース (Knowledge Base) から情報を取得し回答するよう作り込んでいます。それが RAG と呼ばれる機能です。
※ 上記画像は問い合わせから返事までの待ち時間をカットしています。実際には、1分近い待ち時間が発生しています。
アーキテクチャ
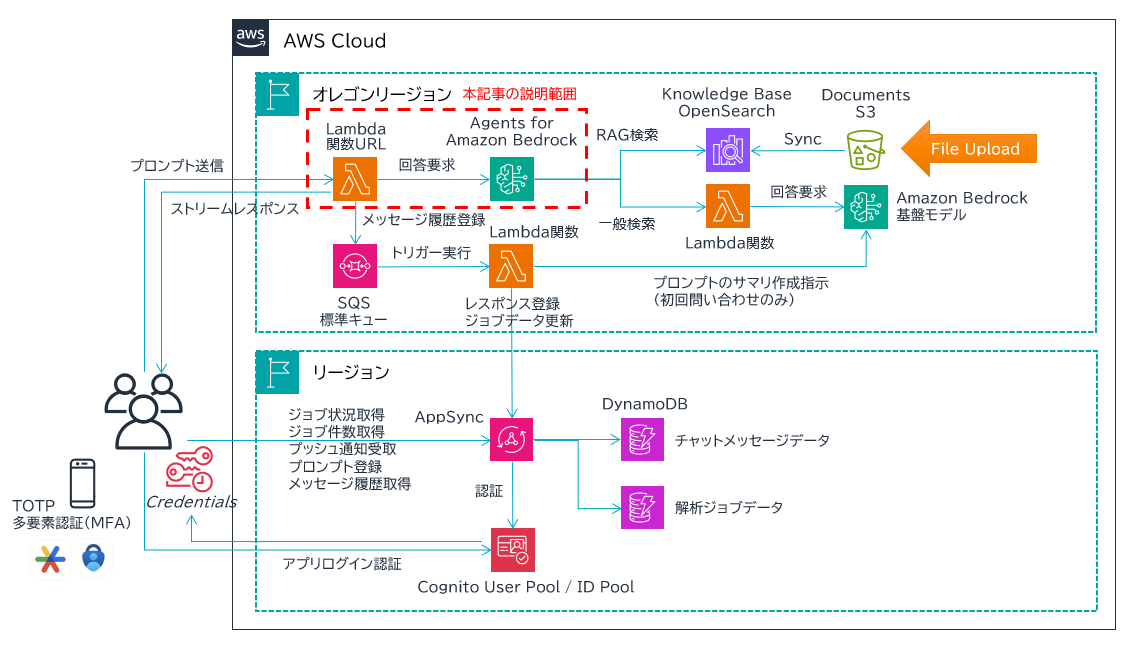
- RAG 用の Knowledge Base (ベクトルデータ) には、Agents for Amazon Bedrock が自動作成してくれる Amazon OpenSearch Service Serverless を使用しています。別途 Amazon S3 バケットを作成し、そこに当社公式ホームページの情報を PDF 化したファイルを格納し、OpenSearch に Sync させます。
- 一般的な回答をするために使用する生成系 AI の基盤モデルには、Amazon Bedrock の Anthropic Claude 2.1 を使用しています。
- ユーザからの問い合わせ内容が当社 (SCSK 株式会社) に関連するものであれば Agents for Amazon Bedrock が自動的に OpenSearch 内の情報を取得します。それ以外の内容であれば AWS Lambda 関数経由で Claude 2.1 モデルに問い合わせます。
- Agents for Amazon Bedrock に問い合わせるのは AWS Lambda 関数 (Node.js 20) です。関数 URL を持たせており、React アプリから直接呼び出します。Lambda 関数を介さずに Agents for Amazon Bedrock の API に直接問い合わせることもできましたが、レスポンスのデータ構造がわからずあきらめました。
- その AWS Lambda 関数からのレスポンスはレスポンスストリーミング対応にしています。それにより、Agents for Amazon Bedrock が回答を作成しつつ、レスポンスを画面に表示できるようにしています。ただ、実際に出来上がった画面を見てみると流れるようなテキスト表示はされていないので引き続き経験を積んで確認していきたいと思います。Agents for Amazon Bedrock を呼び出す API はレスポンスストリーミング対応の InvokeAgentCommand を使用しています。
補足ですが、React アプリから AWS Lambda 関数 URL を認証付きで呼び出す構成は以下参考記事の構成にしています。本記事では説明を割愛します。

また、Agents for Amazon Bedrock により RAG 用の Knowledge Base を作成する方法については、以下の記事が参考になります。マネジメントコンソールで簡単につくれます。

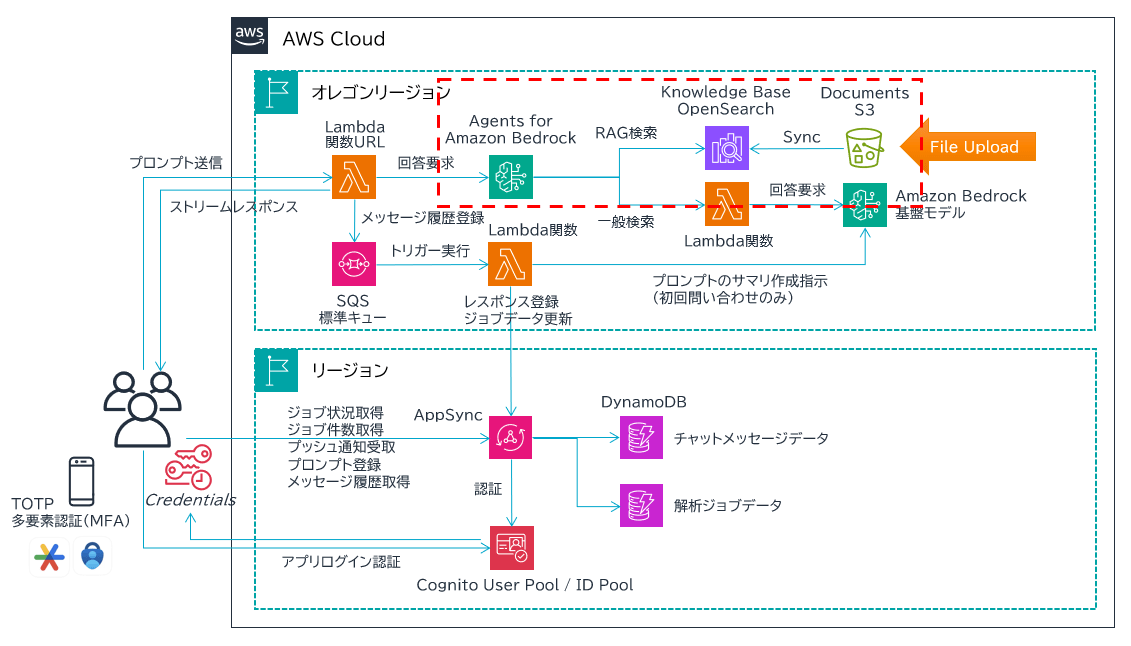
図で表すと以下の赤枠部分のことです。ここについては今後の別記事でもう少し踏み込んで解説したいと思います。
AWS Lambda 関数コード
AWS Lambda 関数に関数 URL を持たせる設定や、レスポンスストリーミングを有効にする設定は以下 AWS 公式ドキュメントを参照ください。この点において難しいことはありません。


InvokeAgentCommand の API が Agents for Amazon Bedrock からのレスポンスを chunk 分割された状態で受け取るので、chunk ごとに React アプリへのレスポンス用ストリーム responseStream に放り込んでいます。レスポンスは Blob なので、途中で人が読み取れるテキストデータに変換する処理が入っています。
const { BedrockAgentRuntimeClient, InvokeAgentCommand } = require("@aws-sdk/client-bedrock-agent-runtime");
const bedrockagent = new BedrockAgentRuntimeClient({region: "${AWS::Region}"});
exports.handler = awslambda.streamifyResponse(async (event, responseStream, _context) => {
try {
const args = JSON.parse(event.body);
if (args.prompt == '') {
responseStream.write("No prompt");
responseStream.end();
}
const agentInput = {
"agentId": "BedrockAgentId", //BedrockのエージェントIDが入る
"agentAliasId": "BedrockAgentAliasId", //BedrockのエージェントエイリアスIDが入る
"sessionId": args.jobid, //セッションIDを入れる
"enableTrace": false,
"endSession": false,
"inputText": args.prompt, //プロンプトを入れる
"sessionState": {
"promptSessionAttributes": { //任意で情報を入れることが可能
"serviceid": args.serviceid,
"user": args.username,
"datetime": args.datetime
}
}
};
const command = new InvokeAgentCommand(agentInput);
const res = await bedrockagent.send(command);
const actualStream = res.completion.options.messageStream;
const chunks = [];
for await (const value of actualStream) {
const jsonString = new TextDecoder().decode(value.body);
const base64encoded = JSON.parse(jsonString).bytes;
const decodedString = Buffer.from(base64encoded,'base64').toString();
try {
chunks.push(decodedString);
responseStream.write(decodedString);
} catch (error) {
console.error(error);
responseStream.write(null);
responseStream.end();
}
}
responseStream.end();
} catch (error) {
console.error(error);
responseStream.write('error');
responseStream.end();
}
});
Python を採用していない理由は、AWS 公式ドキュメントにもありますが AWS Lambda 関数がレスポンスストリーミングをネイティブにサポートしているランタイムが Node.js のみだからです。※執筆時点
sessionId というパラメータを Agents for Amazon Bedrock に送信しています。UUID など一意の ID を生成して入れることで、2回目以降の問い合わせも同じ sessionId であれば過去の問い合わせ内容を自動的に関連付けて回答してくれます。便利!
私のケースでは sessionId はアプリ側でも必要な情報なので、アプリ側で生成した ID を Lambda 関数に渡しています。
React コード
React アプリ側は、Lambda 関数 URL を呼び出すために fetch を使用します。
AWS Lambda 関数 URL から chunk 分割されたレスポンスが送られてくるので、それを順次、直前の chunk と繋げて state に突っ込むだけの、非常に原始的なループのコードです。もっと簡単かつ効率的な処理になる SDK を AWS が開発してくれることを期待しております。
//レスポンス表示用、セッションID用state
const [response, setResponse] = useState("");
const [jobid, setJobid] = useState();
//date、セッションID(jobid)とか
const dt = new Date();
const datetime = dt.toISOString();
setJobid(uuidv4());
//送信するデータ
const body = {
prompt: prompt,
jobid: jobid,
serviceid: serviceid,
user: username,
datetime: datetime
};
//Lambda関数URL呼出
try {
const res = await window.fetch(
"https://xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.lambda-url.us-west-2.on.aws",
{
method: 'POST',
body: JSON.stringify(body),
headers: signedRequest.headers //認証用の署名(説明割愛)
}
);
const reader = res.body.getReader();
const decoder = new TextDecoder();
const sleep = ms => new Promise(resolve => setTimeout(resolve, ms));
while (true) {
const { value, done } = await reader.read();
if (done) break;
const chunk = decoder.decode(value, { stream: true });
if (chunk) {
setResponse(prevData => prevData + chunk);
}
await sleep(100); //100msごとに届いたchunkを処理(=画面更新)
}
} catch (error) {
console.error('Error fetching:', error);
}
sleep のミリ秒数を調整することで、受け取ったレスポンス文章表示の流暢さを調整できます。
すみません、チャットボット画面の UI についてはややこしくなるので割愛させて頂きます。考え方としては、上記コード内にある response ステートをユーザのプロンプト prompt と交互に並べて表示することになります。
セッション ID はコード内では jobid という state に格納していますが、過去の問い合わせとの関係性をクリアするときには jobid を取得し直す処理が必要です。
まとめ
いかがでしたでしょうか。
Amazon Bedrock のモデルを呼び出すコードと Agents for Amazon Bedrock とではレスポンスの仕様が異なるため全く同じというわけにはいきませんでした。AI/ML 領域は技術革新が激しいので、本記事の陳腐化も早いと思います。引き続きキャッチアップしていきたいと思います。
本記事が皆様のお役に立てれば幸いです。