

 本記事は 夏休みクラウド自由研究 8/27付の記事です。 本記事は 夏休みクラウド自由研究 8/27付の記事です。 |
こんにちは。SCSKの島村です。
Googleが提供するオープンAIモデルGemmaについてご存じでしょうか???
Gemmaは、Googleが公開した商用利用可能なオープンモデルで、「軽量かつ高性能なLLM」という特徴があります。
本記事では、
『Gemma』について色々調査いたしましたので、それらを整理してみたいと思います。
また、実際にGoogle Cloud上でGemmaを展開し、利用してみました。その魅力について少しだけご紹介させていただければと思います。
Google Gemmaとは??
Gemma は、「アプリケーション内、ハードウェア、モバイル デバイス、ホスト型サービス」で実行できる
軽量型の生成 AIオープンモデルセットです。
(Geminiモデルの作成に使用されたのと同じ研究とテクノロジーから構築された、軽量で最先端のオープンモデルです。)
Gemma モデルは、ノートパソコン、ワークステーション、または Google Cloud で実行できます。
また、Colab や Kaggle ノートブック、JAX、PyTorch、Keras 3.0、Hugging Face Transformers などのフレームワークなどでもサポートをしています。
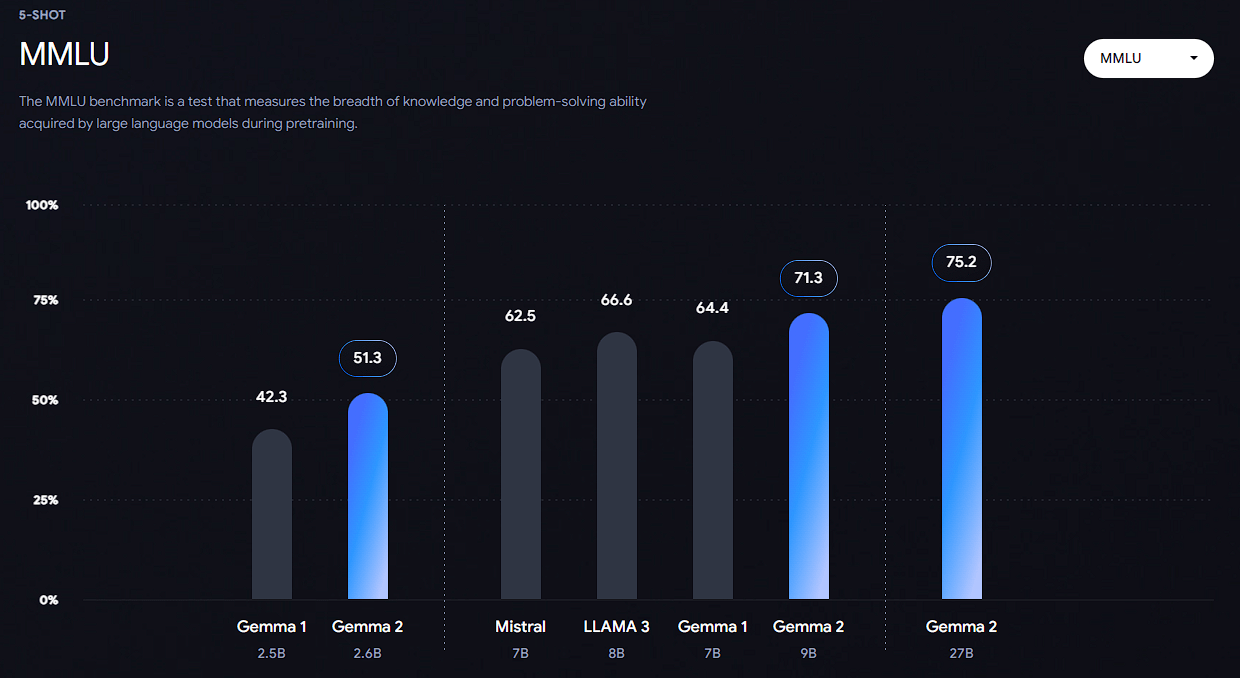
大規模言語モデル(LLM)の性能を評価するためのベンチマークの一つであるMMLUでも
他のモデルと比較して性能が高いとのことです。(2024-06-27時点)
様々な分野、多岐にわたるタスクを網羅した膨大な量の質問と回答のペアで構成されており、LLMが幅広い知識と理解能力を持っているかを測るために用いられます。
- 横軸: 評価されたLLMのモデル名と、そのモデルのパラメータ数(数十億単位)
- 縦軸: MMLUベンチマークにおける正解率(%)
Gemma モデル ファミリー
Gemmaは「様々なサイズや用途に合わせて、複数のモデルが提供」されています。
それらを表で整理してみました。
| Gemma 2 | 200 億、900 億、270 億のパラメータ サイズで利用可能です。 3 つの新しいパワフルで効率的なモデルを提供し、すべてセーフティ機能を備えています。 |
| Gemma 1 | 軽量でテキストからテキストを生成する、デコーダのみの大規模言語モデルです。 テキスト、コード、数学コンテンツの膨大なデータセットでトレーニングされます。 |
| RecurrentGemma | 再帰型ニューラル ネットワークとローカル アテンションを活用してメモリ効率を向上させる、技術的に異なるモデルです。 |
| PaliGemma | PaLI-3 に着想を得たオープンなビジョン言語モデル SigLIP と Gemma を活用しており、幅広い視覚言語タスクに転送するための汎用モデルとして設計されています。 |
| CodeGemma | CodeGemma は、オリジナルの事前トレーニング済み Gemma モデルの基盤を利用して、ローカル コンピュータに適したサイズの強力なコード補完と生成機能を提供します。 |
Google AI Studio上でGemmaを試してみた。
ここからは実施にGemmaモデルを利用してみたを共有できればと思います。
まずは簡単に試してみるということで、『Google AI Studio』からモデルを選択して、そのレスポンスを見てみます。
Google AI Studioとは??
Googleが提供する、生成AIモデルであるGeminiを使って、様々なタスクを実行できるプラットフォームです。
ユーザーフレンドリーなインターフェースによって開発の経験がないユーザーでも簡単に利用可能なことが特徴です。
Google AI Studioへのログインはこちら
Google AI StudioでモデルGemmaを選択してみる。
Gemmaは3つのサイズから選択可能です。
実際にpromptを入力して実行してみました。☟☟☟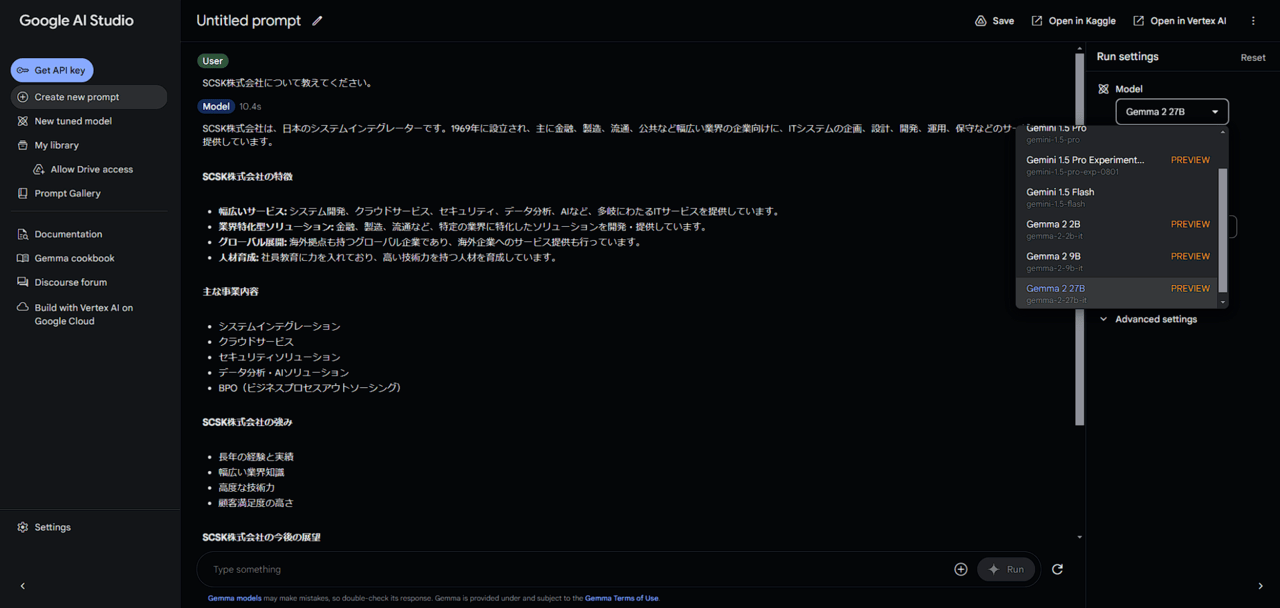
Google Cloud上でGemmaを動かしてみた。
Vertex AI で Gemma モデルを使用すると、
開発者はモデルの調整、管理、監視をシンプルかつ直感的に行えるエンドツーエンドのMLプラットフォームを活用できます。
Google CloudからGemmaを利用するには???
Gemma は、Vertex AI Model Garden からノートブックを起動して利用開始することができます。
また、Google Kubernetes Engine や Dataflow などのGoogle Cloud プロダクトでも利用可能です。
Google Cloud から利用できるGemma モデルのサイズと機能 https://ai.google.dev/gemma?hl=ja
https://ai.google.dev/gemma?hl=ja
GCE(ローカル環境)上にGemamモデルをデプロイして使ってみる!!!!
今回、Gemmaの実行環境としてOllamaを利用しました。
*『Ollam』はローカル環境でLLMモデルを動かすことができる無料でツールあり、使いやすいインターフェースが特徴です。
- GCEインスタンを作成する。今回はGPUとしてNVIDIA T4を利用しました。

- 作成したインスタンスにSSHして DokcerとOllamaをインストールする。
Ollamaは公式ドキュメントの手順通りにインストールをします。
![]() Download Ollama on LinuxDownload Ollama for Linuxollama.com
Download Ollama on LinuxDownload Ollama for Linuxollama.comcurl -fsSL https://ollama.com/install.sh | sh
- Ollama Open WebUIを起動する。
インストールできたら以下のコマンドでDockerを起動します。sudo docker run -d --network=host -v open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://127.0.0.1:11434 --name open-webui --restart always ghcr.io/open-webui/open-webui:main
- ブラウザからOllama Open WebUIにアクセスする。
正しく起動でき、アクセスできると以下の画面が現れます。
*起動したOpenWebUI(GCE)へのアクセスは適切なネットワークとファイアウォールの設定を実施して接続してください。
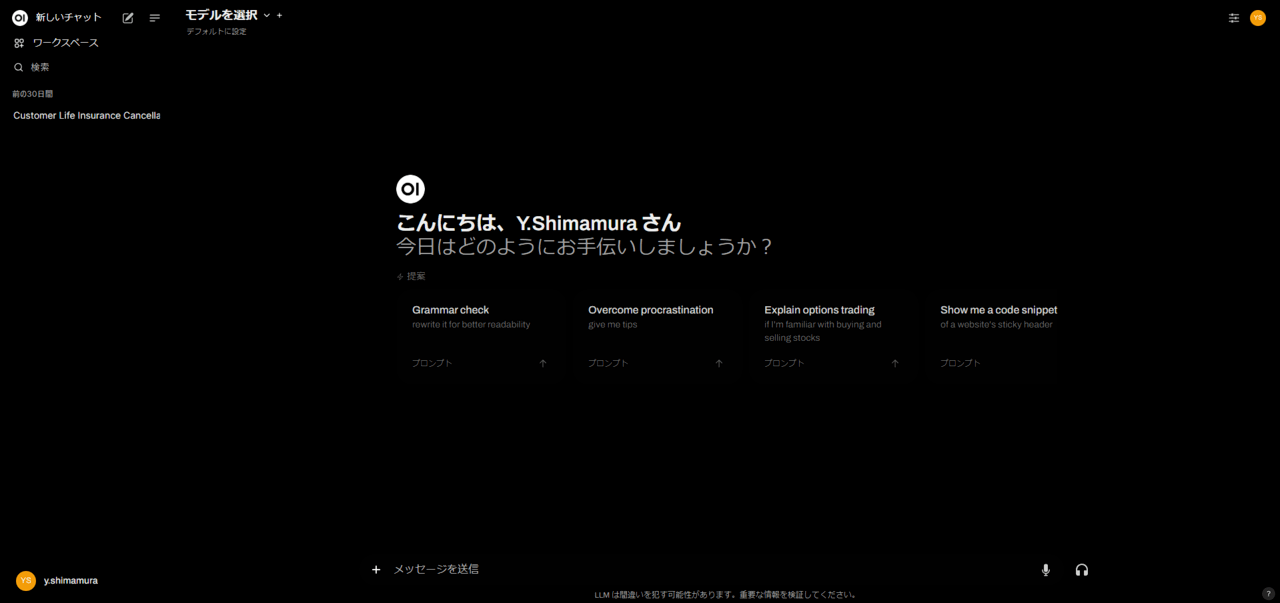
- モデル(Gemma)を選択し、プロンプトを送信してみる。
今回は「Gemma:7b」を利用してみした。
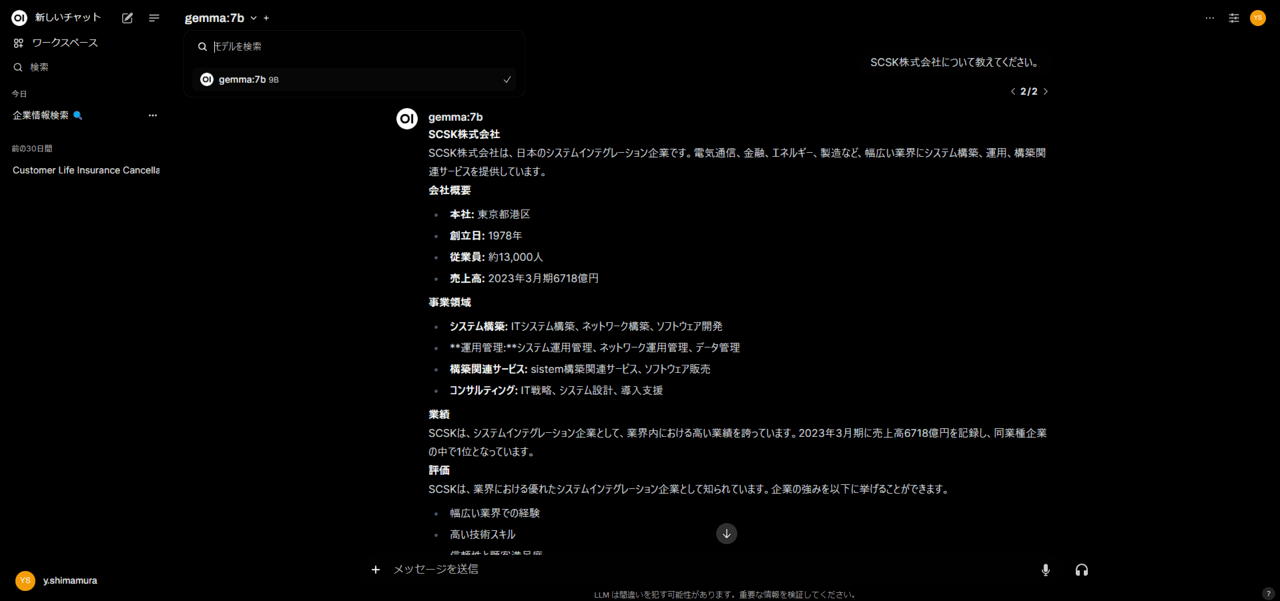
Gemmaをローカル環境でも利用することができました!!!!!!
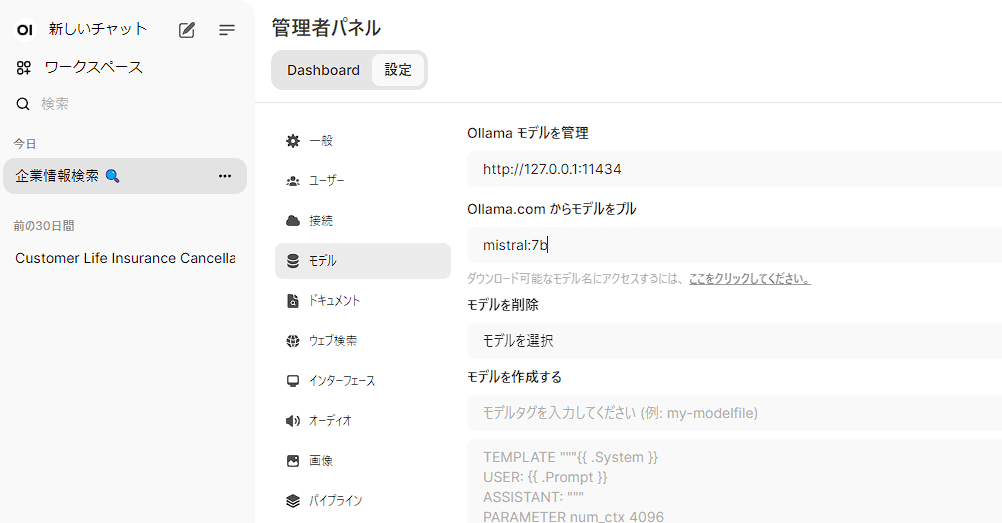
初回利用時は、Gemmaモデルをインストールする必要があります。
[設定]-[モデル]から[Ollama.comからモデルをプル]にてモデル名(例:gemma:7b)と入力しダウンロードしてください。

最後に
今回はGoogle のオープンAIモデル『Gemma』についてご紹介させていただきました。
また、実際にローカル環境で実行してみてその手軽さを少しでもお伝え出来たかなと思います。
より詳細な機能については、追って公開させていただきます。引き続き本ブログをお楽しみください!!!!!!
今後とも、AIMLに関する情報やGoogle CloudのAIMLサービスのアップデート情報を掲載していきたいと思います。
最後まで読んでいただき、ありがとうございました!!!
複数プロンプト実行してみた結果、
Gemini1.5 Flashに比べると出力までの時間は多少要しましたが、精度は申し分ないかと思います。