

こんにちは、SCSKの加古です。
普段Amazon Redshiftを利用する方でも、Amazon Redshift Spectrumの機能はあまり利用しないのではないでしょうか。今回は、SpectrumからAmazon Simple Storage Service(Amazon S3)上に保存されたデータをクエリーする手順について紹介します。
サンプルの取得
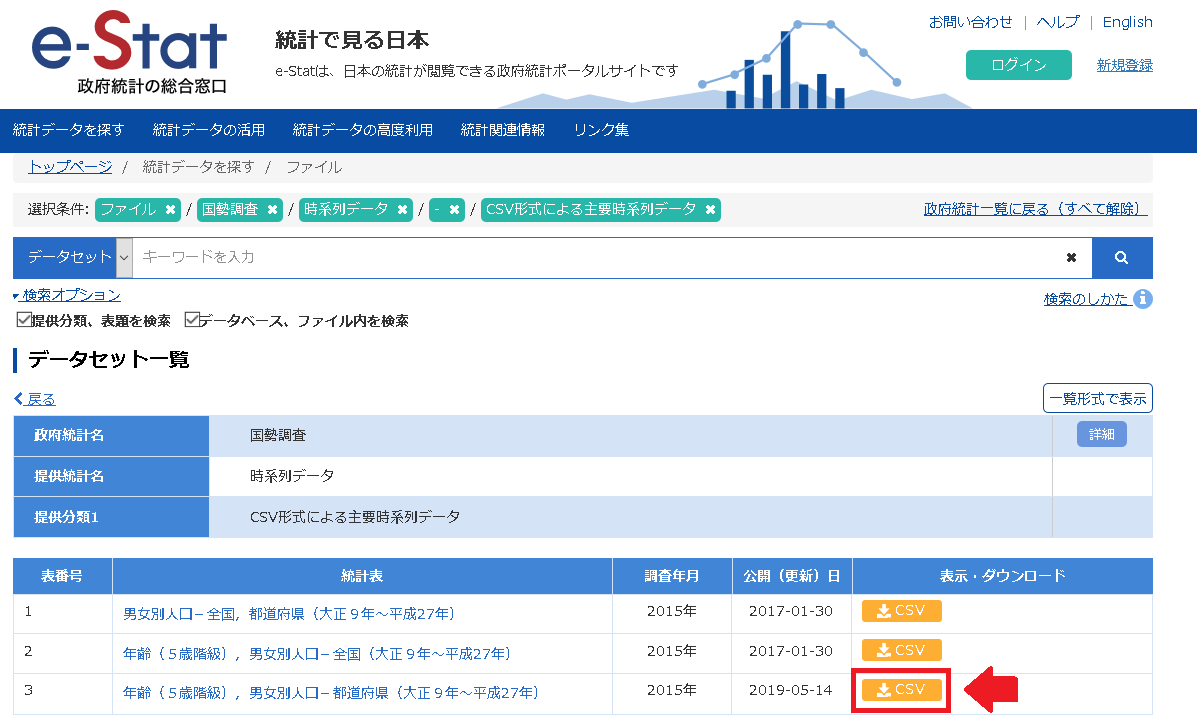
Spectrumから検索するサンプルデータを以下のリンクからダウンロードして下さい。
「年齢(5歳階級),男女別人口-都道府県(大正9年~平成27年)2015年」を使用して説明します。

ダウンロードファイル : 「年齢(5歳階級),男女別人口-都道府県(大正9年~平成27年)2015年」
Amazon S3 バケットにサンプルデータを保存
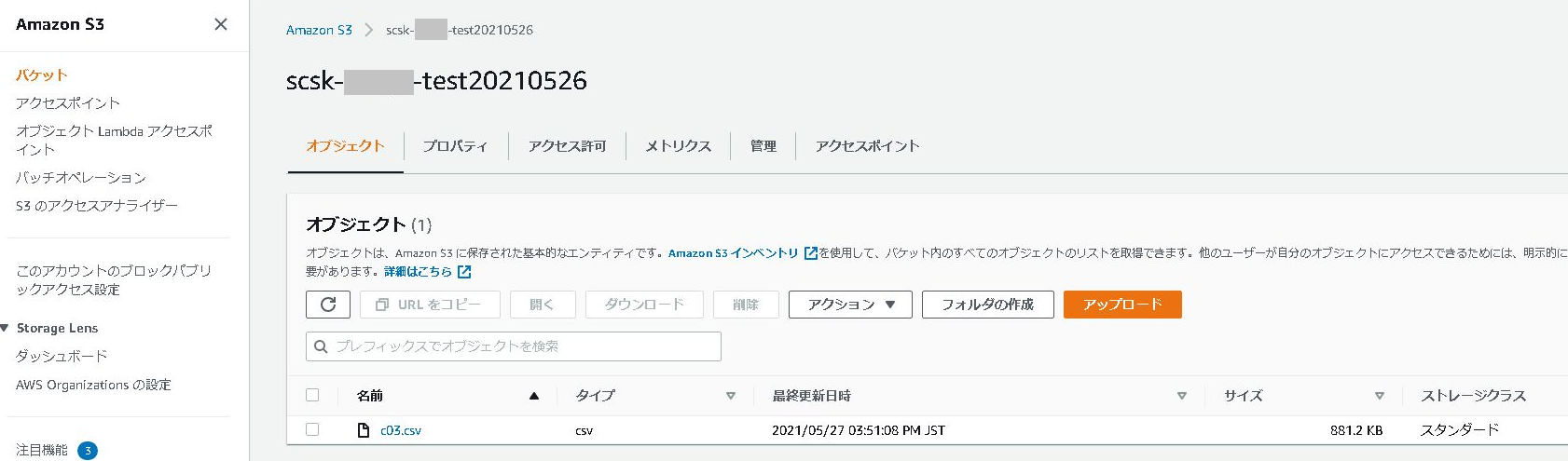
ダウンロードした「csvファイル」をAmazon S3バケットに保存します。
保存先 : s3:::scsk-xxxx-test20210526
xxxxは、任意の文字列を設定下さい。
以下の画面キャプチャは、私が検証したものです。
Amazon Redshiftクラスターのアクセス許可「IAMロール」を作成
1.AWSマネジメントコンソールにログインします。
2.ナビゲーションペインで [Identity and Access Management (IAM)」の「ポリシー」 を選択します。
3.「ポリシー作成」をクリックします。
4.JSONのタブを選択し、Amazon RehshiftからAmazon S3に保存したサンプルデータへのアクセスを許可するために、以下のアクセス権限を追加します。
Resource行には、バケットに保存したフォルダー名を記載して下さい。
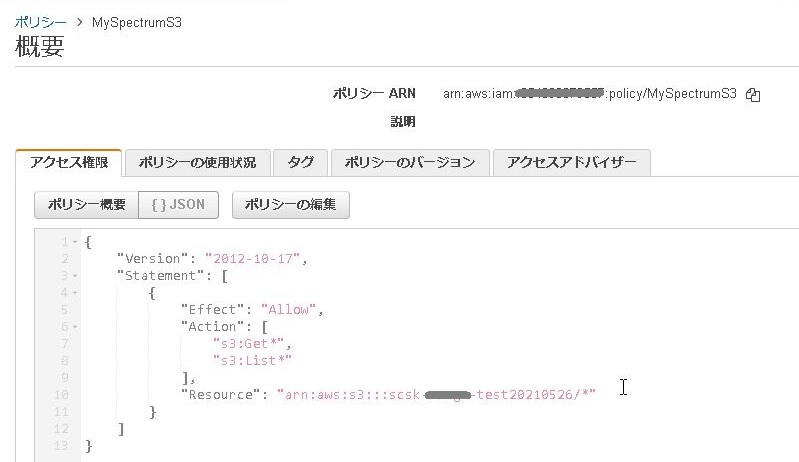
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:Get*",
"s3:List*"
],
"Resource": "arn:aws:s3:::scsk-xxxx-test20210526/*"
}
]
}
5.ポリシー名を「MySpectrumS3」で作成します。
6.「ロールの作成」をクリックします。
7.ユースケースの選択から「Redshift」と画面下の「Redshift – Customizable」を選択し、「次のステップ:アクセス権限」をクリックします。
8.先程作成した「MySpectrumS3」と「AWSGlueConsoleFullAccess」の2つのポシリーをアタッチします。

9.「ロールARN」は以降使用しますので、メモ帳などにコピーし、控えておいて下さい。
10.[ロール名] に、「mySpectrumRole」を入力し、ロールを作成します。
Amazon Redshiftの作成
情報が新しく分かりやすいページのリンクを以下に載せています。
Amazon Redshiftを作成される方は参考にして下さい。

Amazon RedshiftにIAMロールをアタッチ
1.ナビゲーションペインで 「Redshift」を選択します。
2.左メニューのクラスターを選択後、今回使用するAmazon Redshiftの状態が「Available」であることを確認します。
3.「アクション」をクリックし、「IMAロール管理」を選択します。
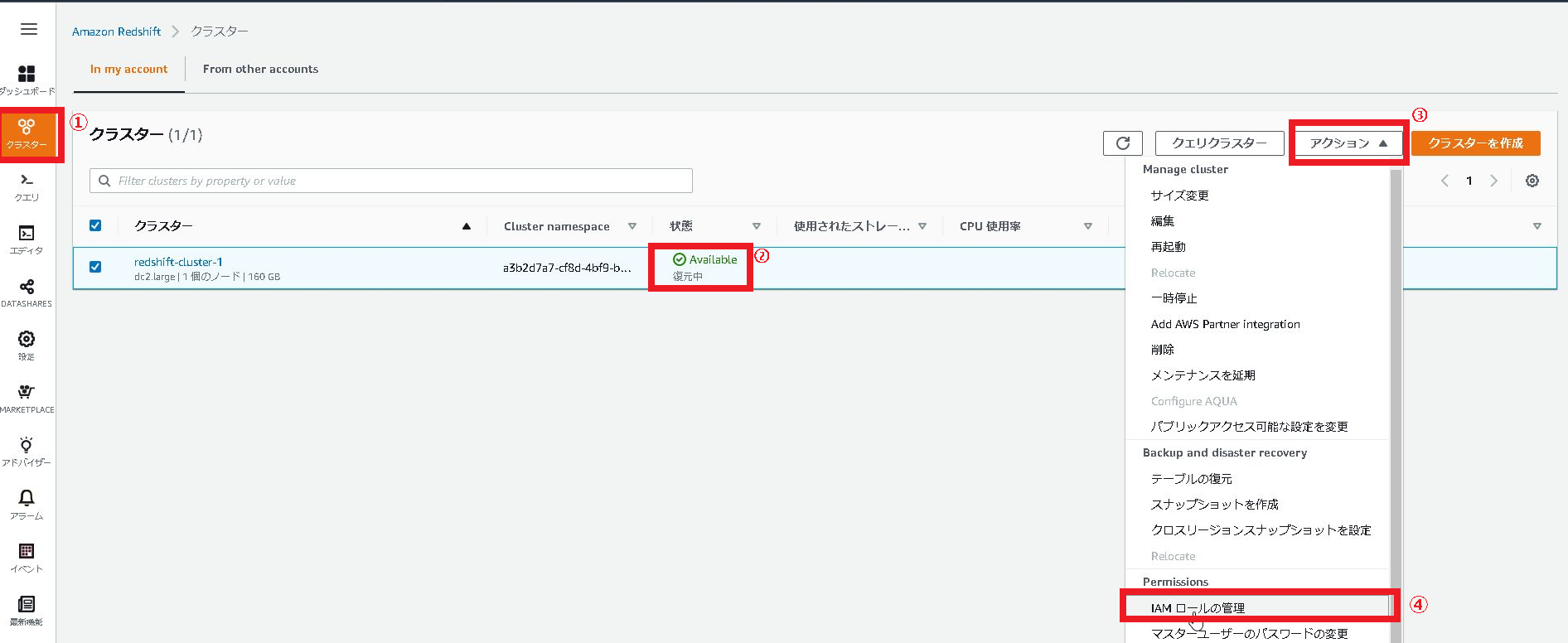
4.使用可能なIAMロールで「mySpectrumRole」選択し、「IAMロールの追加」をクリックします。
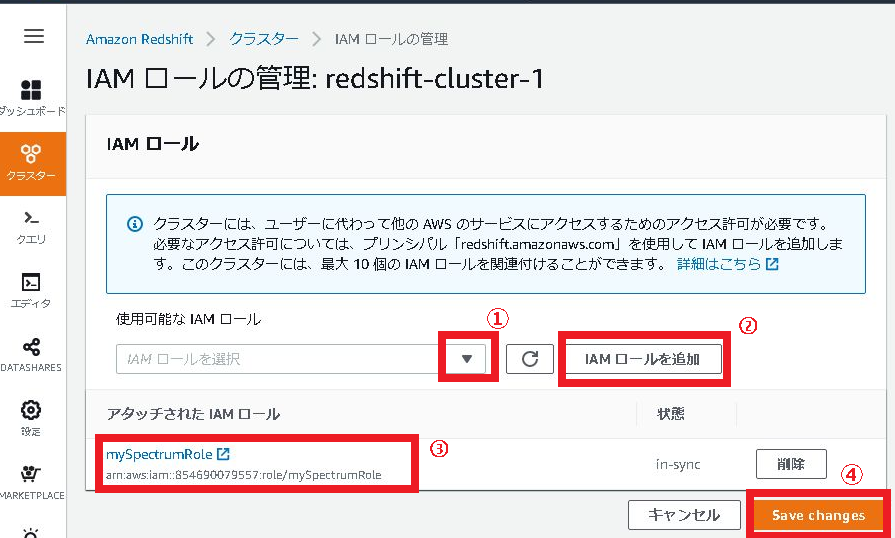 5.アタッチされたIAMロールに「mySpectrumRole」が表示されたことを確認します。
5.アタッチされたIAMロールに「mySpectrumRole」が表示されたことを確認します。
6.「Save changes」をクリックします。
外部スキーマの作成
1.左メニューのエディタを選択後、「接続を変更」をクリックします。

2.Amazon Redshiftを作成した時に設定した「データベース名」、「データベースユーザ」を入力し「接続」をクリックします。
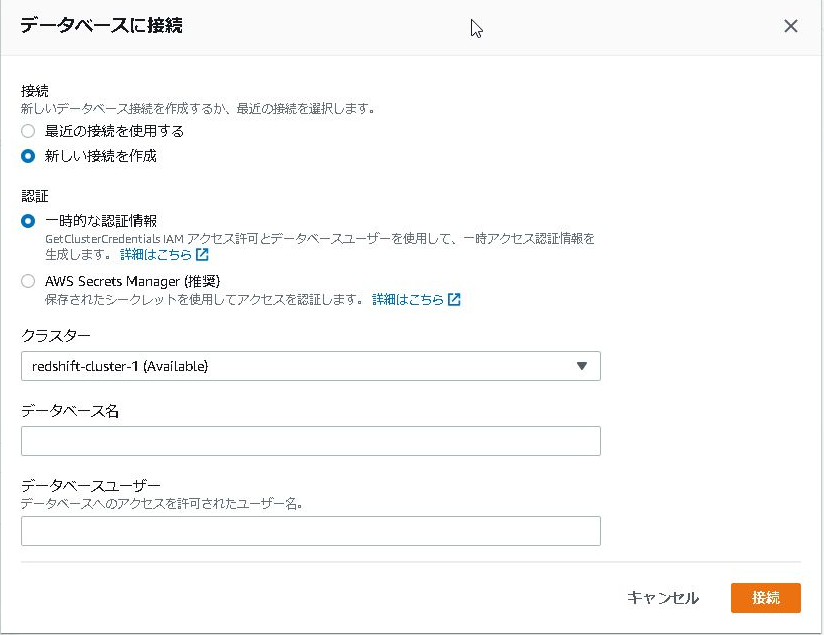
3.状態が「Connected」であることを確認します。

4.Query1の入力欄に以下のコードを貼り付け、「Run」をクリックする。
Query resultsに「Completed」の結果が表示されることを確認します。
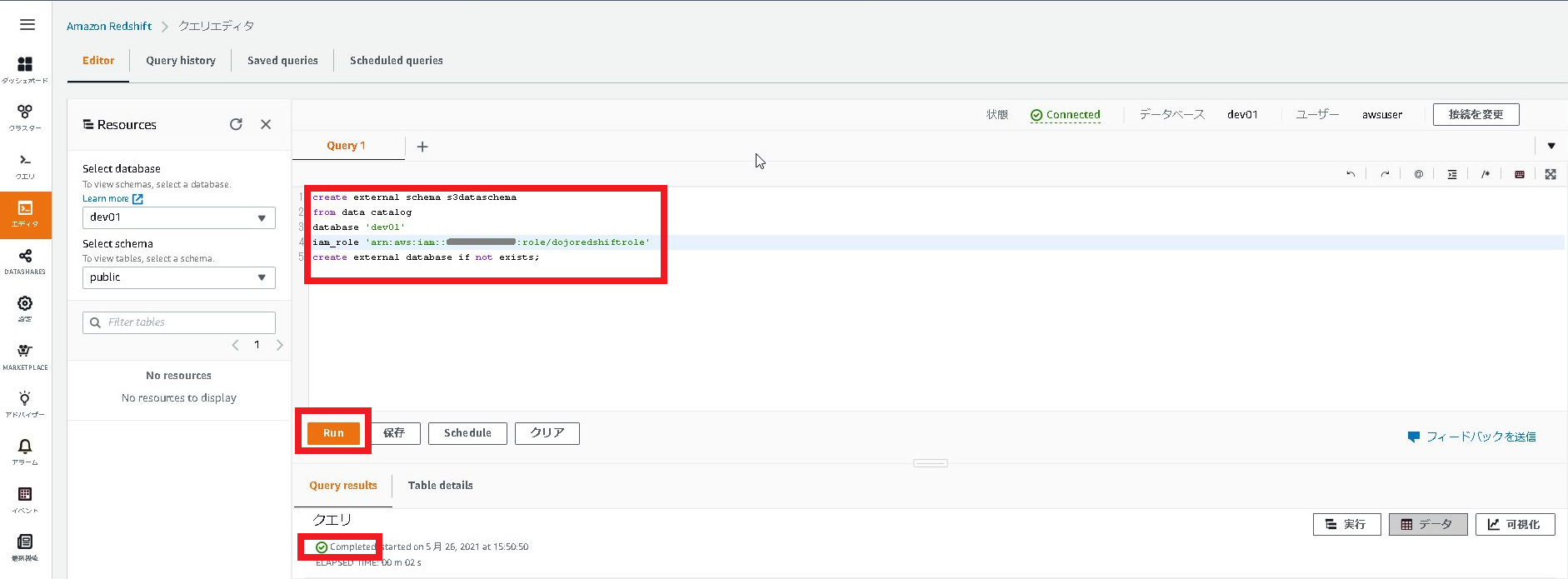
iam_role ‘arn:aws:iam:xxxxxxxxの「xxxxxxxx」はAWSアカウント番号を設定して下さい。
create external schema s3dataschema2 from data catalog database 'dev' iam_role 'arn:aws:iam::xxxxxxxx:role/mySpectrumRole' create external database if not exists;
外部テーブルの作成
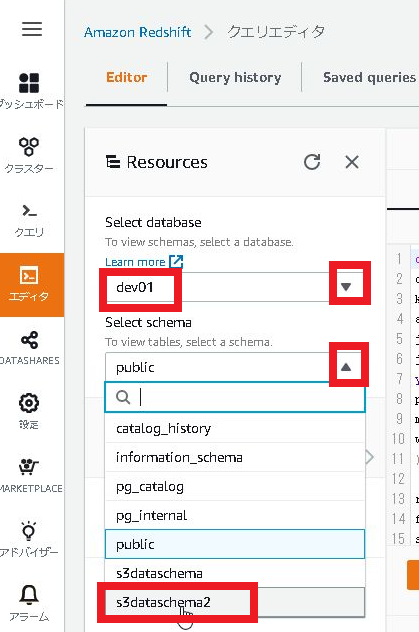
1.Resourcesの接続情報は以下のプールダウンを選択して下さい。
Learn more : dev01
Select schema : s3dataschema2
2.添付のコードを貼り付け「Run」ボタンをクリックし処理をして下さい。
処理結果は「Completed」であることを確認して下さい。
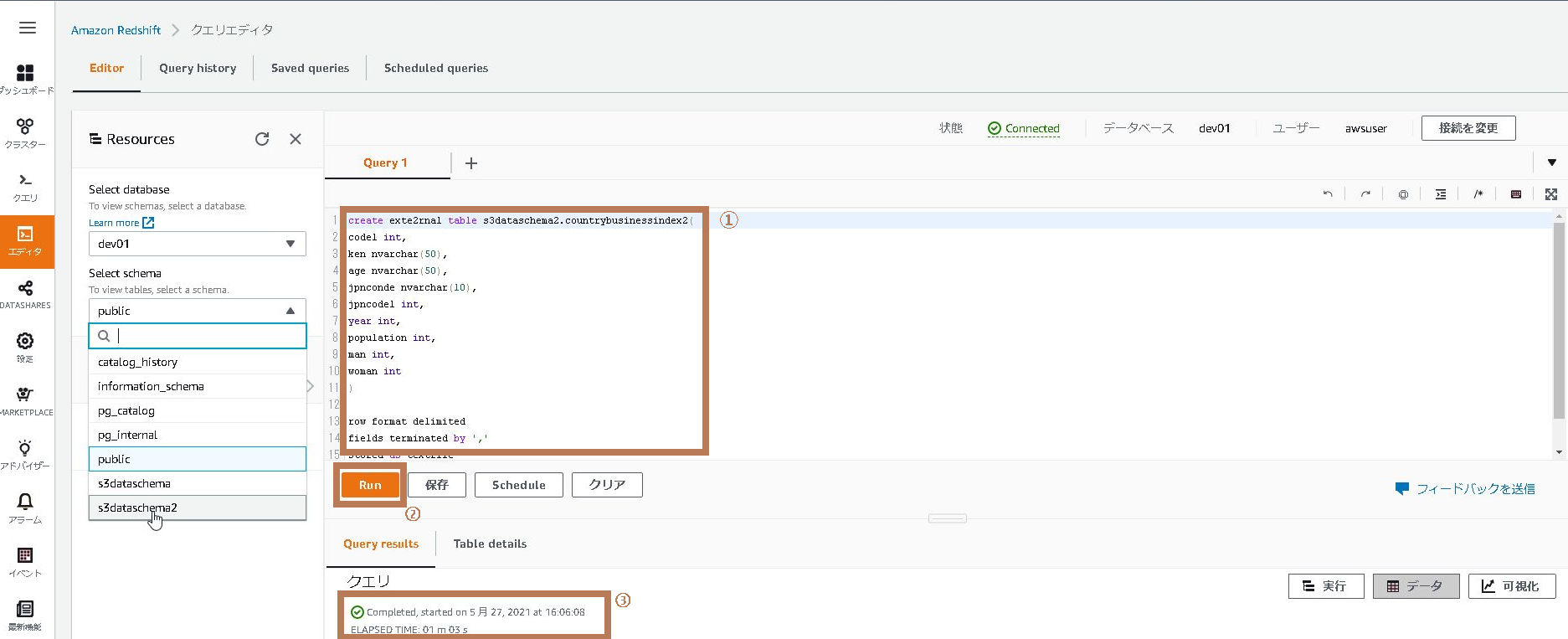
create external table s3dataschema2.countrybusinessindex2( code1 int, ken nvarchar(50), age nvarchar(50), jpnconde nvarchar(10), jpncode1 int, year int, population int, man int, woman int ) row format delimited fields terminated by ',' stored as textfile location 's3://scsk-xxxx-test20210526';
location行には、S3バケットに保存したフォルダー名を記載して下さい。
Amazon S3に保存したデータの検索
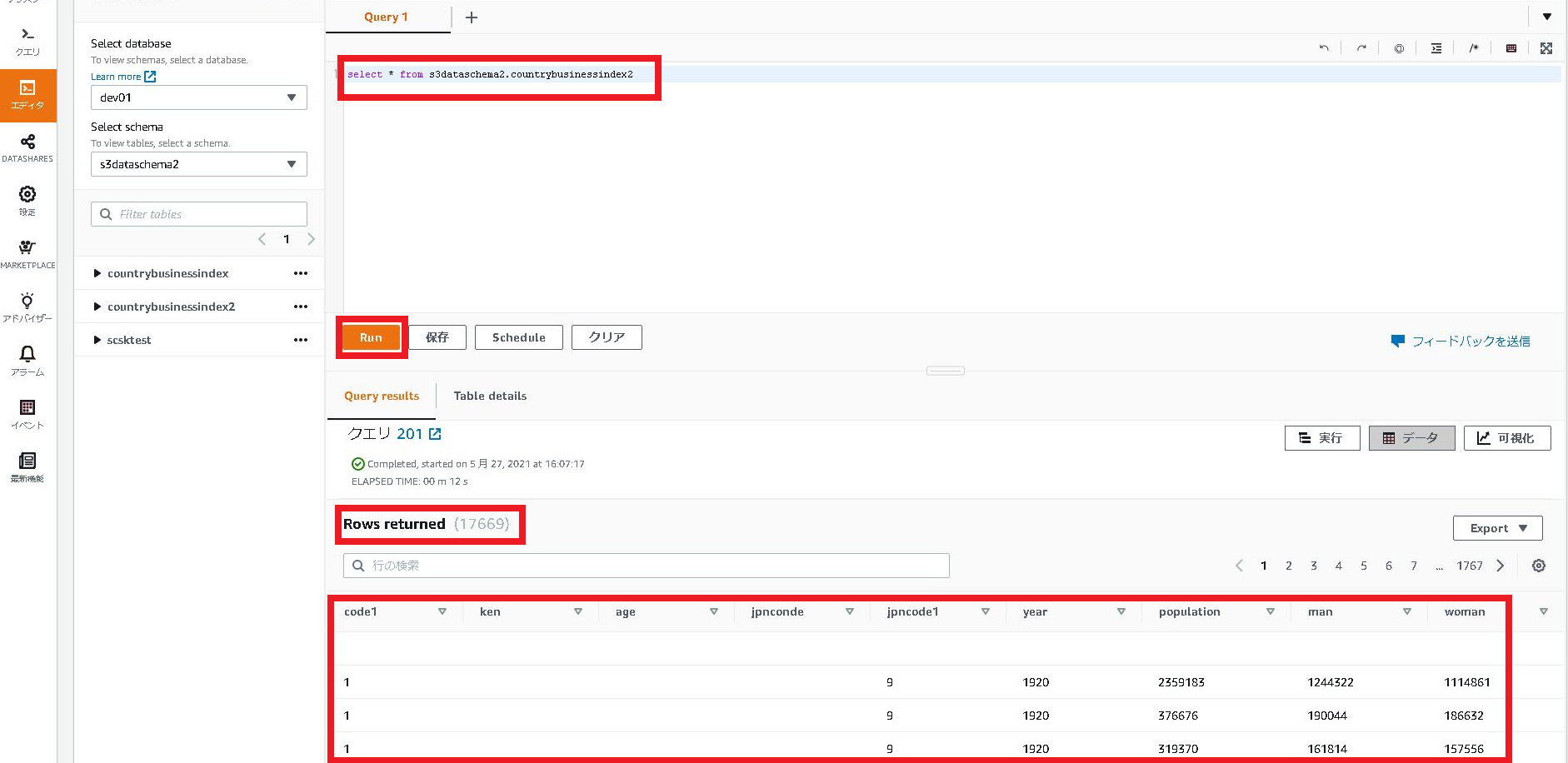
1.添付のコードを貼り付け「Run」ボタンをクリックし処理をして下さい。
検索結果の件数と検索したデータが表示されます。
select * from s3dataschema2.countrybusinessindex2
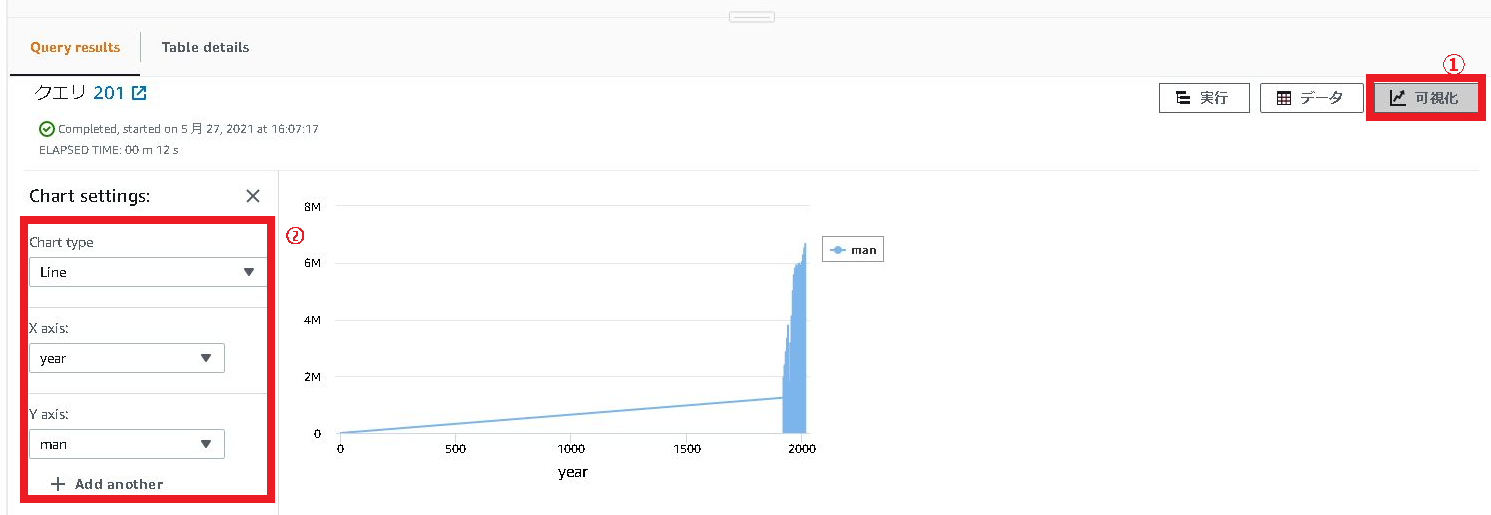
2.検索したデータは「可視化」をクリックし「Chart setings」を設定することでグラフ表示されます。
以上で終わりです。
皆様の環境でも同様の結果が得られましたでしょうか? 少しでも皆様のお役に立てたら幸いです。
最後までお読みいただきありがとうございました。