

はじめに
いきなりですが、パフォーマンスチューニングの極意からお話しましょう。
パフォーマンスチューニングとは、「一定の制約の中で、希望の結果を選び取ること」と考えると、我々人類が日々行っている生存競争と何ら変わりがありません。日々生存競争している、すなわち、常在戦場。つまり戦場の極意=パフォーマンスチューニングの極意でもあるということにほかなりません。
ここで、歴史上の偉人に登場してもらって、戦場での極意を語ってもらいましょう。
孫子曰く、「敵を知り己を知らば百戦あやうからず」
\孫子言いたいだけだろ/ ハイ、その通りです。
敵?己?
今回は、Webサイトのパフォーマンス・チューニングを例としてチューニングを行います。
敵と己にわけて考えます。別に悪意があって敵とするわけではなくて、自分の努力、パフォーマンスチューニングではどうしようもないものを敵と捉えます。自分の手の届く範囲の外にあるもの、と、捉えてもいいですね。
逆に自分でどうにかできるものや、できそうなものを己とします。
- 敵
- Webサーバーに殺到するお客様、あるいはWebサーバーを乗っ取ろうとする攻撃者
- 己
- Webサーバーの特性、Webサイトのアーキテクチャー構成、ネットワーク構成、Webサーバーやシステムの得意技、苦手とするところ、業務要件、制約事項、コンテンツの特性、etc…
こうやって見ると己はすごく多いですね。
パフォーマンス・チューニングの流れ
- パフォーマンス・チューニングの流れとしては、下の図のようになります。
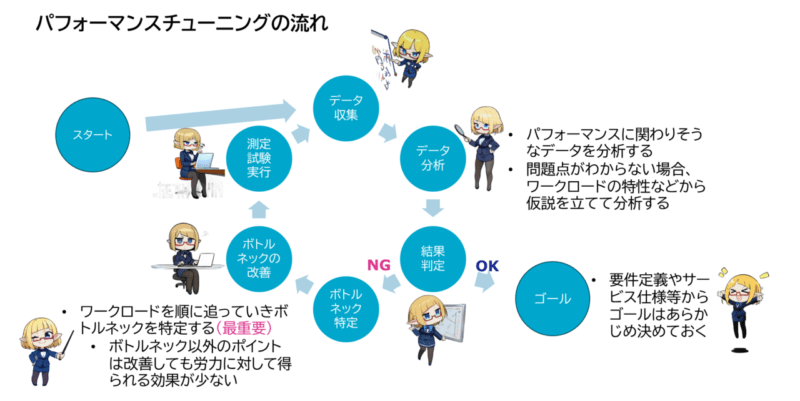
左上のスタートから始まって、ぐるっと回るような流れになっています。

- データ収集
- データ分析
- 結果判定
- ボトルネック特定
- ボトルネック改善
- 測定試験実行
順に見ていきましょう。
1. データ収集
「Webサイトの表示が重くなってきて、最終的に表示されなくなった」「イベントのときにいきなり落ちた」など、訴え事象やお客様からみた状態「だけ」では、Webサイトの中で何が起こっているのか全くわかりません。まずは状況を客観的に判断するためのデータを収集します。
Webサイトであれば、
- Webサーバのアクセスログ
- エラーログ(Webサーバーが 4xx,5xx を返却したログ、あるいはアプリケーションが異常時に出力したログ)
- EC2 や RDS を利用している場合は、CPU利用率や、メモリ利用率
- Akamai, CloudFrontな どのコンテンツデリバリーネットワーク(CDN)サービスを利用しているのではあれば、その統計データ
などのデータがあると思います。そういったデータの中から、
- 異常発生時の状態のログ
- 普段の正常な状態のログ
- できれば異常発生時と同じようなイベントの際のデータと、イベントのない平常時の同じ曜日時間帯など比較できる状況別にあると望ましい
と両方を比較できるようにデータを取得します。
そういったデータがそもそも取得されていないのであれば、まずは取得するところからになってしまいますが、何が起こっているのか全くわからない状況ではどうすればよいのか判断できないので、早速取得を開始しましょう。最低限上記のログと、アプリケーションのログを出力して取得する必要があります。
ある時点でWebサイトがお客様からどのように見えていたかを常時確認するのは困難なため、自動化がおすすめです。 CloudWatch Synthetics Canary などを使って定期的に観測しましょう。後述の試験の際にも利用できます。
合成モニタリング (canary)

2. データ分析
取得したデータを分析します。
不具合が発生した時間帯の前後のエラーログの出力や、傾向の変化や正常時との差分から「己」側に 何が起こって、何が原因となってパフォーマンスが落ちてしまっていたのかをあぶり出します。
- HTTP の応答が 500 系なら、サーバー側のプロセスが異常終了してしまい応答が返せなかった、あるいは、アクセス集中により、応答を時間内に返せなかったと想定
- HTTP の応答が 403 や 404 ならWebサイトやアプリケーションの設定が誤っていて、案内してはいけないページに案内している可能性あり
- Windows の IIS などを利用している場合は、Windowsイベントログ、Linuxサーバーであれば、 /var/log/messages などのシステムログにエラーが出力されていないかどうかを確認
- 一分あたり、OOアクセスを超えたあたりからエラー応答が出るようになったとなると、アクセスが多くなりサーバーのリソースが足りなくなってしまった可能性
- サーバーのCPU使用率が普段は20%~40%なのに、不具合発生時は 80%を超えていた
- 不具合発生時はサーバーのメモリ使用率が 90%を超えていた
- 静的なコンテンツで、CDNを利用している場合は、不具合が発生しているページのキャッシュヒット率を確認します。静的なコンテンツなのにキャッシュヒット率が低い場合、CDNの設定が誤っていて実は全員がサーバーまで取得しに来ているというケースがあるかも
などです。
同時に「敵」側であるアクセス傾向についても分析します。この分析は、再現試験や、対策後の確認試験、Webサイト自体の目標設定の際にも利用できます。
- 平常時であれば、Webサイトには一分間あたり平均OO件、最大でもOOO件程度のアクセス
- 不具合発生直前は、正常、エラー合わせてOOOO件のアクセスが発生していた
- 不具合から回復した直後は、OOO件程度でエラーも発生していなかった
など。
こういった複数の状況から、矛盾しない「仮説」を立てていきます。
例えば、
- イベント開始直前からWebサイトの応答が遅くなったように感じられ、イベント開始時間からは エラーしか帰ってこなくなった、30分くらいしたらアクセスできた
というような訴え事象に対して、
- イベント開始直前のサーバーのログにリソースが不足した旨のエラーメッセージが出ていた
- その直後サーバーのログにはイベント開始時間あたりに再起動の履歴が残っていた
- イベント開始直前から5xx系のエラーログが増え始め、イベント開始30分をすぎるまで5xx系のエラーログが普段より多めに出力された
というログが見つかった場合
- イベント開始直前からアクセス集中により、Webサーバー側でリソースが不足し、Webサーバーの自動再起動が発生した。Webサーバーが再起動中であったために、ユーザーはイベント開始後Webサイトを表示できなかった。Webサーバの自動再起動が完了した後、時間経過に伴いユーザーのアクセス数が少なくなっててきたので、ユーザーはWebサーバーにアクセスできるようになった
という仮説がたてられます。うまく仮説を立てられない場合は、必要なデータが揃っていないことも考えられます。別観点のデータを収集する設定を追加投入する必要があるかもしれません。
例えば、「リソース不足」が発生したことはログに記録されているのでわかったが、そのリソースの具体的な数値を示すメトリクスデータが存在しないのであれば、何らかの方法でログに出力する方法を検討する必要があるかもしれません。
具体的には小さなアプリケーションを作成して定期的にログに出力するよう機能追加する。あるいはよく使われる処理内にそのリソースのメトリクスをログに出力する処理を埋め込む、などです。
3. 結果判定
結果判定フェーズでは分析したデータから、これで良いのかどうか判断します。
初回は不具合が発生しているので、当然NGです。しかし、修正、改善するとして、どこまですればよいかというのは線引きが必要です。
「己」のあるべき姿を再定義するわけです。それと同時に、「敵」の想定も明確にしておきます。
多少エラーリターンが返っても、Webサーバーが落ちなくなればよいのか、Webサーバーが落ちないのは当たり前で、イベント時でもユーザーが重たく感じない程度の時間で応答が帰ってきてほしいなど、許容範囲は幅があると思います。「重たく感じる」だと人によって曖昧になってしまうので「Webブラウザに何も表示されない状態が3秒位内」「最初の応答が返ってくるまでの時間が 3秒 以内が 95%以上、残り5%も10秒を超えないこと」など、数値化しておきます。
アクセス数も不具合発生時のアクセス数が想定以内だったのか、あるいは、想定以上だったのか、今回対策するとして、一分あたり、あるいは一秒あたり何アクセス以内であれば性能目標通りに動作するのかを決めておく必要があります。イベントのアクセス集中には耐えるというのと、企業を狙った大規模なDDoS攻撃にも耐える必要がある、では対策の手段も方法も違ってきます。
パフォーマンス・チューニングとしての目標ですが、信頼性、可用性の目標も同時に達成する必要があります。「いつもは性能が出るけど、忙しくなると落ちる」「イベント時は50%はエラーになるけど50%はOKが返る」というチューニング結果ではNGですよね?
コストの面も関わってきます。パフォーマンス・チューニングはコストとトレードオフになる面も多くあります。「絶対にWebサイトを落とさないように、Webサーバーを今の50倍の台数にしたい!」あるいは、「今のWebサーバーの50倍の性能のサーバーと全て置き換えたい!」といってもコストの観点で無理なのはなんとなくわかると思います。Webサイトのシステム自体が何らかの利益を稼ぎ出すような通販サイトの場合でも、販売促進用の宣伝広告サイトだとしても、Webサイトの維持費が販売して得た利益を上回ってしまう場合はWebサイトのせいで赤字になってしまっては問題でしょう。
4. ボトルネック特定
結果がNGなら、分析と仮説を元にボトルネックを特定します。
例えば以下のように、ユーザーに近い側から「己」の処理を順に見ていきます。「敵」が、どの地点に集中した結果守りきれなかったのか、地点を特定します。
守りきれなかった地点では大抵なんらかの異常を示すログなどが集中して出力されています。ログを記録した地点というよりはログの出元を特定します。例えば、
- CDN のログには Webサーバーからの応答に 5xx 系エラーがたくさん。その時間帯にCDNサービス自体の不具合報告は出ていない。関連するURLの静的コンテンツのキャッシュヒット率は低い
- CDNサービス自体の不具合報告は無いので、5xx系エラーの出元はCDNではなくWebサーバー
- Webサーバー はリソース不足で再起動
- 自身も5xx系のエラーも出している
- DBサーバーはCPU使用率もデータ転送もメモリ使用率も、同時期同時間帯の問題のない時間帯と比較しても何も変わらない
の場合には、Webサーバーのリソース不足がボトルネックになった、と特定できます。
5. ボトルネック改善
前の工程で特定したボトルネックを改善します。次のいずれかの方法になります。
- ボトルネックを太くする
- ボトルネックを通過する処理を詰まらない状況まで減らす
ボトルネックを太くするというのは、ボトルネック自体を太くしてボトルネックでなくしてしまおうとする方法です。今回の例では、リソース不足となった「Webサーバーの台数を増やす」ということになります。普段は問題がないので、常時台数を増やしておく必要はなさそうです。イベント開始前にだけあらかじめWebサーバーを増やしておいて、イベント終了後は元の台数に戻す、といった対策でコスト増を最小限にします。
ボトルネックを通過する処理を詰まらない状況まで減らすというのは、ボトルネックが細くても、そこを通過する処理をボトルネックに詰まらない程度まで少なくすることにより詰まらなくするという方法になります。例えば、Webサーバー上にある静的コンテンツの一部を S3 バケットなどに移動すると、Webサーバー宛のリクエストでなく、S3に対するアクセスとなるので、Webサーバーの負担が減ります。
上記の例ではその上流の CDN において「関連する静的コンテンツのキャッシュヒット率は低い」という分析結果が出ています。CDN でのキャッシュヒットしなかったアクセスはWebサーバーに流れてくる為、ボトルネックとなっているWebサーバーが処理することに繋がります。CDNの設定を適切に変更して 静的コンテンツが正しくキャッシュされるようにすることで、Webサーバーが担当する処理を少なくします。
ボトルネックが改善されると、ボトルネックが別の位置に移動する可能性があります。今までボトルネックで問題が起きていたために一定数以上の処理が来なかった状態であったのが、ボトルネックが解消されたために、その下流側に大量に処理が流れてきて新たなボトルネックになったり、あるいは、広くなった旧ボトルネックよりも手前側で先に詰まってしまうような状況が発生する可能性もあります。ただし、ボトルネックに関連しない修正はあまり効果を期待できません。それに手当たり次第に検討/修正するとなると手間暇もお金も時間も無駄にかかってしまいますので、まずはボトルネックの修正に集中します。
ボトルネックの改善により、システム全体が性能を満たすのに十分なほど改善したのか、あるいは、別の箇所が新たなボトルネックとなって性能要件をまだ満たせないのかを確認するために、次の測定試験を実行します。
6. 測定試験実行
対策が正しく効果を表しているかどうかを試験を行って確認します。
不具合の報告があった時間帯と同じようなアクセスを生成させて動作を確認します。不具合が発生するような状況を作り出すので、本番環境ではなく、試験環境で行います。Webへの大量アクセスはツールを使わないと難しいので、試験ツールを使用します。すでに使用している試験ツールがあるのであればそのツールで試験を行なえばよいのですが、現状利用したことがない、あるいは、そういったツールが無い場合は、以下のAWSのソリューションを利用できます。
AWS での分散負荷テスト

このままではシステムやビジネスの制約条件等で使用できない場合にしても個々のパーツやツールの使われ方などが参考になると思います。
おわりに
いかがでしたでしょうか。
パフォーマンス・チューニングというのは状況により実施する必要のある改善というのはシステムによって、利用するシステム構成、ミドルウェア、OS、ハードウェアや使用言語、制約事項、性能目標、可用性目標、信頼性目標、予算、想定アクセス数等が異なるために、「これをすれば全部のシステムでOK!」というような具体的な手段がなく、抽象的な言い回しに終始してしまった感があります。ただ、「ボトルネックを特定し改修するループを目標達成まで回す」という方法論はどのシステムのパフォーマンス・チューニングを行うにあたっても利用できる考え方だと思います。
この記事が皆さんのパフォーマンス・チューニングの参考になれば幸いです。