

 本記事は 夏休みクラウド自由研究 8/19付の記事です。 本記事は 夏休みクラウド自由研究 8/19付の記事です。 |
残暑お見舞い申し上げます。
立秋とはいえ、連日の猛暑にいささか参っておりますが、皆様いかがお過ごしでしょうか。Masedatiです。
この記事は「夏休みクラウド自由研究」の一環として投稿しています。自由研究は小学生ぶりです。
ちなみに小学生のときの自由研究のテーマは「トルコアイスの仕組みと作り方」でした。
突然ですがヒエログリフをご存じでしょうか。ヒエログリフとは古代エジプトの象形文字のことで、?←こんなものです。
これには「eat, drink, speak, think」等の意味があるとのこと。ここから現在の文字に進化するのですから、人類ってすごい。
アイスを食べながら、ふと思いました。ヒエログリフの画像をFine-tuningしたら、存在しないヒエログリフをそれっぽく生成してくれるのではないかと。現在の文字(プロンプト)から象形文字を生成するので逆進化です。
今回、「Amazon BedrockのFine-tuningでヒエログリフを創作する」をテーマとして自由研究を行いたいと思います。
実は執筆時点でまだ試していないので、成功するのか失敗するのかわかりません。
でもやってみた結果、失敗でもいいのではないかなと思いました。それもまた自由研究だと思うので。
前提
以下でFine-tuningを実施しました。
- リージョン:オレゴン
- モデル:Amazon Titan Image Generator G1
公式ドキュメントに沿ってFine-tuningを行います。

手順
データセットの準備
Text-to-imageでは以下のJSONL形式でデータを準備する必要があります。
{"image-ref": "s3://bucket/path/to/image001.png", "caption": "<prompt text>"}
{"image-ref": "s3://bucket/path/to/image002.png", "caption": "<prompt text>"}
{"image-ref": "s3://bucket/path/to/image003.png", "caption": "<prompt text>"}
S3にPNGもしくはJPEG画像を格納し、その画像のプロンプト(英語のみ)を記述します。
今回以下のように画像(512×512)をS3に格納し、プロンプトとしてそのキャプションを記載しました。
{"image-ref": "s3://bucket/image-train-data/ ", "caption": "Hieroglyphics of a man eating"}
※イメージです。
", "caption": "Hieroglyphics of a man eating"}
※イメージです。
訓練データ一覧
以下のヒエログリフ50個を訓練データ(traindata.jsonl)として用意しました。
ランダムで人・体の部位・動物・物体のヒエログリフをピックアップしています。
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyphics of a man eating"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of a seated man with an oar"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of a man with his hands raised"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of one man dancing"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of the man with the leopard's head"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph on a reclining mummy"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of a man riding two giraffes"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of a man hoeing"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of a seated man with arms raised"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of a man holding a knife"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of a seated woman"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of head"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of face"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of hair"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of eye"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of eye with flowing tears"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of pupillary"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of eyebrow"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of ear"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of mouth"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of on upper lip with teeth"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of hand"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of fist"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of one finger"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of two finger"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of three finger"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of four finger"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of five finger"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of six finger"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of seven finger"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of eight finger"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of nine finger"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of leg"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of foot"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of bull"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of pig"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of cat"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of dog"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of lion"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of owl"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of tilapia"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of bee"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of tree"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of sky"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of sun"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of star"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of land"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of sun over mountain"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of house"}
{"image-ref": "s3://bucket/image-train-data/?", "caption": "Hieroglyph of pot"}
S3の構成は以下のとおりです。
bucket
┣image-train-data
┃ ┣image001.png
┃ ┣image002.png
┃ ┣ ︙
┃ ┗image050.png
┣traindata.jsonl
┗output-bucket
学習終了後、Fine-tuning中の推移データが出力されるので、「output-bucket」を用意してあげます。
(需要が謎ですが、おまけとしてヒエログリフ文字を画像に変換するコードを置いておきます。)
from PIL import Image, ImageDraw, ImageFont
import os
def text_to_images(text, base_file_path, folder_path="train_data", image_size=(512, 512), font_size=300):
# フォントの設定
try:
font = ImageFont.truetype("NotoSansEgyptianHieroglyphs-Regular.ttf", font_size) # Noto Sansフォントファイルを使用
except IOError:
font = ImageFont.load_default()
# フォルダが存在しない場合、作成
if not os.path.exists(folder_path):
os.makedirs(folder_path)
# 各文字ごとに画像を作成して保存
for i, char in enumerate(text):
# 画像を作成
image = Image.new('RGB', image_size, color=(255, 255, 255))
draw = ImageDraw.Draw(image)
# 文字のバウンディングボックスを測定
text_bbox = draw.textbbox((0, 0), char, font=font)
textwidth, textheight = text_bbox[2] - text_bbox[0], text_bbox[3] - text_bbox[1]
# 文字を中央に配置
x = (image_size[0] - textwidth) // 2
y = (image_size[1] - textheight) // 8
# 画像に文字を書き込む
draw.text((x, y), char, font=font, fill=(0, 0, 0))
# 画像を保存
file_path = os.path.join(folder_path, f"{base_file_path}{i + 1}.png")
image.save(file_path)
print(f"{file_path}に画像を保存しました。")
# 文字入力例
text = "??????????????????????????????????????????????????"
base_file_path = "image" # 連番の基本ファイル名
text_to_images(text, base_file_path)
Fine-tuning
以下でFine-tuningを行いました。手順詳細については公式ドキュメントをご参照ください。
- 入力データ
s3://bucket/traindata.jsonl - ハイパーパラメータ(デフォルト値)
- ステップ:自動
- エポック:5
- バッチサイズ:8
- 学習率:0.00001
- 出力データ
s3://bucket/output-bucket/
パラメータの値についてはガイドラインが掲載されています。

結果
学習は約4時間で終了しました。この4時間、学習経過を確認できないのはムズムズしますね…
リアルタイムで推移を観測できれば、Fine-tuningを途中でストップしたり、パラメータを調整できたりと便利なのですが。
学習がおわるとoutput-bucketに「training_artifacts/step_wise_training_metrics.csv」が格納されます。
格納された学習推移データをグラフ化したものは以下です。
※こう見えて折れ線グラフです。
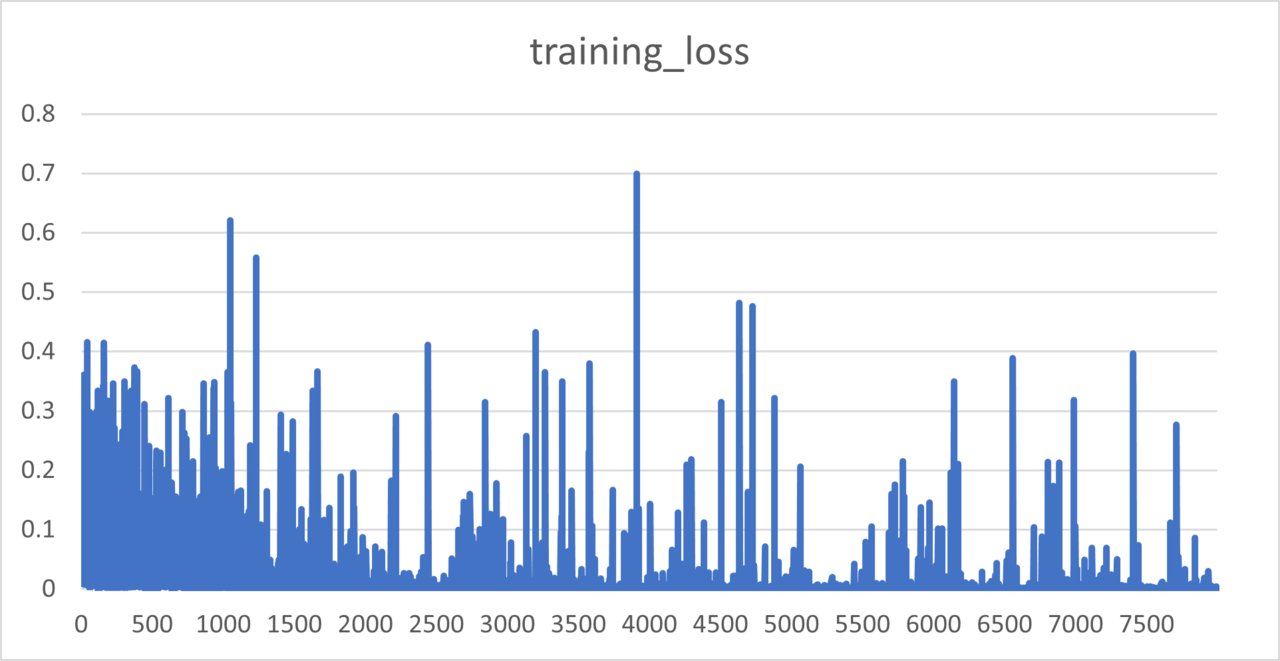
学習ステップをAutoにしたせいで、8000回も学習してしまっています。画像数が多くなると学習回数も増えます。
学習がうまくいっているのかの判別は、簡単に言えばtraining_lossがきれいに収束すればいいのですが、収束しているように見えませんね…
雲行きが怪しくなってきました。
では、さっそくFine-tuned modelを購入してモデルを使用してみます。
と思い、プレイグランドでいつものようにプロンプトを入力したところ以下のように怒られてしまいました。
Malformed input request, please reformat your input and try again.
ドキュメントを確認しましたが、解決法がわからず…仕方ないので、Lambdaで実行します。
Lambdaでの実行方法は以下を参考にさせていただきました。ありがとうございます!

データセットに存在するプロンプト
まずは、データセットに存在するプロンプトの出力を確認します。
プロンプトに「Hieroglyph of a man eating」を入力しました。


上:Original model 下:Fine-tuned model
まさかFine-tuned modelもカラーで出力されるとは思いませんでした。もとのmodelの影響を受けているのでしょう。
Fine-tuned modelでは、元データ「?」に近いものが出力されることがわかります。絵柄はFine-tuningで変えることができるようです。
色々と他のものも試していくうちにうまく学習できるものと、できていないものがあることに気が付きました。
以下の「Hieroglyph of star」が失敗例です。

 上:Original model 下:Fine-tuned model
上:Original model 下:Fine-tuned model
他の学習データと比べて「?」のヒエログリフ自体が異質なことが原因と考えられます。
データセットに存在するプロンプトを複数組み合わせる
次に、データセットに存在するプロンプトを複数組み合わせてみます。
プロンプトに「Hieroglyph of a man eating a pig」を入力しました。


上:Original model 下:Fine-tuned model
データセットに存在する「Hieroglyph of a man eating」?+「Hieroglyph of pig」?が一緒に出力されました。
pigと戯れている男性にしか見えませんが、許しましょう。象形文字ですから。
データセットのpigは左向きですが、右向きにいい感じに修正してくれています。そっぽ向いてると寂しいですもの。
では数の概念は学んでいるのでしょうか?データセットには1~9本の指の画像が存在しています。
「Hieroglyph of five pots」を入力してみます。

_人人人人人人_
> 6個 <
 ̄Y^Y^Y^Y^Y ̄
データセットに存在しないプロンプト
最後にデータセットに存在しないプロンプトを入力します。
古代エジプトになかったであろう「エレキギター」を入力してみます。


上:Original model 下:Fine-tuned model
エレキギターですね。こんなものが出土したらビックリです。
う~ん、データセットに存在しないものは全く変化ありませんでした。もう少し抽象的なものになるかと期待していました。
どうすれば期待した結果を得ることができるのでしょう…?
皆様のご意見お待ちしております。
まとめ
step_wise_training_metricsのグラフを見た時はどうなるかと思いましたが、一部うまく学習してくれてよかったです。
たまにtrain_lossが跳ね上がるのは、データ量が少ないのか、質が悪いのか、パラメータが悪いのか考えられる原因は多いですが、まだまだ実験が必要ですね。
余力と予算があれば、またチャレンジしたいと思います。
感想
これで夏休みの宿題は終わりです。これからBBQに行ってきます。