

 本記事は 新人ブログマラソン2024 の記事です。 本記事は 新人ブログマラソン2024 の記事です。 |
皆さんこんにちは!入社して間もない新米エンジニアの佐々木です。
前回は、Snowflake CortexAIを使ってドキュメント検索アシスタントを構築するチュートリアルに挑戦し、その様子を記事にまとめさせていただきました。多くの方々に読んでいただき、大変嬉しく思っています。
まだ読めていないという方は、以下の記事をまずは読んでいただけると幸いです!!
さて今回は、前回の記事の続編かつ応用編という立ち位置で、Snowflakeの公式チュートリアルに再度挑戦してみました!
前回は基本的なドキュメント検索アシスタントを構築しましたが、今回はより高度なチャットボットバージョンのドキュメント検索アシスタントの構築に踏み込んでみたいと思います。
それでは早速行きましょう!!
前回の振り返り
前回は、以下の公式チュートリアルをハンズオン形式で実践し、Snowflake Cortex AIのベクトル埋め込み機能を利用して、ドキュメント検索アシスタントを構築しました!
具体的には以下の大きく3つの手順で構築を進めました。
- データ準備と前処理: 検索対象となるドキュメントデータの準備、データベース、スキーマ、ウェアハウスの作成、ドキュメント分割関数の作成を行います。
- ベクターストアの構築: CortexAIを用いて各ドキュメントを数値ベクトルとして表現し、ベクターストアの作成を行います。
- チャットUIおよびロジック構築: 前工程で作成したベクターストアを利用して、誰でも簡単に文書検索ができるように、SnowflakeのStreamlitを使用して簡単なフロントエンドの作成を行います。
これらの手順を進めることで、最終的に以下のようなアプリを構築することができました!
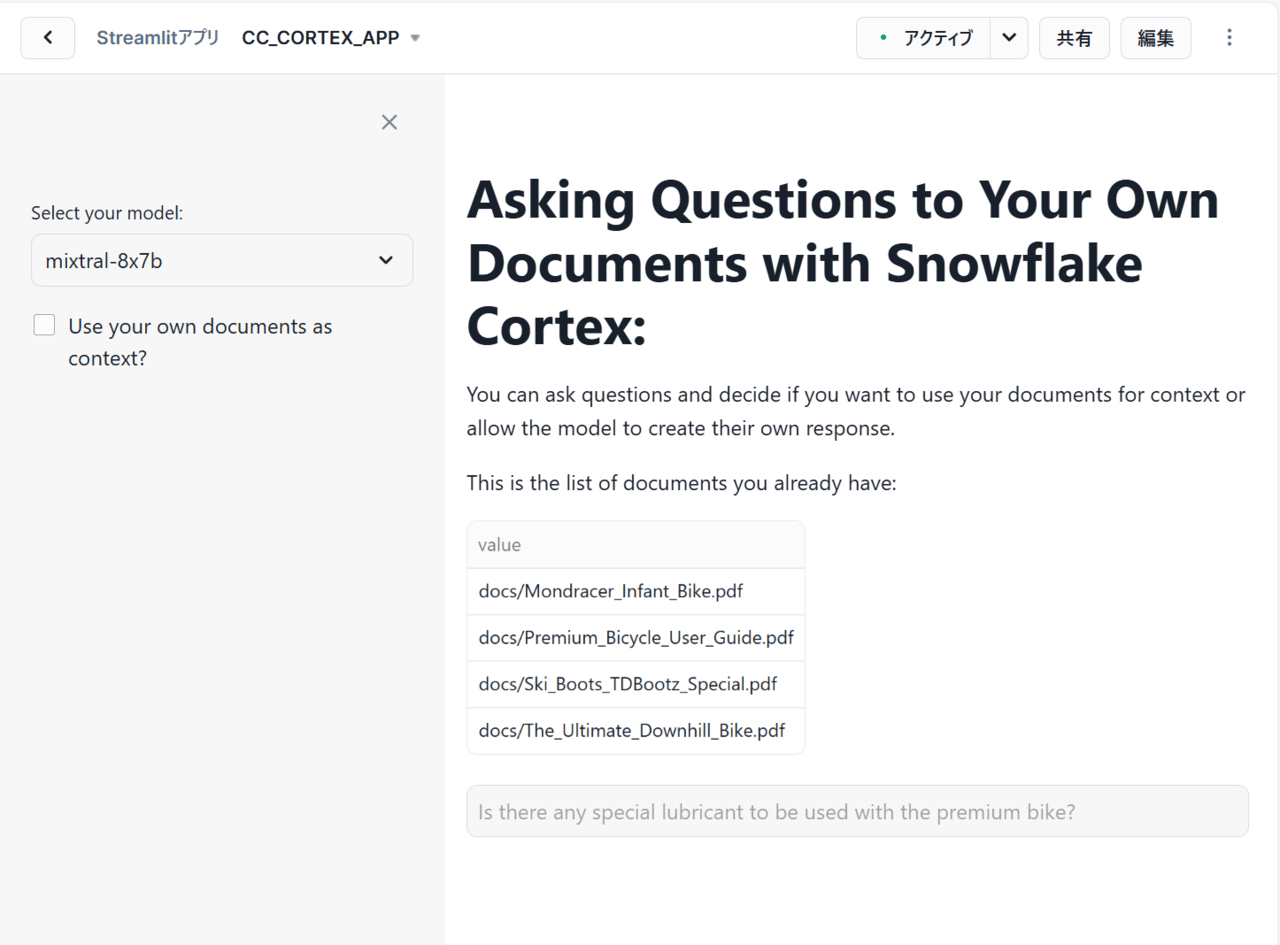
これは、SnowflakeのCortexAIを使ってドキュメントの内容に基づいてユーザーの質問に答えてくれるシンプルなアプリとなっています。
特に重要になるのが、左側にある「Use your own documents as context?」というチェックボックスです。これは回答の生成に事前に取り込んだドキュメントを使用するか否か、つまりRAGを使用するか否かを選択するためにあります。
例えば、チェックボックスを選択しないで質問を投げかけると、LLM(Large Language Model:大規模言語モデル)による一般的な回答のみが得られ、逆に選択して質問を投げかけると、事前に取り込んだPDFのコンテキストを使用して回答を作成するため、ドキュメントに関連したより詳細な回答を得られることが分かりました。
大雑把な説明とはなってしまいましたが、詳細が気になる方は前回の記事をぜひご覧ください!!
今回実施するチュートリアルの概要
前回実施したチュートリアルでは前述したとおり、ユーザーの質問に対してLLMを用いて回答するシンプルなアプリを構築しました。
しかし、これはあくまで一問一答形式となっており、前の質問を記憶して会話できるような状況ではありません。これはLLMがステートレスであり、過去のやり取りやコンテキストを記憶しておらず、各リクエストを独立したイベントとして処理するためです。
そこで、ユーザーとの会話内容を記憶して、チャットボットのように会話できるドキュメント検索アシスタントを構築していきたいと思います!
実際に挑戦してみた!!
前回と同様に、SnowflakeのStreamlitを使用して会話可能なチャットボットUIを作成していきます。
Streamlit構築
まず、Streamlitでアプリを作成します。今回は「CC_CORTES_CHATBOT_APP」というアプリ名にしました。

ここで選択しているデータベースやスキーマは前回作成したものとなります。
次に、作成したStreamlitアプリのコードを以下のように変更します。
import streamlit as st # Import python packages
from snowflake.snowpark.context import get_active_session
session = get_active_session() # Get the current credentials
import pandas as pd
pd.set_option("max_colwidth",None)
### Default Values
#model_name = 'mistral-7b' #Default but we allow user to select one
num_chunks = 3 # Num-chunks provided as context. Play with this to check how it affects your accuracy
slide_window = 7 # how many last conversations to remember. This is the slide window.
#debug = 1 #Set this to 1 if you want to see what is the text created as summary and sent to get chunks
#use_chat_history = 0 #Use the chat history by default
### Functions
def main():
st.title(f":speech_balloon: Chat Document Assistant with Snowflake Cortex")
st.write("This is the list of documents you already have and that will be used to answer your questions:")
docs_available = session.sql("ls @docs").collect()
list_docs = []
for doc in docs_available:
list_docs.append(doc["name"])
st.dataframe(list_docs)
config_options()
init_messages()
# Display chat messages from history on app rerun
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# Accept user input
if question := st.chat_input("What do you want to know about your products?"):
# Add user message to chat history
st.session_state.messages.append({"role": "user", "content": question})
# Display user message in chat message container
with st.chat_message("user"):
st.markdown(question)
# Display assistant response in chat message container
with st.chat_message("assistant"):
message_placeholder = st.empty()
question = question.replace("'","")
with st.spinner(f"{st.session_state.model_name} thinking..."):
response = complete(question)
res_text = response[0].RESPONSE
res_text = res_text.replace("'", "")
message_placeholder.markdown(res_text)
st.session_state.messages.append({"role": "assistant", "content": res_text})
def config_options():
st.sidebar.selectbox('Select your model:',(
'mixtral-8x7b',
'snowflake-arctic',
'mistral-large',
'llama3-8b',
'llama3-70b',
'reka-flash',
'mistral-7b',
'llama2-70b-chat',
'gemma-7b'), key="model_name")
# For educational purposes. Users can chech the difference when using memory or not
st.sidebar.checkbox('Do you want that I remember the chat history?', key="use_chat_history", value = True)
st.sidebar.checkbox('Debug: Click to see summary generated of previous conversation', key="debug", value = True)
st.sidebar.button("Start Over", key="clear_conversation")
st.sidebar.expander("Session State").write(st.session_state)
def init_messages():
# Initialize chat history
if st.session_state.clear_conversation or "messages" not in st.session_state:
st.session_state.messages = []
def get_similar_chunks (question):
cmd = """
with results as
(SELECT RELATIVE_PATH,
VECTOR_COSINE_SIMILARITY(docs_chunks_table.chunk_vec,
SNOWFLAKE.CORTEX.EMBED_TEXT_768('e5-base-v2', ?)) as similarity,
chunk
from docs_chunks_table
order by similarity desc
limit ?)
select chunk, relative_path from results
"""
df_chunks = session.sql(cmd, params=[question, num_chunks]).to_pandas()
df_chunks_lenght = len(df_chunks) -1
similar_chunks = ""
for i in range (0, df_chunks_lenght):
similar_chunks += df_chunks._get_value(i, 'CHUNK')
similar_chunks = similar_chunks.replace("'", "")
return similar_chunks
def get_chat_history():
#Get the history from the st.session_stage.messages according to the slide window parameter
chat_history = []
start_index = max(0, len(st.session_state.messages) - slide_window)
for i in range (start_index , len(st.session_state.messages) -1):
chat_history.append(st.session_state.messages[i])
return chat_history
def summarize_question_with_history(chat_history, question):
# To get the right context, use the LLM to first summarize the previous conversation
# This will be used to get embeddings and find similar chunks in the docs for context
prompt = f"""
Based on the chat history below and the question, generate a query that extend the question
with the chat history provided. The query should be in natual language.
Answer with only the query. Do not add any explanation.
<chat_history>
{chat_history}
</chat_history>
<question>
{question}
</question>
"""
cmd = """
select snowflake.cortex.complete(?, ?) as response
"""
df_response = session.sql(cmd, params=[st.session_state.model_name, prompt]).collect()
sumary = df_response[0].RESPONSE
if st.session_state.debug:
st.sidebar.text("Summary to be used to find similar chunks in the docs:")
st.sidebar.caption(sumary)
sumary = sumary.replace("'", "")
return sumary
def create_prompt (myquestion):
if st.session_state.use_chat_history:
chat_history = get_chat_history()
if chat_history != []: #There is chat_history, so not first question
question_summary = summarize_question_with_history(chat_history, myquestion)
prompt_context = get_similar_chunks(question_summary)
else:
prompt_context = get_similar_chunks(myquestion) #First question when using history
else:
prompt_context = get_similar_chunks(myquestion)
chat_history = ""
prompt = f"""
You are an expert chat assistance that extracs information from the CONTEXT provided
between <context> and </context> tags.
You offer a chat experience considering the information included in the CHAT HISTORY
provided between <chat_history> and </chat_history> tags..
When ansering the question contained between <question> and </question> tags
be concise and do not hallucinate.
If you don´t have the information just say so.
Do not mention the CONTEXT used in your answer.
Do not mention the CHAT HISTORY used in your asnwer.
<chat_history>
{chat_history}
</chat_history>
<context>
{prompt_context}
</context>
<question>
{myquestion}
</question>
Answer:
"""
return prompt
def complete(myquestion):
prompt =create_prompt (myquestion)
cmd = """
select snowflake.cortex.complete(?, ?) as response
"""
df_response = session.sql(cmd, params=[st.session_state.model_name, prompt]).collect()
return df_response
if __name__ == "__main__":
main()上記のコードを見ても分かりにくいですよね、、自分自身も理解に苦しみました(笑)
そこで簡単ではありますが、内容をまとめてみました。
特に、それぞれの関数がどのような包含関係でどの順に呼び出され、どのような処理を行っているのかについてまとめました!
①main():メイン関数
②config_options():サイドバーの設定を表示
③init_messages():チャット履歴を初期化
④complete(myqusestion):LLMを使って質問に回答
⑤create_prompt(myquestion):LLMへのプロンプトを作成
⑥get_chat_history():過去のチャット履歴を取得
⑦summarize_question_with_history(chat_history, question):チャット履歴とユーザーの質問を要約
⑧get_similar_chunks(question):ユーザーの質問に関連するドキュメントチャンクを取得
上記でそれぞれの関数を階層構造で表現している理由は、関数同士の包含関係を示すためです。ここで⑦の処理は、⑥の処理で過去のチャット履歴が存在した場合のみ実行されます。そのため、今回のように過去のチャット履歴を汲み取って会話できるチャットボットとして機能するためには、特に⑦の処理が重要だと言えます!
よりコードの詳細を知りたい方は以下の補足説明をぜひ読んでみてください!興味がなければ飛ばしてもらってOKです!!
1行目~7行目:
import streamlit as st # Import python packages
from snowflake.snowpark.context import get_active_session
session = get_active_session() # Get the current credentials
import pandas as pd
pd.set_option("max_colwidth",None)StreamlitやPandasといった必要なライブラリをインポートしています。
9行目~14行目:
### Default Values #model_name = 'mistral-7b' #Default but we allow user to select one num_chunks = 3 # Num-chunks provided as context. Play with this to check how it affects your accuracy slide_window = 7 # how many last conversations to remember. This is the slide window. #debug = 1 #Set this to 1 if you want to see what is the text created as summary and sent to get chunks #use_chat_history = 0 #Use the chat history by default
今回構築するチャットボットのデフォルトの設定値を定義しています。具体的に各変数がどのような意味を持っているのかを以下に示します。
model_name:
使用するLLMの名前を示しています。 デフォルト値としてMistral-7Bというモデルが設定されています。この値は、config_options()関数内のst.sidebar.selectboxによって、ユーザーが実行時に変更できるようになっています。 つまり、ユーザーはサイドバーから異なるLLMモデルを選択することができます。
num_chunks:
ドキュメントから抽出する関連するテキストチャンクの数を示しています。 Snowflake Cortexは、ユーザーの質問に対する回答を生成する際に、関連するドキュメントの断片(チャンク)を利用します。この値が3の場合、最も関連性の高い3つのチャンクがLLMに提供されます。 この値を調整することで、コンテキストの量を制御し、回答の精度や効率に影響を与えることができます。 値を大きくすると、より多くのコンテキストが考慮されますが、処理時間が長くなる可能性があります。 逆に、値を小さくすると、処理速度は向上する可能性がありますが、回答の精度が低下する可能性があります。
slide_window:
チャット履歴において考慮する過去の会話の数を示しています。指定した個数分の直近の会話が、次の質問に対する回答生成に利用されます。例えばこの値が7の場合、直近7回の会話の履歴がコンテキストとして考慮されます。この値を増やすと、より多くの過去の会話が考慮されるため、よりコンテキストに富んだ回答が期待できますが、メモリ消費量が増加する可能性があります。逆に値を小さくすると、メモリ消費量は少なくなる一方で、コンテキストが不足して回答の精度が低下する可能性があります。
debug:
デバッグモードのオンオフを切り替えるための変数です。 値が1の場合(真)、summarize_question_with_history()関数が生成した、過去の会話履歴と現在の質問を要約したテキストがサイドバーに表示されます。これは、LLMに渡されるチャンクを確認し、モデルの動作をデバッグする際に役立ちます。 通常はコメントアウトされており、デフォルトではデバッグモードは無効になっています。
use_chat_history:
チャット履歴を使用するかどうかを制御するための変数です。 値が0の場合(偽)、チャット履歴は考慮されません。 値が1の場合(真)、チャット履歴が考慮されます。これは、config_options()関数内のst.sidebar.checkboxによって、ユーザーが実行時に変更できるようになっています。 デフォルトではコメントアウトされ、config_options内でvalue=Trueに設定されているため、初期状態ではチャット履歴が使用されます。
18行目~56行目:
def main():Streamlitアプリを動作させるための主要な処理がまとめられているメイン関数です。
59行目~79行目:
def config_options():
Streamlitのサイドバーを設定するための関数です。
具体的には、LLMモデルの選択、過去のチャット履歴の使用、デバッグモードの有効化、会話のリセットボタンなどを配置する処理を行っています。
82行目~86行目:
def init_messages():
チャット履歴を初期化するための関数です。
具体的には、セッションがクリアされた場合、またはmessagesがセッション状態に存在しない場合に、空のリストをst.session_state.messagesに設定する処理を行っています。
89行目~113行目:
def get_similar_chunks (question):
入力された質問に最も類似したチャンクをドキュメントから取得するための関数です。
具体的には、Snowflake CortexのVECTOR_COSINE_SIMILARITY関数を使って、質問ベクトルと各チャンクベクトルのコサイン類似度を計算し、類似度の高い上位num_chunks個分のチャンクを取得し、文字列として結合して返す処理を行っています。
116行目~125行目:
def get_chat_history():
過去のチャット履歴を取得するための関数です。
具体的には、st.session_state.messages、つまりStreamlitのセッションから最新のslide_window個分のチャット履歴を取得し、リストとして返す処理を行っています。
128行目~157行目:
def summarize_question_with_history(chat_history, question):
過去のチャット履歴と現在の質問をLLMに渡し、それらを要約したクエリを生成するための関数です。
また、デバッグモードが有効な場合、生成された要約をサイドバーに表示することができます。
159行目~197行目:
def create_prompt (myquestion):
LLMに渡すプロンプトを作成するための関数です。ユーザーが指定することで、チャット履歴を組み合わせてプロンプトを作成することも可能です。
具体的には、チャット履歴を使用する場合は、前述のsummarize_question_with_history関数を呼び出してクエリを取得し、さらに前述のget_similar_chunks関数を用いて関連するドキュメントのチャンクを取得します。そしてそれらの情報を含めてプロンプトを作成する処理を行っています。
200行目~208行目:
def complete(myquestion):
ユーザーの質問に対する回答を取得するための関数です。
具体的には、前述のcreate_prompt関数を呼び出して得られたプロンプトとLLMモデルをSnowflake CortexAIのsnowflake.cortex.complete関数に渡して呼び出すことで、ユーザーの質問に対する回答を生成する処理を行っています。
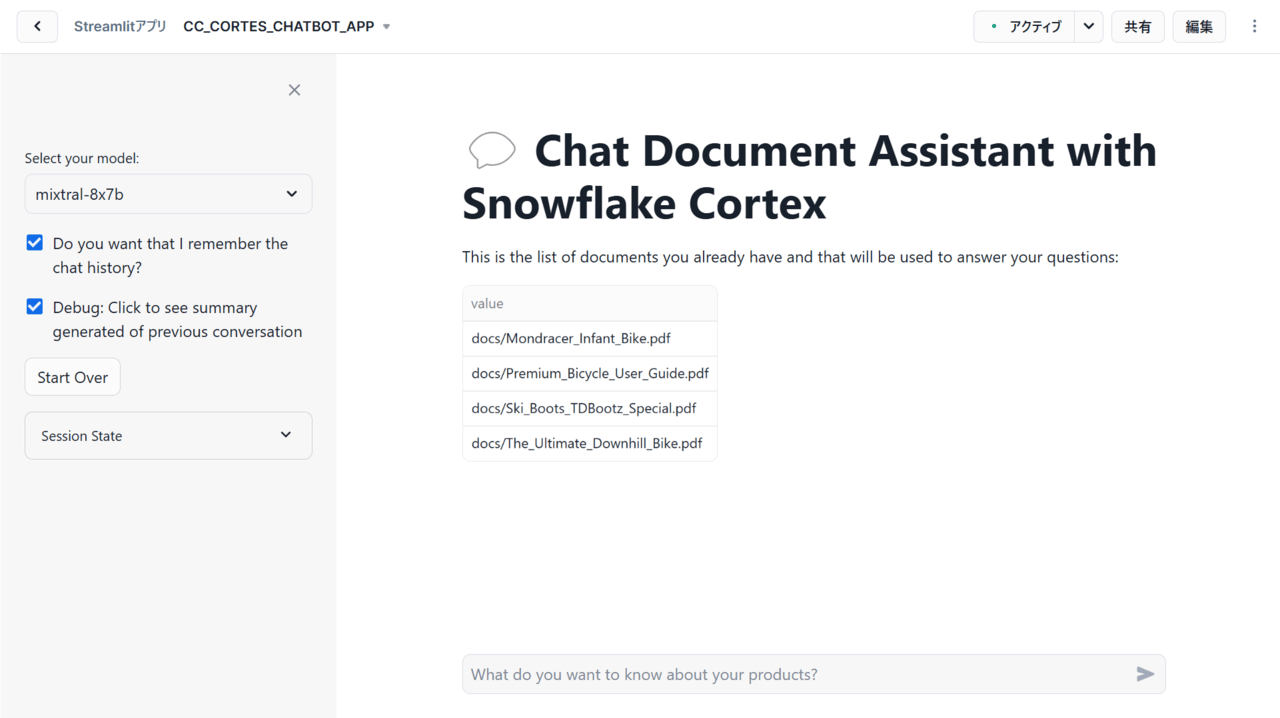
長々と話してきましたが、結局のところコードを実行することで無事以下のようなアプリが表示されました!
検証
では実際に作成したアプリを実行して検証をしてみたいと思います!
今回投げかける質問としては以下の3つがあります。
①What is the name of the ski boots?(スキーブーツの名前は何ですか)
②Where have been tested?(どこでテストされましたか)
③What are they good for?(何に適していますか)
なぜこのような質問を投げかけるかというと、②、③の質問は①のチャット履歴を記憶していないと具体的な回答ができないため、チャット履歴の記憶の有無を検証する上では最適だからです。
チャット履歴を記憶する場合
まずは、サイドバーの「Do you want that I remember the chat history?」がチェックされた状態、つまりチャット履歴を記憶した状態で質問を投げかけてみたいと思います。
投げかけた結果、以下のような回答が返されました。
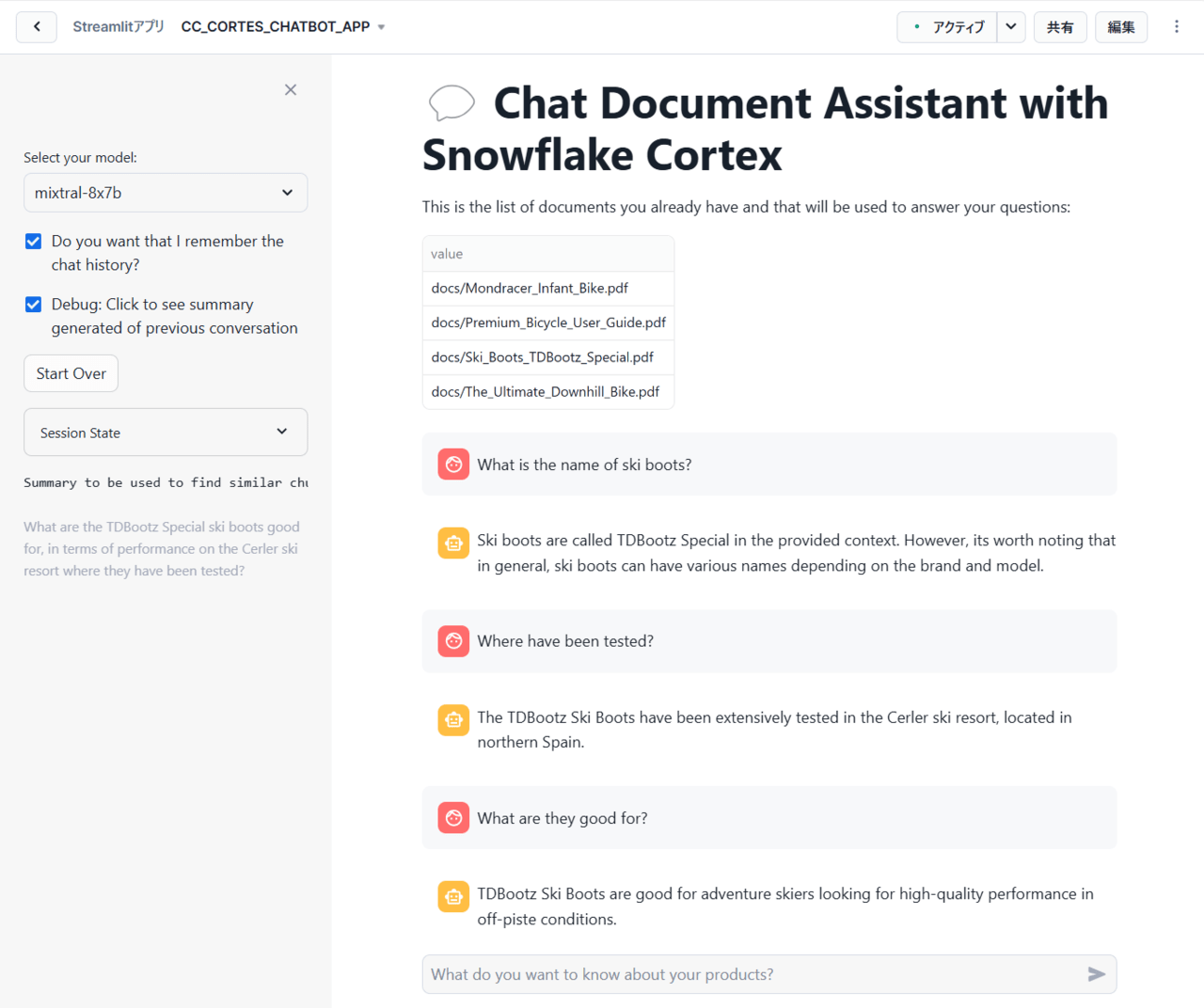
上記のチャット内容を日本語に訳すと以下の通りです。ここで、黒文字が質問、赤文字が回答となります。
①スキーブーツの名前は何ですか?
提供された情報によると、スキーブーツの名前はTDBootz Specialです。ただし、一般的にスキーブーツの名前はブランドやモデルによって様々であることに注意する価値があります。
②どこでテストされましたか?
TDBootz スキーブーツは、スペイン北部にあるセルレルスキーリゾートで広範囲にテストされました。
③何に適していますか?
TDBootz スキーブーツは、オフピステでの高性能を求めるアドベンチャースキーヤーに適しています。
上記を見てわかる通り、①の回答で得られたTDBootz Specialというスキーブーツの名前を、後続の質問②、③も引き継いで質問に回答していることが分かります。つまり、チャット履歴を記憶して会話できていると言えます!
チャット履歴を記憶しない場合
次に、サイドバーの「Do you want that I remember the chat history?」のチェックが外された状態、つまりチャット履歴を記憶しない状態で質問を投げかけてみたいと思います。
投げかけた結果、以下のような回答が返されました。
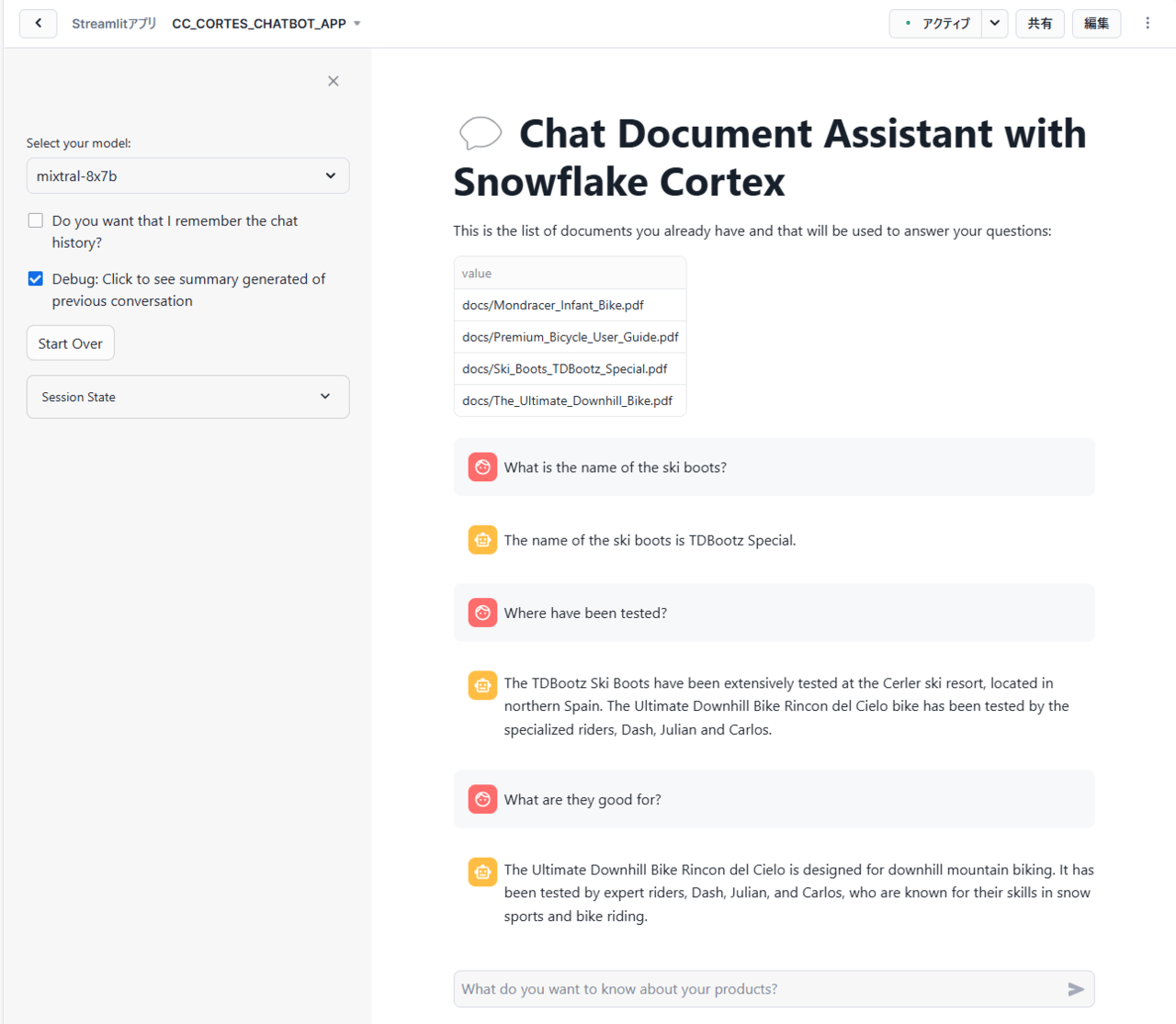
上記のチャット内容を日本語に訳すと以下の通りです。ここで、黒文字が質問、赤文字が回答となります。
①スキーブーツの名前は何ですか?
スキーブーツの名前はTDBootz Specialです。
②どこでテストされましたか?
TDBootz スキーブーツは、スペイン北部のセルレルスキーリゾートで広範囲にテストされました。Ultimate Downhill Bike Rincon del Cieloバイクは、ダッシュ、ジュリアン、カルロスという専門のライダーによってテストされました。
③何に適していますか?
Ultimate Downhill Bike Rincon del Cieloは、ダウンヒルマウンテンバイク用に設計されています。雪上スポーツと自転車に乗ることに長けたスキルを持つことで知られる、ダッシュ、ジュリアン、カルロスという専門のライダーによってテストされました。
上記を見てわかる通り、①ではTDBootz Specialというスキーブーツの名前を得られたにも関わらず、②、③ではUltimate Downhill Bike Rincon del Cieloというバイクに関する回答をしており、それぞれの質問に対する回答は独立しています。つまり、チャット履歴を記憶していないと言えます!
まとめ
本記事では、Snowflake CortexAIを使って独自のドキュメントに対して質問できるチャットボットUIを構築する方法、特に以前の会話を記憶させる方法について解説しました。ハンズオンを通して、当初構築が難しそうだと感じたチャットボットを比較的容易に実装できることを身に染みて実感しました!
特に、セッション変数を利用した会話履歴の管理は、より自然で文脈を理解した回答を実現する上で非常に重要だと感じました。単純な一問一答ではなく、過去のやり取りを踏まえた上でユーザーの意図を汲み取れるため、より人間らしい応対が可能になると感じました。この手法は、カスタマーサポートや社内ナレッジベースへのアクセスなど、様々な場面での応用が期待できると思います!
一方で、セッション管理やプロンプトエンジニアリングなど、更なる改善の余地も感じました。例えば、会話履歴の保存期間やトークン数の制限、より効果的なプロンプトの設計など、実運用においては考慮すべき点がいくつかあります。これらの課題に取り組むことで、より洗練された、実用的なチャットボットを構築できると思います。
引き続き、Snowflake CortexAIの最新情報に注目し、その進化を追い続けていきたいと思います!