

こんにちは!佐藤です。
「あれ、昔見た映画なんだっけ…タイトルが全く思いだせない…」
こんな経験、ありませんか?
映画の一場面やキャラクターは覚えているのに、タイトルが思い出せなくてモヤモヤする…。
友人と話していても結構こういう場面に遭遇するんですよね。
そこで今回は、Amazon Bedrockのナレッジベースとエージェント機能を使って、映画の断片的な記憶から作品を特定できるシステムを作ってみた――――というお話です。
1. Amazon Bedrockとナレッジベースとは?
Amazon Bedrockは、AWS(Amazon Web Services)が提供する生成AIサービスです。APIを通じてClaude、Stable Diffusion、Anthropicなど様々な基盤モデルを実装したサービスを構築できるのが特徴です。
その中でも今回注目したいのが「ナレッジベース」機能。
これは独自のデータをAIに学習させ、そのデータを基に回答を作成する、自分だけのAIアシスタントを作れる機能です。
映画情報をナレッジベースに登録すれば、「宇宙で女性が一人」などの断片的な情報から映画を特定できるようになります!

ナレッジベースの特徴
2. システム構築をしてみよう
アクセス設定
まずはAmazon Bedrockへのアクセス設定から始めます。
AWSマネジメントコンソールにログインし、Bedrockサービスに移動しましょう。
初めて使う場合は、モデルアクセスの設定が必要です。サイドバーの「モデルアクセス」から必要なモデルへのアクセスをリクエストします。
今回は特にClaude 3.5 Sonnet v2モデルを使用するので、このモデルへのアクセスを確保しておきましょう。
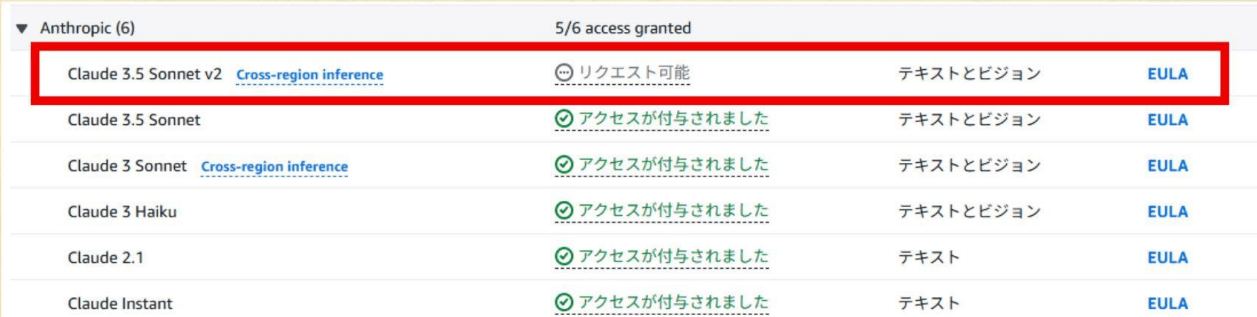
アクセス権がリクエスト可能になったら、リクエストを送信し、許可を待ちます。通常数分で承認されます。
データの準備
次に、映画データの準備です。今回私は次のような情報を含むJSONファイルを作成しました:
今回は、国内最大級の映画・ドラマ・ アニメレビューサイト「Filmarks(https://filmarks.com)」さんのデータをお借りして投入データを作成してみました。
その中でも、2024年最も輝いた映画・ドラマ・アニメを表彰する「Filmarks Awards 2024」の、国内映画部門ノミネート作品から、以下の5作品のデータを投入します(詳細は、https://filmaga.filmarks.com/articles/315003/)。

このデータをS3バケットにアップロードします。
コンソールからS3サービスに移動し、「バケットを作成」をクリックします。
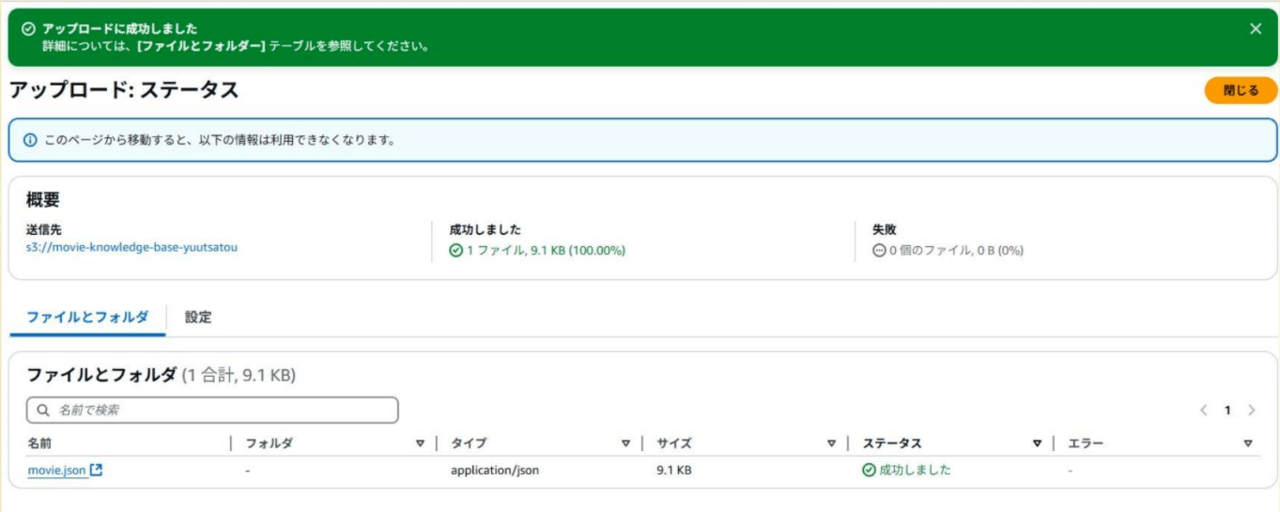
私は「movie-knowledge-base-yuutsatou」という名前でバケットを作成し、先ほど準備したJSONファイル(movie.json)をアップロードしました。
ナレッジベースの作成
データの準備ができたら、いよいよナレッジベースを作成します。
Bedrockコンソールの「オーケストレーション」から「ナレッジベース」を選択し、「作成」ボタンをクリックします。
ナレッジベースの詳細を設定します:
- 名前:「MovieMemoryKnowledgeBase」
- 説明:「曖昧な記憶から映画を特定するためのナレッジベース」
- データソース:S3から先ほどアップロードしたJSONファイルを指定
- ベクトルストア:OpenSearch Serverlessを使用
設定が完了したら、ナレッジベースを作成します。インデックス作成には少し時間がかかりますが、辛抱強く待ちましょう。
エージェントの作成
最後に、このナレッジベースを活用するエージェントを作成します。
「オーケストレーション」の「エージェント」から「エージェントを作成」をクリックします。
エージェントの詳細を設定します:
- 名前:「MovieMemoryAssistant」
- 説明:「曖昧な記憶から映画を特定するアシスタント」
- モデル:Claude 3.5 Sonnet v2
- エージェント向けの指示:
あなたは映画の専門家です。ユーザーの曖昧な記憶や断片的な情報から映画を特定することを得意としています。
例えば:
-「80年代の、タイムマシンの映画で、車に乗って過去に行くやつ」からは「バック・トゥ・ザ・フューチャー」を特定
-「宇宙で女性が一人取り残される映画」からは「ゼログラビティ」を特定など
ユーザーの質問から映画を特定できない場合は、「他にどんな特徴があったか教えてみてよ~」と言って、ユーザーからの追加情報を引き出す質問をしてください。
映画を特定できた場合は、タイトル、監督、制作年、主演俳優、簡単なあらすじを教えてあげてください。
さらに、先ほど作成したナレッジベース「MovieMemoryKnowledgeBase」をエージェントに関連付けます。
エージェント向けのナレッジベースの指示には、以下のようにフィールドマッピングを設定しました:
以下のようにフィールドマッピングされているので、回答の参考にしてください。
{title}:日本語のタイトル
{title_en}:英語のタイトル
{year}:公開年
{director}:監督名
{cast}:主な出演者
{synopsis}:あらすじ
{keywords}:キーワード(映画の中で印象強いシーンなど。ここが最も重要視される)
すべての設定が完了したら、エージェントを作成します。
4. 実際に試してみた結果
さて、いよいよ完成したシステムを試してみましょう!
なんと、一発で正解しました!しかも情報もかなり詳しいです。
次に少し難しい質問を試してみます。
おお!これも正解です!映画の中のワンシーンでしかない洗濯機が出てくるシーンをよく理解できましたね…
5. まとめと今後の改善点
今回はAmazon Bedrockのナレッジベースとエージェント機能を使って、「あの映画なんだったっけ?」問題を解決するシステムを構築してみました。実際に試してみた感触は以下の通りです!
良かった点
- 断片的な情報からでも映画を特定できた!
- 自然な会話形式で映画について質問できる!
- タイトルだけでなく、監督や出演者、あらすじも教えてくれる!
改善したい点
- より多くの映画データを追加しても回答がかぶらないのか?(現在はまだ系統の違う5作品のみ)
- 複数の候補がある場合の絞り込み精度を上げる(追加の質問を自主的に考えられるのか?)
また、投入したデータの粒度や形式によっても回答の精度は変わりそうですね…
あらすじやキーワードといった、回答にダイレクトに使えそうなデータを投入したので、これが曖昧になると回答がどうなるのかも気になります。。
映画好きの皆さん、「あの映画なんだったっけ?」でモヤモヤすることなく、スムーズに映画の会話を楽しめる日が近いかもしれません…!