

本記事では、Google Cloudの新サービス「AlloyDB」について性能を検証したので、その内容を記載します。
そもそも「AlloyDB」とは
オープンソースDBであるPostgreSQLとの完全互換性を特徴としたフルマネージドRDBMS です。
AlloyDBはPostgreSQLとの互換性を保ちながら、DBに最適化されたストレージアーキテクチャを採用しています。また、集計に必要な列だけを読み込むことでI/Oのオーバーヘッドを大きく削減できるカラムストアによって分析を高速化しています。
ただし、Google Cloudにはすでに「Cloud SQL」と呼ばれる「AlloyDB」に類似するRDBMSが存在します。
では性能面でこの2つにはどのような違いがあるのでしょうか?
早速検証していきましょう。
検証内容
構成イメージ
構成イメージは以下の通りです。
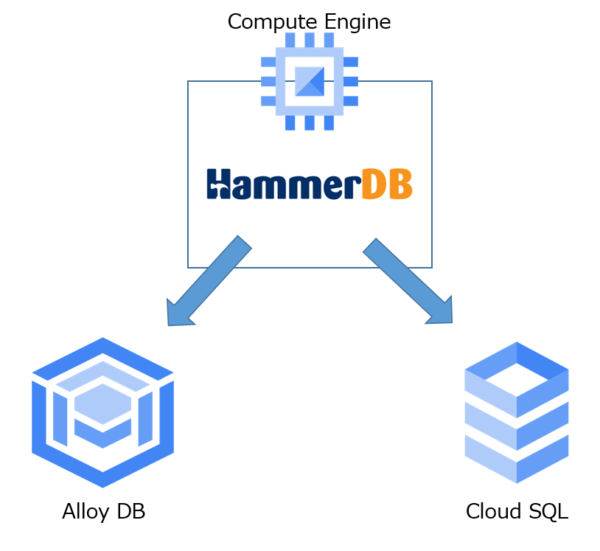
AlloyDBのマシンタイプ
- コア数:2
- メモリ:16GB
- 場所:asia-northeast1-c
- 高可用性構成
Cloud SQLのマシンタイプ
- コア数:4
- メモリ:16GB
- 場所:asia-northeast1-c
- 高可用性構成
使用したベンチマークアプリケーションとその条件
今回はOLAP系の処理を手軽にできるという強みのある、HammerDB ver4.5 を採用しました。
HammerDBの条件
- 同時実行ユーザー数:1ユーザ
- 繰り返し回数:10回
- データ量:20GB

以上の条件でAlloyDBとCloud SQLに負荷をかけ、終了時間の差を確認します。
また、今回は2つのパターンで検証してみました。
《パターン1》ベンチマークテスト
パターン1では特にクエリを意識することなく、シンプルなベンチマークテストを行い処理速度を比較することにしました。
《パターン2》特定の列に対する分析系クエリを流す
パターン2では大量の件数があるテーブルへの特定の列へアクセスをした際のパフォーマンスを確認するため、以下のようなクエリを用意しました。

フラグの設定の仕方は以下をご参考ください。
検証結果
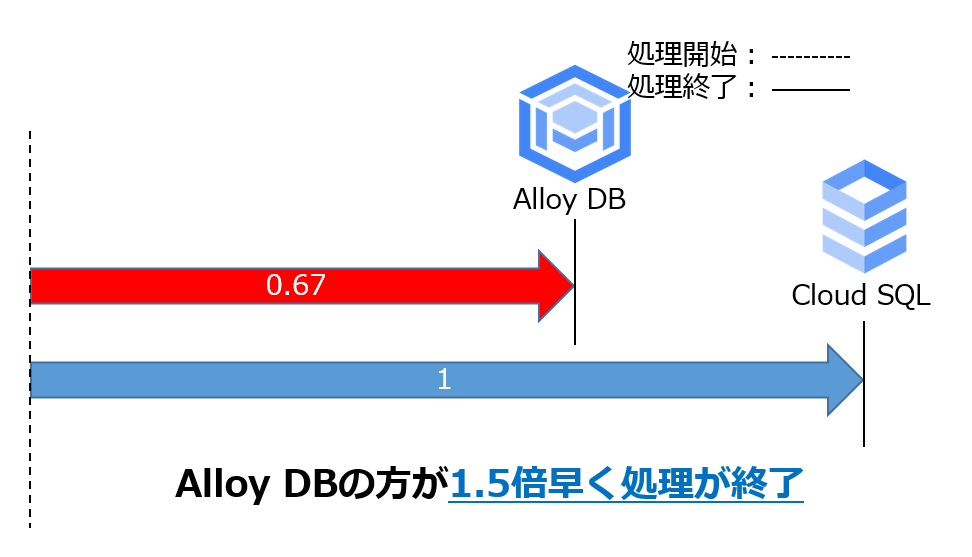
《パターン1》では以下の通りCloud SQLよりAlloyDBの方が1.5倍早く処理が終了しました。
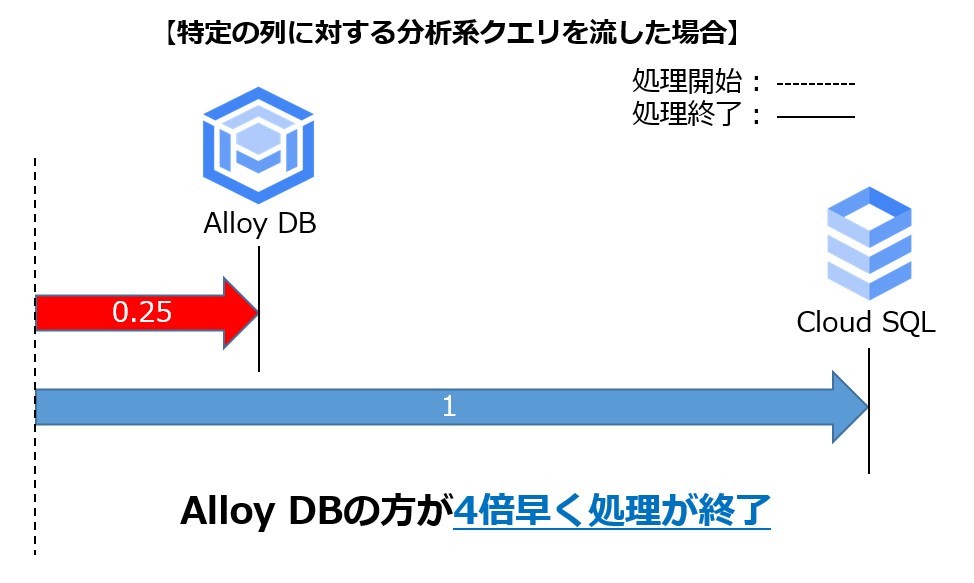
また《パターン2》では以下の通りCloud SQLよりAlloyDBの方が4倍早く処理が終了しました。
《パターン2》のクエリがカラムストアを使用しているかはEXPLAINコマンドで確認しました。
QUERY PLAN
—————————————————————————————————————
Finalize GroupAggregate (actual rows=2525 loops=1)
Group Key: l_shipdate
Buffers: shared hit=14
-> Gather Merge (actual rows=7575 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=14
-> Sort (actual rows=2525 loops=3)
Sort Key: l_shipdate
Sort Method: quicksort Memory: 452kB
Buffers: shared hit=14
Worker 0: Sort Method: quicksort Memory: 452kB
Worker 1: Sort Method: quicksort Memory: 452kB
-> Partial HashAggregate (actual rows=2525 loops=3)
Group Key: l_shipdate
Batches: 1 Memory Usage: 1649kB
Worker 0: Batches: 1 Memory Usage: 1649kB
Worker 1: Batches: 1 Memory Usage: 1649kB
-> Parallel Append (actual rows=0 loops=3)
-> Parallel Custom Scan (columnar scan) on lineitem (actual rows=60002889 loops=3)
Rows Removed by Columnar Filter: 0
Rows Aggregated by Columnar Scan: 19693657
Columnar cache search mode: native
-> Parallel Seq Scan on lineitem (never executed)
Planning:
Buffers: shared hit=169 read=12
I/O Timings: read=2.036
(27 rows)
パターン1、パターン2ともに高速になったことから、AlloyDBがいかに優れたRDBMSであるかがうかがえますね。
まとめ
今回の検証結果から、さまざまなワークロードが含まれるシステムにAlloyDBが優れた性能を発揮でき、特に列アクセスが含まれるワークロードに関してはよりその性能向上が期待できることが分かりました。またAlloyDBの方がコア数が少ないにも関わらず良いパフォーマンスを発揮したことから、AlloyDBはより少ないコンピューティングリソースでも優れたパフォーマンスを実現できると言えそうです。
ちなみに今回は手動でフラグを追加しましたが、AlloyDBには自動的にフラグを追加してくれるような機能もあるみたいです。
ですのでGoogle CloudでPostgreSQLを利用する場合、性能面や管理の楽さを重視するのであればCloud SQLよりもAlloyDBを選択する方が良いと思います。
AlloyDBについて興味を持った方は是非使用してみてください!!

参考
- AlloyDB for PostgreSQL
- Cloud SQL
- HammerDB
- フラグの設定方法
- フラグの自動追加方法