

こんにちは! SCSKの山口です。
先日「From Data to Insights with Google Cloud」という三日間の研修に参加してきました。
BigQueryを活用し、大規模データから分析情報を取り出す方法を探るといった内容のものでしたが、その中でも「分析のためのテーブル分割」の内容が個人的にとても興味深かったので、今回はBigQueryでの「テーブルの論理パーティション分割の有効性」についてご紹介します。
BigQueryとは
概要

BigQueryは、”費用対効果”に優れたGoogle Cloudのデータウェアハウスサービスです。
主な機能は以下の通りです。
- 組み込みの機械学習
- 各種クラウドでのデータ分析、共有
- クエリ高速化機能によるリアルタイム分析
- あらゆる種類のデータ統合、管理、統制
他にも様々な機能がありますが、BigQueryでは“ペタバイト規模のデータセットに対するクエリ実行を数十秒で完了できる”ことによって“大規模なデータをほぼリアルタイムで分析する”ことが可能です。

課金体系
BigQueryの課金体系についてご紹介します。BigQuery料金の要素には大きく分けて以下の二つがあります。
[BigQuery料金の要素]
- 分析料金:クエリの処理にかかる費用
- ストレージ料金:BigQueryに読み込むデータを保存する費用
さらに、分析料金のモデルには以下の二つがあります。
[分析料金のモデル]
- オンデマンド料金:各クエリによって処理されたバイト数に基づいて課金
- 定額料金:仮想CPUであるスロットを購入することで専用の処理容量を購入する
どの課金体系を選択するかは要件次第ですが、デフォルトでは「オンデマンド料金モデル」で課金されます。
【概要】でも述べた通り、BigQueryでは“大規模なデータをほぼリアルタイムで分析する”ことが可能です。
しかし、それには“多額の料金が発生する恐れ”があるので、十分な配慮が必要となります。
データセット内でテーブルを分割
概要
前述したとおり、大規模なデータを分析する際はデータの読み取りが大量に発生し、結果として多額の料金が発生してしまう恐れがあります。
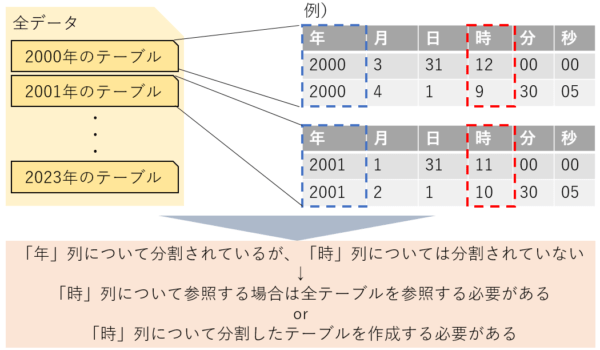
例えば以下の図のような状態です。

例えば上記の場合、参照したいのは2023年12月31日のデータのみですが、それ以外のデータに対する多くの無駄な参照が発生してしまうことになります。
このような場合に有効となる手段の一つが”データセット内でのテーブル分割”です。
文字通り、あらかじめテーブルを分割して作成することにより参照する回数を減らし、読み取りのバイト数を削減する方法です。
以下のようなイメージになります。
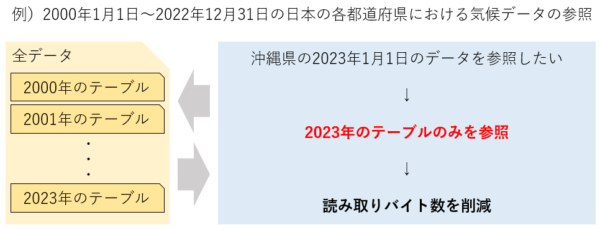
上図の各年のテーブルはすべてBigQueryの標準テーブルです。
(※以降、上図のようにデータセット内のテーブルを複数の標準テーブルに分割することを”テーブル分割”と表します。)
それでは実際に分割された標準テーブルでのクエリ実行をやってみます。
やってみた①:ワイルドカードテーブルと_TABLE_SUFFIXを使用した分割後の標準テーブルに対するクエリ実行
ここでは、「ワイルドカードテーブル」と「_TABLE_SUFFIX」を使用して分割された標準テーブルへのクエリ実行を行い、読み取られたバイト数を見ることで有効性を確認します。
まずは用語の確認です。
|
用語
|
意味
|
例
|
|---|---|---|
| ワイルドカードテーブル | ワイルドカードを用いた式に一致するすべてのテーブルを結合したもの。 | table1900~table2022が存在する場合(1900年~2022年の一年ごとに分割されたテーブル)
・table19* ⇒ table1900~table1999が結合されたテーブル |
| _TABLE_SUFFIX | クエリで参照する対象範囲を特定のテーブルセットに限定する際に使用。 | 上記のワイルドカードテーブルから1950年以降のテーブルを参照したい場合
・WHERE _TABLE_SUFFIX >= ’50’ |

それでは上記の内容を実際にやってみます。
今回は、BigQueryの一般公開データセットである「bigquery-public-data」の中の「noaa_historic_severe_storms」データセットを使用して検証します。
※一般公開データセットに関する情報はコチラをご覧ください。
「noaa_historic_severe_storms」データセットの詳細情報は以下の通りです。
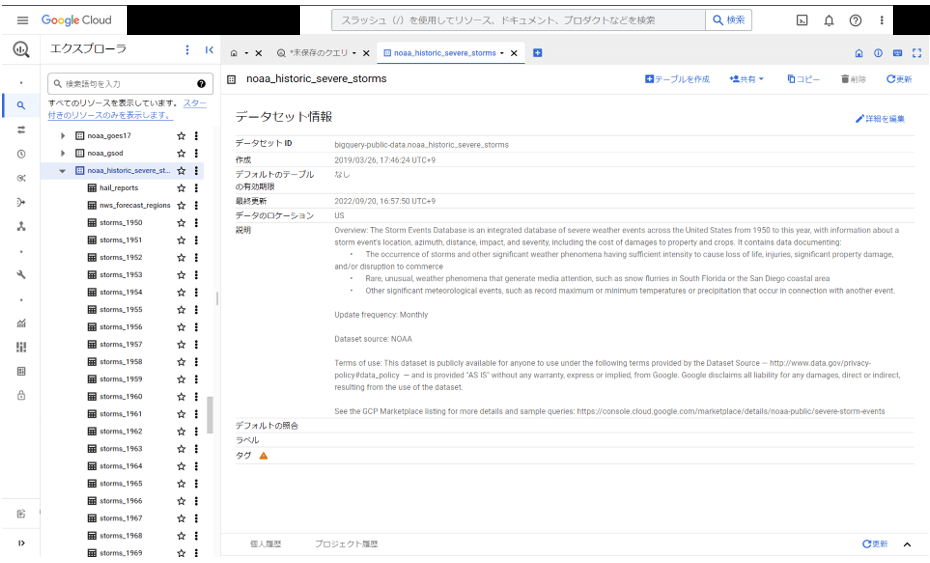
このデータセットには、1950年~2023年の間にアメリカで発生した暴風雨の情報を一年ごとに分割したテーブルが含まれています。
例として、2022年のテーブルの詳細を見てみます。
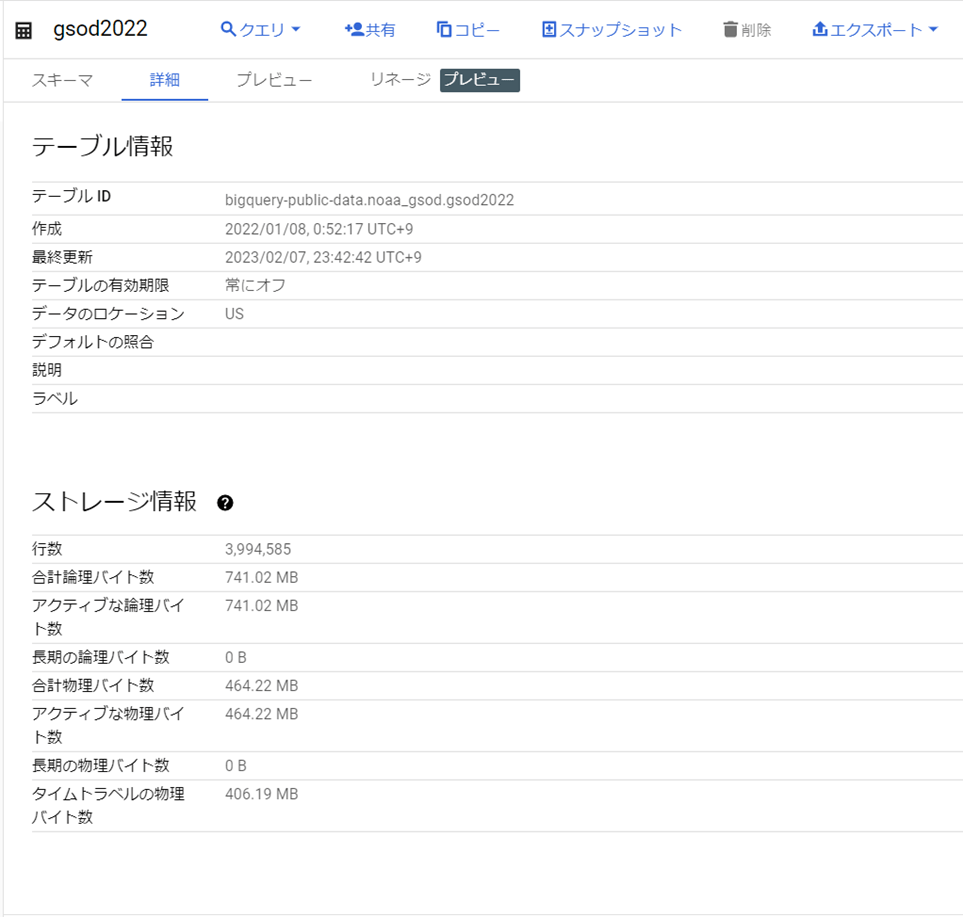
ストレージ情報の「合計論理バイト数」を見ると、2022年のテーブルだけで約740MBのデータが含まれています。本データセットには70年分以上のテーブルが含まれていますので、単純計算で約50GB以上のデータが含まれていることになります。
では、このデータセットから「2022年以降のデータのみを取り出す」クエリを実行してみましょう。
実行する前に、今回参照するテーブル全体の合計バイト数を計算しておきます。
2022年のバイト数は確認済みなので、2023年のデータを確認します。

以上より今回参照対象のテーブルの合計バイト数は741.02+68.28=809.3MBとなります。
以下、「2022年以降のデータのみを取り出す」ために実際に実行したクエリとその結果です。
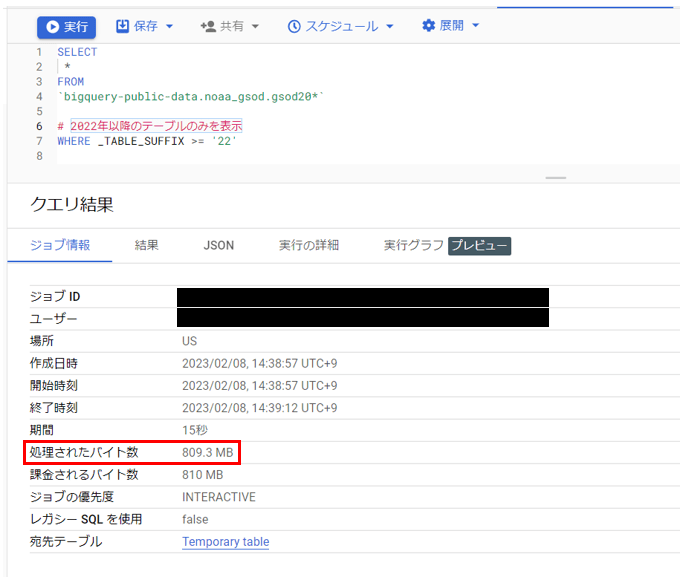
赤枠から確認できる通り、処理されたバイト数が見積もっていた809.3MBと一致しています。
以上より、ワイルドカードテーブルと_TABLE_SUFFIXを使用することで全体で50GB以上のデータセットのすべてを参照することなく、任意のデータを読み取ることができました。
しかし、ここまでの内容はあくまで「あらかじめテーブルが適切に分割されているとき」に活用できる方法です。
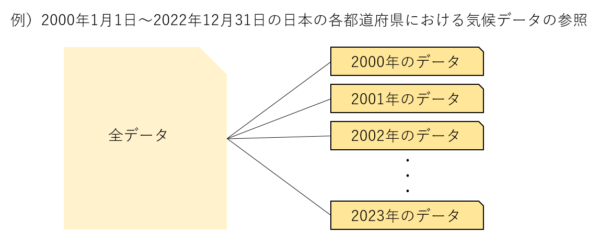
実際にBigQueryを用いる場面では、そもそもテーブルが分割されていない場合や、求める粒度でテーブルが分割されていない場合も多いでしょう。例えば以下のように、「年ごとに分割された複数の標準テーブルから”12時台のデータ”を取り出したい場合」などは今回紹介した方法が通用しません。時間ごとに分割された標準テーブルを作成するのにも時間と労力が必要です。
そのような場合に役立つのが次に紹介する「テーブルの論理パーティション分割」です。
テーブルの論理パーティション分割
概要
「パーティション分割テーブル」とは、単一のテーブルを複数の論理パーティションに分割したテーブルです。以下の図のようなイメージになります。
テーブルの設計時にパーティションを適切に設定しておくことで、クエリ実行によって読み取られるバイト数を削減することができ、コストを抑えることができます。
パーティショニングには以下の種類があります。
| パーティショニング種別 | 種類 | 詳細 |
|---|---|---|
| 整数範囲パーティショニング | INTEGER | ”列名、開始、終了、間隔”を引数として指定 |
| 時間単位列パーティショニング | DATE | 日単位、月単位、年単位で作成可能 |
| TIMESTAMP | 時間単位、日単位、月単位、年単位で作成可能 | |
| DATETIME | ||
| 取り込み時間パーティショニング | (データを取り込んだ時間に基づいて行を割り当て) | ”_PARTITIONTIME疑似列”を用いてパーティショニング |
やってみた②:パーティション分割テーブルに対するクエリ実行
ここからは実際に「テーブルの論理パーティション分割」を使用し、クエリを実行してみます。
今回は「時間単位列パーティション分割」を実践します。その他パーティション分割テーブルの作成に関しては下記参考サイトをご参照ください。
ここでは自作した下記の「date」テーブルを使用します。以下、「date」テーブルの詳細です。
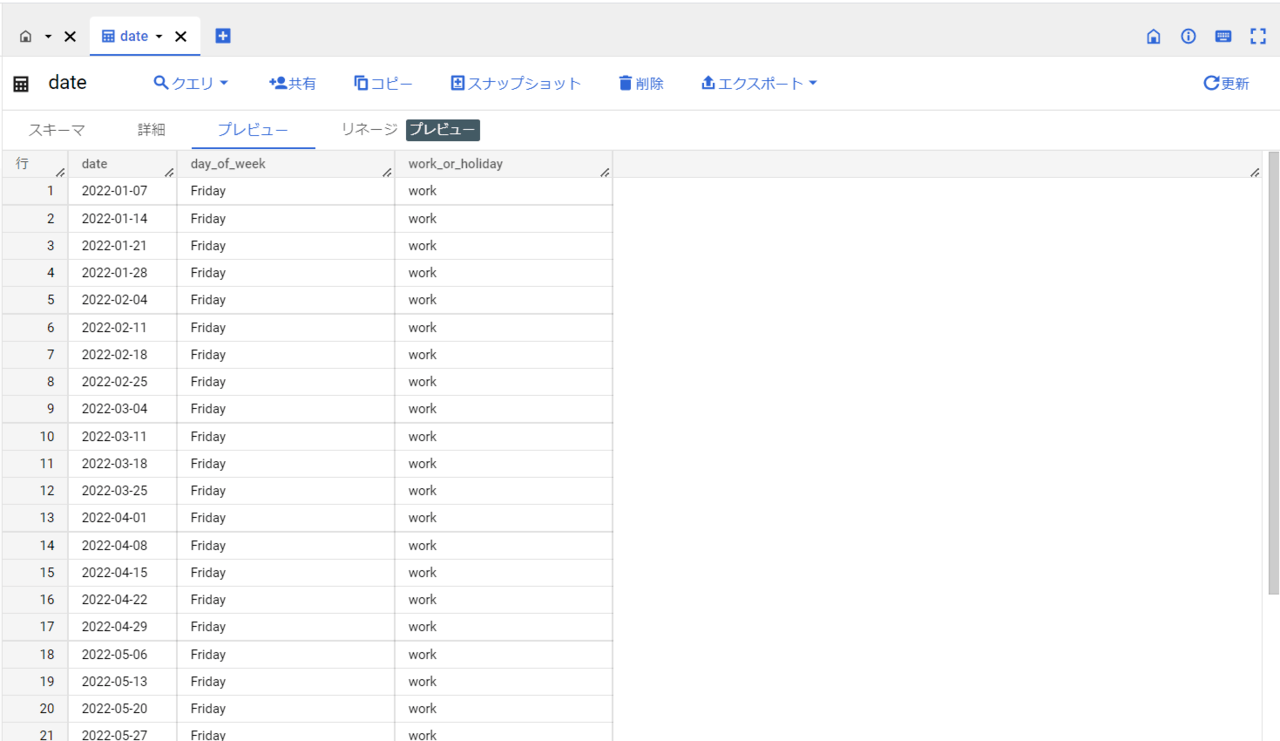
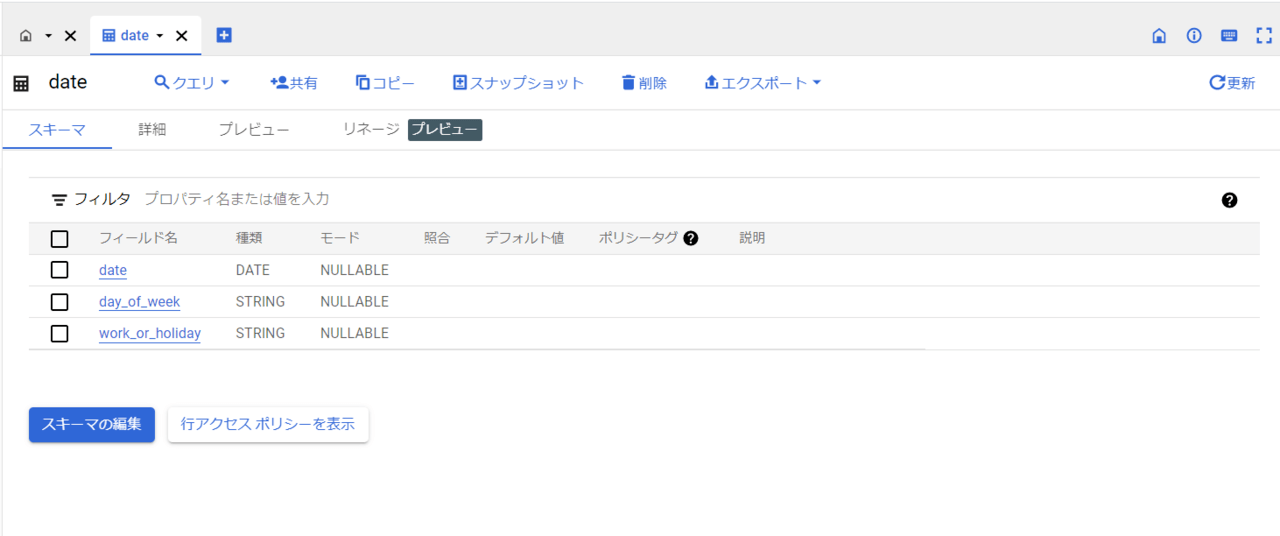
dateテーブルは以下のフィールドを持つテーブルです。
- data:日付
- day_of_week:曜日
- work_or_holiday:仕事か休日(平日か土日)か ※祝日は考慮していません。
dateテーブルに関しては、まだパーティション分割がされていません。ここからパーティション分割をしていきます。
以下クエリを実行し、dateテーブルをパーティション分割をした”partition_by_date”テーブルを作成します。
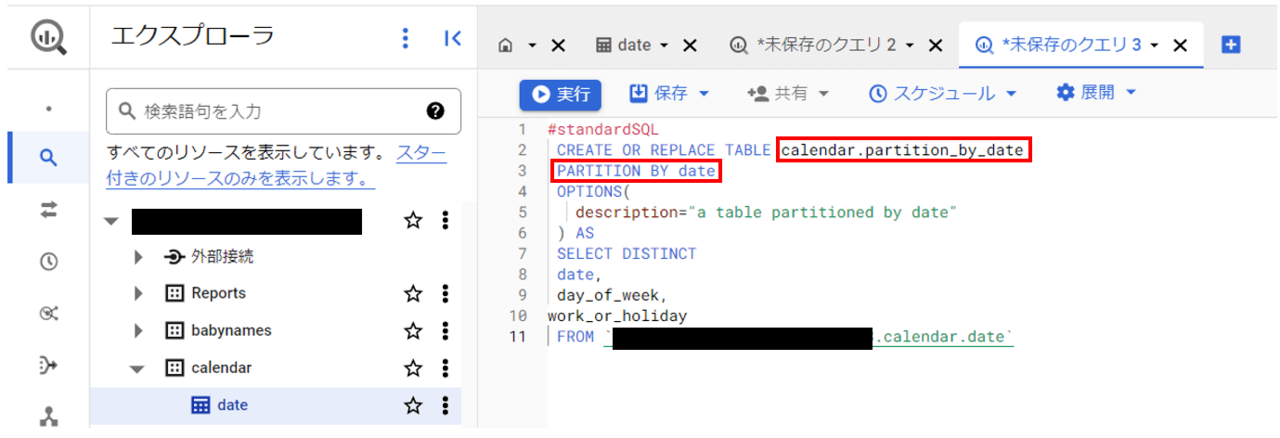
上記クエリの詳細について説明します。
|
行数
|
内容
|
説明
|
|---|---|---|
| 2 | CREATE OR REPLACE TABLE calendar.parttition_by_date | calendarデータセット配下に「parttition_by_date」という名称でテーブルを作成。
(calendar.dateとすると上書き) |
| 3 | PARTITION BY date | 「date」フィールドでパーティション分割を行うことを指定。
(※「型」ではなく「行」を指定) |
| 4~6 | OPTIONS(
description=”a table partitioned by date” ) |
テーブル情報の説明欄に記載する文言を指定。 |
上記クエリの実行によって以下のテーブルが作成できました。
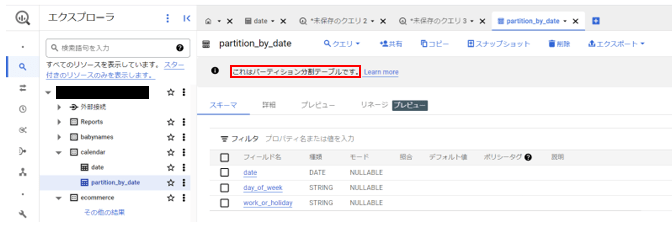
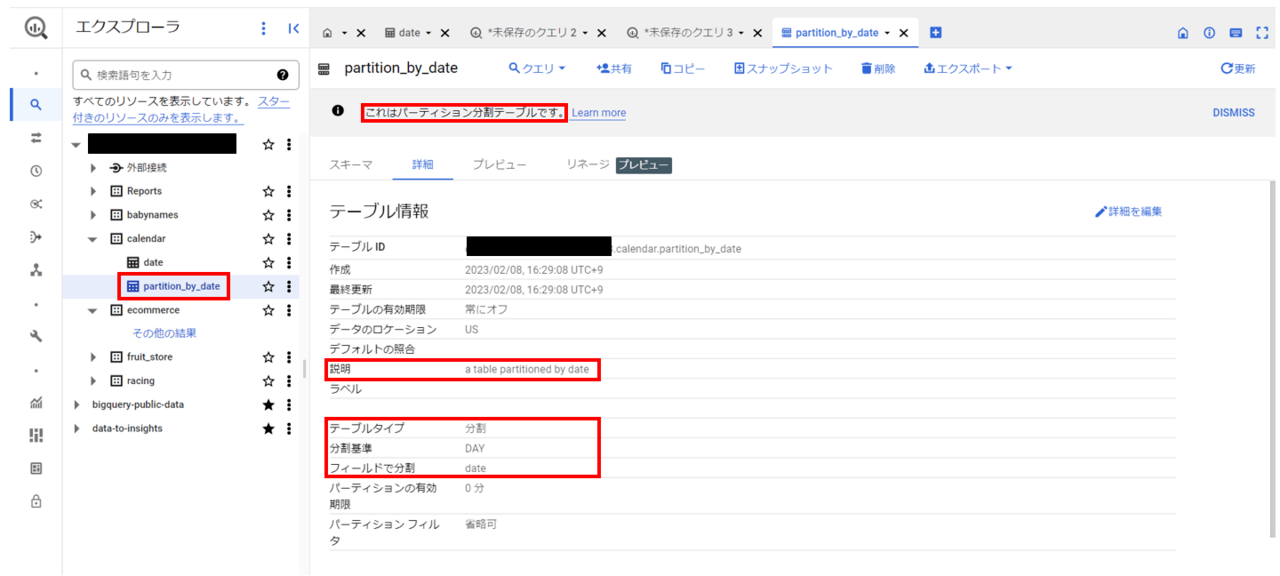
それではここから、パーティション分割前後のテーブルに対して「ある特定の日のデータを取り出す」内容の同一のクエリを実行し、クエリ実行に対する課金バイト数を比較します。
実行内容と結果は以下の通りです。
|
|
パーティション分割前
|
パーティション分割後
|
|---|---|---|
| 実行クエリ | SELECT *
FROM ’[リソース名].calendar.date‘ WHERE date = ‘2023-01-01’ |
SELECT *
FROM ’[リソース名].calendar.partition_by_date‘ WHERE date = ‘2023-01-01’ |
| 実行クエリ内容 | dateテーブル(パーティション分割前テーブル)から
2023年1月1日のデータを得る。 |
partition_by_dateテーブル(パーティション分割後テーブル)から
2023年1月1日のデータを得る。 |
| クエリ実行結果画面 |
|
|
| 処理されたバイト数(B) | 9470 B | 25 B |
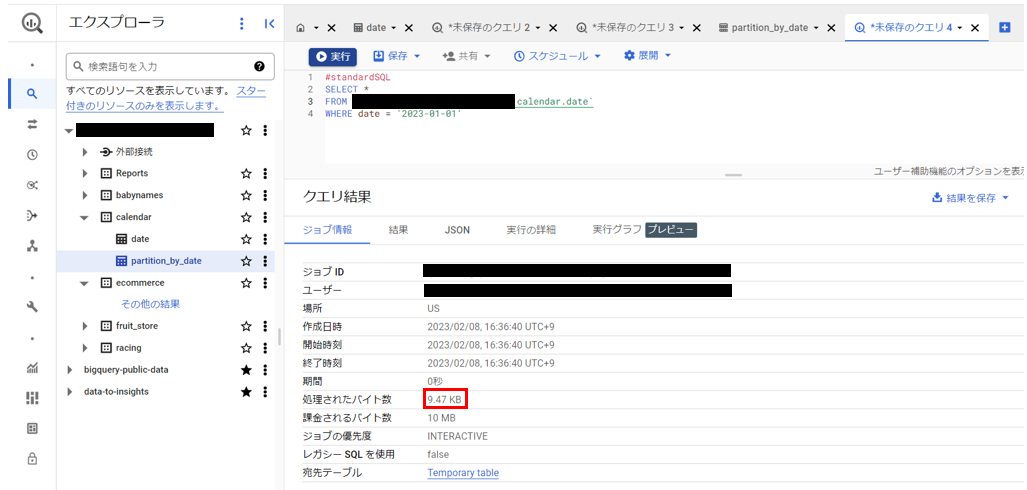
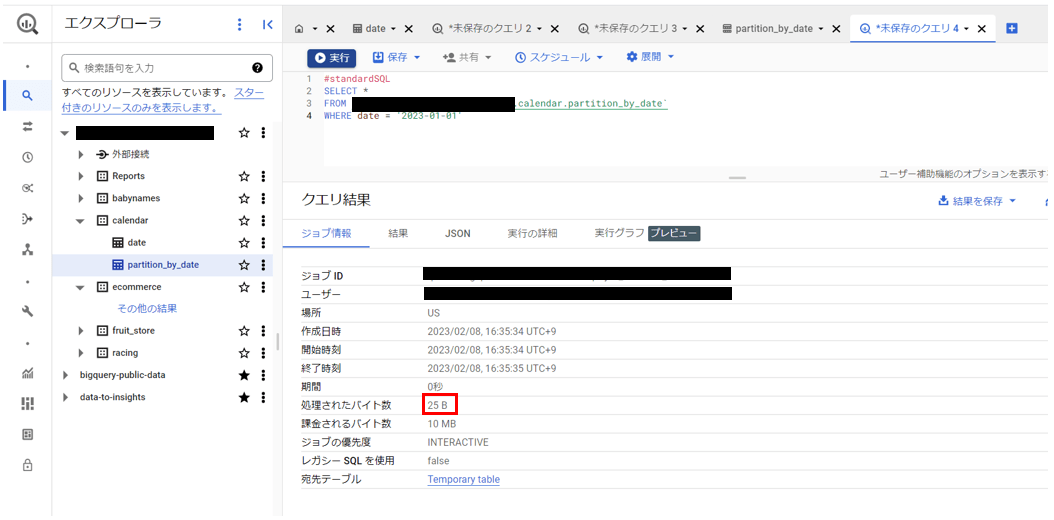
実行結果より、処理されたバイト数に大きな差が表れていることがわかります。
クエリ結果画面の「課金されるバイト数」に関しては、クエリ当たりのデータ最小処理容量が10 MBであるため今回はどちらも10 MBとなっています。
今回は小さな規模のテーブルでの検証であるため課金対象が10 MBに丸められていますが、大規模なデータセット・テーブルを扱う際はパーティション分割を行うことでコストを削減することが可能です。
もう一つ検証してみましょう。今度は、ヒットするデータが0件となるクエリを実行してみます。
実行内容と結果は以下の通りです。
|
|
パーティション分割前
|
パーティション分割後
|
|---|---|---|
| 実行クエリ | SELECT *
FROM ’[リソース名].calendar.date‘ WHERE date = ‘2024-01-01‘ |
SELECT *
FROM ’[リソース名].calendar.partition_by_date‘ WHERE date = ‘2024-01-01‘ |
| 実行クエリ内容 | テーブルに存在しない値(2024年1月1日)を検索。 | テーブルに存在しない値(2024年1月1日)を検索。 |
| クエリ実行結果画面 |
|
|
| 処理されたバイト数(B) | 9470 B | 0 B |
| 課金されるバイト数(B) | 10000000 B | 0 B |
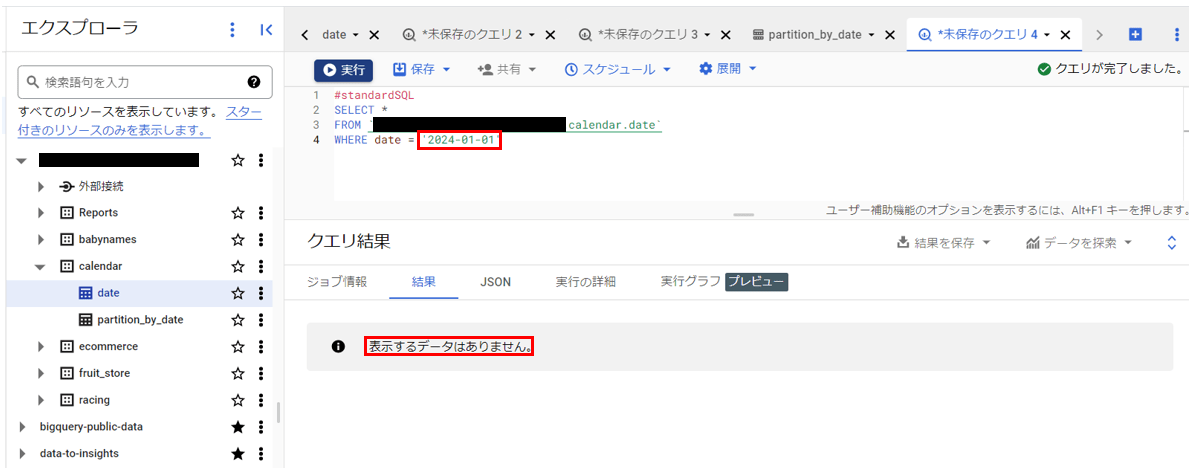

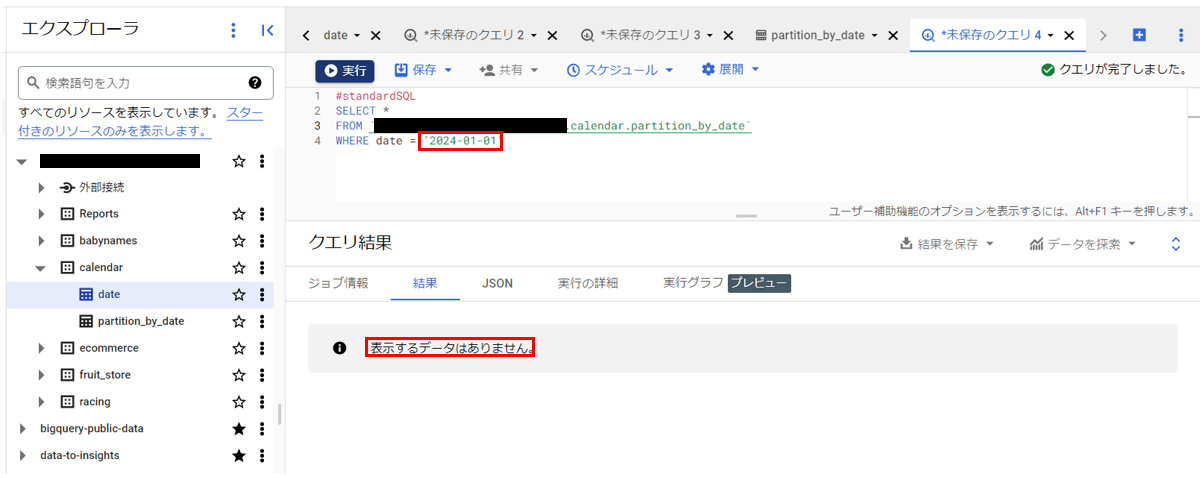
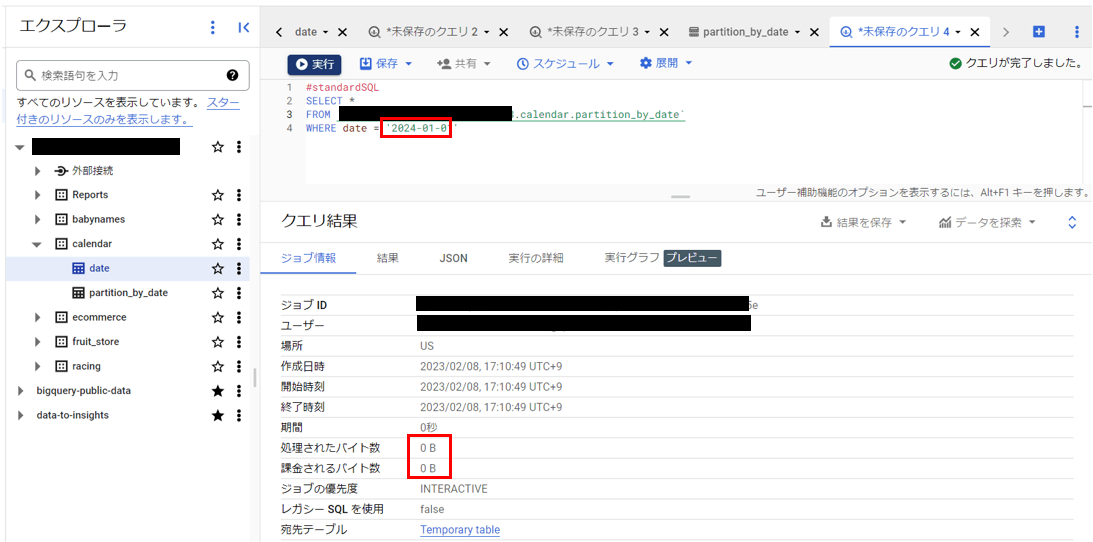
処理されたバイト数・課金されたバイト数を見てみると、なんと分割前のテーブルでは”返される結果が0件でもクエリの読み取り(課金)が発生”しているのに対し、分割後のテーブルでは”返される結果が0件の場合はクエリの読み取り(課金)が発生しない”という結果になりました。
パーティション分割前と後で、以下のような処理の違いが発生することにより、処理バイト数・課金対象バイト数に違いが生じています。
- パーティション分割前:WHERE句の条件を判定するためにすべてのレコードのdate値を参照
- パーティション分割後:実行クエリに関係のないパーティションのレコードは一切参照しない
パーティション分割テーブルを活用し、大規模なテーブルをパーティションで分割することでクエリ実行のパフォーマンス向上、クエリ実行に対するコスト削減の効果があります。
まとめ
今回は、テーブル分割と論理パーティション分割についてご紹介しました。最後にテーブル分割、論理パーティション分割のそれぞれの特徴についてまとめます。
(「ここだけ読めば何とかなる。」レベルでまとめます。)
テーブル分割
テーブル分割は、データセット内を以下のように分割するイメージです。
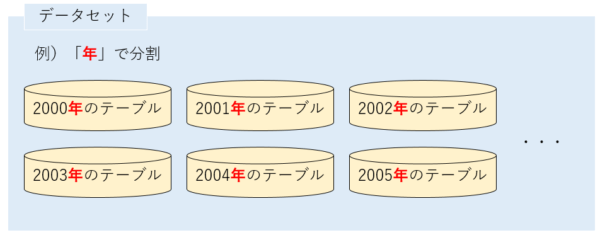
上図のようにデータセット内を「年」で分割することで、データの読み取りバイト数を抑えてクエリを実行し、任意のデータを得ることができます。
しかし、「日」や「時」単位でデータを取得したい場合はすべてのテーブルに対して読み取りを行うか、手間をかけてテーブルを分割しなおす必要があります。
論理パーティション分割
論理パーティション分割は、データセット内のテーブルをもとに、任意の列※に関して分割したテーブルを作成します。
(※整数範囲、時間単位、取り込み時間による分割のみが可能)
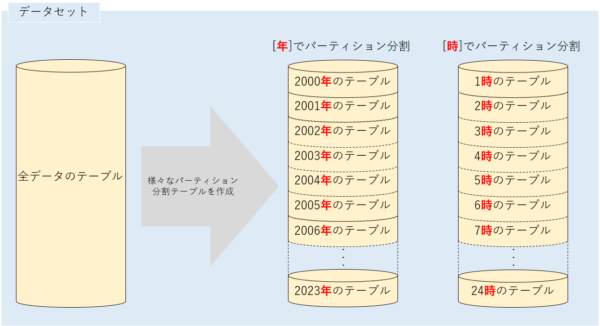
テーブル分割とは異なり、数行のクエリを実行するだけでパーティション分割テーブルの作成が可能なため、より柔軟なテーブルの加工が可能です。
ただし、論理パーティション分割には”パーティションの上限が4000”という制限があります。このため、より細かい粒度でデータを取り扱う際には注意が必要となります。
最後に
アウトプットのスピードを上げると言いつつ、またまた数か月かかってしまいました。
今回のブログ執筆の内容調査をしているうちに、「クラスタリング」の技術が気になったので次はこれに関して書こうと思います。(いつになることやら。。)
参考