

こんにちは。SCSKの山口です。
今回は、過去のブログで作成したモデルが算出した予測値を説明させてみよう。の回です。
以前作成した線形回帰モデルで、工場の製造コスト、人件費、生産効率、従業員数から、工場の「原材料費」を予測するモデルを作成し、下記の予測値を出力として得ました。

この結果、モデルがどうやって算出したのか気になりませんか、、、?
そんな時に役立つのが、XAIとも呼ばれるBigQuery Explainable AI です。早速見ていきましょう。
BigQuery Explainable AI
Explainable AI は、データ行の各特徴がどのように予測結果に影響を与えるかを定義することで、予測 ML モデルが分類タスクと回帰タスクに対して生成する結果の理解を容易にします。この情報を「特徴アトリビューション」と呼びます。
カンタンにいうと
- モデルが期待通りに動作していることの確認
- モデルのバイアスを認識すること
- モデルやトレーニングデータの改善方法を知ること
が可能です。
ローカルとグローバルの説明可能性
説明可能性には、ローカルの説明可能性とグルーバルの説明可能性の2種類があります。
それぞれの説明可能性から「ローカルな特徴重要度」と「グローバルな特徴重要度」を得ることができます。
ローカルの説明可能性
説明された各列の特徴アトリビューション値を返します。
これらの値は、それぞれの特徴がベースラインの予測に対してどの程度影響を及ぼすかを示します。
ローカル説明関数の「ML.EXPLAIN_PREDICT」を使用することで取得可能です。
グローバルの説明可能性
データセット全体の特徴アトリビューションを集計し、モデルに対する特徴の全体的な影響を返します。
絶対値が大きいほど、特徴がモデルの予測により大きな影響を与えたことを示します。
グローバル説明関数の「ML . GLOBAL _ EXPLAIN」を使用することで取得可能です。
ここから実践に入りますが、以前作成したモデルは単一のテーブルで学習させたので、今回はローカルの説明可能性を試してみます。
実践:ローカルな特徴重要度を取得
ローカル説明関数の「ML.EXPLAIN_PREDICT」を使った下記クエリを実行します。
SELECT * FROM ML.EXPLAIN_PREDICT( MODEL `yamaguchi_test_bqml.test_model_liner_reg`, ( SELECT IFNULL(cost_manufacturing, 0) AS cost_mf, IFNULL(cost_material, 0) AS label, IFNULL(cost_employees, 0) AS cost_emp, IFNULL(manufacturing_line, 0) AS manu_line, IFNULL(manufacturing_efficiency, 0) AS manu_eff, IFNULL(employees, 0) AS emp FROM `yamaguchi_test_bqml.test` WHERE employees=476 ), STRUCT(5 AS top_k_features) )
上記クエリのサブクエリのSELECT句
で評価データを生成するクエリを入力します。今回は以前のブログで実際の予測をする際に使用したクエリを流用します。
また、
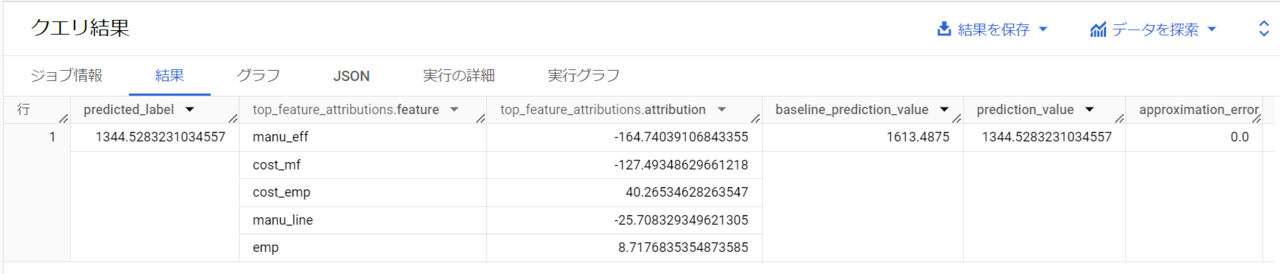
- predicted_label:モデルが算出した予測値
- top_feature_attributions.feature:特徴名(影響度で降順)
- top_feature_attributions.attribution:各特徴の影響度
- baseline_prediction_value:モデルの予測におけるベースライン
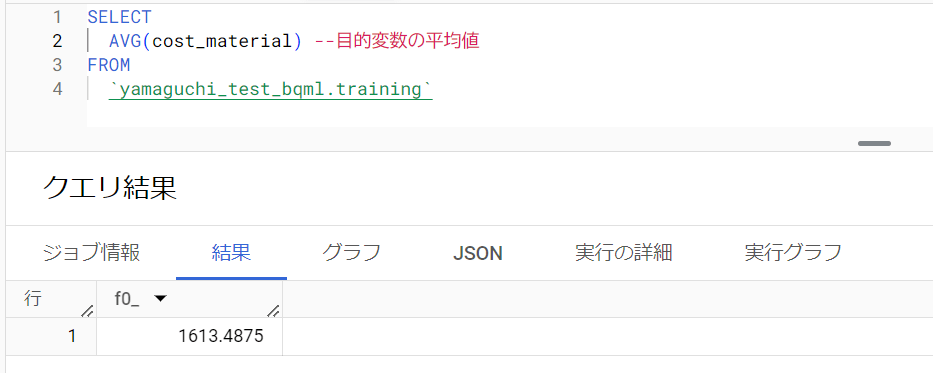
baseline_prediction_valueについてちょっと寄り道します。
モデルを作成する際、最初にある程度の”アタリ”をつけたうえで、そこから微調整をかけていくのですが、baseline_prediction_valueは「最初につけたアタリ」を指します。
調べた結果、
が採用されていました。
このベースラインの値を基準として、モデルが各特徴の影響度を加味して予測値を算出してくれます。下記のイメージです。
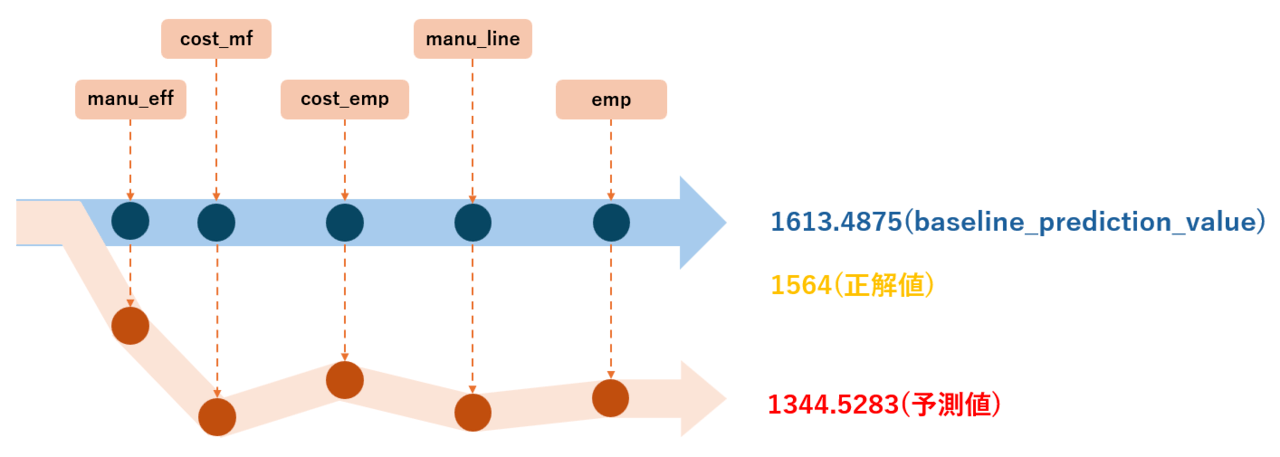
最初にアタリをつけたベースライン(青矢印)に対して、各特徴の影響を与えていきます。するとベースラインの値の青丸が調整され、赤丸になっていきます。
こうしてベースラインの青矢印が各特徴に影響され、赤矢印のような動きをして予測値を算出してくれます。
今回はベースラインの方が正解値に近い残念な結果になっています。。。
ただ、各特徴がどの程度影響を与えた結果、予測値がどう外れているかをある程度掴むことができました。この情報をモデルの性能改善へと活用することが可能です。
モデルの性能改善については今後ブログ化していきます。
まとめ
今回は、以前作成した線形回帰モデルの予測結果をExplainable AI(XAI)を使って説明させてみました。
どの特徴が予測結果にどの程度影響を与えているかが数値的につかめるので、かなり便利だと思いました。