

こんにちは。SCSKの山口です。
今回はBigQuery MLを使って機械学習モデルの作成、テストをやってみます。
・とにかくBigQuery MLを触ってみたい
・BigQuery MLでモデルを作成してみたい
・BigQuery MLでモデルを使って推論してみたい
・Google Cloud歴:約2年
・BigQueryのコンソール操作には慣れている
・SQLが少し書ける
・AI/MLの知識はあまりない
より詳細な概念、知識に関しては後続のブログをお待ちください。
BigQuery ML

BigQuery MLを使用する最大のメリットは、
- Google Cloudコンソール
- bqコマンドラインツール
- BigQuery REST API
- BigQueryに統合されたColab Enterpriseノートブック
- Jupyter ノートブックやビジネス インテリジェンス プラットフォームなどの外部ツール
今回は、Google Cloudコンソール(BigQuery画面)でBigQuery MLを触ってみます。
また、BigQuery MLでは下記のモデルが内部でトレーニング済みで、BigQuery MLに組み込まれています。
- 線形回帰
- ロジスティック回帰
- K平均法クラスタリング
- 行列分解
- 主成分分析(PCA)
- 時系列
上記以外にも様々なモデルが使用可能です。詳細はこちらの公式ドキュメントをご参照ください。
今回は、線形回帰のモデルを使用して予測を行います。
BigQuery ML使ってみた
では、さっそく触ってみます。
事前準備
今回は、モデルのトレーニング用とテスト用で二つのテーブルを用意しました。(※同一データは含んでいない)
| スキーマ情報(2テーブル共通) |
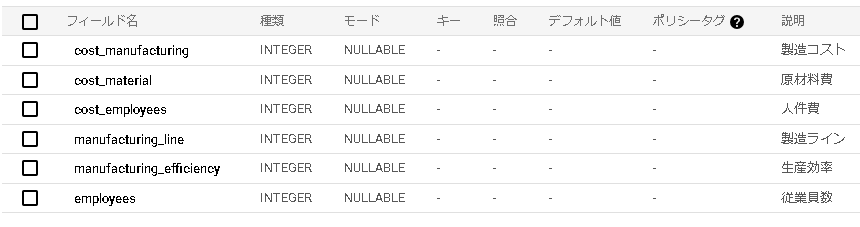 |
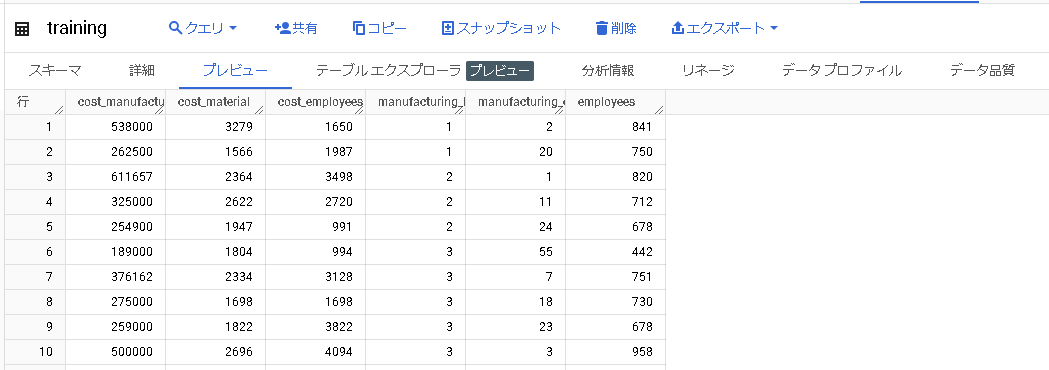
| training:80行 |
 |
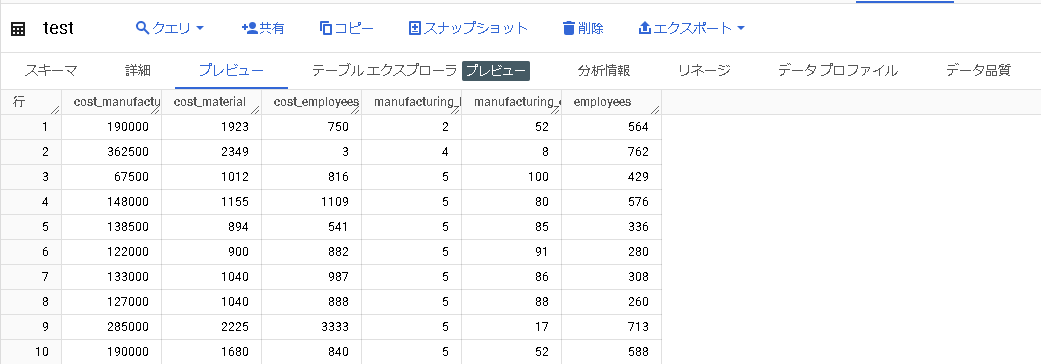
| test:20行 |
 |
モデルを作成し推論するにあたって、下記を決めておきます。
- 目的変数:予測したいデータ
- 説明変数:予測するために使用するデータ
今回は目的変数を「cost_material:原材料費」とし、説明変数をその他のカラムとします。
モデル作成・トレーニング
下記SQLを実行して、モデルを作成します。
CREATE OR REPLACE MODEL `yamaguchi_test_bqml.test_model_liner_reg` OPTIONS(model_type='linear_reg') AS SELECT IFNULL(cost_manufacturing, 0) AS cost_mf, IFNULL(cost_material, 0) AS label, --目的変数 IFNULL(cost_employees, 0) AS cost_emp, IFNULL(manufacturing_line, 0) AS manu_line, IFNULL(manufacturing_efficiency, 0) AS manu_eff, IFNULL(employees, 0) AS emp FROM `yamaguchi_test_bqml.training` ;
CREATE MODEL文で簡単にモデルを作成することが可能です。OPTIONS句内で今回使用する線形回帰(linear_reg)を指定しています。
その後のSELECT文によって指定されたデータを使用してモデルをtrainingします。
また、「cost_material」に対して、「label」というエイリアスを作成することで、cost_materialが目的変数であることを示しています。CREATE句でinput_label_cols=オプションを使用して目的変数を設定することも可能です。
最後のFROM句でトレーニング用のテーブル「training」を指定しています。
モデル作成が完了すると、エクスプローラ画面の「モデル」配下に作成したモデルが表示されます。
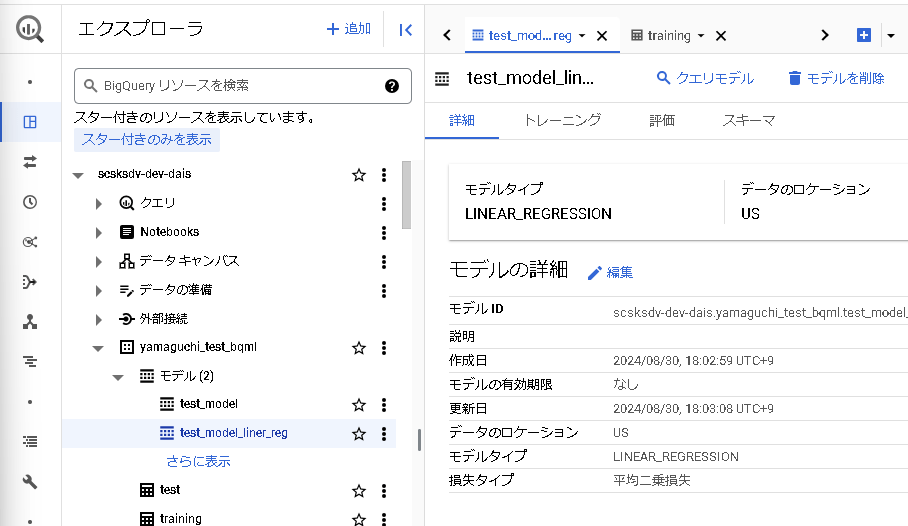
以上でモデルの作成・トレーニングは完了です。
モデルテスト
作成したモデルを使って予測をしてみます。
下記SQLを実行します。
SELECT predicted_label AS predicted_costs FROM ML.PREDICT(MODEL `yamaguchi_test_bqml.test_model_liner_reg`, ( SELECT IFNULL(cost_manufacturing, 0) AS cost_mf, IFNULL(cost_employees, 0) AS cost_emp, IFNULL(manufacturing_line, 0) AS manu_line, IFNULL(manufacturing_efficiency, 0) AS manu_eff, IFNULL(employees, 0) AS emp FROM `yamaguchi_test_bqml.test` WHERE employees=476 ))
ML.PREDICT関数を使って予測を行います。モデルの出力列名はpredicted_<label_column_name>としています。
SELECT句で指定しているpredicted_labelはlabelの推定値になります。
ネストされたSELECT句は、モデル作成のCREATE MODEL句と同じにしていますが、FROM句にはtestテーブルを指定しています。
trainingのデータでモデルを学習させ、testのデータを使って予測の挙動を見る。といった狙いです。今回は、「従業員数が476人の場合の原材料費」を予測しています。
予測結果を見てみましょう。

1344.5283 …という予測が得られました。testテーブルの実際のデータを比較してみると、
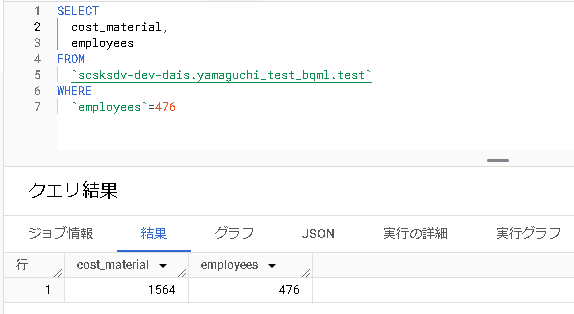
、、、、何とも言えない結果ですね。。
とはいえ、そこまでかけ離れている数値ではないです。
予測の精度が良くない原因として、そもそも学習に使用するデータ量が少ない点がまず考えられます。
それ以外にもモデルを学習させる際に、CREATE句のOPTION内で様々な設定をし、予測精度を上げることも可能です。ここについては後続のブログで書きたいと思います。
まとめ
今回は、BigQuery MLを使ってモデルを作成し、実際に予測をしてみました。
今回は公式ドキュメントに沿って実践を進めたのですが、「モデルの評価」については本ブログでは触れませんでした。(長くなりそうだったので。)
今回作成したモデルの評価結果を先出しておきます。
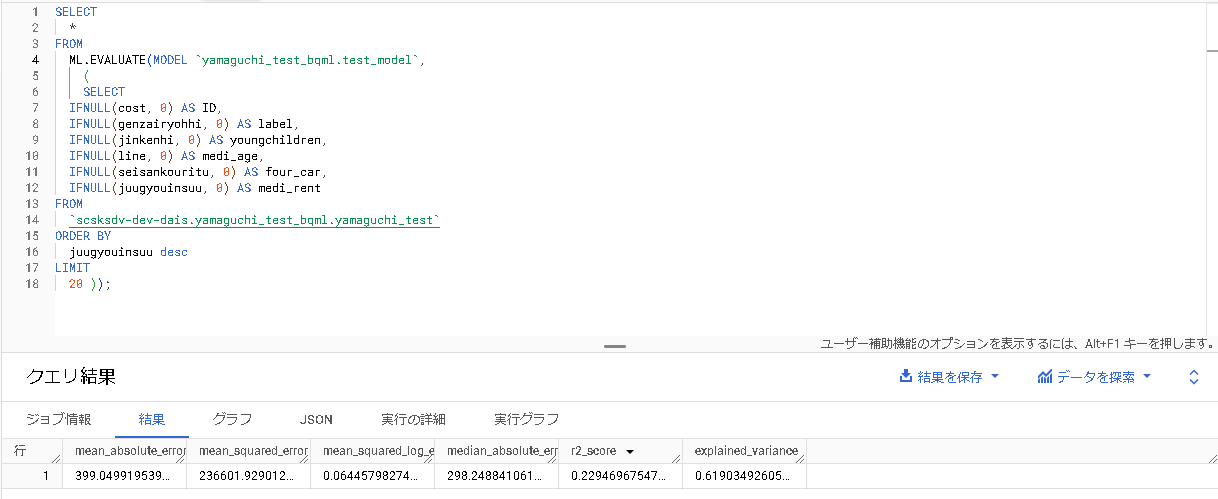
こんな感じです。初めて見る評価指標がズラリと並んでいたので、この辺りは別のブログで深堀していきます。