

こんにちは、SCSK浦野です。
Webアプリで取得しているログを分析に利用する際に、一部の値が他データと異なる表現となっており、データのコピーと合わせて変換をした際の手順を共有できればと思います。
やりたいこと
アプリのログはjson形式でS3に保存されており、以下のような形式となっているとします。
この、hogehoge に入る値のうち特定値だけ他のデータ群で登録されている値と違う為、保存先のS3にコピーする際に同じ値に置換したいというのが今回の目的です。
(例ではfooの値が hoge、piyo等の時はそのままに、fuga の時だけ bar に変換したい )
もちろん、その他の処理も合わせて行う事が出来ますが、今回は移動とその値の置換だけを対象とします。
{
"key1": "XXX",
"key2": "YYY",
"username": "Toyosu Taro",
・・・
"foo": "fuga",
・・・
}

赤枠で囲われた部分の処理です。
設定手順
- AWS Glue Studio を開き「Visual with a source and target」を選択して、「Create」を押します。
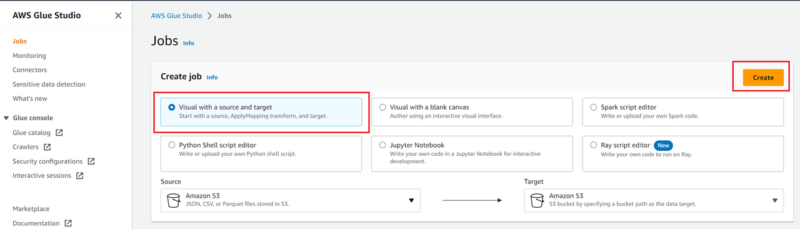
- 以下の画像のような視覚的にブロックが表示されますので、各ブロックに必要事項を入力します。
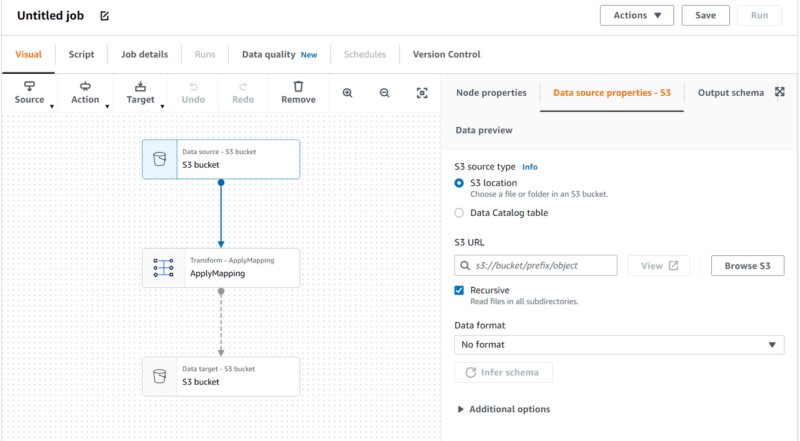
「S3 Bucket」にはソース、S3 URL、取得の際に再帰的にファイルを探すか、保存のフォーマットなどを設定
「Apply mapping」では読み込んだ情報の取捨選択や型の変換などを設定します。 - 手順2で自動作成されたScriptに追記・修正する形で値の変換を設定します。
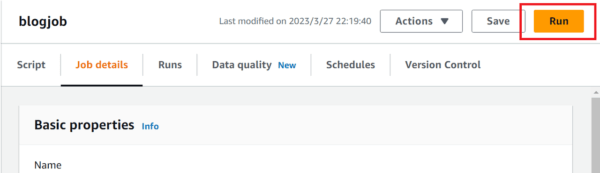
以下を「ApplyMapping」で生成されたブロックと、書き込み先の 「S3 bucket」で生成されたブロックの間に記述し、書き込み先の 「S3 bucket」内の引数を「replaceIf_node3」に変更します。#以下2行追加 from pyspark.sql.functions import col from pyspark.sql.functions import when #「ApplyMapping」で生成されたブロックと、書き込み先の 「S3 bucket」で生成されたブロックの間に記述 replaceIf_node3 = ApplyMapping_node2.withColumn('hogehoge', when(col('hogehoge') == 'fuga', 'bar').otherwise(col('hogehoge'))) - Job detail のタブの中で実行環境を設定し、画面右上の「Run」を押しジョブを実行し、実行結果を確認します。
例のjsonであれば、以下のように変換されます。{ "key1": "XXX", "key2": "YYY", "username": "Toyosu Taro", ・・・ "foo": "bar", ・・・ } - 必要に応じて、「Schedules」タブ内で実行スケジュールを登録します。
以上になります。
変換(と移動)だけの利用ということは少ないかもしれませんが、何方かのGlueを利用する際の参考になれば幸いです。