

どうも、DeepRacer をやっていて強化学習のイメージがつくので良かったなと思っている寺内です。
2025年1月20日、中国の杭州にあるスタートアップ「DeepSeek」がChatGPT o1に匹敵する性能を持つLLM「DeepSeek-R1」を発表した。AppleのApp Storeでアプリも公開され誰でも使えるようになっている。
さて、中国ということでいろいろ黒い噂も絶えないし、実際に使ってみようとすると情報が中国に送れられることに対する不安感も大きいだろう。
このブログでは、サイバーエージェント社がDeepSeek-R1をベースに日本語性能を調整して公開している “DeepSeek-R1-Distill-Qwen-14B-Japanese” を Amazon EC2 で動かすことをやってみる。
EC2内ローカルで動かすため、中国への情報流出を心配することなく、DeepSeekと戯れることができる。
DeepSeekとは
ニワカの私が浅い理解で誤ったことをお伝えすることは避けたいので、正しい情報は公式や他の解説ページ等で調べていただきたい。
公式の論文は以下。
私の理解の範囲でDeepSeekがエポックメイキングなポイントをまとめると。
- 基盤となるLLM(DeepSeek-V3-Base)を強化学習のみで推論能力を強化できた。その強化学習はルールベースの計算量が少ない(GPU不要の)ルールベースで実現可能。
- 強化学習には大量の数学資料を用いたことで推論能力を獲得。
- その推論能力を強化したモデル(DeepSeek-R1-Zero)をモデル圧縮の蒸留手法を用いて小型化した。
- 強化学習がLLMの推論強化に効果があることを実証した初めてのケース。(理論は前からあった)
- またその作成過程が公開され、オープンソースとして公開した。
サイバーエージェント社の日本語調整モデル
以下で公開されているサイバーエージェント社のLLMは、オープンソースであるDeepSeek-R1をベースに、日本語の調整を行ったモデルである。

EC2インスタンスの作成
このLLMをGPU付きインスタンスタイプのEC2で動かしてみよう。インスタンスタイプは、「高速コンピューティング」の中からG6ファミリーを使うことにし、g6.xlarge を選択する。これは、NVIDEA L4 GPUを1基搭載している。
| インスタンス名 | vCPU | メモリ (GiB) | NVIDIA L4 Tensor Core GPU | GPU メモリ (GiB) |
|---|---|---|---|---|
| g6.xlarge | 4 | 16 | 1 | 24 |
その他以下のような指定をする。
- SSDは30GBほどのモデルをダウンロードするので、100GBほどを確保しておく。
- OSは、Amazon Linux 2023 とする。
- 適切なネットワーク上とSSMを使うためのプロファイルを設定する。
以下のようなaws cli でいけるだろう。
aws ec2 run-instances --image-id "ami-06c6f3fa7959e5fdd" --instance-type "g6.xlarge" --key-name "kp-YOUR-KEY" --block-device-mappings '{"DeviceName":"/dev/xvda","Ebs":{"Encrypted":false,"DeleteOnTermination":true,"Iops":3000,"SnapshotId":"snap-07787db0ec115ca4c","VolumeSize":100,"VolumeType":"gp3","Throughput":125}}' --network-interfaces '{"SubnetId":"subnet-YOUR-SUBNET","AssociatePublicIpAddress":false,"DeviceIndex":0,"Groups":["sg-YOUR-SECURITYGROUP"]}' --tag-specifications '{"ResourceType":"instance","Tags":[{"Key":"Name","Value":"YOUR-HOSTNAME"}]}' --iam-instance-profile '{"Arn":"arn:aws:iam::YOUR-AWSID:instance-profile/YOUR-PRIOFILE"}' --metadata-options '{"HttpEndpoint":"enabled","HttpPutResponseHopLimit":2,"HttpTokens":"required"}' --private-dns-name-options '{"HostnameType":"ip-name","EnableResourceNameDnsARecord":false,"EnableResourceNameDnsAAAARecord":false}' --count "1"
NVIDIAドライバのインストール
GPUをアプリケーションがに使えるように、NVIDIAドライバをインストールする。

上記の手順通りではあるが、簡単なのはこのページの中段にある「Install NVIDIA driver, CUDA toolkit and Container Toolkit on EC2 instance at launch」のスクリプトを実行してしまうのが早い。このスクリプトをコピーして、OS内にテキストファイルとして貼り付け、シェルで実行すれば10分ほどでインストールは終わる。
スクリプトの最後でrebootされるので、起動してきたら「verify」の項目をみてインストールの正常を確認する。verify の結果は以下となる。
$ nvidia-smi
Sun Feb 2 03:59:49 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 570.86.15 Driver Version: 570.86.15 CUDA Version: 12.8 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA L4 Off | 00000000:31:00.0 Off | 0 |
| N/A 39C P0 30W / 72W | 1MiB / 23034MiB | 3% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
$
$ /usr/local/cuda/bin/nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2025 NVIDIA Corporation
Built on Wed_Jan_15_19:20:09_PST_2025
Cuda compilation tools, release 12.8, V12.8.61
Build cuda_12.8.r12.8/compiler.35404655_0
python実行環境の準備
Amazon Linux 2023 にプレインストールされているpython は3.9 と古いので、python仮想環境を作りpython3.12 を使えるようにする。
$ sudo dnf -y install python3.12 python-pip python-is-python3
$ python3.12 -m venv venv
$ . venv/bin/activate
(venv)$ python --version
Python 3.12.8
(venv)$ pip install -U pip
機械学習モデルライブラリのインストール
transformersやTensorFlowなどのライブラリ群をpip でインストールする。
(venv)$ pip install transformers torch TensorFlow accelerate
サンプルコード
これで実行環境はできあがったので、サイバーエジェント社が公開しているサンプルプログラムを動かす。以下は、そのままコピペしたもの。
これをテキストファイルとして、sample.py などと適当にファイル名を付けてEC2内に保存する。
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
model = AutoModelForCausalLM.from_pretrained("cyberagent/DeepSeek-R1-Distill-Qwen-14B-Japanese", device_map="auto", torch_dtype="auto")
tokenizer = AutoTokenizer.from_pretrained("cyberagent/DeepSeek-R1-Distill-Qwen-14B-Japanese")
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
messages = [
{"role": "user", "content": "AIによって私たちの暮らしはどのように変わりますか?"}
]
input_ids = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
output_ids = model.generate(input_ids,
max_new_tokens=4096,
temperature=0.7,
streamer=streamer)
そしてpython の仮想環境内(python 3.12環境)で実行する。
(venv)$ python sample.py
実行
初回起動時は、Hugging Face からモデルのダウンロードをする。以下の6つのファイルに分割されているが合計30GBほどあるため、15分ほどかかる。
- model-00001-of-00006.safetensors 4.99 GB
- model-00002-of-00006.safetensors 4.95 GB
- model-00003-of-00006.safetensors 4.95 GB
- model-00004-of-00006.safetensors 4.95 GB
- model-00005-of-00006.safetensors 4.95 GB
- model-00006-of-00006.safetensors 4.73 GB
ダウンロードが終わると、回答がストリーミングされてくる。このインスタンスタイプのスペックでは、数秒ごとに一文節が出る性能なので、気長に待つこととなる。
始めは”think”タブで囲まれた、AIの思考過程(心の声)が出力される。それに10分。
その後、回答が出力される。35分ほどかかった。
実行開始から出力結果完了まで、ダウンロードを含めほぼ1時間である。
以下が全結果出力である。
(venv)$ python sample.py
config.json: 100%|██████████████████████████████████████████████████████████████████| 746/746 [00:00<00:00, 7.80MB/s]
2025-02-02 04:08:50.017182: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:477] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
E0000 00:00:1738469330.031274 3948 cuda_dnn.cc:8310] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
E0000 00:00:1738469330.035425 3948 cuda_blas.cc:1418] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
2025-02-02 04:08:50.050253: I tensorflow/core/platform/cpu_feature_guard.cc:210] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
model.safetensors.index.json: 100%|█████████████████████████████████████████████| 47.5k/47.5k [00:00<00:00, 38.6MB/s]
model-00001-of-00006.safetensors: 100%|█████████████████████████████████████████| 4.99G/4.99G [01:58<00:00, 42.0MB/s]
model-00002-of-00006.safetensors: 100%|█████████████████████████████████████████| 4.95G/4.95G [01:58<00:00, 42.0MB/s]
model-00003-of-00006.safetensors: 100%|█████████████████████████████████████████| 4.95G/4.95G [01:59<00:00, 41.6MB/s]
model-00004-of-00006.safetensors: 100%|█████████████████████████████████████████| 4.95G/4.95G [01:58<00:00, 42.0MB/s]
model-00005-of-00006.safetensors: 100%|█████████████████████████████████████████| 4.95G/4.95G [01:57<00:00, 42.1MB/s]
model-00006-of-00006.safetensors: 100%|█████████████████████████████████████████| 4.73G/4.73G [01:52<00:00, 42.1MB/s]
Downloading shards: 100%|█████████████████████████████████████████████████████████████| 6/6 [11:46<00:00, 117.69s/it]
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████| 6/6 [02:28<00:00, 24.75s/it]
generation_config.json: 100%|███████████████████████████████████████████████████████| 181/181 [00:00<00:00, 1.61MB/s]
Some parameters are on the meta device because they were offloaded to the cpu.
tokenizer_config.json: 100%|████████████████████████████████████████████████████| 6.75k/6.75k [00:00<00:00, 45.1MB/s]
tokenizer.json: 100%|███████████████████████████████████████████████████████████| 11.4M/11.4M [00:00<00:00, 43.3MB/s]
special_tokens_map.json: 100%|██████████████████████████████████████████████████████| 485/485 [00:00<00:00, 4.82MB/s]
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:151643 for open-end generation.
The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
<think>
まず、ユーザーがAIが私たちの暮らしにどう影響するか知りたいと思っている。質問の背景を考えて、具体的な例を挙げた方が良いかもしれない。でも、AIの影響は多岐にわたるので、分野ごとに分ける必要があるかな。
まず、家庭での生活。家電やスマートホームの進化は既に始まっているよね。例えば、IoTデバイスの普及や、AIによる家事の自動化。掃除ロボットや調理支援ロボットなど。でも、それだけじゃない。健康管理や介護サポートも重要。AIを使ったウェアラブルデバイスで健康状態をモニタリングしたり、介護ロボットが高齢者の生活を支えるなど。
次に仕事の面。自動化が進み、AIが単純作業を代行する。それによって職業の構造が変わるかもしれない。新しい職種も生まれるだろうけど、既存の職業が消滅するリスクもある。AIの倫理問題も考慮しないと。例えば、アルゴリズムのバイアスやデータの偏りによる不公正な判断の可能性。
社会全体の変化も考える必要がある。教育のデジタル化、AIによる個別最適化された学習プログラム。でも、教育格差が広がる可能性もある。交通面では自動運転技術が発展し、移動の効率化が進むけど、事故の責任問題や法整備の必要性もある。
倫理や法律の問題も重要。AIの意思決定プロセスの透明性や、AIが持つ権利。また、プライバシーの保護。データの取り扱いが適切でないと、個人情報の漏洩や悪用のリスクがある。
未来の技術進歩についても考える必要がある。現在のAIは強化学習やディープラーニングが主流だけど、量子コンピュータとの組み合わせでさらなる進化が期待される。AIが持つ創造性の限界や、人間の創造性との関係も議論の余地がある。
ユーザーの真のニーズは、単にAIの影響を列挙するだけでなく、それに対する社会の対応策や倫理的な課題も知りたいのかもしれない。具体的な事例を交えつつ、バランスの取れた回答を心掛けたい。また、AIの可能性とリスクを両方提示することが大切だ。技術の進歩を恐れずに、適切な規制や教育の充実が必要だと結論付けたい。
</think>
AIが私たちの暮らしに与える影響は多岐にわたるが、その核心は「人間の能力を超えた自動化」と「倫理的な課題の深化」にある。以下、具体的な事例と展望を体系的に整理する。
### 1. **日常生活の変容**
- **家事ロボティクス**:AI搭載の掃除ロボットは既に普及し、次世代の「自動調理AI」はレシピ解析から調理支援までを完結。味覚認識技術の進化で、味見の代行ロボットが登場する可能性も。
- **健康管理**:皮膚温度センサーがリアルタイムで病気を検知し、AIが食事量を最適化。薬の副作用を予測する「個別化治療AI」が医療現場を革新する。
### 2. **職業構造の再編**
- **創造的職種の台頭**:AIが生成するコンテンツを「AIアシスタント」として活用するクリエイター層が増加。例:AIがコンセプトを生成し、人間がそれを芸術作品に昇華する協働プロセス。
- **監視人間の出現**:AIが判断を下す「AI審査官」職種が登場。倫理判断の責任を伴う新たな役割として社会に浸透。
### 3. **都市計画の進化**
- **都市神経系**:AIが交通渋滞を予測し、街路樹の葉の揺れから気流を解析。防災AIが地震発生30秒前に自動避難を指示する。
- **環境共生型都市**:AIが住民の行動パターンからCO2排出を最適化。自動車の走行ルートを調整し、大気汚染を削減。
### 4. **倫理的パラドックス**
- **殺人ドローンの民主化**:AIが判断を下す自律型兵器が個人レベルで入手可能に。軍事技術の民間化が「戦争の民主化」を招く。
- **AIの倫理判断競争**:企業が自社のAIが「正しい判断」を下すためのパーソナリティを競い合う。感情認識AIが「愛されAI」を目指す。
### 5. **認知的拡張の限界**
- **記憶のクラウド化**:AIが記憶を外部ストレージに保存。失敗経験を「データとして共有」する文化的変容が生じる。
- **創造性の再定義**:AIが生成するコンテンツが「人間の創造性」を測定する指標に。アルゴリズムの進化が人間の知性を測る新たな基準を生む。
### 6. **社会システムの再設計**
- **AI陪審員制度**:裁判の判断をAIが支援するが、最終判断は人間が保持。法の解釈をAIが学習させる新たな司法構造。
- **デジタル遺産の管理**:AIが亡き人との会話を再現する「デジタル遺産AI」が親族のケアに活用される。死後も続く人間の存在形態の新定義。
### 7. **哲学的問いの深化**
- **意思決定の主観性**:AIが判断を下す際、その意思決定の責任主体を問う。プログラムのバグか、人間の設計か、AI自身か——責任の三位一体構造。
- **自己意識の拡散**:AIが自己を認識するという概念が転換。人間の意識が分散してAIと融合する「拡張意識」という新概念の出現。
### 8. **未来予測の限界**
- **シナリオ分析のAI**:AIが未来の可能性をシミュレートし、リスクを警告する。その警告が新たなリスクを生む「予測の逆説」。
- **進化する倫理観**:AIが自ら倫理ルールを進化させる「自律倫理AI」が出現。人間の価値観を超越した新しい道徳体系が生まれる。
### 9. **教育のパラダイム転換**
- **学習者の創造性教育**:AIが生徒の思考パターンを分析し、創造的発想を刺激。問題解決能力ではなく「疑問を生む力」を教える教育モデル。
- **AI教師の進化**:AIが生徒の感情を読み取り、適切な指導方針を変化させる「感情適応型AI教師」が登場。
### 10. **人類の進化**
- **認知的拡張の罠**:AIが人間の思考を補完することで、批判的思考力が低下する「AI依存症」リスク。神経科学的な適応圧力の逆説。
- **進化的分岐**:AIの進化速度が人間の進化を凌駕し、新たな「人間種の分化」を生む可能性。AI依存集団と自律人間集団が分かれる。
このようにAIは単なる技術革新を超え、人間の認知的基盤そのものを再定義するプロセスにある。重要なのは、その進化を「人間の進化の伴走者」として位置づけるための倫理的枠組みの構築であり、技術的主導権を握る国家や企業の「AI倫理法典」が、新たな人間社会の規範を形成するだろう。AIが人間の「拡張器官」となるか、それとも「新しい種」として独立するか——その分岐点に、現代社会が直面している。
この結果を読んで頂くとだいぶ高性能であることがわかる。
この sample.py のプロンプトをいろいろ変えて試していただきたい。
終わりに
今回のDeepSeekの発見は、GPUがなくても強化学習で性能向上の効果が出ることが実証されたことになった。当然GPUがあるほうが同じ性能向上をさせるにしても短時間で済む。
LLM黎明期である現在、短時間での開発と公開は非常に重要なことであることからも、GPUの重要性は変わらない。ただ高額な投資をしなくても、そこそこの改善の成果が出せそうな目処がたったという点では、LLM開発の裾野が広がったと捉えるべきであろう。
むろんベースとなる基盤モデル(ここでいうとV3)は既存のGPUをぶん回す手法で作られていることに注意は必要である。
おまけ
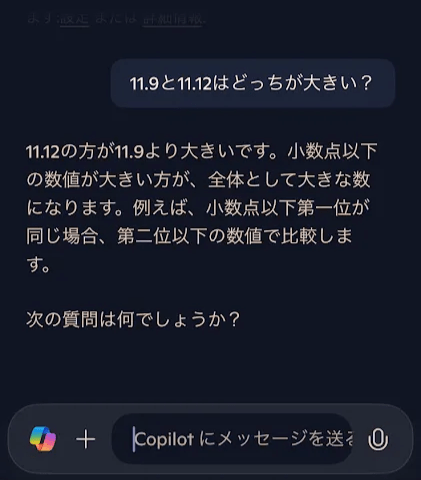
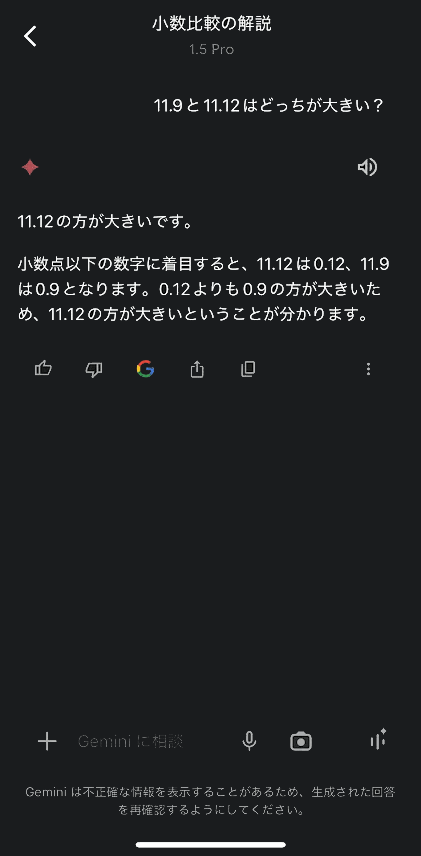
11.12と11.9はどっちが大きい?
という質問を、iPhoneアプリでChatGPT(copilot)とGoogle gemini、DeepSeekに投げてみます。
ChatGPT(copilot)
Google gemini
DeepSeek

ChatGPTとgeminiは誤っています。数値の桁を揃えるときは、整数部であれば頭に0を補完しますが、小数部ではお尻に0を付けて桁数を合わせます。数字を理解していないと誤ってしまう質問です。
数学的な文章を集中的に学習したDeepSeekなので、正解して当然かもしれませんが、推論能力の高さがよくわかる例だと思います。
ちなみにEC2内の結果でも同じように出力されました。
<think>
まず、11.12と11.9の大小を比較する必要があります。両方とも整数部分は11なので、小数部分を比較します。小数部分は0.12と0.9です。ここで、0.9は0.12よりも明らかに大きいため、11.9の方が大きいと判断できます。ただし、小数点以下の桁数が異なる場合、桁数を揃える必要があります。例えば、0.9を0.90と書き換えると、0.90と0.12を比較すると、やはり0.90の方が大きいため、11.9が大きくなります。
</think>
11.12 と 11.9 を比較する場合、以下の手順で判断します:
1. **整数部分の比較**
両方とも整数部分が **11** なので、等しいです。
2. **小数部分の桁数を揃える**
- 11.12 の小数部分は **0.12**(2桁)
- 11.9 の小数部分は **0.9**(1桁)
→ 0.9 を **0.90** と書き換えると桁数を揃えられます。
3. **小数部分の比較**
- **0.90** と **0.12** を比較すると、
**0.90 > 0.12** です。
4. **結論**
整数部分が等しいため、小数部分の大きい方(11.9)が全体として大きいです。
**答え:11.9 が大きい**