 AWS
AWS AWS Step Functions Map ステート分散モードで任意の Amazon S3 バケットのフォルダーにあるオブジェクトを並列処理する
掲題のリソースを実装したときに気付いた注意点を紹介します。
 AWS
AWS  AWS
AWS  AWS
AWS  AWS
AWS 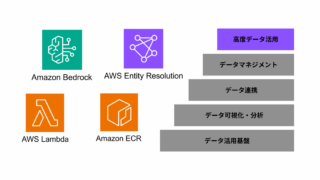 AWS
AWS  AWS
AWS 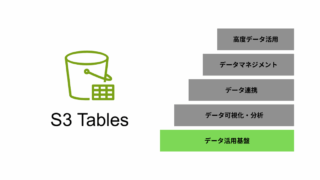 AWS
AWS  データ分析・活用基盤 データ分析・活用基盤
データ分析・活用基盤 データ分析・活用基盤  AWS
AWS