
SCSKの畑です。
今回は、前回の投稿でも触れていた通り、アプリケーションにおける更新差分データの表示を効率化・高速化するための一連の取り組みや試行錯誤の過程について説明していきます。
はじめに
アプリケーションにおける更新差分データの表示の導出・表示機能について、概要を簡単に説明します。
本アプリケーションにおける管理対象のテーブルについて、データの更新差分を表示できるようにしています。ケースとしては以下2パターンがありますが、どちらも同じ仕組みで更新差分を導出・表示しています。
- 異なるデータバージョン(例えば最新データとその一世代前のデータ)間での更新差分導出・表示
- 編集中のデータと最新のデータ(=編集前のデータ)間での更新差分導出・表示
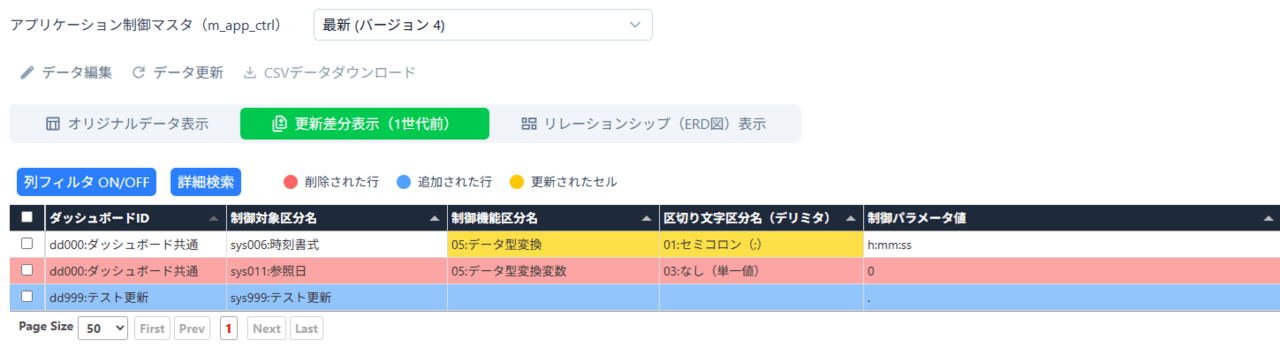
画面としては、以下のように更新差分の種類(追加/削除/変更)ごとに行ないしはセルの色を変更することで、更新差分の内容が視覚的に分かりやすくなるよう工夫しています。(スクショの都合上、更新差分行に絞って表示しています)
また、この更新差分導出処理を非同期処理に変更した話を今年度初回のエントリにて触れていたかと思いますが、導出自体は昨年度投稿した以下エントリの内容に概ね従って実装しており、

導出した差分情報は同じく昨年度投稿した以下エントリに記載の Amplify スキーマ定義に従ってアプリケーション上で扱っていました。

この更新差分情報の画面表示のレスポンスが、特にデータ量の大きいテーブルで著しく悪化するケース(場合によっては数分程度)が散見されるようになり実用上支障をきたすことから、改善に向けた取り組みが必要となりました。
今回の取り組みに至った原因とその背景
前回のエントリで半ば予告していましたが「本アプリケーションで扱うテーブルデータの長大化、及びテーブルデータ更新パスの多様化に伴い更新差分データ量が増大したことで、更新差分情報の画面表示に時間を要するケースが増えた」ことが主な原因です。
前者の要因については初回のエントリにて説明した通りですが、後者の要因については、本プロジェクトにおける ETL/ELT 処理改善の取り組みの結果として、本アプリケーションで扱うテーブルの一部に対してバッチ更新が入るようになったことが背景にあります。
例えば、機種別の売上データの集計を行う ELT 処理において、機種マスタに登録されていない新しい機種に紐付くような売上データが存在した場合はそのデータの集計を保留した上で、ユーザにより問題ない(=機種マスタに追加すべき)と判断されたデータについては機種マスタに自動追加(バッチ更新)するようなロジックを追加しています。このようなロジックを一連の ETL/ELT 処理において複数の観点から導入することで、特にマスタ関連テーブルの手動メンテナンスの負担を軽減するというのが狙いでしたが、一方で複数のテーブルがバッチ更新の対象となった結果、今回のようなケースが増えてしまったということになります。
実装上の問題点
ということで前置きが長くなりましたが、具体的な実装の話に入っていきます。
まず、更新差分情報は以下のようなフォーマット(型定義)で扱っていました。DataDiffInfo 配下の AddedRowsInfo に追加された行、DeletedRowsInfo に削除された行、UpdatedRowsInfo に更新された行の情報がそれぞれネストして格納されます。更新された行については更新された列を特定するために、列名の情報も合わせて持たせています。
type DataDiffInfo {
diff_summary: RSS3DiffStatus!
added_rows_info: [AddedRowsInfo]!
deleted_rows_info: [DeletedRowsInfo]!
updated_rows_info: [UpdatedRowsInfo]!
}
type RSS3DiffStatus{
column: Boolean
constraint: Boolean
data: Boolean
}
type PKInfo {
name: String!
value: String!
}
type AddedRowsInfo {
pk: [PKInfo!]!
row_data: String!
}
type DeletedRowsInfo {
pk: [PKInfo!]!
row_data: String!
}
type UpdatedRowsInfo {
pk: [PKInfo!]!
cols: [String!]!
row_data: String!
}
さて、この更新差分情報を画面に表示・反映するためには、当たり前の話ですがアプリケーション画面から参照しているテーブルデータのどの行/列が更新差分に該当しているかを導出する必要があります。そこで昨年度の実装時点では、上記定義の通り更新差分情報に PK の値を含めた上で、PK の値が一致するかどうかで導出していました。本アプリケーションで扱う全てのテーブルに PK が定義されており、PK の値が一致する行は当然ながら一意となるため、更新差分情報を表示・反映すべき行を導出することが可能となります。
と、ここまでは特段違和感のある内容ではないと思うのですが、結論から言うとこの「PK の値が一致する行を導出(検索)する処理」が、更新差分情報の画面表示に時間を要する最も大きな原因となってしまっていました。
普通に考えると、もちろんデータ量に依存する前提とはいえ、表データ(オブジェクト(連想配列)の配列)の検索にそこまで時間を要するか?と疑問に思うところなのですが・・この検索を tabulator という、テーブルデータを画面上で表形式で扱うためのライブラリ経由で実施する必要があった、という点がミソでした。ある意味当たり前の話ですが、tabulator を使用してテーブルデータを画面に表示している以上は、tabulator 上でどの行が更新差分情報に該当するかを導出(検索)する必要があるためです。
なお、tabulator については昨年度概要について紹介していますので、ご興味のある方はこちらのエントリもご覧頂ければと思います。

tabulator 自体は多機能なライブラリであるため値の検索機能も充実しており、当初はこの機能を使用して PK を検索する実装としていました。ただ多機能とはいえさすがに RDBMS のように O(1) のオーダーで PK を検索できる訳ではなく、アルゴリズムなどを工夫する余地もありませんでした。そして何よりも、画面から検索機能が大量に連続実行されるようなことはライブラリ側では(おそらく)想定されておらず、ライブラリの処理によるオーバーヘッドも増大した結果・・先述の通りテーブルデータや更新差分の行数が数万行単位になってくるとパフォーマンスが大幅に悪化してしまいました。
また、tabulator 経由でテーブルデータを検索する処理としている以上、tabulator による表データの構築・画面レンダリングが完了したイベントを以ってこの処理を実行せざるを得ないという点も扱いづらい点でした。(以下 URL の tableBuilt というイベントが該当します)
例えば、検索アルゴリズムに工夫の余地がないなら、更新差分情報取得直後に他の重い処理と並列実行することで処理時間を稼ぐようなチューニングの方向性もあり得ると思うのですが、事実上ほとんどの処理が完了したタイミングからでないと tabulator 経由での検索ができなかったため、そのようなアプローチも取れませんでした。
以上の理由により、これまでの実装を大幅に見直す必要がありました。
参考までに当時のコードの一部抜粋も載せておきます。tableBuilt イベントをフックして呼び出される処理となっており、tabulator の検索機能を使用して更新差分情報に該当する行/列を検索の上、フォーマットを変更しています。こう見るとコードの流れ自体はシンプルですが、一部抜粋と記載した通り実際にはもう少しややこしいデータ変換処理などが入っていたため、ここまで見やすくはなかったです。。
tabulator.value.on("tableBuilt", function(){
// 差分行記録用配列の初期化
diffROWIDs = {}
// PKの条件に合致する行を探して削除された行を赤色に変更
for (const row of diffinfo.deleted_rows_info) {
let searchConditions = []
for (const pk of row.pk) {
searchConditions.push({field: pk.name, type: "=", value: pk.value})
}
let target_row = tabulator.value.searchRows(searchConditions);
diffROWIDs[target_row[0].getIndex()] = {type:'DELETED'}
}
// PKの条件に合致する行を探して追加された行を青色に変更
for (const row of diffinfo.added_rows_info) {
let searchConditions = []
for (const pk of row.pk) {
searchConditions.push({field: pk.name, type: "=", value: pk.value})
}
let target_row = tabulator.value.searchRows(searchConditions);
diffROWIDs[target_row[0].getIndex()] = {type:'ADDED'}
}
// PKの条件に合致する行を探して更新されたセルを黄色に変更
for (const row of diffinfo.updated_rows_info) {
let searchConditions = []
for (const pk of row.pk) {
searchConditions.push({field: pk.name, type: "=", value: pk.value})
}
let target_row = tabulator.value.searchRows(searchConditions);
diffROWIDs[target_row[0].getIndex()] = {type:'UPDATED', cells: row?.cols}
}
// 更新差分該当行を再レンダリングして、変更したフォーマットを反映
for (const row of tabulator.value.getRows()){
if (Object.keys(diffROWIDs).map(str => parseInt(str, 10)).includes(row.getIndex())){
row.reformat();
}
}
});
改修その1:改善したが完全解決には至らず
以上を踏まえて解決策の検討を始めました。まずは、アプリケーション側で更新差分に該当する行を導出(検索)する際の計算コストを抑えるのが目標となりました。
また実のところ、テーブルデータの編集画面において NOT NULL 制約の存在する列(≒入力必須の列)の色を変更するような、条件に応じて行/列の色を変更する処理自体は他にもあったのですが、いずれもパフォーマンスの問題が発生していませんでした。よって、更新差分情報の表示においてもそれらのロジックと同じような実装に改修できればよいのではないかと考えられたため、早期に方向性を定めることができました。
具体的には、tabulator によりテーブルデータの構成・レンダリングを実施する前に rowFormatter コールバックを使用して、特定の行/列のフォーマット(もちろん色も含みます)を変更するのかをあらかじめ定義しておくような流れとなります。以下 URL の実装例ではコールバック内で対象の行データを取得した上で、「col」という列の値が「blue」である行の色を #1e3b20 に変更しています。
rowFormatter という名前通りテーブルの全行に対してこのコールバックは適用されるため、上記と同じような処理における条件を PK の値が一致するかどうかに変更すれば、少なくとも現行の実装よりは計算コストを抑えることができるのではないかと考えて実装を変更しました。すると確かに改善は見られたものの、今回特に問題となっているようなデータサイズの大きなテーブルでは差分情報の画面表示が完了するまでに一定の時間を要してしまい、完全解決には至りませんでした。
当初実装より改善していることは間違いないものの、PK の一致チェックをするために結果的に全行の値を取得している以上、データサイズの影響を多少なりとも受けてしまうことは確かです。また、PK が複数の列による複合キーで定義されるテーブルが今回のタイミングで複数追加され、PK の一致チェック自体の計算コストも今後増大し得る傾向が見て取れたため、より抜本的な対策を取れないかどうかを引き続き検討することにしました。
改修その2:そして完全解決へ・・
さてそうなると、tabulator の仕様上 rowFormatter コールバックを使用する必要があるため改修の方向性自体は大きく変わらないものの、より計算コストを抑えるためには、実質的に行データを取得することなく更新差分に該当する行を導出するようなアプローチを考える必要がありました。言い換えると、PK 以外で更新差分に該当する行を導出できるように更新差分情報のフォーマットを変更する必要があるということになります。
これが難題で、正直しばらくは八方塞がりというか、ひとまず改善できたし一旦妥協しない?と何回も自問自答するくらいには悩み倒しました。。↑のセクションでは偉そうなこと書いてますが・・
というのも、テーブルデータにおいて特定の一意な行を検索するために使用するのって基本 PK なんですよね。もちろん UK (Unique Key) を別に定義することもできますし、その PK や UK を包含した複数行の値で検索することもできるので十分条件にはなりますが、わざわざそういった他の方法を取る意味がないよねというのは自明なところだと思います。(蛇足ですが、本アプリケーションで扱うテーブルに UK が定義されたものはありません)
つまり、更新差分情報のフォーマットを見直そうにも見直しようがないという理屈になってしまい、先述の通り悩み倒す羽目になったのですが・・どうにか改善できる箇所ないかなーと思いながらコードを見ていた時にふと気づきました。
あ、行番号(ROW_ID列)が使えるじゃん!!! と。
いきなりすっ飛ばして結論を言うとこれで解決したのですが、、順を追って説明します。
まず tabulator で表データを編集するにあたり、以下 URL の通り Row Index(以下行番号と呼称)としてどの列を指定するかを定める必要があります。全く同じ列の値を持つ行が複数行あったとしても、ライブラリとしてはそれらのデータを別物として扱う必要があるためですね。よって、その列の値は PK と同じように、行ごとに一意な値を持つ必要があります。つまり、PK などと同じように特定の一意な行を導出するための情報として使用できるということになります。
また、上記の通り tabulator において行を一意に特定する情報として扱われていることから、先述した rowFormatter コールバック内の処理においても getIndex() メソッドを使用することで行番号のみを取得できます。先述の通り rowFormatter コールバックはテーブル全行が対象となるため行数の影響は受けてしまいますが、それでも行データの取得処理や PK 一致チェック処理をスキップできる分計算コスト的にも有利となるということで、この方針でフロントエンド/バックエンドを改修していくことにしました。
以下、具体的な実装例を記載していきます。コード全量を記載するとさすがに長くなるため一部抜粋である旨ご容赦ください。
バックエンド (Amplify/AppSync)
まず、行番号を使用して更新差分に該当する行を導出できるよう、更新差分情報のフォーマットを変更しました。以下の通り、PK 列の代わりに行番号を使用するように定義を変更しています。PKInfo タイプが不要となった分、相対的にシンプルになっています。
type DataDiffInfo {
diff_summary: RSS3DiffStatus!
added_rows_info: [AddedRowsInfo]!
deleted_rows_info: [DeletedRowsInfo]!
updated_rows_info: [UpdatedRowsInfo]!
}
type RSS3DiffStatus{
column: Boolean
constraint: Boolean
data: Boolean
}
type AddedRowsInfo {
row_data: String!
index: Int!
}
type DeletedRowsInfo {
row_data: String!
index: Int
}
type UpdatedRowsInfo {
cols: [String!]!
row_data: String!
index: Int!
}
バックエンド (Lambda)
次にこのフォーマットに合わせてバックエンドの各処理(主に更新差分導出用の Lambda 関数)を改修していくことになりましたが、さすがに一筋縄ではいかず少々苦労しました。というのも、上記の通り行番号の情報はあくまで tabulator(フロントエンド)側で必要な情報であり、バックエンド側でその情報をどこまで考慮して処理するようにすれば良いかの見極めがやや難しかったためです。
本アプリケーションによる2つのテーブルデータの更新差分導出・表示機能は冒頭で述べた通り、以下2パターンが存在します。
- 異なるデータバージョン(例えば最新データとその一世代前のデータ)間での更新差分導出・表示
- 編集中のデータと最新のデータ(=編集前のデータ)間での更新差分導出・表示
この内、1.のパターンではいずれのデータも Redshift から UNLOAD で取得してきたデータであるため、そもそも対象となるデータに行番号が含まれていません。2.のパターンにおける編集中のデータにのみ行番号が含まれています。先述の通り Amplify/AppSync のスキーマ定義を行番号を返すように変更している以上、Redshift から UNLOAD で取得してきたデータにも行番号を付加する必要があるのでは?と当初懸念していたのですが・・よくよく考えると全くその必要はありませんでした。
まず 1.のパターンにおいては、表データを DataFrame として読み込む際に暗黙的に index を持つため、これをそのまま行番号として返してあげれば OK でした。index には特定の列を指定することもできますが、指定しない場合はデータの頭から 0 オリジンの連番が割り当てられます。そして、バックエンドからフロントエンドにテーブルデータを返す際も全く同じロジックで行番号を付与していたため、DataFrame の index 値をそのまま行番号として使用することができました。
次に 2. のパターンにおいては、編集中のデータに対して最新のデータとの更新差分を導出する以上、更新差分情報に含まれる行番号は編集中データのものを使用しないと画面上に更新差分情報が正しく表示されなくなってしまうため、そもそも最新データへの行番号付加は不要でした。最も、フロントエンドから S3 上に編集中のデータを差分導出用に一時保存する際に行番号も合わせて含めておかないと Lambda 関数から行番号を返せなくなるので、その部分の改修は必要でした。
また、2つのテーブルデータ間における差分情報を導出するにあたり行番号は言わずもがな不要な情報となるため、pandas による差分計算時はテーブルデータ(が格納されている DataFrame)からは編集中のデータの行番号を一時的に削除しておき、得られた差分情報に再度行番号を付加するというやや複雑な処理が必要になりました。
具体的には、まず以下のように編集中のデータが格納されている DataFrame (df_dst) のサブセットとしてPK列+ROW_ID列のみの Daraframe (df_dst_row_id_subset) を作成してから、差分計算のために df_dst から ROW_ID列(行番号)を削除しています。
# 編集中のデータと最新のデータ間比較の場合(編集中のROW_ID値を反映するため)
df_dst_row_id_subset = None
if diff_type == 'btwn_temp_and_latest':
# df_dstのサブセットを作成(PK列 + ROW_ID列)
subset_columns = pk_constraints + ['ROW_ID']
df_dst_row_id_subset = df_dst[subset_columns].copy()
# df_dstからROW_ID列を削除
df_dst = df_dst.drop(columns=['ROW_ID'])
その上で、以下のように得られた差分情報と PK の値が一致する行を上記で作成したサブセットから検索して、その行の ROW_ID を最終的な差分情報に含める形で出力する、というような流れで実装しています。
# index_valueの算出ロジック
if diff_type == 'btwn_temp_and_latest':
# PK列が一致する行のROW_IDを取得
pk_query_conditions = []
for pk_name, pk_value in zip(pk_constraints, pk_cols):
pk_query_conditions.append(f'{pk_name} == "{pk_value}"')
pk_query_str = ' & '.join(pk_query_conditions)
matched_row_id = df_dst_row_id_subset.query(pk_query_str)
index_value = int(matched_row_id['ROW_ID'].iloc[0])
フロントエンド (typescript)
ここまでできればフロントエンド側ではある意味どうとでもなるのですが、具体的には以下のような実装となりました。
diffROWIDs 変数が更新差分情報を格納している連想配列(キーが行番号)となっており、row.getIndex() メソッドで取得した対象行の行番号が同連想配列に含まれているかを判定し、含まれている場合は差分の内容(追加/削除/更新)に従って行またはセルの色を変更するような処理となっています。改修前のコードと比較すると処理自体が大きく変更されているのが分かるかと思います。
// rowFormatter設定(差分行の色付け)
const diffRowsFormatter = function(row){
const row_id = row.getIndex()
if (Object.keys(diffROWIDs).map(str => parseInt(str, 10)).includes(row_id)){
// 追加行の色付け
if (diffROWIDs[row_id].type === 'ADDED'){
row.getElement().style.backgroundColor = "#93c5fd";
}
// 削除行の色付け
else if (diffROWIDs[row_id].type === 'DELETED'){
row.getElement().style.backgroundColor = "#fca5a5";
}
// 更新行の色付け
else if (diffROWIDs[row_id].type === 'UPDATED'){
for (const cell of row.getCells()){
for (const diff_cell_name of diffROWIDs[row_id].cells){
if (cell.getColumn().getDefinition().field === diff_cell_name){
cell.getElement().style.backgroundColor = "#fde047";
}
}
}
}
// 例外処理
else {
addErrorInfo('未定義の差分定義情報です')
}
}
}
以上の一連の対応により、データサイズ/更新差分が数万行単位となる大きなテーブルにおいても、差分情報の画面表示は概ね1秒未満で完了するまでにパフォーマンスを改善できたため、完全解決と相成りました。
まとめ
改めて今振り返っても、元々の更新差分情報の型定義自体は特に問題のない仕様だったかと思います。先述の通り、一意な行を導出するために使用できるテーブルデータ内の情報はやはり PK になるからです。
ただ、それはあくまでテーブル内の情報を使用するという前提で考えた場合の話であり・・この情報をアプリケーション側でどう扱うのか、どのような型定義の方が性能面も含めてより扱いやすいか、というような観点が欠けていたことも事実であり、個人的にはとても良い勉強になりました。最も RDBMS で言うところの正規化の問題みたいなものだと考えると、(私の元々の専門が DB なだけに)もうちょっと最初から気を使えただろうという反省もあるのですが、、
本記事がどなたかの役に立てば幸いです。
補足すると、上記の例(機種マスタに対する新しい機種データの追加)であれば、ユーザが手動メンテナンスした場合でも更新(差分)量としては同一であるため、本質的にはバッチ更新そのものが問題となる訳ではありません。ただし、一連の処理フローにおいてこのように差分情報を導出できない or 導出するための計算コストが膨大になってしまうケースもあり、その場合は全テータの洗い替えによって対応する必要があります。すると結果的に更新差分の量もより大きくなってしまいます。
元々の本アプリケーションの設計思想としては、対象のテーブルを本アプリケーション経由で手動更新することを前提としていたため、必然的に更新差分の量もそれほど多くはならないだろうという見込みでしたが、バッチ更新が実装されたことでそのような更新パターンも発生し得ることになりました。