

こんにちは。SCSKの岡尾です。
今回は、AWS Glueを利用したETL処理を実装していた中でハマったポイントを紹介したいと思います。
私自身、ETLの実装は初めてでした。これからGlueを使ったETL処理実装していこうとしている方が同じようにつまずかないようにハマりポイントをご紹介できればと思います。
目次
- はじめに
- ハマりどころ
- ネットワーク:Glueセキュリティグループの「自己参照」
- トランザクション:Commit Failed Exception
- PySpark:メモリ不足エラー
- まとめ
1. はじめに
今回のプロジェクトでは、Amazon RDS上の業務データをS3 Tablesで構築したデータレイクへ同期するパイプラインを構築しました。
システム構成を簡略化した図が以下の通りです。ポイントとしてはRDSはVPC内のプライベートサブネットに配置されているというところです。
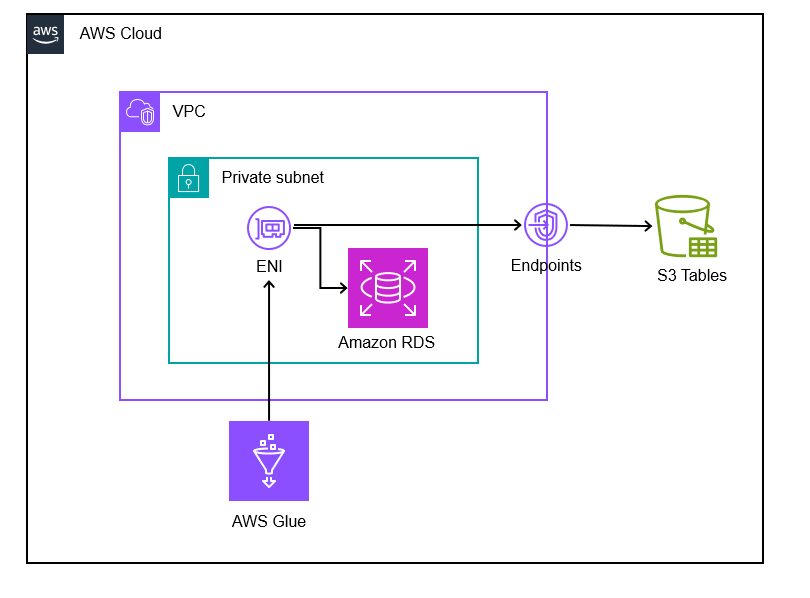
一見シンプルな構成ですが、実際に構築してみると思わぬ落とし穴がありました。
2.1【ハマりどころ①】ネットワーク:Glueセキュリティグループの「自己参照」
最初のハマりどころは、GlueでのRDSへの接続設定です。
VPC内にあるRDSへGlueから接続する場合、Glue Connection(接続情報)を作成し、VPC・サブネット・セキュリティグループ(SG)を指定する必要があります。
ここで、Glue特有の要件として自己参照ルールというものがあります。Glueジョブは、内部的にドライバーとワーカーノード間で通信を行います。この通信はVPC内に作成されたENIを経由して行われます。 そのため、Glueに割り当てたセキュリティグループ自身が、そのセキュリティグループからの全TCP通信を許可している必要があります。
そのため、Glueにアタッチするセキュリティグループのインバウンドルールには以下を追加する必要があります。
- タイプ: すべてのTCP
- ポート範囲: 0 – 65535
- ソース: カスタム(自分自身のセキュリティグループID sg-xxxxxx)
この設定がないと、Glueジョブの実装ができないようです。
2.2【ハマりどころ②】トランザクション:Commit Failed Exceptionエラー
続いてのハマりどころは、icebergテーブルの書き込み競合です。
今回の実装では、Glueジョブは連携するテーブルの数だけ作成し同時に複数のジョブが起動するような構成としていました。このとき、偶発的にCommitの競合を示すような以下のエラーが発生しました。
「pyiceberg.exceptions.CommitFailedException: CommitFailedException: Request doesn’t meet the requirement condition: Requirement failed: branch main has changed: expected id …..」
![]()
調べてみると、以下の公式ブログにもある通り、共通のカタログを利用していると異なるテーブルであってもCommitFailedException が発生する仕様となっているようでした。
Manage concurrent write conflicts in Apache Iceberg on the AWS Glue Data Catalog
これを回避するためには、このエラーが発生した場合にリトライ処理を実施するような実装が必要でした。異なるテーブルであれば同時にジョブ実行しても問題ないと思っていましたが、カタログが共通だと書き込みの競合が発生してしまうんですね。
2.3【ハマりどころ③】PySpark:メモリ不足エラー
最後のハマりどころは、Glueジョブの処理性能です。
最初はコスト効率のいいPython Shellでpythonのpyicebergライブラリを利用した実装をしていました。 しかし、データ量が増え、数万行レベルになった際に、データをDataFrameとしてメモリに展開しようとした際に落ちてしまうMemoryErrorが発生しました。

Python Shellで利用したpyicebergライブラリのupsert処理では、一度に処理できるデータの件数に制約があるようです。
そこで、Python Shellでの戦いを諦め、分散処理が可能なGlue ETL (Spark) へ切り替えました。これにより、Sparkの分散処理により数十万件のデータも一度にupsertできるようになりました。また、Worker Typeの選定も柔軟になり、DPUサイズも調整することで安定してデータ連携が可能になりました。
最初は小さくPythonで、将来的なデータ増加に応じてSpark構成を検討するというのがいいのではないかなと感じました。
3. まとめ
今回は、RDSのデータをGlueジョブを使ってS3 Tablesへ連携する際のハマりどころを紹介しました。
Glueはサーバレスのサービスであるために便利な側面が多い反面、そこで利用される仕組みを理解した上での実装が必要になると勉強になりました。
皆様もGlueを使う際にはぜひ参考にしてみてください!