

LifeKeeperの『困った』を『できた!』に変える!サポート事例から学ぶトラブルシューティング&再発防止策
こんにちは、SCSKの前田です。
いつも TechHarmony をご覧いただきありがとうございます。
システム基盤の主戦場がオンプレミスからパブリッククラウドへと移り変わり、AWSやAzure上でHAクラスタを構築する機会がぐっと増えましたよね。クラウドには「自動復旧」や「フルマネージドサービス」といった便利な機能が豊富に揃っており、一見するとシステムの可用性を担保するのはとても簡単になったように感じられます。
しかし、HAクラスターソフトウェアであるLifeKeeperをクラウド環境で運用する場合、この「便利な標準機能」や「クラウド特有の仕様」が思わぬ牙を剥くことがあります。良かれと思って有効にしたクラウド側の自動復旧機能が、LifeKeeperのフェイルオーバー動作と競合してしまったり、オンプレミスでは意識しなかった「ネットワークエンドポイント」や「アクセス権限」の壁に阻まれ、リソース設定がエラーで弾かれたりといった、予期せぬトラブルに直面することがあります。
本連載企画「LifeKeeper の『困った』を『できた!』に変える!サポート事例から学ぶトラブルシューティング&再発防止策」では、サポートセンターに蓄積された「生のトラブル事例」を元に、安定運用のための実践的な知恵を共有していきます。
はじめに
今回からスタートする新シリーズのテーマは、「カテゴリ3:クラウド環境特有の落とし穴:AWS/Azure連携でハマるポイント」です。
第一弾となる本記事では、AWS環境(EC2, Route53, S3)におけるLifeKeeperの構築・運用にフォーカスします。 良かれと思って設定したAWSの「Auto Recovery(簡易自動復旧)」が引き起こすクラスタ停止劇や、Route53連携・S3 Quorum設定時に見落としがちなネットワーク設計と権限の盲点など、実際に現場で発生したお問い合わせ事例を深掘りします。
「なぜAWS連携がうまくいかないのか?」「どう設計すればクラスタの単一障害点を防げるのか?」——AWS特有の仕様を正しく理解し、手戻りなく安定稼働させるためのノウハウを一挙に公開します!
💡 次回の記事(カテゴリ3 第2弾)はこちら!
▶【クラウド環境特有の落とし穴 #2】オンプレ感覚の「同一サブネット」はNG!?Azure環境のネットワーク要件とQuorum設計の最適解 – TechHarmony
今回の「困った!」事例3選と解決策
事例1:良かれと思った「AWS Auto Recovery」が引き起こすクラスタ停止劇
【事象の概要】
「AWSの標準機能だから有効にしておけばより安心だろう」と、EC2インスタンスの「簡易自動復旧(Auto Recovery)」を有効にして運用していました。ある日、稼働系のEC2に障害が発生。待機系へのフェイルオーバー自体は行われたものの、障害のあった稼働系EC2も自動復旧で起動してきてしまい、想定外の挙動をしてしまいました。
【判明した根本原因】
LifeKeeperの「EC2リソース(Recovery Kit for EC2)」は、異常を検出するとまずローカルリカバリー(自身の再起動など)を試み、ダメならリソースを停止して対向ノードへフェイルオーバーします。 しかし、ここにAWSのAuto Recoveryが介入し、LifeKeeperが異常を検知・処理する前にOSごと再起動させてしまうとどうなるでしょう? 対向ノードがノード異常を検出してフェイルオーバーを開始する一方で、再起動した旧稼働系のノード上でもLifeKeeperがサービスを再開しようと動き出します。結果として動作が競合し、最悪の場合は両ノードでLifeKeeperのリソースが停止し、サービス全体がダウンするリスクが生じます。
【具体的な解決策と学び】
- ベストプラクティス: LifeKeeperのEC2リソースを利用する場合は、AWSの「Auto Recovery(簡易自動復旧やCloudWatchアクションベースの復旧)」との併用は非推奨です。
- 復旧の主導権はLifeKeeperに一本化し、システム全体の確実なフェイルオーバーを優先する設計にしましょう。
事例2:Route53リソースが作れない!見落としがちな3つの原因
【事象の概要】
Route53リソースを作成しようとしたところ、「Hosted Zoneが見つからない」という旨のエラー画面が表示され、リソース作成に進めません。AWS側の権限(IAMポリシー)は間違いなく付与しているはずなのに、なぜ情報を取得できないのでしょうか。
【判明した根本原因】
サポートとの切り分けの結果、主に以下の3つの「隠れた原因」でAWS CLIによるRoute53へのアクセスが失敗することが判明しました。
- プロキシ設定の未反映: OSにプロキシ設定をしていても、LifeKeeperのプロセスがそれを認識していない。
- カスタムSSL証明書の読み込み漏れ:
AWS_CA_BUNDLEなどの環境変数を使用しているが、正しくエクスポートされていない。 - 同名のHosted Zoneの存在(LifeKeeperの仕様): パブリックとプライベートで「同じ名前のHosted Zone」が存在すると、Multiple zone matchedとなりリソース作成に失敗する仕様となっている。
【具体的な解決策と学び】
- 環境変数は
exportまで確実に: プロキシやカスタムSSLの環境変数を利用する場合、/etc/default/LifeKeeperファイルの末尾に以下のようにexportコマンドを含めて追記し、LifeKeeperを再起動する必要があります。<記述例>
AWS_CA_BUNDLE=/etc/pki/tls/certs/ca-bundle.crt; export AWS_CA_BUNDLE
HTTP_PROXY=http://192.168.x.x:8080; export HTTP_PROXY - Hosted Zone名の一意化: パブリックとプライベートで同名のHosted Zoneは使用せず、重複しない名前にするか、リネームして対応します。
※おまけの注意点
バージョンアップ(例: v9.3.x → v9.8.x)を行うと、Route53の監視処理(quickCheck)スクリプトなどが最新の標準ファイルで上書きされます。手動でスクリプトをリネームして無効化するなどの運用を行っている場合は、アップデート後の再設定を忘れないようにしましょう。
事例3:S3 Quorumを導入したのにF/Oしない?盲点は「NAT Gatewayの配置」
【事象の概要】
スプリットブレイン(ネットワーク分断時に両ノードがアクティブになってしまう現象)対策として、S3を利用したStorage Quorum(aws_s3)を設計しています。 しかし、「AZ(アベイラビリティゾーン)障害が起きた際、生き残った側のノードが正しくS3にアクセスしてアクティブになれるのか?」という懸念が浮上しました。
【判明した根本原因】
AWS環境でS3へアクセスする際、インターネットを経由する「NAT Gateway」を利用する構成がよく採られます。しかし、NAT Gatewayを1つのAZにしか配置しない(シングル構成)と、そのAZがダウンした瞬間に、生き残ったもう一方のAZにあるLifeKeeperからもS3へアクセスできなくなります。 S3にアクセスできない(Quorumとしての多数決が取れない)状態になると、LifeKeeperは安全を優先して自身をアクティブにする判断を行わず、結果としてフェイルオーバーが実行されません。
NG構成 OK構成
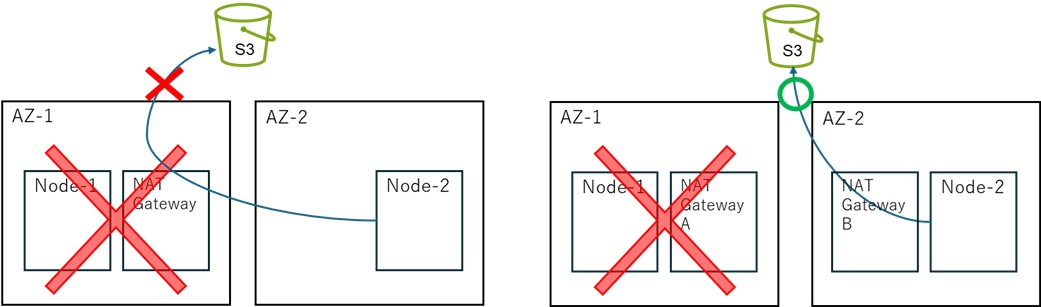
S3 Quorum構成時のNAT Gateway配置(NG構成 vs OK構成)
【具体的な解決策と学び】
- S3アクセス経路の冗長化: マルチAZ構成のLifeKeeperクラスタでは、NAT GatewayもそれぞれのAZに配置(冗長化)し、各ノードが自身のいるAZのNAT Gatewayを経由してS3へアクセスできるようにルートテーブルを設計することが必須です。
- 必要なIAMポリシーの過不足ない付与: S3 Quorumを正常に動作させるためには、バケットに対する
s3:PutObject,s3:GetObject,s3:ListBucket,s3:GetBucketLocationの4つの権限をIAMロールに必ず付与してください。
「再発させない!」ための対応策と学び(チェックリスト)
今回の事例から導き出された、設計・構築時に必ず確認したい「AWS環境構築チェックリスト」です。現場のノウハウが詰まっていますので、ぜひご活用ください!
- ☑ AWSの自動復旧機能との切り分け
- LifeKeeperの「EC2リソース」を使用する場合、対象インスタンスの「Auto Recovery(簡易自動復旧)」は無効化されているか?
- ☑ Route53連携・ネットワーク設定の確認
- パブリックとプライベートで「同じ名前のHosted Zone」を作成していないか?(同名が存在するとLifeKeeperからリソース作成に失敗します)
- プロキシ環境やカスタムSSL証明書を使用する場合、
/etc/default/LifeKeeperにexportコマンドを含めて正しく環境変数を定義し、再起動しているか?
- ☑ S3 Quorum(スプリットブレイン対策)の確実な構成
- IAMロールにS3 Quorum動作の必須ポリシー(
s3:PutObject,s3:GetObject,s3:ListBucket,s3:GetBucketLocation)が付与されているか? - 異なるAZからS3へアクセスする際、NAT Gateway等の通信経路は「各AZに冗長配置」されているか?(AZ障害時にS3へアクセスできないとQuorumが機能しません)
- IAMロールにS3 Quorum動作の必須ポリシー(
- ☑ 運用・保守時の注意(バージョンアップ時など)
- LifeKeeperのバージョンアップを実施する際、過去に手動でリネーム・カスタマイズしたスクリプト(quickCheckなど)が上書きされることを手順書に盛り込み、再設定を計画しているか?
まとめ
AWSの各種サービス(EC2, Route53, S3など)とLifeKeeperは非常に相性が良く、強力な可用性を実現できます。しかし、それぞれの「仕様の壁」や「機能の重複」を理解していないと、いざという時に想定外の動きをしてしまいます。
「復旧の主導権をどちらに持たせるのか(LifeKeeper優先)」「LifeKeeperのプロセスがAWS側の権限やネットワーク経路を正しく認識できているか」の2点を意識するだけで、トラブルの多くは未然に防ぐことができます。 日々の設計や運用の中で、ぜひ本記事のチェックリストをご活用いただき、安定したクラウドHAクラスタ基盤を実現してください!
次回予告
次回は、同じくクラウド基盤として利用が拡大しているAzureをテーマにお届けします。 「連載企画カテゴリ3 第二弾:Azure環境でのLifeKeeper構築・運用:ネットワークとQuorum設計の要点」をお送りする予定です。Azureならではの落とし穴とその回避策について解説しますので、どうぞお楽しみに!
📚 本連載のバックナンバー
過去のトラブル事例と解決策もぜひあわせてご覧ください!
カテゴリ1:リソース起動・フェイルオーバー失敗の深層
▶【リソース起動・フェイルオーバー失敗の深層 #1】EC2リソースが起動しない!クラウド連携の盲点とデバッグ術 – TechHarmony
▶【リソース起動・フェイルオーバー失敗の深層 #2】ファイルシステムの思わぬ落とし穴:エラーコードから原因を読み解く – TechHarmony
▶【リソース起動・フェイルオーバー失敗の深層 #3】設定ミス・通信障害・バージョン違いの深層と再発防止策 – TechHarmony
カテゴリ2:OS・LKバージョンアップで泣かないために
▶【OS・LKバージョンアップで泣かないために #1】OSバージョンは変えていないのに!?カーネル更新の「落とし穴」と互換性の真実 – TechHarmony
▶【OS・LKバージョンアップで泣かないために #2】「設定が消えた!?」「亡霊IPが警告!?」を防ぐロードマップ:単純な上書き更新に潜む落とし穴と回避策 – TechHarmony
カテゴリ3:クラウド環境特有の落とし穴
▶【クラウド環境特有の落とし穴 #1】良かれと思った自動復旧が仇に!?AWS環境(EC2/Route53/S3)でハマる構成と回避策 – TechHarmony
▶【クラウド環境特有の落とし穴 #2】オンプレ感覚の「同一サブネット」はNG!?Azure環境のネットワーク要件とQuorum設計の最適解 – TechHarmony
カテゴリ4:DataKeeper:ミラー同期とデータ保護の核心
▶【DataKeeper:ミラー同期とデータ保護の核心 #1】同期中だから切り替わらない!?フェイルオーバーの「絶対条件」と性能評価の罠 – TechHarmony
▶【DataKeeper:ミラー同期とデータ保護の核心 #2】スナップショットから戻したのに動かない!?リストア後の「整合性」確保とバックアップ連携の盲点 – TechHarmony
カテゴリ5:クラスタ健全性維持の要
▶【クラスタ健全性維持の要 #1】クラスタの番人Quorum/Witness:その設定、本当に必要? 正しく選んで正しく守る設計術 – TechHarmony