

こんにちは。
今回はAmazon MSK(Managed Streaming for Apache Kafka)上のデータを、S3 Sink Connectorによって Amazon S3 へ出力するパターンを解説します。
MSKはクラスター内のトピックにデータを保管しますが、そのデータをS3へバックアップすることができます。
前提条件
本記事で触れている内容は、以下の構成を前提としています。
-
ブローカータイプ:標準ブローカー(kafka.m5.large など)
-
クラスタタイプ:プロビジョンドクラスタ
-
メタデータ管理:Apache Zookeeper モード
AWS公式ドキュメントに記載されている下記の内容を参考にしています。
準備
今回、下記リソースは準備済みとして進めます。
- MSK クラスター(プロビジョンド、Zookeeper モード)
- S3 バケット(クラスターと同リージョン)
- MSK Connect 用 IAM ロール
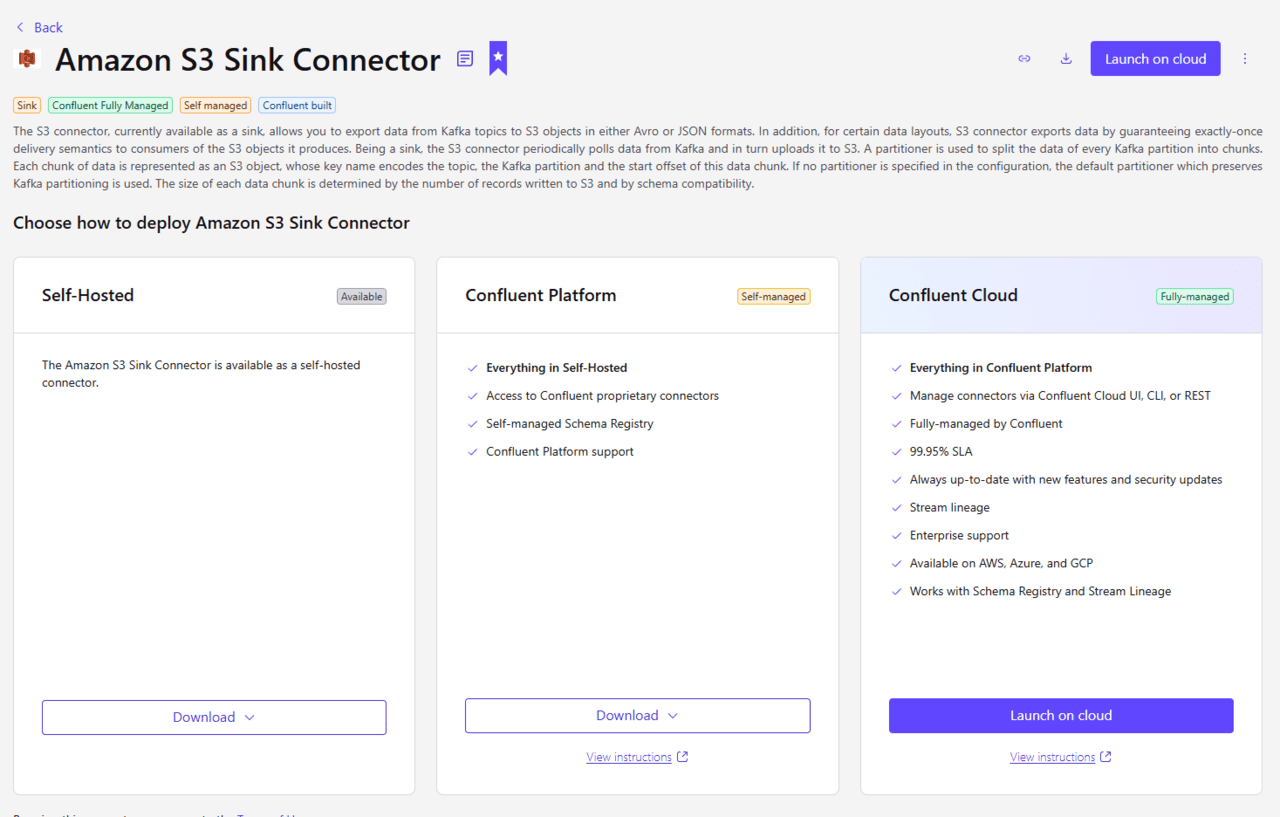
まず、S3 Sink Connectorを用意するためドキュメントに記載されているリンクから、Confluent S3 Sink Connector を入手します。
一番左の Self-Hosted をダウンロードし、ZIP ファイルを取得します。
一番左の Self-Hosted をダウンロードし、ZIP ファイルを取得します。
次に、MSK クラスターをデプロイした同じリージョンの S3 上に ZIP ファイルを配置しておきます。
ここまでで事前準備は完了です。
ここまでで事前準備は完了です。
カスタムプラグインの作成
カスタムプラグインは、MSK Connect を通じて利用する外部 Kafka Connector の ZIP アーカイブです。S3 Sink Connector の Kotlin/Java クラスを含むバイナリパッケージを事前に登録します。
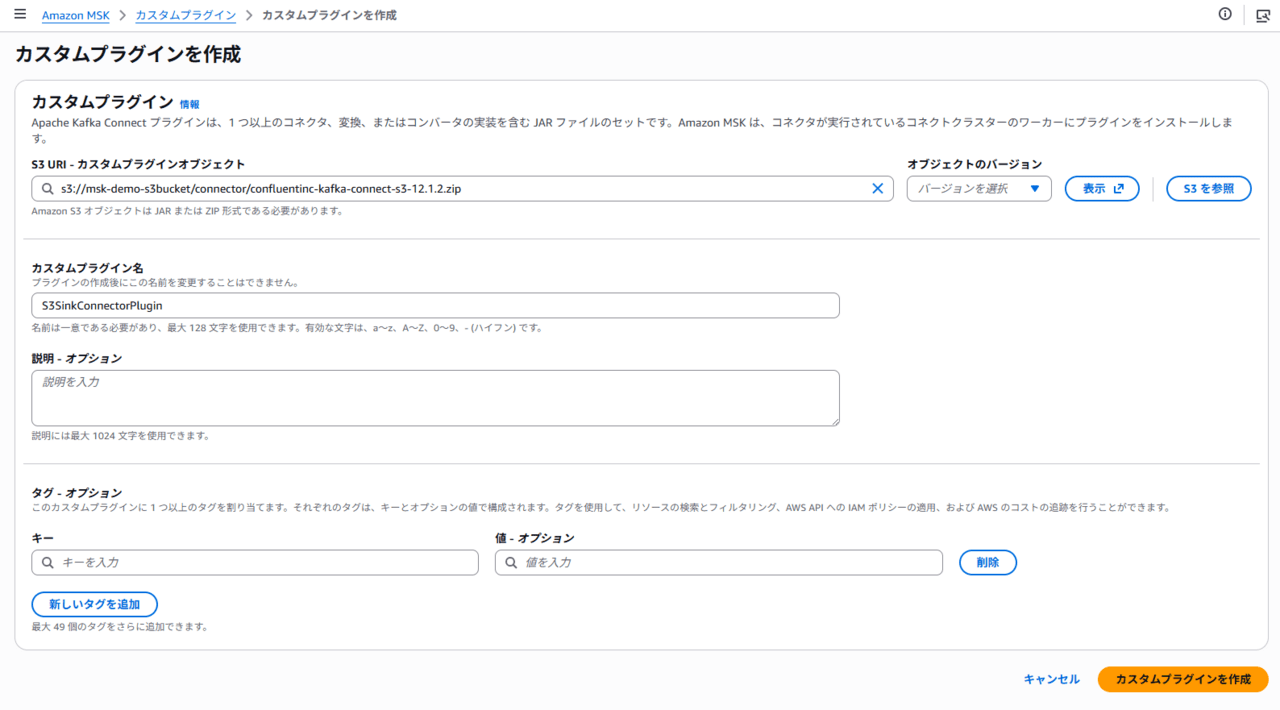
先ほど配置した ZIP ファイルの S3 パスを取得し、カスタムプラグインの作成画面で指定します。
カスタムプラグイン名を任意で設定し、「カスタムプラグインを作成」をクリックします。
カスタムプラグイン名を任意で設定し、「カスタムプラグインを作成」をクリックします。
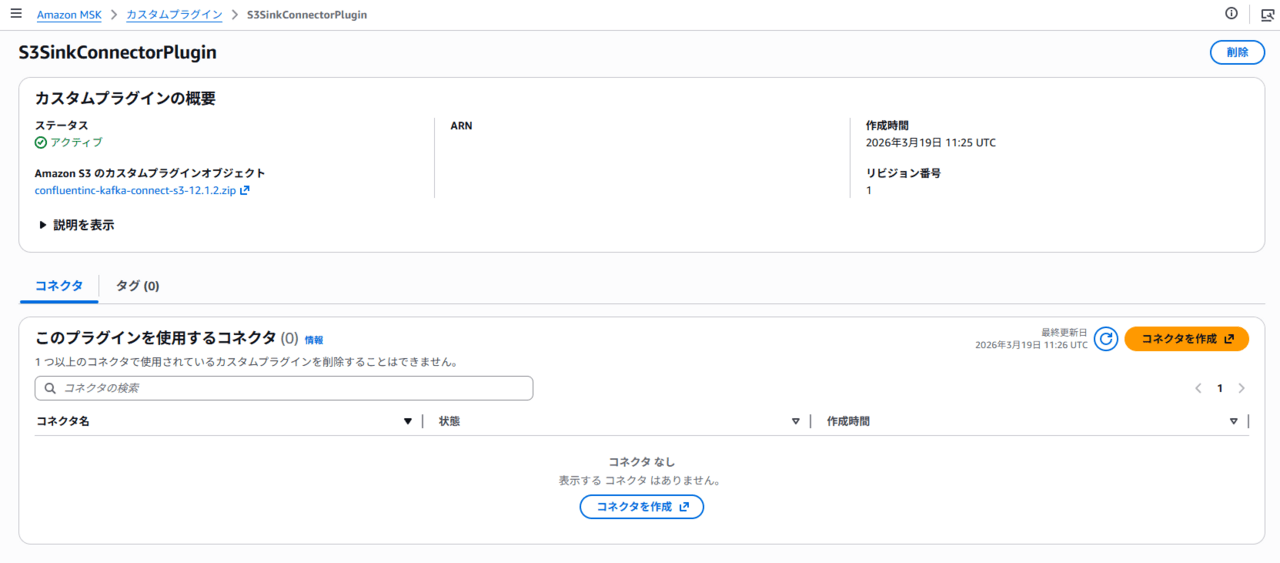
作成が完了すると、ステータスがアクティブになります。
次に、このプラグインを用いてコネクターを作成します。
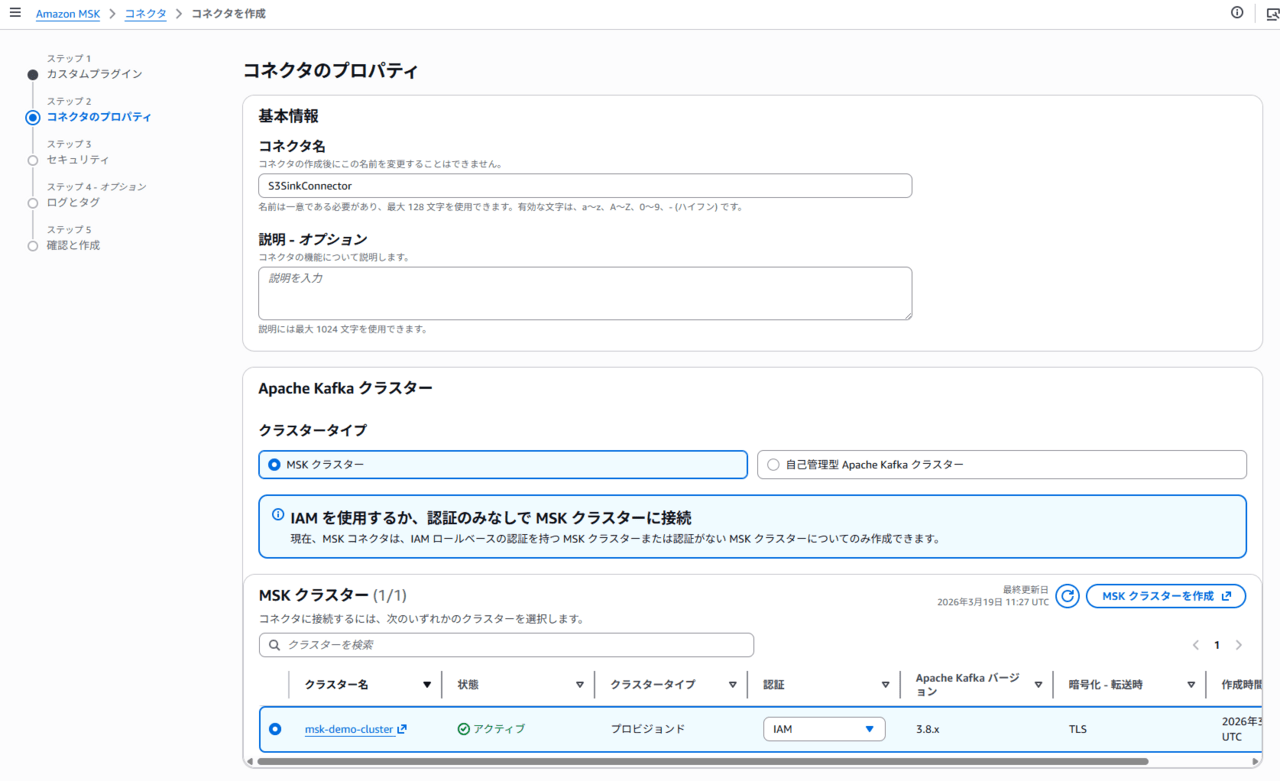
コネクターの作成
MSK Connector は、MSK Connect における Kafka Connect ジョブの単位です。既存のカスタムプラグインを指定して、接続先(MSK クラスター)・タスク数・出力先(S3)等を設定します。
コネクタ作成画面で、先ほど作成したカスタムプラグインを指定します。
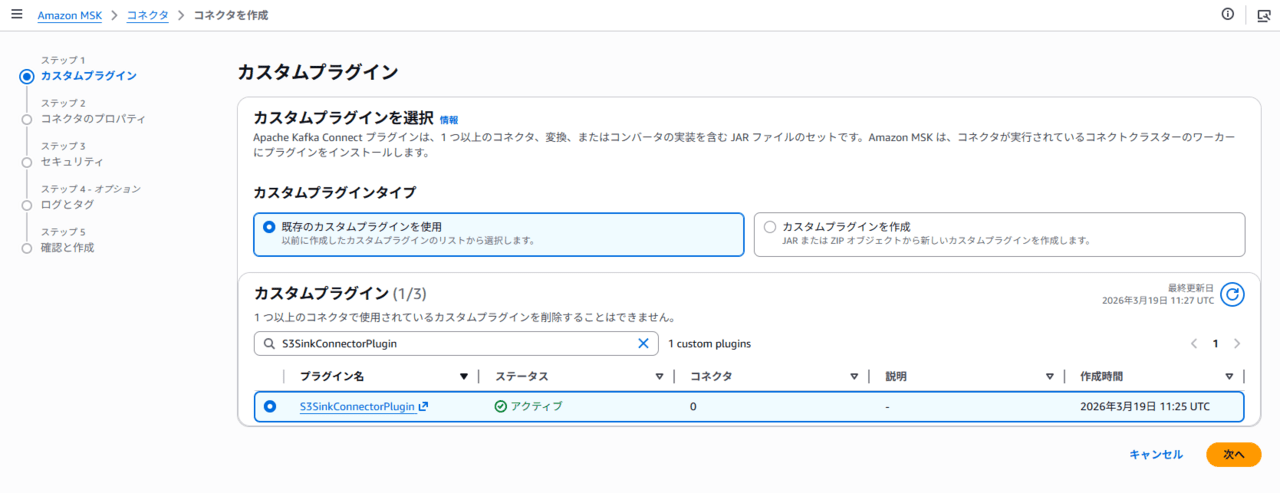
画面に従い、設定を進めます。
- 任意のコネクター名
- バックアップする対象となるMSKクラスター
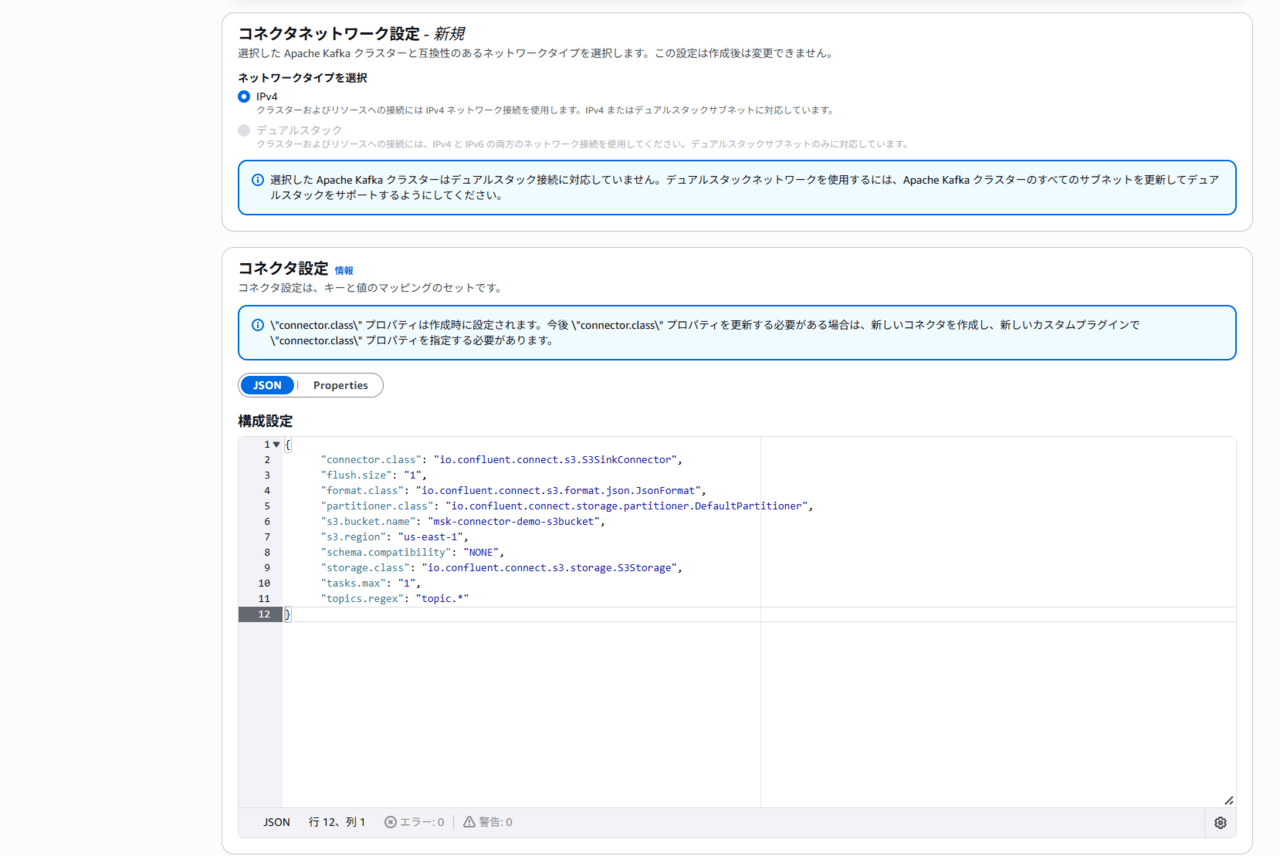
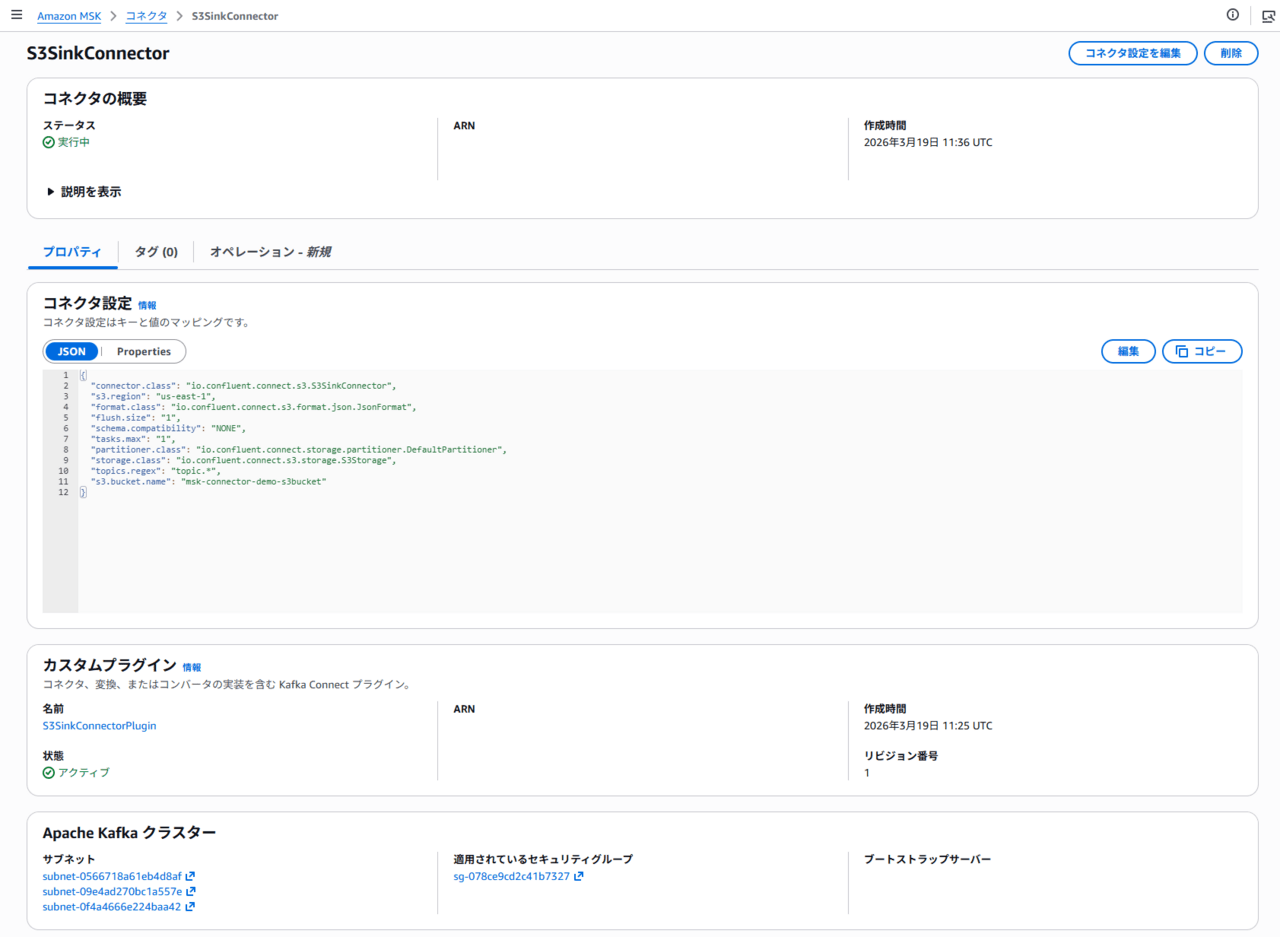
コネクタ設定は、公式ドキュメントを参考に設定します。今回は下記の通り設定しました。
補足として、1つの MSK Connector で複数 Topic を S3 へバックアップするために `topics.regex` を利用しています。
このパラメータを利用することで、`topic` から始まるトピック名のみを対象とすることができます。
このパラメータを利用することで、`topic` から始まるトピック名のみを対象とすることができます。
{
"connector.class": "io.confluent.connect.s3.S3SinkConnector",
"flush.size": "1",
"format.class": "io.confluent.connect.s3.format.json.JsonFormat",
"partitioner.class": "io.confluent.connect.storage.partitioner.DefaultPartitioner",
"s3.bucket.name": "msk-connector-demo-s3bucket",
"s3.region": "us-east-1",
"schema.compatibility": "NONE",
"storage.class": "io.confluent.connect.s3.storage.S3Storage",
"tasks.max": "1",
"topics.regex": "topic.*"
}
(補足) プロパティについて
今回は同アカウントのS3に出力するため、下記の通り指定しています。
- s3.bucket.name: 出力先バケット名
- s3.region: 出力先バケットのリージョン
また、公式ドキュメントの例だと、単一トピックを指定していますが、これだと「バックアップ対象のトピック」とConnectorが同じ数必要となります。
Connectorの数が増えると、下記のような問題につながります。
- Connectorの利用料金が増える
- Connectorの数によりサブネットのIP数が足りなくなり、MSK Clusterのスケールアウトができなくなる等の影響がある
今回は1つのS3 Sink Connectorで複数TopicのデータをS3へ出力するため、「topics.regex」を利用しています。
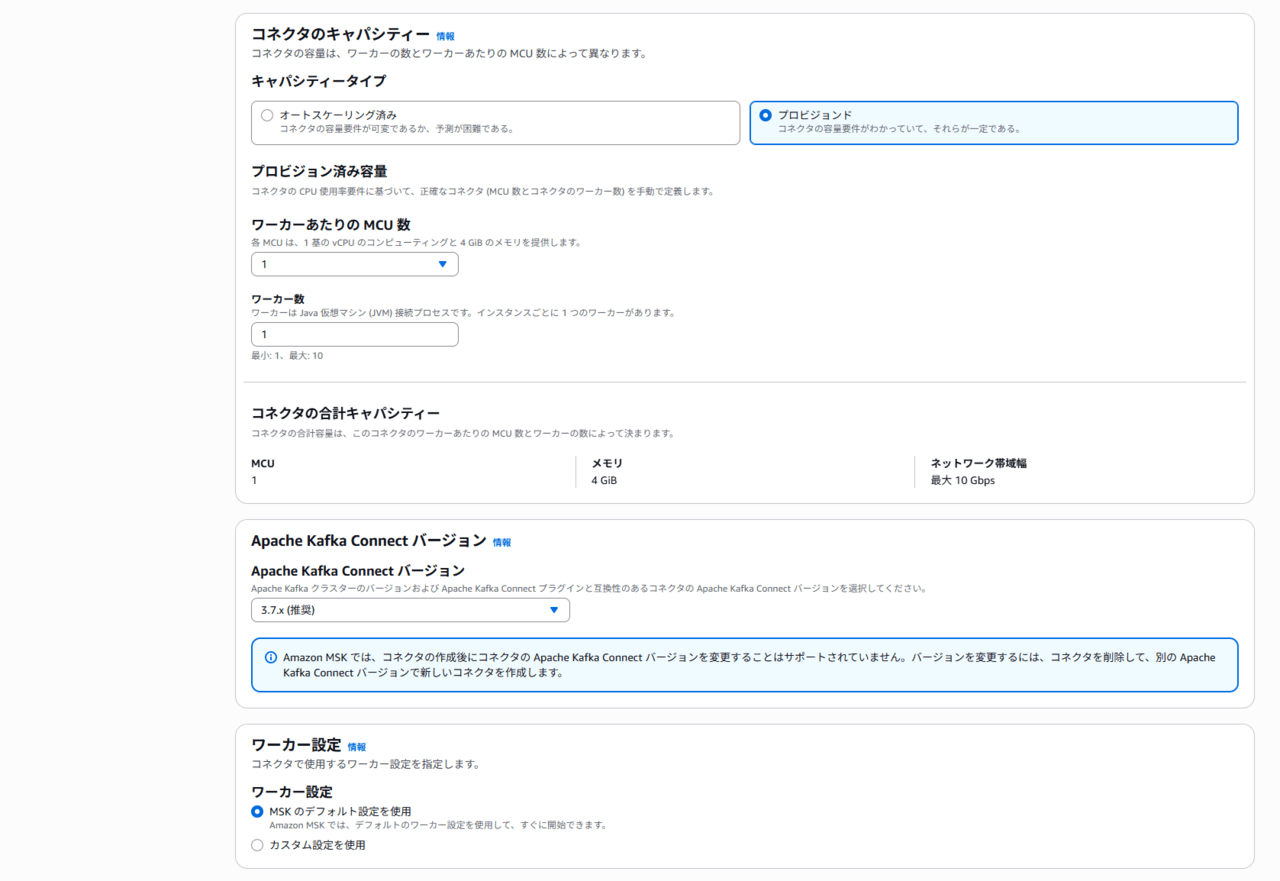
残りの設定を行います。
 。
。最後に、IAMロールを指定します。
ここで重要なのが、警告にある通り「AWSServiceRoleforKafkaConnect」ロールを指定できないことです。
ここで重要なのが、警告にある通り「AWSServiceRoleforKafkaConnect」ロールを指定できないことです。
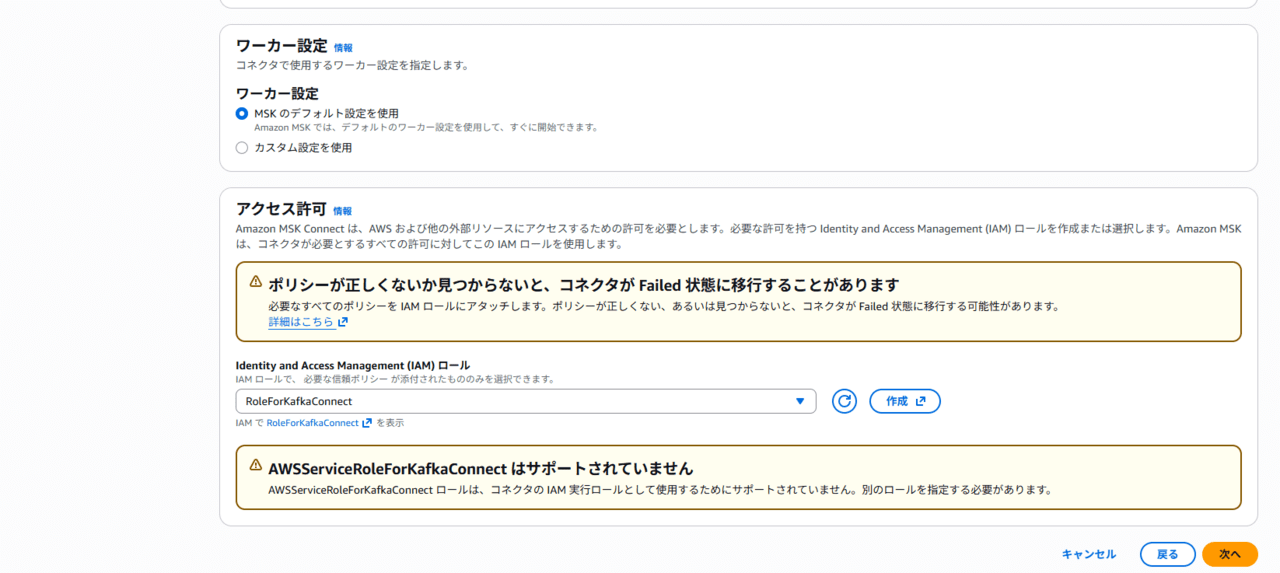
必ず、別途IAMロールを用意しましょう。公式ドキュメントに必要なポリシーがまとめられています。
はまりやすいのが、今回のケースで利用できるMSK Connect用の管理ポリシーは現時点で存在しません。MSKFullAccessという管理ポリシーはありますが、MSK ConnectのIAMロールとして使うには権限が足りていません。
もし権限が不足している場合は、MSK Connectの作成途中に下記エラーが発生します。
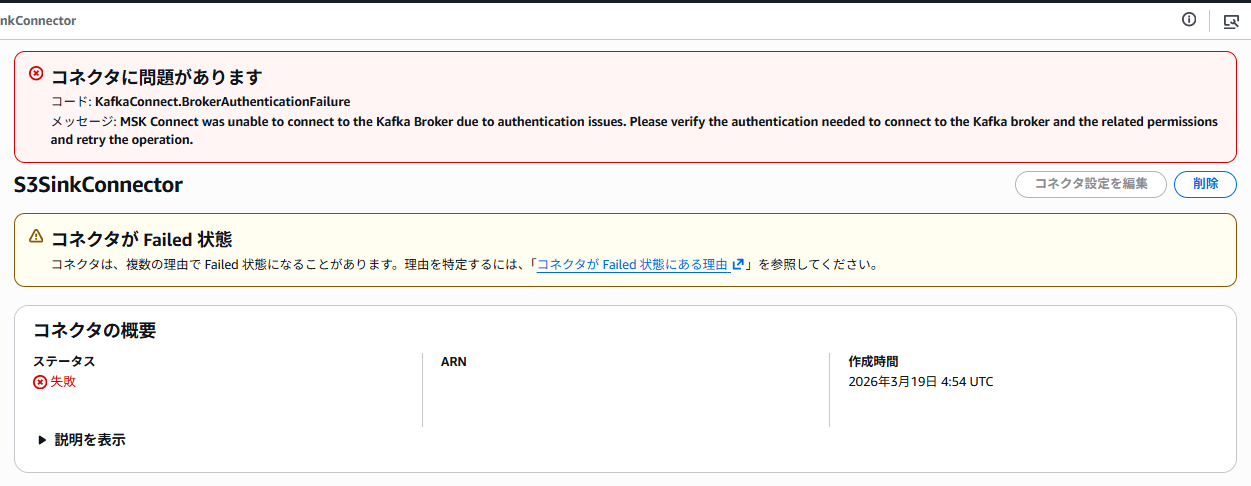
コード: KafkaConnect.BrokerAuthenticationFailureメッセージ: MSK Connect was unable to connect to the Kafka Broker due to authentication issues. Please verify the authentication needed to connect to the Kafka broker and the related permissions and retry the operation.
こうなったときは一度Connectorを削除し、再作成する必要があります。
IAMロールを指定し、「次へ」をクリックします。
IAMロールを指定し、「次へ」をクリックします。
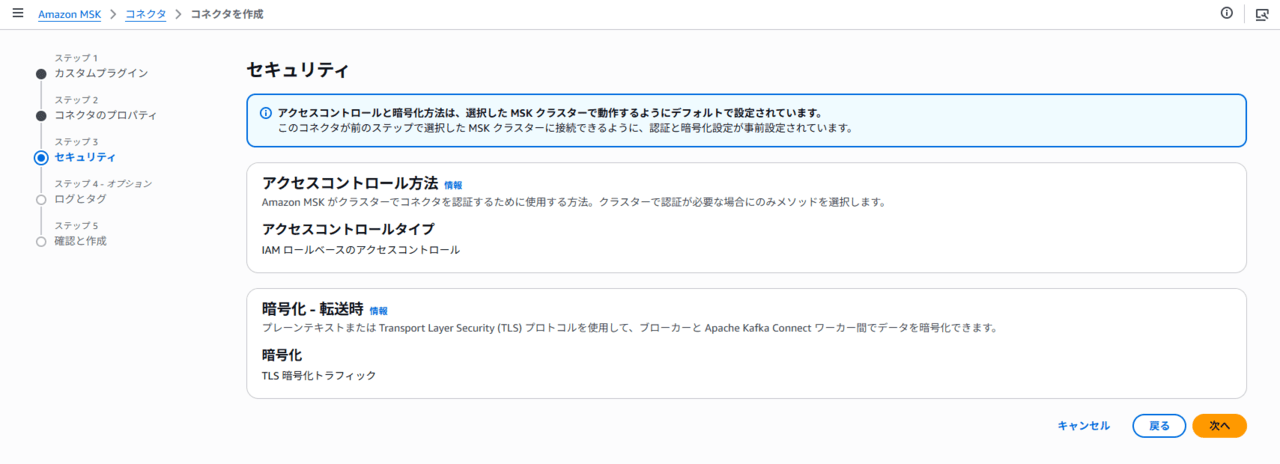
セキュリティの画面はそのまま「次へ」とし、ログは必要に応じて設定します。
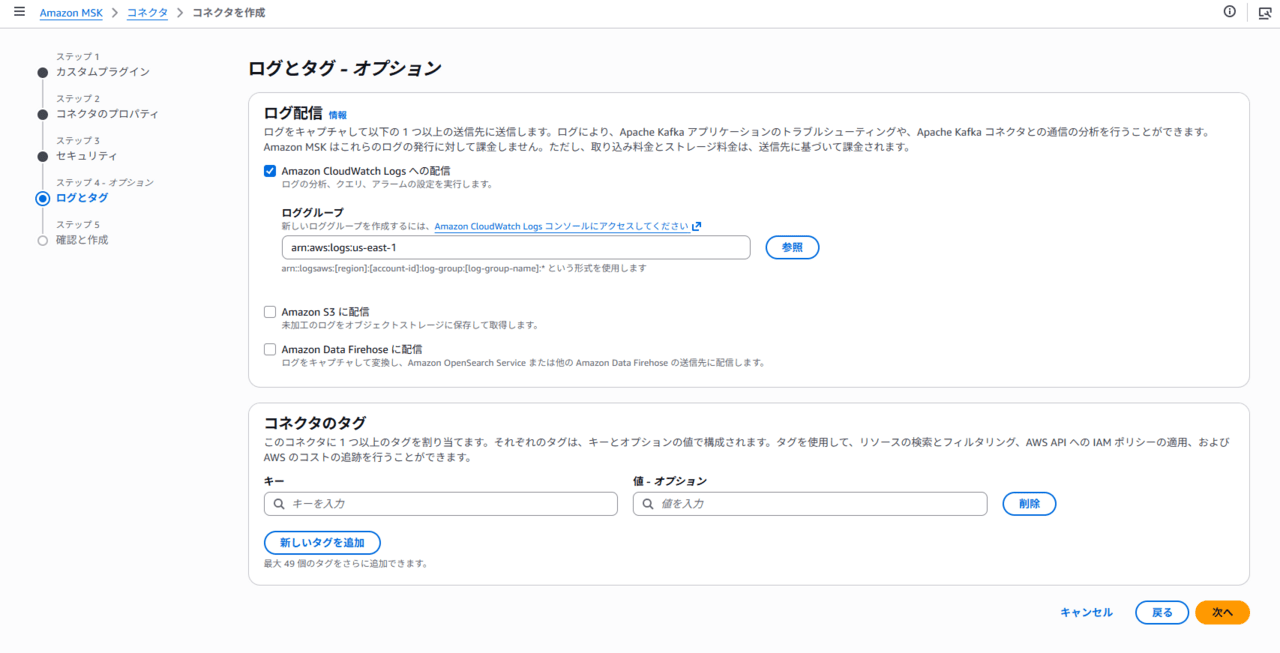
MSK Connectの作成が失敗した場合などのトラブルシューティングに役立つため、ログは有効化することをお勧めします。
各設定を確認し、「コネクタを作成」をクリックします。
各設定を確認し、「コネクタを作成」をクリックします。
しばらく時間がかかりますが、作成が完了するとステータスが「実行中」になります。
ここまでで Connector の作成は完了です。次はバックアップ対象として扱う Topic を用意し、正しく S3 へ出力されるかを確認します。
トピック作成
S3 に Topic 内のデータが出力されることを確認するため、まずいくつか Topic を作成します。今回は下記トピックを作成してみました。
- demo-topic
- topic-demo-dev01
- topic-demo-stg01
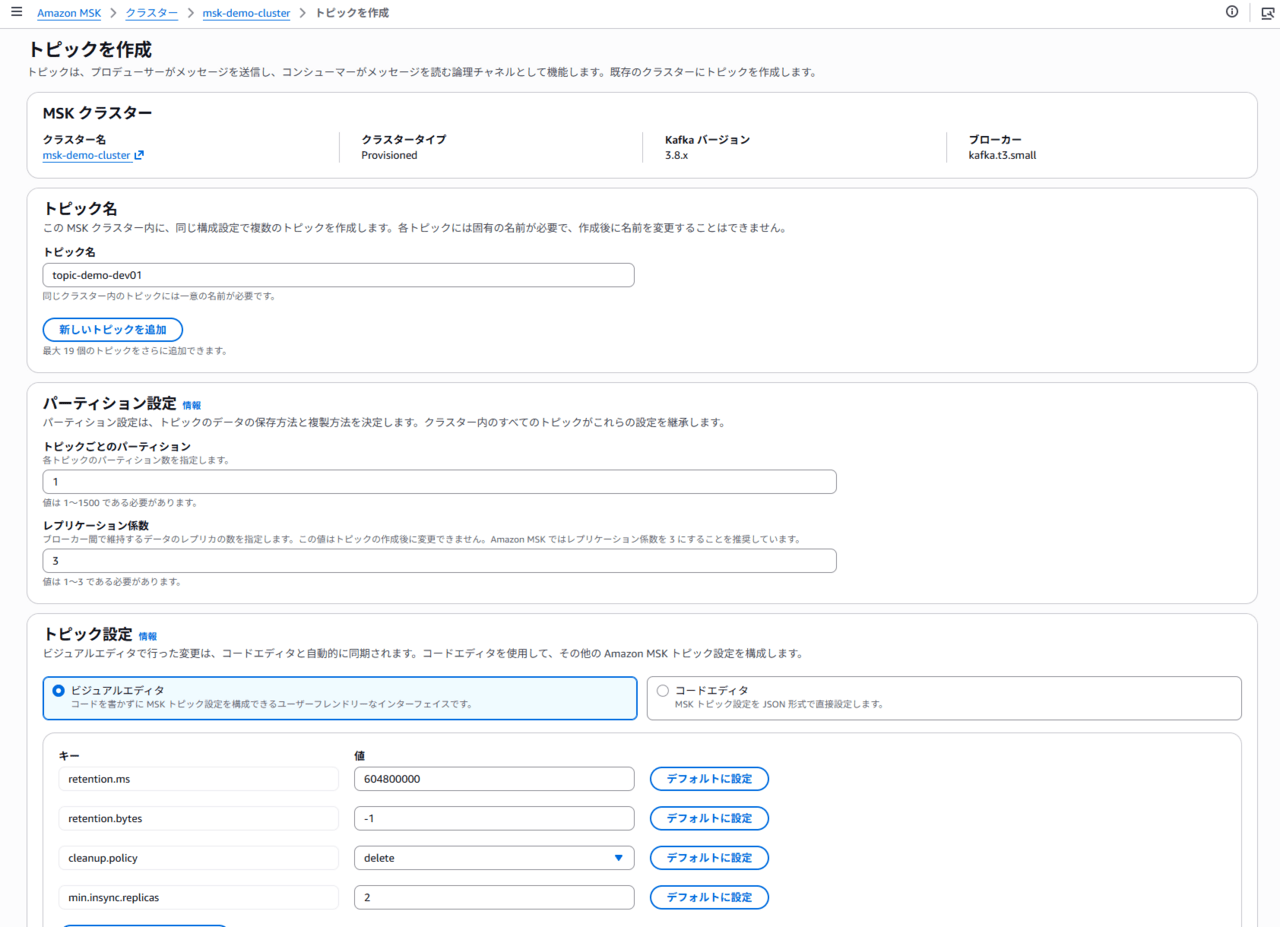
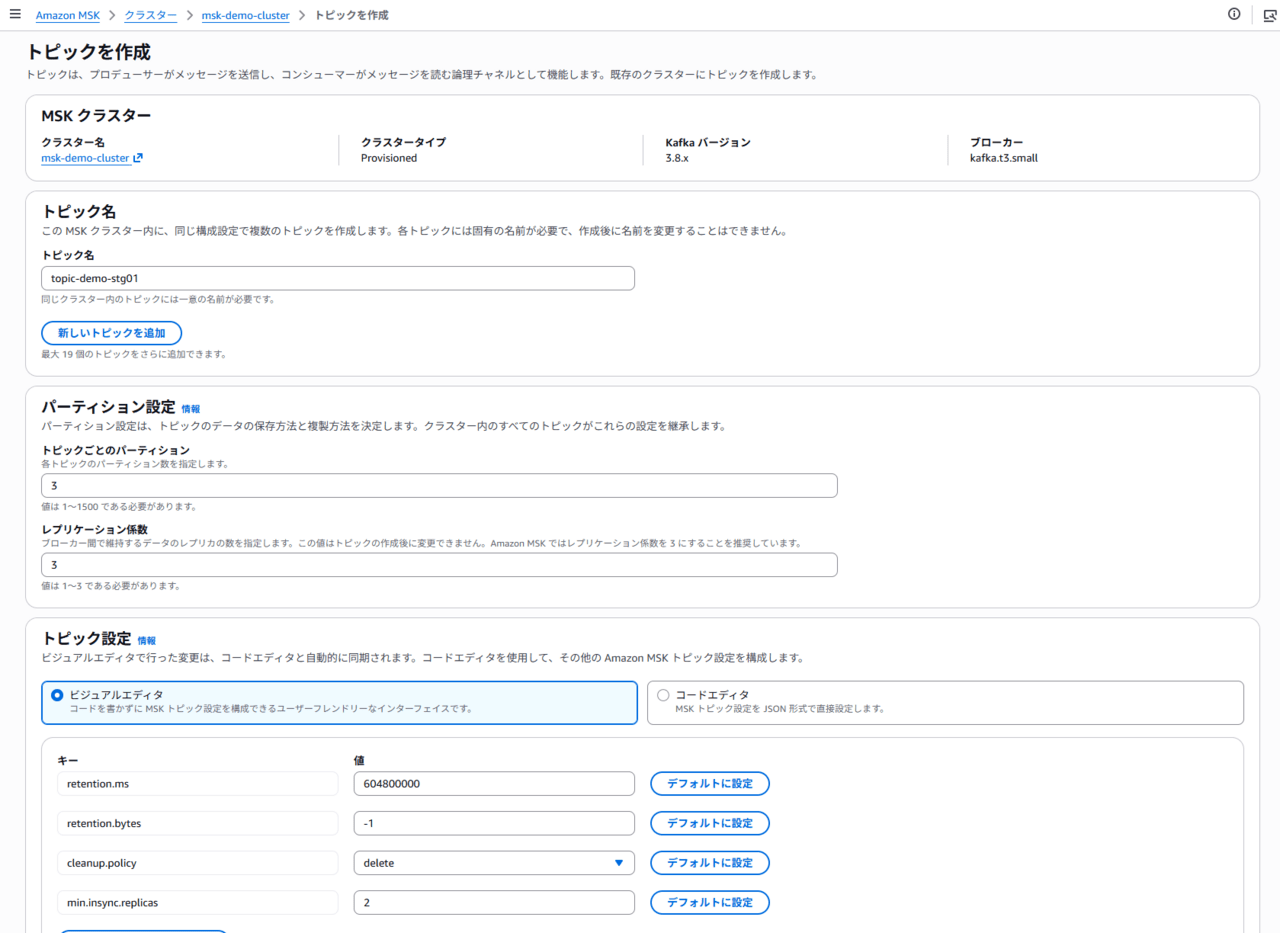
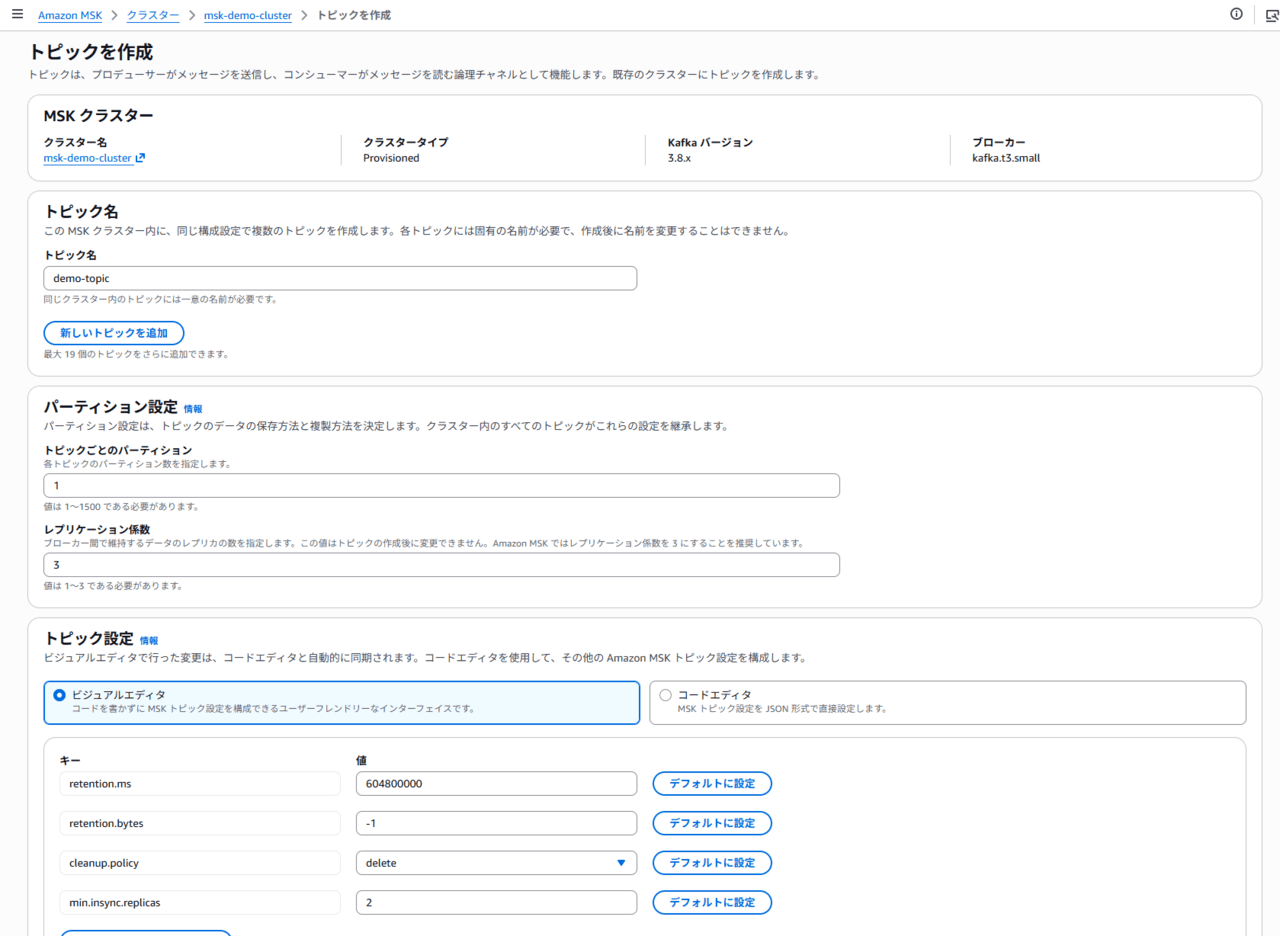
Connector作成時の設定により、「topic」から始まるトピックのみバックアップされることを確認します。
EC2などに配置した Kafka CLI で、トピックへメッセージを格納します。いったん、現在の Topic を一覧化します。
EC2などに配置した Kafka CLI で、トピックへメッセージを格納します。いったん、現在の Topic を一覧化します。
./bin/kafka-topics.sh --list --bootstrap-server <bootstrap-server> --command-config config/client.properties __amazon_msk_canary __amazon_msk_connect_configs_S3SinkConnector_4ab1ac36-1695-4b03-9e22-dcf79cee7218-2 __amazon_msk_connect_configs_S3SinkConnector_63bdb115-000a-4432-8668-b8c70bba0b34-2 __amazon_msk_connect_configs_S3SinkConnector_a6910ee0-12fc-4c43-ad89-784a9a5136ca-2 __amazon_msk_connect_configs_S3SinkConnector_b293673e-999e-4f0e-a616-e8eaed5206c2-2 __amazon_msk_connect_configs_S3SinkConnector_fb60d2ef-8ae7-4621-ba7d-1b891d1602dd-2 __amazon_msk_connect_offsets_S3SinkConnector_4ab1ac36-1695-4b03-9e22-dcf79cee7218-2 __amazon_msk_connect_offsets_S3SinkConnector_63bdb115-000a-4432-8668-b8c70bba0b34-2 __amazon_msk_connect_offsets_S3SinkConnector_a6910ee0-12fc-4c43-ad89-784a9a5136ca-2 __amazon_msk_connect_offsets_S3SinkConnector_b293673e-999e-4f0e-a616-e8eaed5206c2-2 __amazon_msk_connect_offsets_S3SinkConnector_fb60d2ef-8ae7-4621-ba7d-1b891d1602dd-2 __amazon_msk_connect_status_S3SinkConnector_4ab1ac36-1695-4b03-9e22-dcf79cee7218-2 __amazon_msk_connect_status_S3SinkConnector_63bdb115-000a-4432-8668-b8c70bba0b34-2 __amazon_msk_connect_status_S3SinkConnector_a6910ee0-12fc-4c43-ad89-784a9a5136ca-2 __amazon_msk_connect_status_S3SinkConnector_b293673e-999e-4f0e-a616-e8eaed5206c2-2 __amazon_msk_connect_status_S3SinkConnector_fb60d2ef-8ae7-4621-ba7d-1b891d1602dd-2 __consumer_offsets demo-topic topic-demo-dev01 topic-demo-stg01
今回手動で作成したTopic以外にいくつか存在していますが、こちらはMSK内部で自動作成されるものです。
メッセージ送信と検証
kafka-console-producer を利用して、適当なメッセージを送ります。
- topic-demo-dev01 にメッセージ送信
./bin/kafka-console-producer.sh --bootstrap-server <bootstrap-server> --topic topic-demo-dev01 --producer.config config/client.properties message1 message2 message3
- topic-demo-stg01 にメッセージ送信
./bin/kafka-console-producer.sh --bootstrap-server <bootstrap-server> --topic topic-demo-stg01 --producer.config config/client.properties message1 message2 message3
- demo-topic にメッセージ送信(対象外で確認)
./bin/kafka-console-producer.sh --bootstrap-server <bootstrap-server> --topic demo-topic --producer.config config/client.properties message1 message2 message3
次に、S3を確認します。
トピック名のオブジェクトが作成されています。
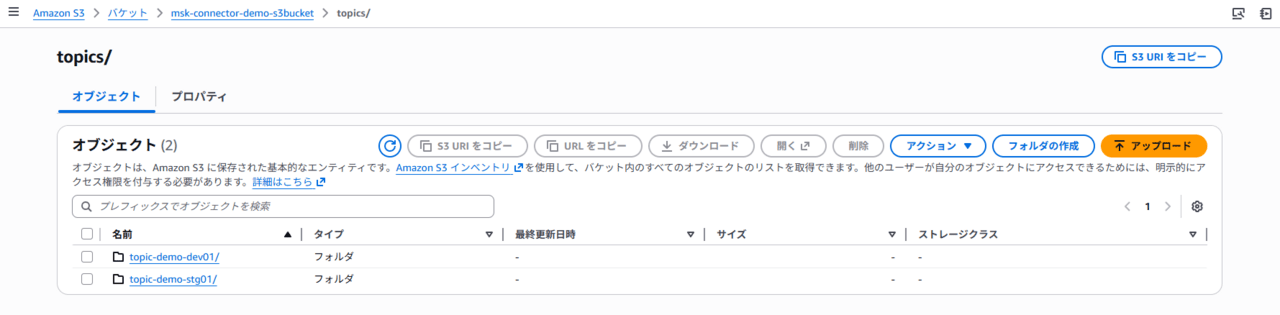
配下に移動すると、JSONオブジェクトとして出力されています。
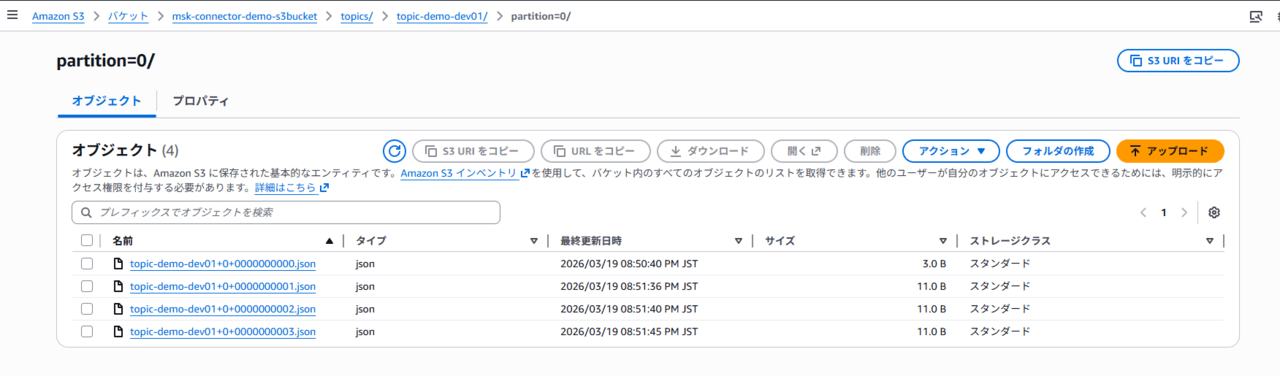
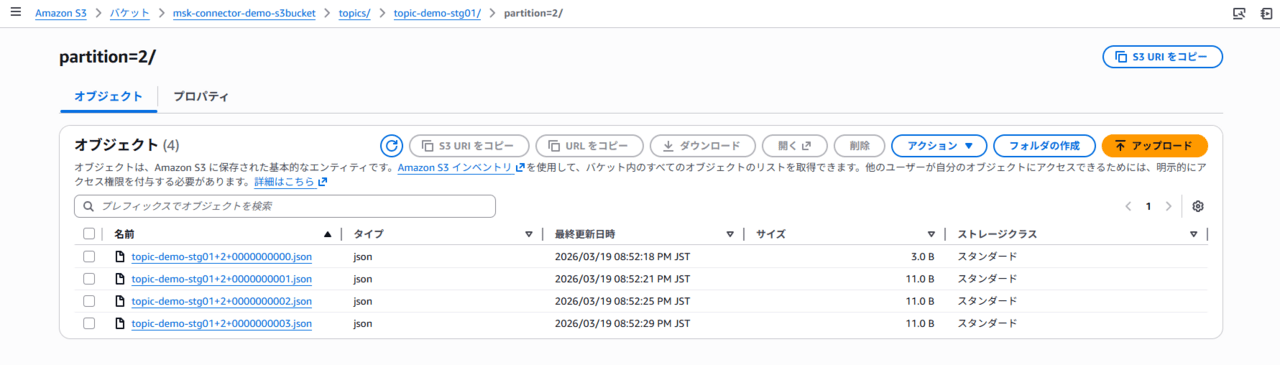
このように、S3へTopic内のデータを出力することができました。
ちなみにオブジェクト名は、トピック名+パーティション数+オフセット番号から構成されています。
また、ここでわかるように「topic」から始まるトピックのみが S3 へ出力されています。demo-topic に関しては出力されていません。
また、ここでわかるように「topic」から始まるトピックのみが S3 へ出力されています。demo-topic に関しては出力されていません。
まとめ
MSK Connect の S3 Sink Connector を活用し、複数Topic のバックアップをする方法をご紹介しました。
MSKクラスターのデータをバックアップする手段はいくつかありますが、今回はS3 Sink Connectorを使っています。MSK Connector自体はクラスター同様、MSK ConnectorはMSKクラスターが配置されているサブネット上に作成されます。
サブネットのIPアドレスに空きが十分でないと、クラスターのスケールアウトなどにも影響があります。
MSKクラスターの設計と合わせて検討することをおすすめします。