
こんにちは、SCSKの松岡です🪣
データ基盤の構築でIceberg (S3 Tables)を導入した際の試行錯誤を整理しました。
従来のS3によるファイル格納型のデータレイクと比較し、Icebergを採用することで得られたメリットや、それをマネージドで扱えるS3 Tablesの利便性について紹介します。
背景

データ活用基盤におけるデータレイクは、単にデータを蓄積するだけでなく、直接参照して検索・分析に活用したいというニーズが増えています。そのような用途では、複数テーブルのJOINや同時アクセスなどに対する性能も重要な観点となります。
従来は、データレイクのデータをRedshiftやSnowflakeといったDWHに取り込み、集計・加工したうえで活用する構成が一般的でした。
一方で、マルチクラウド環境では、組織や用途に応じて複数のツールから同一データを参照したいケースも増えています。
また、データオーナーの視点では、業務プロセスの変化に伴うデータ構造の変更に対して、データレイク側が柔軟に対応できるかが重要になります。列追加やデータ型変更などを、既存データに影響を与えずに実施できることが望まれます。
さらに、データ基盤管理者にとっては、従来のファイル形式のデータレイクでは、フォルダ構成やファイルサイズ、データ配置などの設計が必要となり、構築・運用のハードルが高いという課題がありました。
加えて、大量の履歴データを長期保管する特性上、データ量の増加に伴うストレージコストの増大や、運用負荷の増加も懸念されました。
構成と選定理由

Why Iceberg?
「背景」で述べた課題を踏まえ、データレイクにIcebergの仕組みを採用しました。
Icebergはオープンソースのテーブルフォーマットであり、オブジェクトストレージ上のデータをテーブルのように扱える点が大きな特徴です。
メタデータや統計情報を活用することで、必要なデータファイルのみを読み込むことが可能となり、従来の単純なファイル型データレイクと比較して効率的な検索が可能です。
また、Icebergはオープンテーブルフォーマットであるため、特定のDWHサービスに依存せず、AthenaやRedshift、Snowflakeなど複数の分析エンジンから同一データを参照できます。これにより、用途に応じてBI・AI/MLなどのツールを柔軟に選択でき、ベンダーロックインを避けた構成を実現できます。
さらに、用途ごとにテーブルを分離し、加工データを段階的に保持するデータレイク構成にも適しています。
機能面では、「スキーマ進化(Schema Evolution)」により、既存データを書き換えることなくカラム追加などのスキーマ変更が可能であり、データ構造の変化にも柔軟に対応できます。
Why S3 Tables?
S3 TablesはIcebergをマネージドで利用できるAWSのサービスです。S3 Tablesを採用することで、Icebergのテーブル管理を簡素化することができました。
テーブル単位でデータを管理できるため、フォルダ構成やファイル設計を個別に検討する必要がなく、データ管理をシンプルに保つことが可能です。
また、スナップショットやメタデータ管理がマネージドで提供されるため、履歴管理に伴う運用負荷を軽減できます。
必要に応じてスナップショットの保持期間などを手動で制御することも可能です。
さらに、データファイルの最適化が自動で実施されるため、運用による性能維持の負担を抑えつつ、必要に応じてパーティション設定などのチューニングも行えます。
加えて、S3ベースのストレージを利用するため低コストでのデータ保管が可能であり、コストタグやAWS Cost Explorerを用いた可視化・管理にも対応しています。
構成
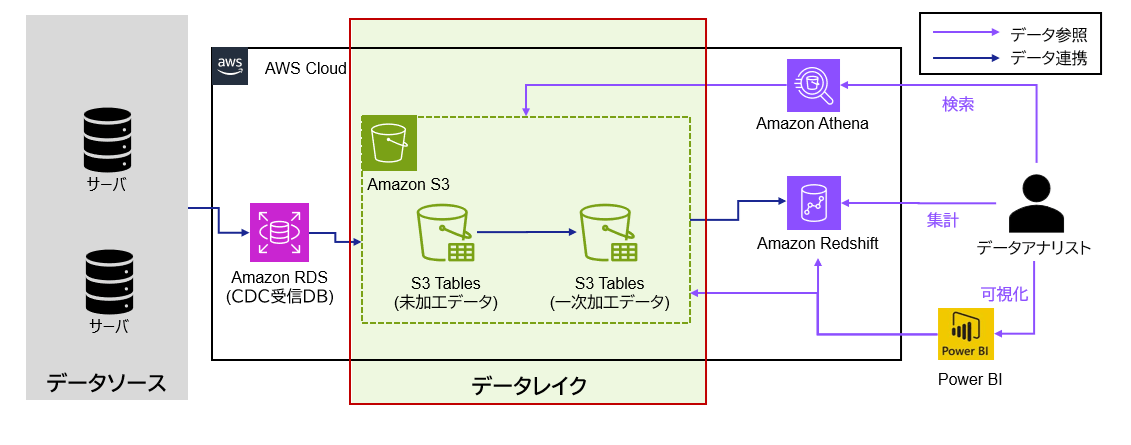
今回のケースでは、オンプレミスのサーバから収集したデータの蓄積先としてS3 Tablesを採用しています。
未加工データと一次加工データをテーブル単位で分離し、用途や処理段階に応じたデータレイク構成としています。
S3 Tablesに格納したデータは、AthenaやRedshift、BIツールなどから直接参照しています。
気にしたポイント
基本的なテーブルの構築は、S3 Tablesユーザーガイドのチュートリアルに従うことで簡単に実現可能でした。
運用も考慮した場合、追加で以下のような観点を考慮しました。
テーブル設定に関する考慮
基本的にS3 Tables側がマネージドで制御されるので、初期作成時には以下の点だけ気にしました
・テーブルプロパティ(スナップショットを保持する世代数、保持する最長時間)
・パーティション設定
テーブル定義に関する考慮
Iceberg 形式では、次のスキーマ進化の変更がサポートされています。
- Add – 新しい列をテーブルまたはネストされた
structに追加します。- Drop – 既存の列をテーブルまたはネストされた
structから削除します。- Rename – 既存の列またはネストされた
structのフィールドの名前を変更します。- 順序変更 – 列の順序を変更します。
- 型昇格 – 列、
structフィールド、mapキー、map値、またはlist要素の型を広げます。Iceberg テーブルでは、現時点で次のケースがサポートされています。
- 整数から大きな整数
- 浮動小数点から倍精度浮動小数点
- 10 進数型の精度を上げる
Icebergでは、既存テーブルに対してカラム追加や型拡張などのスキーマ変更(スキーマ進化)が可能です。
一方で、スキーマ進化には制約があり、数値型から文字列型のような互換性のない型変更はサポートされていません。その場合は、列の追加やテーブル再作成による対応が必要になります。
このため、スキーマ変更に柔軟に対応できる一方で、初期段階でのテーブル定義設計は依然として重要となります。
テーブル定義変更方法の制約
S3 Tablesのテーブルの作成はAWS AthenaやAWS CLIから可能です。
一方で、作成済テーブルに対するパーティション変更やソート順の変更など、一部のテーブル設定はAthenaやCLIからは実行できず、GlueのSparkジョブからSQLを実行する必要がありました(2025年時点)。
コストに関する考慮
2025年6月のアップデートにより、S3 TablesはCost Explorer からテーブルレベルのコストデータを参照できるようになりました。
他のAWSサービスと同様に、コストタグの設定も行えるようになりました。
比較的に新しいサービスなので、このような機能アップデートが活発に行われている状況です。
権限に関する考慮
S3 Tablesの権限制御はLakeFormationベースで行う必要があります。
従来のS3バケットの権限管理とは異なるため、導入時には注意が必要です。
一般的には、IAMユーザー/ロールごとに、S3 Tablesの名前空間やテーブル単位で権限を付与する形となります。
(追記) S3 Tablesに対して、IAM ベースの認証をサポートするというような記事も投稿されていました。
まとめ
Icebergを採用することで、データ構造の変化に柔軟に対応しつつ、効率的な検索が可能なデータレイクを構築することができました。
また、S3 Tablesを利用することで、構築・運用における設計負荷を大きく軽減できました。
本構成は柔軟性・性能・運用負荷のバランスに優れたデータ基盤の選択肢であると考えています。
一方で、Icebergにはスキーマ進化の制約があり、またS3 Tablesについても一部のテーブル設定変更に制約があるなど、設計時に考慮すべきポイントが存在していました。
IcebergはIoTデータなどの大規模データの格納基盤としても注目されており、今後はリアルタイムデータやAI/ML活用など、さらなるユースケースへの適用も検討していきたいです。
(宣伝) クラウドデータ活用サービス
今回ご紹介した内容は、SCSKで提供しているクラウドデータ活用サービスの中で扱っているテーマの一部になります。
お客様のデータ活用状況に応じて、基盤構築から可視化、データ連携、データマネジメント、高度データ活用までを段階的にご支援しています!
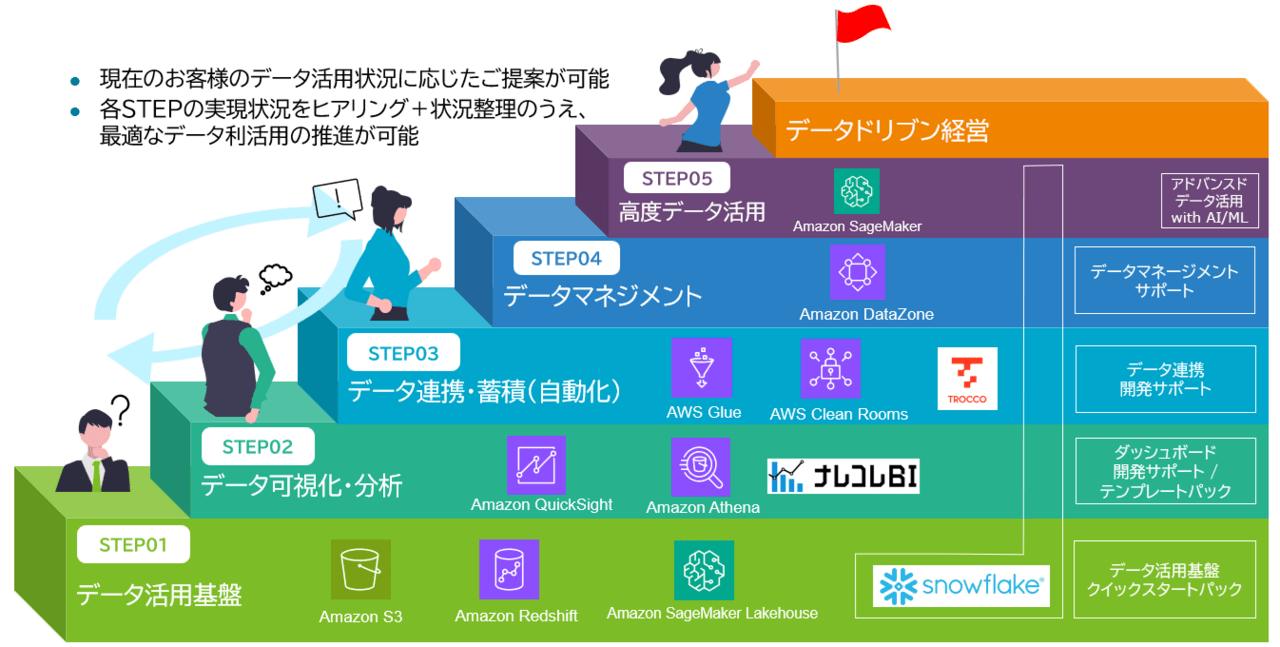
私自身もこのサービスに関わっており、AWS Summitのブースやミニセッションでもご紹介してきました。
ご関心あれば、以下のサービスページもご参照ください。