
こんにちは、SCSKの松岡です🔗
データ連携の実装でAWS Glue (Python Shell Job)を導入した際の試行錯誤を整理しました。
RDSからデータレイクであるS3 Tablesに連携する際に、横展開可能な軽量なデータ連携ジョブを実現するために気にしたポイントについて紹介します。
背景

データ活用基盤を構築するにあたり、「データをどのように集めるか」は重要なテーマの一つです。
仮に収集元のシステムが単一であっても、対象となるテーブルが複数存在する場合、テーブルごとに連携方法を検討し、ジョブとして実装していく必要があります。そのため、連携対象のテーブル数が多い場合には、テーブル単位での開発工数をいかに抑えつつ、効率的に横展開できるかが重要なポイントとなります。
また、データ連携方式を検討する際には、データ量だけでなく実行頻度も重要な判断軸となります。1回あたりのデータ量が少量であっても、高頻度で実行する必要がある場合、実行回数に比例してコストが増加するため、想定以上にコストが膨らむ可能性があります。
- 連携元はRDS(PostgreSQL)のみだが、連携対象テーブルが多数
- 処理1回あたりのデータ量は少量だが、毎時で何度も差分連携しなければならない
- 開発コストと運用コストの両方をなるべく抑えたい
- データレイクとしてIceberg (S3 Tables)にデータを連携したい
このような前提のもと、開発コストと運用コストの双方を抑えつつ、シンプルに実現できるデータ連携方式を検討しました。
構成と選定理由
Why AWS Glue(Python Shell)?
データ連携方式として、AWSサービスを利用することを前提に、以下から比較検討しました。
- AWS Glue (Python Shell)
- AWS Glue (Spark)
- AWS DMS
- AWS Lambda
その結果、今回は AWS Glue (Python Shell)を採用しました。
主な理由は以下の通りです。
- AWS Glue (Python Shell)は起動時間が短く、小規模かつ高頻度なデータ連携を効率的に実行できる
- AWS Glue (Python Shell)は、PythonベースでSQL抽出や変換処理を柔軟に制御できる
- AWS Glue (Spark)は大規模データ処理に適しているが、要件に対して過剰スペックになる
- AWS DMSには差分レプリケーション機能があるが、S3 Tablesに対応していない(※2025調査時点)
- AWS Lambdaで柔軟な処理開発が可能だが、15分の実行時間制約がある
構成
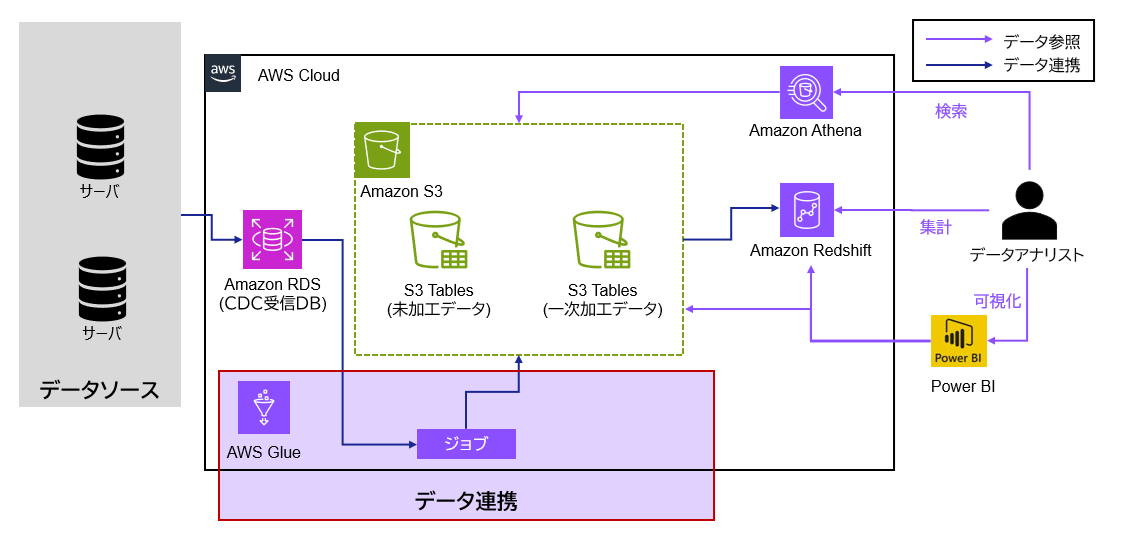
データソースからRDS(PostgreSQL)に集約したデータを、AWS Glue(Python Shell)ジョブによりAmazon S3へ連携し、未加工データとしてS3 Tablesに蓄積します。その後、AthenaやRedshiftから参照・集計し、BIツール(Power BI)で可視化する構成としています。
構成図では簡略化していますが、ジョブの起動はGlueトリガーによりスケジュール実行し、実行結果の監視や通知についてはEventBridgeおよびAmazon SNSを組み合わせて実現しています。
※本記事ではGlueジョブ中の変換処理は扱わず、未加工データをそのまま連携するシンプルなデータパイプラインにフォーカスしています。
気にしたポイント
差分更新の設計
Glueの処理にフォーカスしたデータ連携の概要は、以下の通りです。
Glueジョブを動かすための要素として、RDS側で管理・履歴テーブル、S3側に各種ファイル配置先を設定しています。
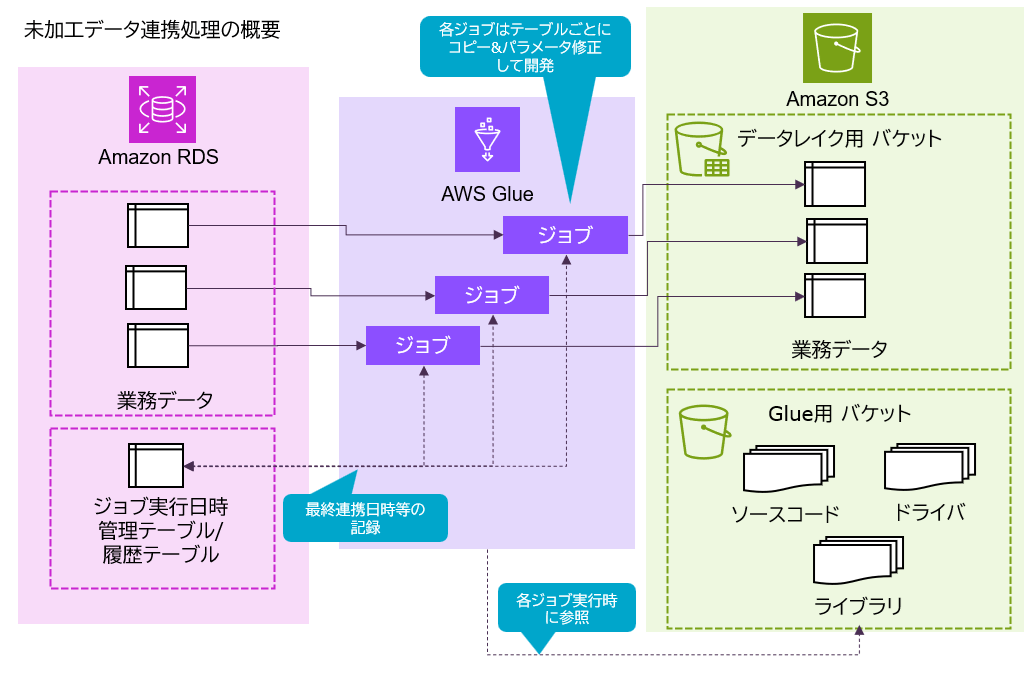
本構成では、RDS(PostgreSQL)に格納された業務データを、AWS Glue(Python Shell)ジョブによりS3へ連携します。
差分更新を実現するため、RDS側にはジョブ実行日時を管理する「管理テーブル」と「履歴テーブル」を配置し、S3側にはデータ出力先に加えて、Glueで利用するソースコードやドライバ、ライブラリを格納するバケットを用意しています。
Glueジョブは実行時に管理テーブルを参照し、前回処理日時をもとに差分データを抽出します。抽出したデータはS3へ出力され、その後、処理結果を管理テーブルへ反映することで、次回実行時の差分基準として利用されます。
また、GLueジョブの実行結果は履歴テーブルにも記録されるように設計しています。具体的には、各実行ごとに「連携対象日時(FROM/TO)」「処理件数」「実行成否」などをRDSに記録することで、過去の実行状況を追跡可能としています。
さらに、実行結果はCloudWatch Logsにも出力し、個々のジョブ実行の詳細を確認できるようにしています。
ジョブのパラメータ設定
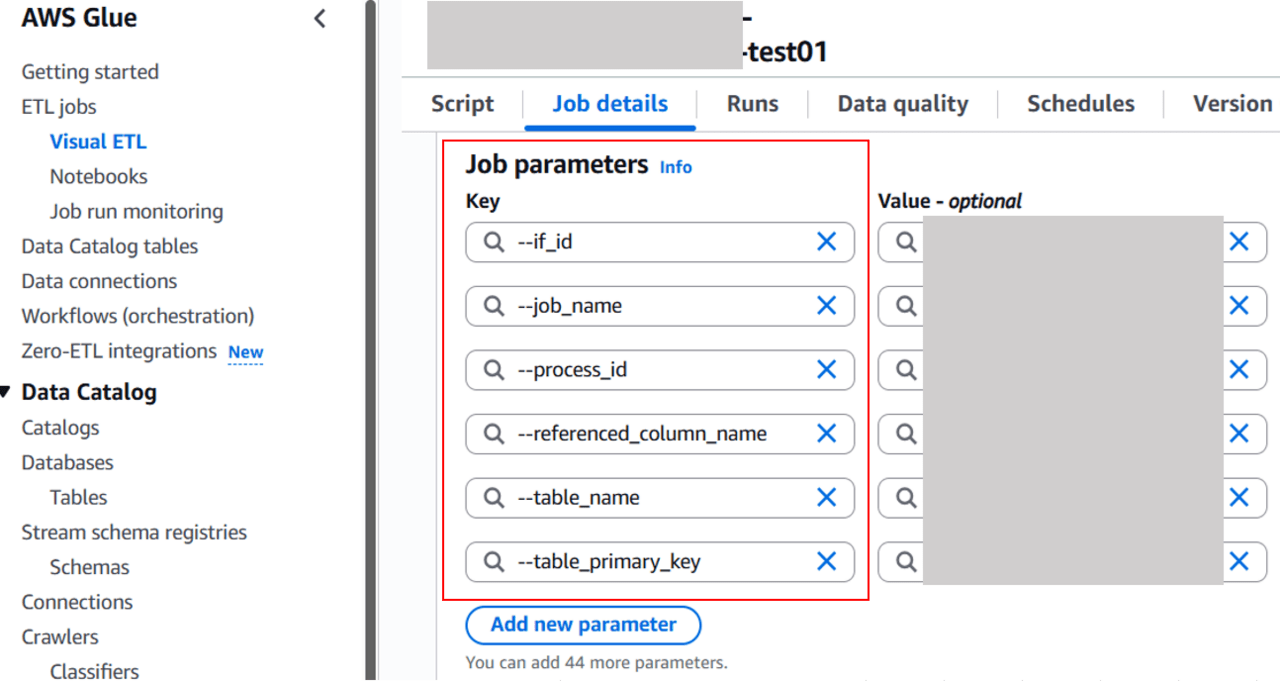
Glueジョブでは、パラメータを指定することで、ジョブごとに処理対象や抽出条件を動的に制御することができます。
このパラメータ設計は、複数テーブルのジョブ実装対応を効率化する上で重要なポイントとなります。テーブルごとに個別のジョブを1から作成すると開発負荷が高くなるため、ジョブをパラメータ化し、共通のジョブ定義をベースとして複製することで、複数テーブルに対応できるようにしました。
(GlueジョブはClone機能により簡単に複製が可能です)
具体的には、以下のようなパラメータを定義しています。
- table_name:対象テーブル名を指定し、スクリプト内で参照するテーブルを動的に切り替える
- primary_key:主キー項目を指定し、更新処理時のキー条件を動的に制御する
- last_update_column:差分抽出に利用する列を指定し、当該列をもとにフィルタ条件を動的に生成する
これにより、ジョブ定義の共通化と再利用性を確保しつつ、テーブル数が増加した場合でも効率的に展開できる構成としています。
PostgreSQL → Icebergのデータ型変換
出力先をIcebergテーブルとして利用する前提のため、データ型の整合性を意識した設計を行いました。
PostgreSQLとIcebergでは型の扱いに差異があるため、スキーマをもとに列ごとの型変換を動的に適用する方式としています。これにより、テーブルごとに個別対応することなく、共通ロジックで型整合性を担保できる構成としています。
また、今回のケースに限らず、システム間連携においては、各システムで扱うデータ型の仕様を正しく理解しておくことが重要です。特に、型の不一致による連携漏れや桁あふれなどの問題が発生しないよう、事前に設計段階で考慮しておく必要があります。
ライブラリ管理
Glue Python Shellでは、処理内容に応じて必要なPythonライブラリを自前で準備する必要があります。
今回の構成では、PostgreSQL接続用にpg8000、S3 Tables / Iceberg操作用にpyicebergなどのライブラリを利用しており、これらをwhlファイルとしてS3に配置して使用しています。
これらのライブラリを事前に配置しておくことで、実行時に外部リポジトリへアクセスして取得する必要がなく、インターネット接続に依存しない安定した実行環境を構築することができます。
また、Glue Python Shellにはあらかじめ利用可能なライブラリが含まれている一方で、用途によっては追加でライブラリを用意する必要があります。そのため、利用するライブラリが事前インストール済かどうかを確認した上で、必要に応じて追加対応を行うことが重要です。
さらに、ライブラリによってはGlueの実行環境との互換性によりそのまま利用できない場合もあるため、事前の検証やビルド方法の調整が必要となる点には注意が必要です。
まとめ
AWS Glue Python Shellは、起動時間が短く、コストを抑えながらPythonで柔軟に実装できる点が特徴であり、軽量なデータ連携基盤として非常に有効な選択肢です。特に、SQL主体のシンプルなETL処理や高頻度のバッチにおいては、その特性を活かしやすく、効率的なデータ連携を実現できました。
一方で、ライブラリの準備や実行環境との互換性、差分更新の設計などは自前で考慮する必要があり、構成によっては設計・運用面での工夫が求められます。また、ジョブのパラメータ設計やログ出力などを含めた運用設計も重要なポイントとなります。そのため、処理内容やデータ量、運用要件に応じて、Glue SparkやDMS、リアルタイム連携であればKinesis Data Firehose、またはTROCCOのようなサードパーティ製ETLツールも含めて、適切に使い分けることが重要だと思いました。
本記事のような軽量かつ柔軟なデータ連携のユースケースにおいては、Glue Python Shellは実用性の高い選択肢であると感じました。
(宣伝) クラウドデータ活用サービス
今回ご紹介した内容は、SCSKで提供しているクラウドデータ活用サービスの中で扱っているテーマの一部になります。
お客様のデータ活用状況に応じて、基盤構築から可視化、データ連携、データマネジメント、高度データ活用までを段階的にご支援しています!
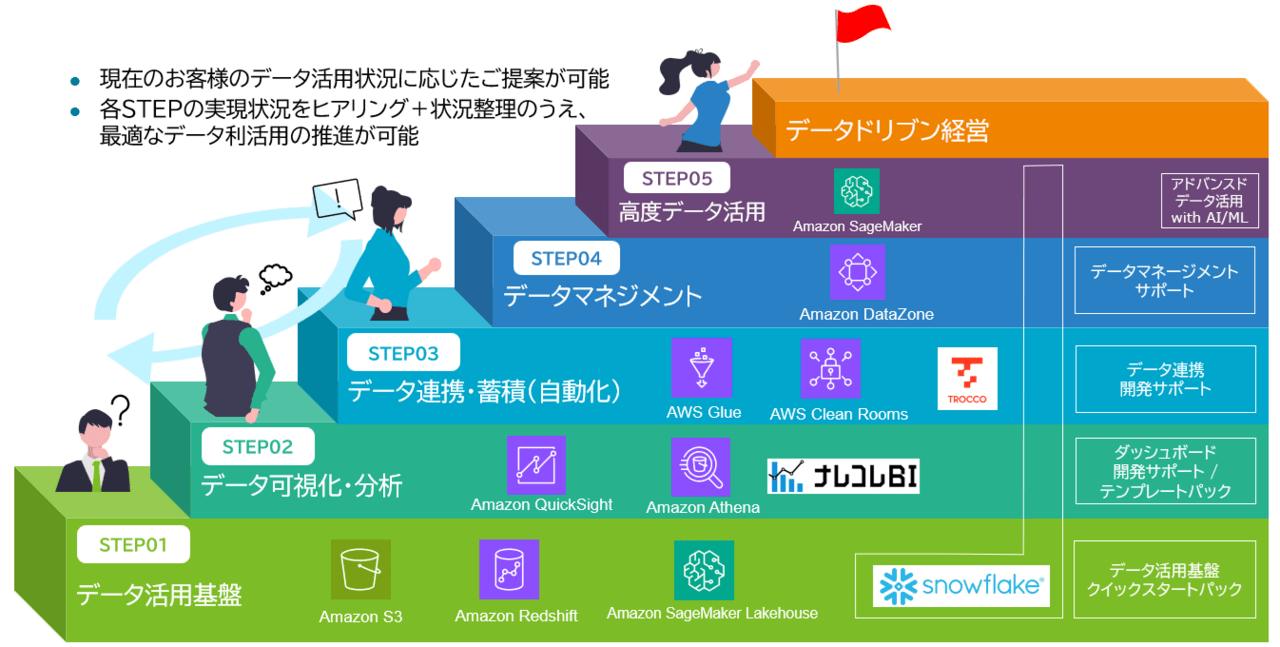
ご関心あれば、以下のサービスページもご参照ください。
