

こんにちは。SCSKの島村です。
Google Cloud Next ’26 in Las Vegas で紹介された「Agent Development Kit 2.0」についてご存じでしょうか?
ADK 2.0では高度なAIエージェントを構築するための強力なツールを導入し、 エージェントがよりコントロール的に難しいタスクを実行できるようになりました。本記事では、
『Agent Development Kit (ADK) 2.0』について色々と調査し、実際に触ってみましたので、その魅力について少しだけご紹介させていただければと思います。
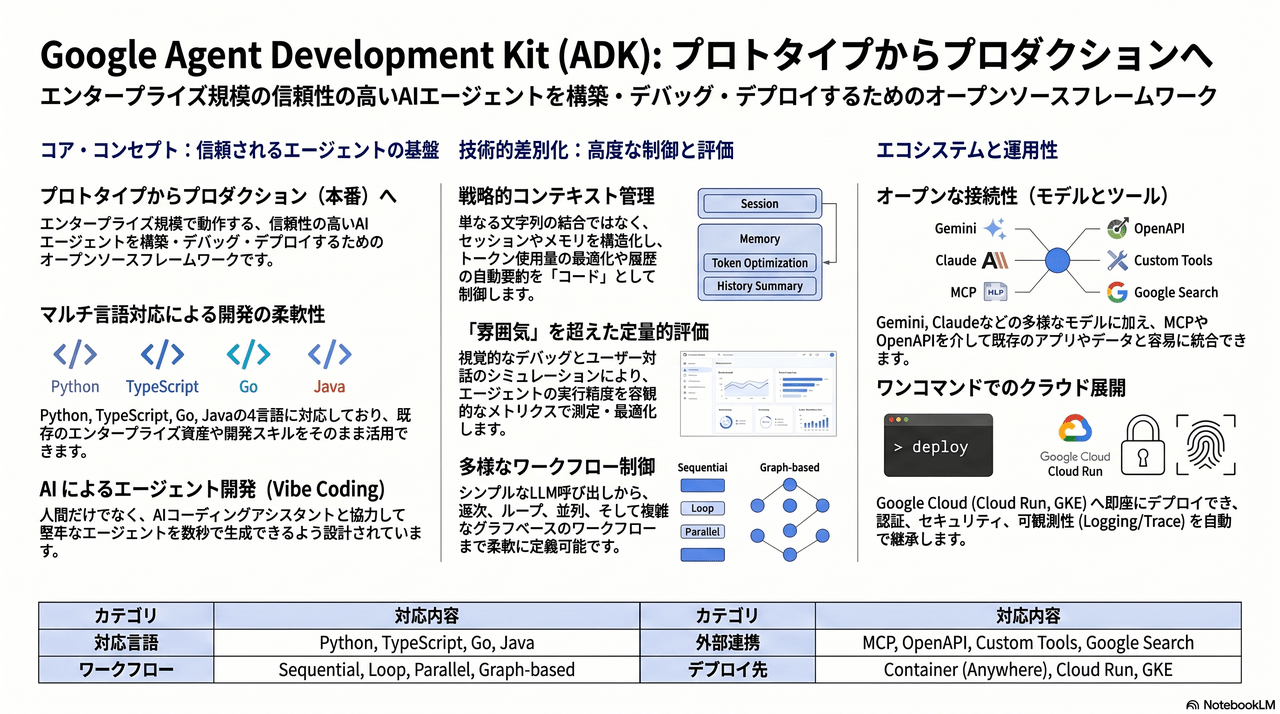
Agent Development Kit (ADK) とは??
ADKは、Googleが提供するオープンソース(Apache 2.0)のマルチエージェント開発フレームワークです。
エンタープライズ規模で信頼性の高いAIエージェントを構築、デバッグ、デプロイできる開発キットとして注目されています。
Agent Development Kit (ADK) 2.0 になって何が変わった??
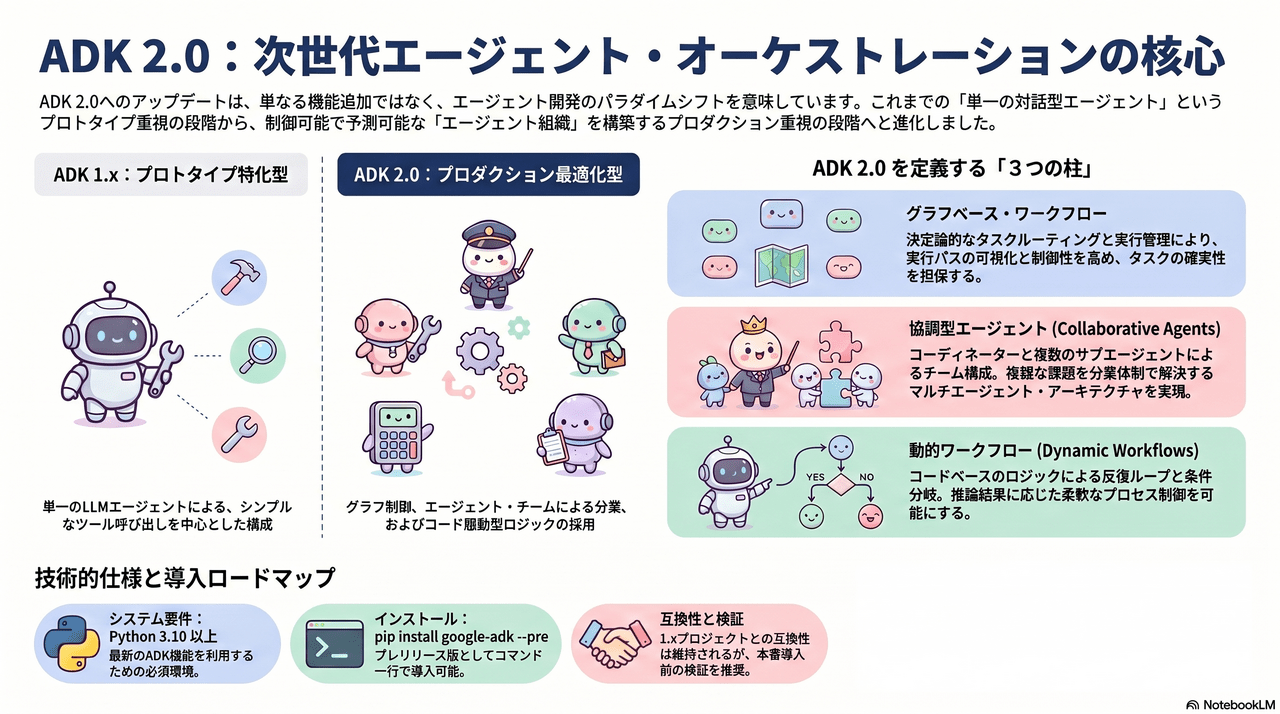
ADK2.0 では従来の1.x系から**「単一の対話型エージェント」の枠組みを超え、制御可能で予測可能な「エージェント組織」の構築**へと大きく進化しています。
- グラフベース・ワークフロー (Graph-based Workflows)
- 1.xまで: プロンプトやシンプルなツール呼び出しに基づく、比較的自由度の高い(あるいは制御しにくい)実行形式。
- 2.0: 決定論的なタスクルーティングと実行管理が可能に。タスクの実行パスを可視化し、制御性を高めることで、業務プロセスとしての確実性を担保します。
- 協調型エージェント (Collaborative Agents)
- 1.xまで: 基本的に単一のLLMエージェントが主体。
- 2.0: コーディネーターと複数のサブエージェントによるチーム構成(マルチエージェント・アーキテクチャ)が可能に。複雑な課題を分業体制で解決する「エージェント組織」を実現します。
- 動的ワークフロー (Dynamic Workflows)
- 1.xまで: 逐次的な実行がメイン。
- 2.0: コードベースのロジックにより、推論結果に応じた反復ループや複雑な条件分岐を組み込めるようになった。これにより、柔軟かつ高度なプロセス制御が可能になる。
Agent Development Kit (ADK) 2.0 を実際に触ってみる。
ADK2.0 では、これまでの Sequential/Parallel エージェントに加え、より柔軟で決定論的な制御が可能な Workflow クラス が導入されています。
今回は、この最新の Workflow API を使い、「記事作成 ➔ 並列レビュー ➔ 結果集約」という Fan-Out / Fan-In を伴う実践的なワークフローを実装しました。
グラフベースの「Workflow」でマルチエージェント・パイプラインを構築する
1. ADK 2.0 の真骨頂:Workflow API
ADK 2.0 における最大の変化は、エージェントの連携を**グラフ(ノードとエッジ)**として明示的に定義するようになった点です。
- 1.x 以前:
SequentialAgentなどで入れ子構造を作る。 - 2.0:
Workflowクラスでedges(エッジ)をリストアップし、実行順序を完全にコントロールする。
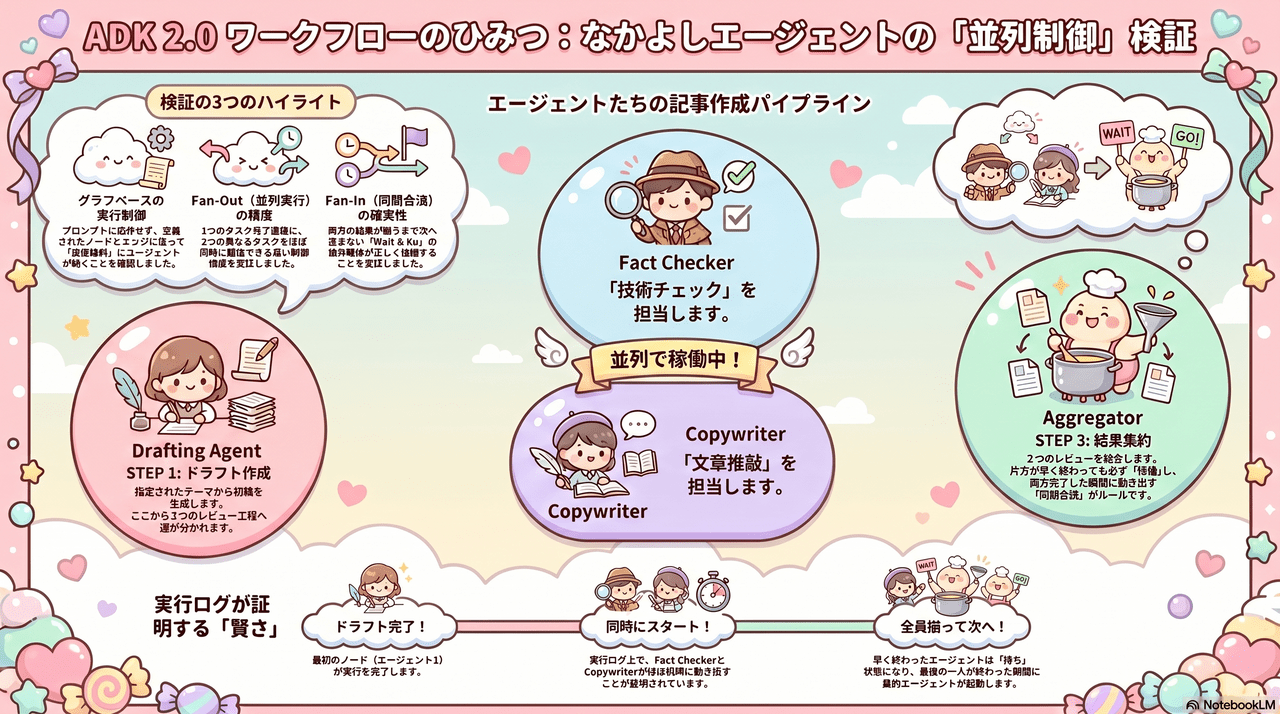
2. 構築するグラフ構造
今回は、効率的なコンテンツ制作を支える以下のパイプラインを構築します。
- Drafting Agent (START): テーマに基づき初稿を執筆。
- Parallel Reviewers (Fan-Out): 初稿完成後、以下の2エージェントが同時に並列稼働します。
- Fact Checker: 技術的な正確性を検証。
- Copywriter: 文章のトーンや読みやすさを推敲。
- Aggregator (Fan-In): 2つのレビュー結果が出揃うのを待ち、それらを統合して最終的なフィードバックを作成します。
ADK 2.0 の Workflow では、「複数のノードが同時に完了するのを待ってから次のノードへ進む(Fan-In)」という高度な制御が非常にシンプルに記述できます。
3. 実装コード (ADK 2.0.0b1)
ADK 2.0をインストールする
pip install google-adk --pre
*ADK 2.0 はプレ GA リリースとして提供されていますが、自動的にはインストールされません。インストールオプションとして選択する必要があります。
import os
import asyncio
from google.adk.agents import Agent
from google.adk import Workflow
from google.adk.runners import Runner
from google.adk.sessions import InMemorySessionService
from google.genai import types
async def main():
# 認証とバックエンドの設定
os.environ["GOOGLE_GENAI_USE_VERTEXAI"] = "True"
# --- エージェントの定義 ---
drafting_agent = Agent(
model="gemini-2.5-pro",
name="drafting_agent",
instruction="技術ブログのドラフトを作成してください。",
)
fact_checker = Agent(
model="gemini-2.5-pro",
name="fact_checker",
instruction="技術的な正確性をレビューしてください。",
)
copywriter = Agent(
model="gemini-2.5-pro",
name="copywriter",
instruction="文章の構成や読みやすさをレビューしてください。",
)
aggregator = Agent(
model="gemini-2.5-pro",
name="aggregator",
instruction="複数のレビュー結果を統合し、最終まとめを作成してください。",
)
# --- ワークフローの構築 (グラフ定義) ---
workflow = Workflow(
name="blog_workflow",
edges=[
("START", drafting_agent),
# drafting_agent の完了後、2名を並列実行 (Fan-Out)
(drafting_agent, (fact_checker, copywriter)),
# 両方のレビュー完了を待ち、aggregator へ (Fan-In)
((fact_checker, copywriter), aggregator)
]
)
# --- 実行 ---
sessions = InMemorySessionService()
sessions.create_session_sync(app_name="blog_app", session_id="s1", user_id="u1")
runner = Runner(app_name="blog_app", agent=workflow, session_service=sessions)
new_message = types.Content(
role="user",
parts=[types.Part.from_text(text="テーマ:「BERTをDistillationして軽量化したDistilBERTについて」")]
)
async for event in runner.run_async(user_id="u1", session_id="s1", new_message=new_message):
if event.is_final_response():
print(f"[{event.agent_name}]:\n{event.content}\n")
if __name__ == "__main__":
asyncio.run(main())4. 検証結果:Fan-Out と Fan-In の挙動
実行ログを確認すると、以下の挙動が明確に見て取れます。
drafting_agentがまず動き、ドラフトを生成する。
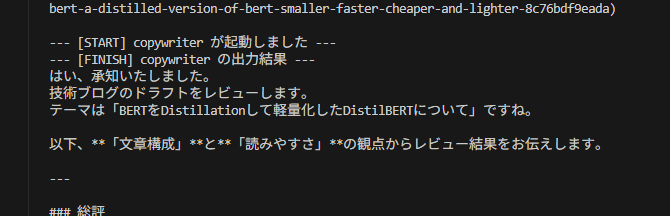
- その後、
fact_checkerとcopywriterの処理がほぼ同時に開始される。(並列実行の確認)
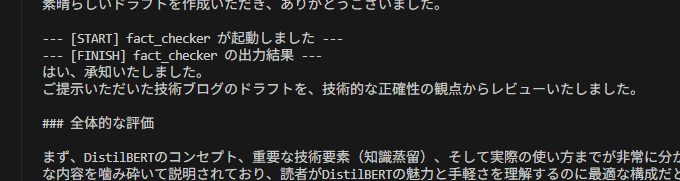
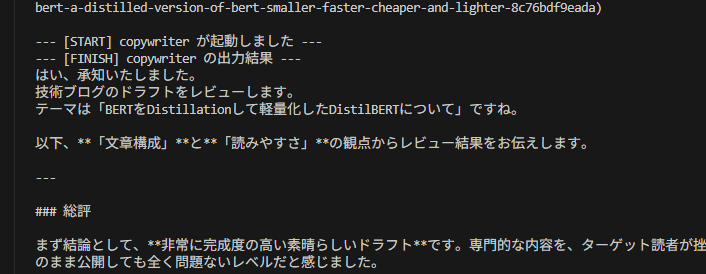
- 重要なポイント: どちらか片方が早く終わっても、
aggregatorは即座には起動しません。両方のレビュー結果が出揃った瞬間にaggregatorが起動し、統合処理を開始しました。
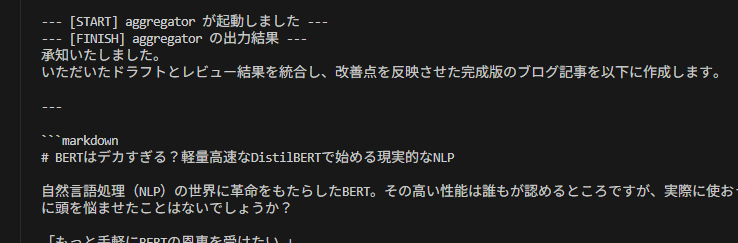
このように、ADK 2.0 の Workflow を使えば、複雑な依存関係を持つエージェント・オーケストレーションを、直感的かつ確実に実装できることが分かりました。
参考. 実際の出力結果(blog_article.md)
承知いたしました。ご提示いただいたドラフトと、非常に的確で質の高いレビュー結果を統合し、完成版のブログ記事を作成します。レビューでご指摘いただいた修正点と、記事の完成度をさらに高めるためのご提案をすべて反映させました。—# DistilBERT: BERTを軽量化した高効率モデルを徹底解説!自然言語処理(NLP)の世界で大きな変革をもたらしたBERTですが、その巨大なモデルサイズと計算コストは、多くの実用的なアプリケーションにとって高いハードルとなっていました。そんな中、性能を維持しつつ、より軽量で高速なモデルとして登場したのが**DistilBERT**です。この記事では、そんなDistilBERTの魅力に迫ります。– DistilBERTって何?BERTと何が違うの?– どんな仕組みで軽量化を実現しているの?– 実際にどうやって使うの?といった疑問に、初心者にも分かりやすく答えていきます。## DistilBERTとは?**DistilBERT**は、Hugging Face社によって開発された、BERTを軽量化したモデルです。その名前は「Distilled BERT(蒸留されたBERT)」に由来します。主な特徴は以下の通りです。– **BERTより40%小さいモデルサイズ**– **60%高速な推論速度**– **BERTの性能の97%を維持**これにより、リソースが限られた環境(例えば、スマートフォンなどのエッジデバイス)でも、BERTに匹敵する高性能な言語モデルを利用することが可能になりました。## コア技術「知識蒸留(Knowledge Distillation)」DistilBERTの軽量化を実現している核心技術が**知識蒸留**です。これは、巨大で高性能な「**教師モデル**(Teacher Model)」が持つ知識を、より小さく軽量な「**生徒モデル**(Student Model)」に転移させる手法です。*(画像出典: Hugging Face)*DistilBERTでは、教師モデルとしてオリジナルの**BERT**を、生徒モデルとしてアーキテクチャを小さくした**DistilBERT**を用いて学習が行われます。この学習プロセスでは、単に正解ラベルを学習させるだけでなく、「教師モデルの出力(振る舞い)」そのものを真似るように学習します。そのために、以下の3つの損失関数を組み合わせて最適化が行われます。### 1. Distillation Loss (蒸留損失)教師モデルが予測する確率分布(各単語がどれくらいの確率で出現するか)を、生徒モデルが模倣するように学習するための損失です。これにより、正解ラベルだけでは得られない「知識の機微(例:「A」が正解だが、「B」もかなりもっともらしい)」を学習できます。学習にはKLダイバージェンスが用いられます。(より厳密には、教師モデルと生徒モデルの出力を温度Tで平滑化したソフトマックス確率分布間のクロスエントロピーを計算しており、これはKLダイバージェンスを最小化することと等価です。)### 2. Masked Language Model Loss (MLM損失)これはオリジナルのBERTでも用いられていた損失で、文章中の一部の単語をマスク(隠し)、それを予測させるタスクの損失です。DistilBERTは、教師から学ぶだけでなく、このタスクを通じて言語そのものも学習します。### 3. Cosine Embedding Loss (コサイン埋め込み損失)教師モデルと生徒モデルの隠れ層の出力ベクトル(各単語の意味を表現するベクトル)の方向が、できるだけ近くなるように学習するための損失です。これにより、生徒モデルが教師モデルと同じような内部表現を持つことを促します。これら3つの損失を組み合わせることで、DistilBERTは小さいながらもBERTの豊かな表現力を受け継ぐことができるのです。## アーキテクチャの変更点知識蒸留に加えて、DistilBERTはモデルのアーキテクチャ自体もシンプルにすることで、軽量化・高速化を実現しています。– **Transformerのレイヤー数を半減**– BERT-baseの12層から**6層**に削減。これによりパラメータ数が大幅に削減されました。– **Token-type Embeddingsを削除**– 文章の区別をするためのToken-type Embeddingsを削除しました。(これは、BERTの事前学習で用いられた2つの文の関係性を予測するタスク(NSP)が、DistilBERTでは採用されなかったためです。)– **Pooling Layerを削除**– 文章全体のベクトル表現を得るためのPooling Layerをなくし、代わりに最初のトークンである`[CLS]`トークンの隠れ状態ベクトルを使用します。これらの工夫により、計算量を大幅に削減しつつも、性能の劣化を最小限に抑えています。## Hugging Face Transformersで使ってみようそれでは、実際にHugging Faceの`transformers`ライブラリを使ってDistilBERTを動かしてみましょう。BERTを使ったことがある方なら、モデル名を変更するだけで驚くほど簡単に利用できます。“`python# 必要なライブラリをインストール# !pip install torch transformersimport torchfrom transformers import DistilBertTokenizer, DistilBertModel# 1. モデルとトークナイザの読み込み# モデルは’distilbert-base-uncased’(英語、小文字区別なし)を使用tokenizer = DistilBertTokenizer.from_pretrained(‘distilbert-base-uncased’)model = DistilBertModel.from_pretrained(‘distilbert-base-uncased’)# 2. テキストの準備とトークナイズtext = “Hello, this is a blog about DistilBERT.”inputs = tokenizer(text, return_tensors=’pt’) # PyTorchのテンソル形式で返す# 3. モデルによる推論with torch.no_grad(): # 勾配計算を無効化して計算量を削減outputs = model(**inputs)# 4. 結果の確認input_ids = inputs[‘input_ids’]last_hidden_state = outputs.last_hidden_stateprint(f”Input text: {text}”)print(f”Input IDs shape: {input_ids.shape}”)print(f”Last hidden state shape: {last_hidden_state.shape}”)# 実行結果# Input text: Hello, this is a blog about DistilBERT.# Input IDs shape: torch.Size([1, 13])# Last hidden state shape: torch.Size([1, 13, 768])“`### コード解説– **`DistilBertTokenizer`**: テキストをモデルが理解できるIDのシーケンスに変換します。– **`DistilBertModel`**: トークン化されたIDを入力として受け取り、各トークンの隠れ状態(文脈を考慮したベクトル表現)を出力します。– **`input_ids.shape`**: `[1, 13]`は、バッチサイズ1、トークン数13(`[CLS]`、`hello`、`,` … `[SEP]`)を意味します。– **`last_hidden_state.shape`**: `[1, 13, 768]`は、バッチサイズ1、トークン数13、各トークンのベクトル次元数768を意味します。このベクトルが、後続のタスク(分類、質問応答など)への入力となります。このように、数行のコードで簡単にDistilBERTの力を借りることができます。## まとめDistilBERTは、**知識蒸留**という賢い手法とアーキテクチャの簡素化により、**「軽量・高速・高性能」** を実現した画期的なモデルです。– **計算リソースを抑えたい**– **リアルタイム性が求められるアプリケーションを開発したい**– **手軽に高性能なNLPモデルを試したい**といった場合に、DistilBERTは非常に強力な選択肢となります。ぜひ、あなたの次のプロジェクトでこの素晴らしいモデルを活用してみてください。Happy Developing
最後に
今回は『Agent Development Kit (ADK) 2.0』について実際のデモともにご紹介させていただきました。
エージェントの連携を**グラフ(ノードとエッジ)**として明示的に定義する。 そんなデモを実感頂けたと思います。
ADK 2.0 (v2.0.0b1) へのアップデートにより、Workflow クラスという強力な武器が加わりました。 プロンプトのみで制御していた 1.x 以前に比べ、グラフ構造による確実なフロー制御が可能になったことで、エンタープライズレベルの複雑な業務パイプライン構築がより現実的になります。
今後とも、AIMLに関する情報やGoogle CloudのAIMLサービスのアップデート情報を掲載していきたいと思います。
最後まで読んでいただき、ありがとうございました!!!