

 本記事は TechHarmony Advent Calendar 2025 12/16付の記事です。 本記事は TechHarmony Advent Calendar 2025 12/16付の記事です。 |
こんにちは。SCSKの さと です。
2025年のre:Inventは何が印象に残ったでしょうか。DevOps Agent?新しいSecurity Hub?あるいはDr. Werner Vogelsの最後のKeynoteでしょうか。
さて、今回はre:Inventで発表された自動推論チェックについてご紹介します。とはいっても2024年のre:Inventです。本機能は長らくプレビュー状態で申請をしないと利用できない状態だったのですが、8月ごろにGAとなっていたため、触ってみました。
Amazon Bedrock Guardrails 自動推論チェック

自動推論チェック機能はBedrockのガードレールポリシーの一つとして追加され、大規模言語モデル(LLM)によって生成される出力を検証可能な推論エンジンを用いて評価し、応答の正確性を検証するものです。
自動推論は人工知能の一分野として長年研究されてきた技術であり、統計モデルを用いる機械学習とは異なり、論理式やルールに基づく推論を用いて結論を導きます。推論過程が明確で説明可能性が高いことから、高い信頼性が求められる領域で有効です。
AWSではすでにIAM Access Analyzerなどで自動推論の技術が使われてきましたが、今回は同様の技術がBedrock Guardrailsに取り込まれ、最大99%の検証精度が実現されると宣伝されています。
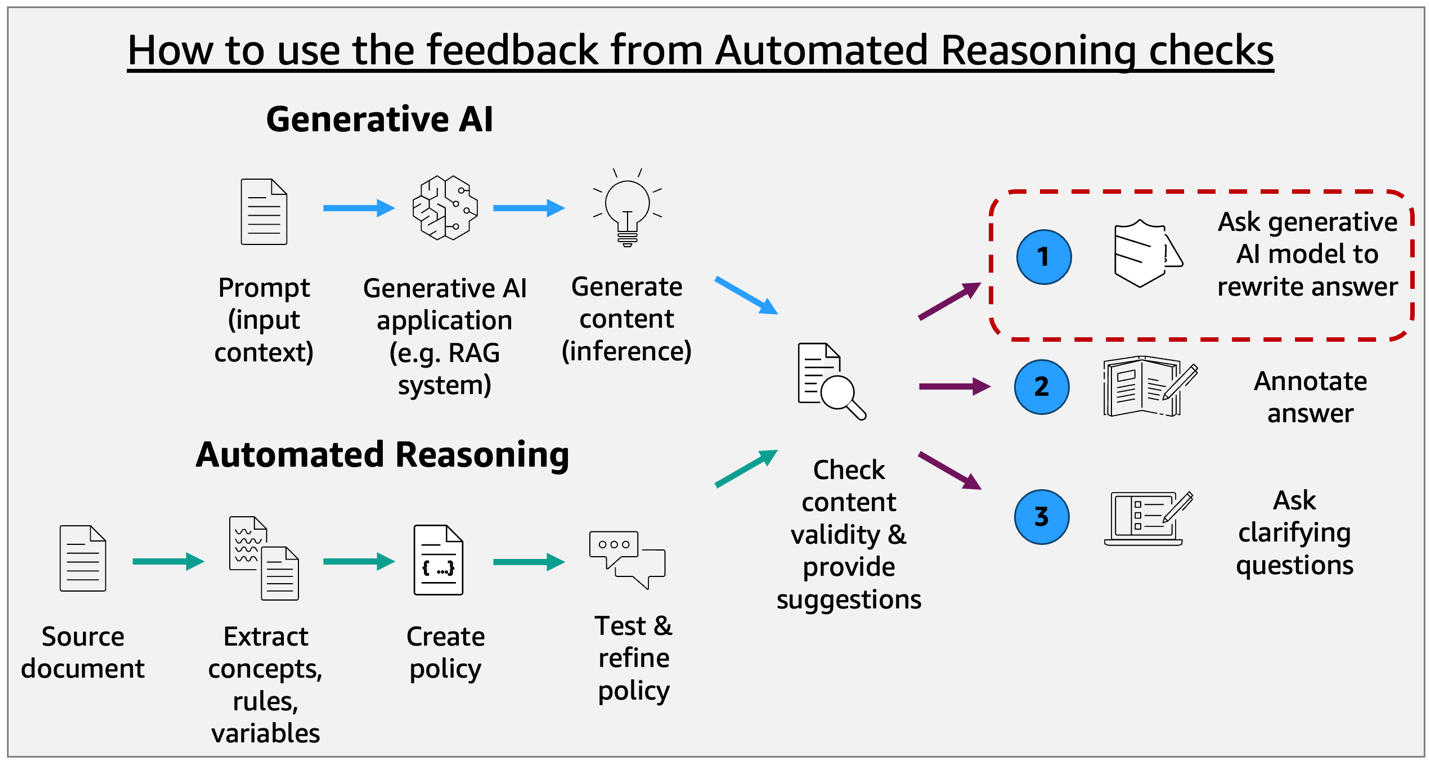
ユーザーが自然言語でドキュメントをソースとして読み込ませると、サービスはドキュメントからルールを抽出し、ポリシーを生成します。自動推論チェックでは、LLMの応答とポリシーを照合し、以下の検証結果を返します。
| 結果タイプ | 説明 |
| VALID | 入出力の組をポリシーから導くことができ、さらに矛盾するポリシーが存在しない |
| INVALID | 入出力の組に対して明確に矛盾するポリシーがある |
| SATISFIABLE | 他の条件によっては入出力が真とも偽ともなりうる |
| IMPOSSIBLE | 入出力に含まれる前提がポリシーと矛盾している、またはポリシー同士で論理的な競合が起こっている |
| NO_TRANSLATIONS | 入出力がポリシーと無関係等の理由により、入力の一部または全てが形式的な表現に変換できなかった |
| TRANSLATION_AMBIGUOUS | 入出力が曖昧なため適切に形式論理として解釈できず、さらに質問をするなどで追加情報が必要 |
| TOO_COMPLEX |
入出力が複雑であり、有効な時間内に回答できない |
なお、記事執筆時点において自動推論チェックは検出モードのみをサポートしており、このためLLMの回答に対してINVALIDと判定された場合であっても自動で回答がブロックされることはありません。このため、無効と判定された回答に対して再生成を促すワークフローを組むなど、適宜ユーザー側で実装が必要である点については留意が必要です。
実際に使ってみた
というわけで、本記事ではカスタムのドキュメントを読み込ませ、生成されるポリシーをテストするところまで実際に行ってみようと思います。今回は成績を評価するためのルールをChatGPTに作ってもらいました。(実際にはこちらを英訳したものを読み込ませています)
ドキュメントのアップロード
自動推論のコンソールで「ポリシーを作成」をクリックし、ソースとなるドキュメントをアップロードします。その下には、ドキュメントの説明を入力する欄があります。こちらの入力は任意ですが、入力された情報はルールの抽出処理で使われるため、どのようなドキュメントなのか、どのような質問が想定されるのかを書いておくことが公式ドキュメントで推奨されています。
ドキュメントからポリシーを抽出するのに数分待ったあと、抽出されたポリシーの定義が表示されます。ポリシーは、ドキュメントに登場する主要な概念を表す変数、変数間の論理的関係を規則の形式として表すルール、変数がブール型・数値型のいずれでもない場合に取りうる値を規定するカスタム型から構成されます。
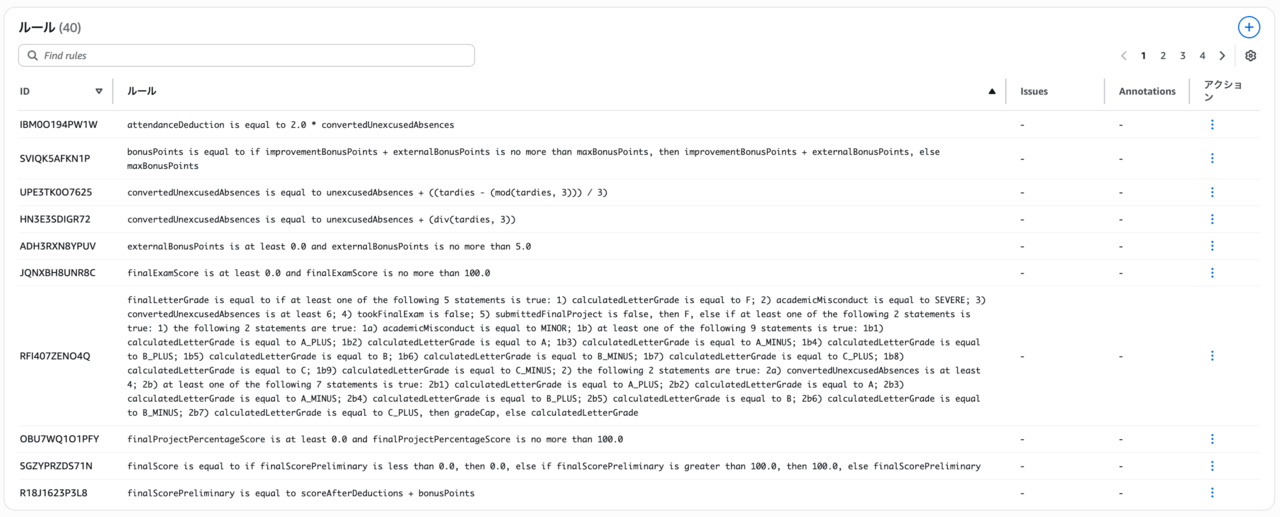
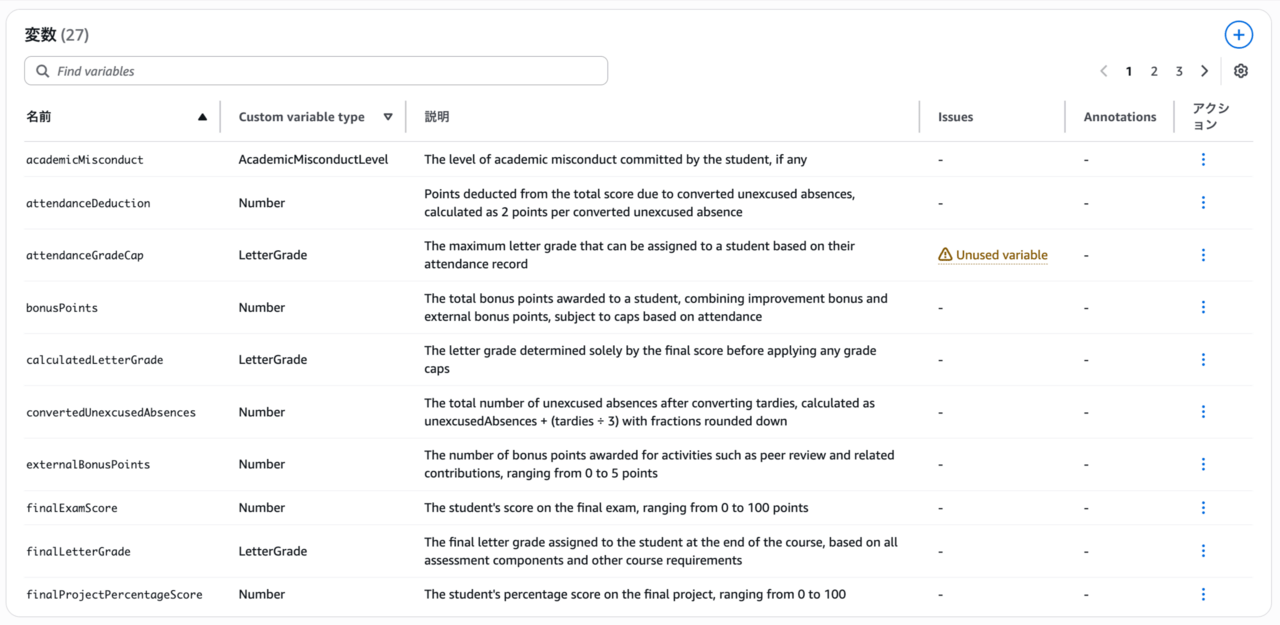

ポリシーのテスト
ポリシーの生成と同時に、ポリシーがドキュメントの内容を正しく反映しているか検証するためのテストケースも自動で生成してくれます。これに加えて、テストケースを追加で生成、あるいはユーザー自身で作成することも可能です。
今回は次のようなテストケースを作成しました。軽微な不正行為により、成績が最大でもDになるというシナリオです。
関連するルール
一定の条件に当てはまる場合、点数が高くても評定の上限がかかります(上げる方向には働きません)。
9.1 軽微な学術不正
軽微な学術不正(不適切な引用等)がある場合、最終評定は 最大でもD です。
※点数が60未満ならFのままです。
9.2 出席キャップ
換算無断欠席が4回以上の場合、最終評定は 最大でもC です。
(本来C+以上になる点数でもCまでに制限されます)
出力: Dです。
期待される評価結果: Valid
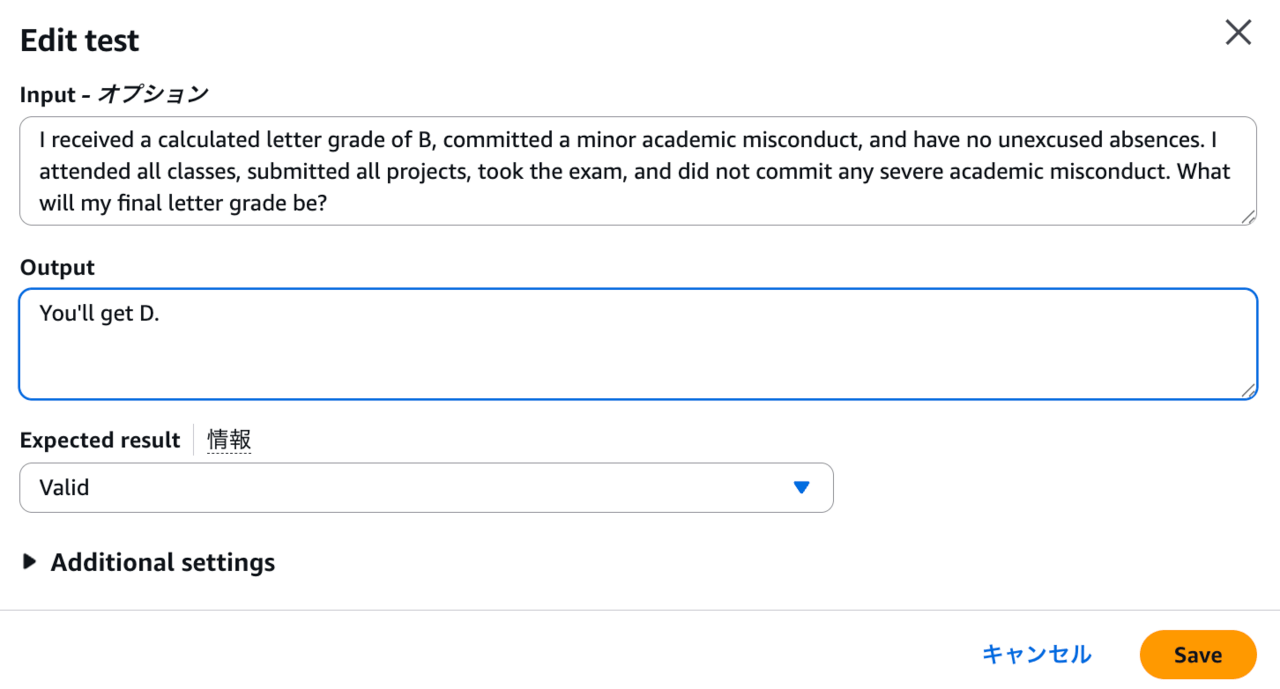
テストケースを保存すると、自動で評価が走ります。結果を見ると、本来応答が正しい(Valid)と判定されるべきところをSatisfiable、すなわち「応答結果が有効とも無効ともなりうる」と判断されて失敗してしまったようです。
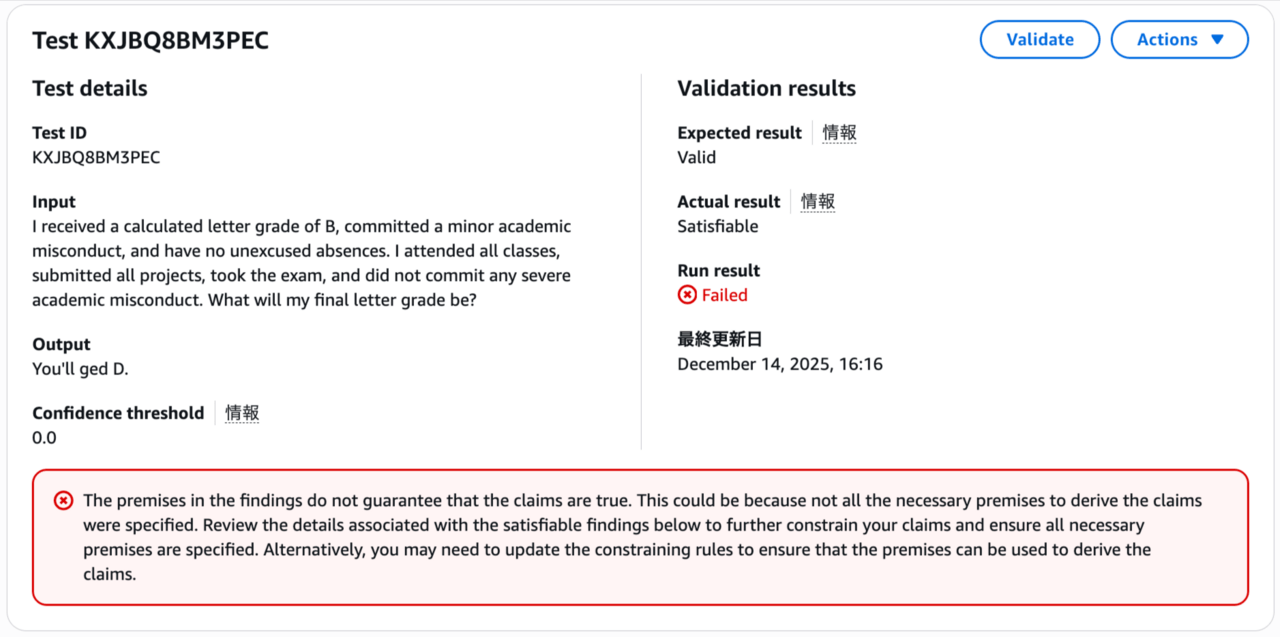
詳細を開くと、どのようなシナリオで失敗しているかを確認することができます。今のルールでは、与えられた条件から、今回はDで確定されるべきfinalLetterGradeがBとなりうると導かれてしまっているようです。

ポリシーの修正
テスト結果から想定されない最終評定が導かれてしまっていることが分かったため、ポリシーを修正していきます。最終評定(finalLetterGrade)が関係するルールを検索すると、以下のようなものがありました(実際のルールを日本語に読み下しています)。
- 以下のいずれかに該当する場合、最終評定をFとする。
- 暫定の評定がF・重大な不正を行った・6回以上欠席した・期末試験を受験していない・最終課題を提出していない
- 1に当てはまらず、以下の場合は、最終評定を上限評定(gradeCap)とする。
- 暫定の評定がC-以上で軽微な不正を行った場合
- 暫定の評定がC+以上で4回以上欠席した場合
- 上記のいずれにも当てはまらない場合、暫定の評定がそのまま最終評定となる。
実際のルール
finalLetterGrade is equal to:
if at least one of the following 5 statements is true:
1) calculatedLetterGrade is equal to F
2) academicMisconduct is equal to SEVERE
3) convertedUnexcusedAbsences is at least 6
4) tookFinalExam is false
5) submittedFinalProject is false
then F
else if at least one of the following 2 statements is true:
1) the following 2 statements are true:
1a) academicMisconduct is equal to MINOR
1b) at least one of the following 9 statements is true:
1b1) calculatedLetterGrade is equal to A_PLUS
1b2) calculatedLetterGrade is equal to A
1b3) calculatedLetterGrade is equal to A_MINUS
1b4) calculatedLetterGrade is equal to B_PLUS
1b5) calculatedLetterGrade is equal to B
1b6) calculatedLetterGrade is equal to B_MINUS
1b7) calculatedLetterGrade is equal to C_PLUS
1b8) calculatedLetterGrade is equal to C
1b9) calculatedLetterGrade is equal to C_MINUS
2) the following 2 statements are true:
2a) convertedUnexcusedAbsences is at least 4
2b) at least one of the following 7 statements is true:
2b1) calculatedLetterGrade is equal to A_PLUS
2b2) calculatedLetterGrade is equal to A
2b3) calculatedLetterGrade is equal to A_MINUS
2b4) calculatedLetterGrade is equal to B_PLUS
2b5) calculatedLetterGrade is equal to B
2b6) calculatedLetterGrade is equal to B_MINUS
2b7) calculatedLetterGrade is equal to C_PLUS
then gradeCap
else calculatedLetterGrade
一見してルールが正しく反映されてそうですが、よく見ると他のルールでgradeCapの値がどうなるか定義されておらず、どのような値でも正しいと評価されてしまう状態となっていました。
ポリシーの修正も自然言語で行うことができます。今回は、以下のように上限評定(gradeCap)を定義するルールを追加しました。
If academicMisconduct = MINOR, then gradeCap = D.
Else if convertedUnexcusedAbsences >= 4, then gradeCap = C.
Otherwise, gradeCap = A_PLUS.
 再度評価を実行し、結果がValidとなることを確認できました。
再度評価を実行し、結果がValidとなることを確認できました。
まとめ
いかがだったでしょうか。確率的な応答をする生成AIに対して、推論システムの力を借りて説明可能性を高めるというアプローチは魅力的な一方、今回のハンズオンを通じて分かったように、生成されたポリシーを手放しでデプロイできる、というまではまだ難しいようです。
実は、今回のハンズオンでは一部AWSの定めるベストプラクティスから外れた部分があります。
AWS公式の自動推論に関するドキュメントでは、まずは核となる最小限のポリシーを生成し、そこから十分なテストを繰り返しながら段階的にルールを付け加えていくことを推奨しています。だからこそ、コンソール上でテストを行い、結果を反映させるための機能が充実している点も触ってみる中で強く印象に残りました。
ここまでお読みいただきありがとうございました。よい年をお迎えください。