

SCSK三上です。
AWS Certified Data Analytics Specialtyを受験し、分野ごとに抑えておいた方が良い点まとめました。
今回は、Storage(格納)・Processing(処理)編です!
Storage(格納)
AWS S3
- ストレージクラス
- S3 Standard – General Purpose
- 頻繁にアクセスされるデータ向け
- S3 Standard – Infrequent Access (IA)
- 存続期間が長くあまり頻繁にアクセスされないデータ向け
- スタンダードよりは安い
- S3 One Zone – Infrequent Access
- 存続期間が長くあまり頻繁にアクセスされない、かつ重要度の低いデータ向け
- データ取り出し費用:あり
- 標準(IA)より20%安い
- S3 Intelligent Tiering
- アクセスパターンが変化、または不明な存続期間が長いデータ向け
- データ取り出し費用:あり
- スタンダードとレイテンシーやスループットパフォーマンスは同じ
- Glacier
- 取得時間が数分から数時間許容される長期アーカイブデータ向け
- データ取り出し費用:あり
- Glacier Deep Archive
- 取得時間が12時間許容される長期アーカイブデータ向け
- データ取り出し費用:あり
- S3 Standard – General Purpose
- S3 Multi-Part upload
- S3に大きなサイズのファイルをアップロードする際に使用する。
- アップロードするファイルをいくつかに分割(断片ファイル)し、断片ファイルをそれぞれS3にアップロードした後に、S3側で一つのファイルに結合する機能。
- 100MB以上のオブジェクトの場合は、マルチアップロード機能を使うことを検討する。
- S3 Transfer Acceleration
- 海外リージョンなど、送信元から遠く離れたS3へのデータ転送をAWSのエッジロケーションとネットワークプロトコルの最適で高速化するサービス。
- ユースケース
- 世界中からアップロードが行われるケース
- 大陸間で定期的にGB~TBのデータを転送するケース
- 暗号化
- SSE-S3
- AWSが管理する鍵を使用して暗号化する方法。
- AES256を使用。
- SSE-KMS
- AWS KMSで管理されている鍵を使用して暗号化する方法。ユーザ毎に別の鍵を利用することも可能。
- 鍵のアクセス権限の管理や、利用履歴などを確認することも可能。
- SSE-C
- ユーザが作成した鍵をAWSに送信し、AWSで暗号化する方式。
- AWSでは暗号化後、秘密鍵を破棄して公開鍵のみ保持することで第三者の復号を防ぐ。
- HTTPSのみ対応!
- クライアントサイドの暗号化
- クライアントがキーと暗号化サイクルを完全に管理する。
- ユースケース
- S3に送信する前に、クライアントはデータを暗号化する必要がある。
- S3からデータを取得する場合、クライアントはデータ自体を復号化する必要がある。
- SSE-S3
- S3 イベント通知
- S3のイベント通知を利用して、SNS、SQS、Lambda関数を呼び出すことが可能。
Amazon DynamoDB
- DynamoDB Stream
- DynamoDBテーブル内の項目レベルの変更の時系列シーケンスをキャッチアップし、情報を最大24時間ログに保管する。暗号化は、DynamoDB Streamのデータが暗号化される。
- ストリームを有効すると、DynamoDBはテーブル内のデータ項目に加えられた各変更に関する情報をキャプチャする。
- アプリがテーブル内の項目を作成・更新・削除するたびにDynamoDB Streamは変更された項目のプライマリーキー属性を付けて、ストリームコードを書きこむ。変更履歴を保持し、取り出しが可能になる。
- 過去24時間以内にそのテーブルのデータに対して行われた変更のストリームすべてにアクセス可能。24時間経過後は削除され、容量は自動的に管理される。
- 非同期に動作するため、パフォーマンス影響はない。
- DynamoDB – DAX
- DynamoDBと互換性のあるフルマネージド型のインメモリキャッシュサービス。レスポンスをミリ秒単位からマイクロ秒単位まで高速化することが可能。
- ホットキーなど解決する。デフォルトでキャッシュは5分間維持される。
- プロビジョニングスループット
- テーブルに対するデータのWrite/Readスループットがキャパシティユニットを超えると、クライアントに対して「ProvisionedThroughputExceededException」エラーを返却する。
- DynamoDB キャパシティユニット
- キャパシティユニットとは1秒間に処理できるデータ量の単位のこと。
- 書き込みキャパシティユニット(WCU)
- 1WCUで1秒間で1KBまで書き込みが可能。少数刻みは指定できない。
- 読み込みキャパシティユニット(RCU)
- 結果整合性のある書き込み
- 書き込みが成功してもそれが反映された最新データが取れる保証はない。デフォルト。
- 1RCUで1秒間に4KBの読み込みを2回行うことが出来る。つまり、1秒間で最大8KB読み込み可能。
- 1秒間に16KBを読み込みたい場合は、2RCUを指定する必要がある。
- 強力な整合性のある読み込み
- 最新データが反映した結果を取得可能。
- 1RCUで1秒間に4KBの読み込みを1回行うことが出来る。1秒間に16KBを読み込みたい場合は、4RCUを指定する必要がある。
- 結果整合性のある書き込み
- セカンダリインデックス
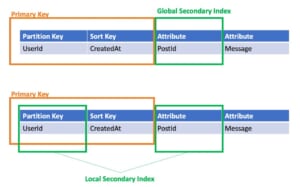
- GSI
- 全データの中からPodtIdを指定して抽出
- LSI
- あるUserIdの中からPostIdを指定して抽出
Amazon ElastiCache
NoSQLデータをメモリ上にキャッシュして格納することで高速化を図るサービス。
- Memcached
- インメモリのキーバリュー型データを格納するためのキャッシュサーバ。
- シンプルなデータモデルで複数スレッドで構成されたインスタンスを実行する必要がある場合や、システム不可の増減に応じたスケールアウトとスケールインが必要な場合はコチラを選択する。
- ユースケース
- 単純なデータ型で良い時
- マルチスレッドを使用する場合
- オブジェクトをキャッシュする必要がある場合
- Redis
- ユースケース
- 複雑なデータ型が必要な場合
- フェイルオーバが必要な場合
- 永続化が必要な場合
- ユースケース
Processing(処理)
AWS Lambda
- サポートしている言語
- Node.js
- Python
- Java
- C#
- Go
- Powershell
- Ruby
- アンチパターン
- 長時間実行されるアプリ
- EC2を代わりに使う
- ダイナミックなウェブサイト
- ステートフルなアプリ
- 長時間実行されるアプリ
AWS Glue
- ジョブマーク
- 古いデータの再処理を防止し、差分を抽出する。
- アンチパターン
- 複数のETLエンジン
- Sparkベースなので、Hive、Pigなど使いたければEMRが良い。
- 複数のETLエンジン
- 開発エンドポイント
- ノートブックでETLのスクリプトを開発出来るような仕組み。
AWS Lake Formatoin
データレイクのアクセス制御
Amazon EMR
EC2上にHadoopを管理する。
- ユースケース
- リアルタイム性が要求される場合
- 多様な分析手法を用いる
- 大規模なデータを扱う機会学習
- ETLやクレンジング
- マスターノード
- クラスターを管理する。
- タスクのステータスやモニタリングする機能。
- リーダーノードともいわれる。
- コアノード
- タスクを実行し、クラスター上のHDFSにデータを保持するコンポーネントを持つ。
- スケールアップ・ダウン可能だが、リスクあり
- マルチノードクラスターには、最低1つのコアノードが必要。
- タスクノード
- タスクを実行するのみ。
- HDFSにデータを保持しない。
- スポットインスタンスに最適。
- オプション
- HDFS
- Hadoopのファイルシステム
- EMRFS
- HDFSのようにS3にアクセスする
- Hadoop
- オープンソースのフレームワーク
- Spark
- Hadoopよりも大幅に高速に処理が可能
- Hive
- Hadoop上に構築されたデータウェハウス構築環境で、SQLライクなHiveSQLを使ってデータの集約・問い合わせ・分析が可能。
- HBase
- ≒DynamoDB
- インメモリ型
- Presto
- ペタバイトスケールの対話型クエリ
- Athenaの配下で使われている。
- Apache Zeppelin
- Jupyter Notebookと同じようなWebアプリケーション。画面上でSparkのコードを記述することができ、実行結果もまとめて残しておくことが出来る。処置を書いてその場で実行できる。
- SparkやZeppelinはEMRによってHadoopクラスタ上に自動的にセットアップすることが可能。
- Hue
- WebUI
- Hadoopユーザのエクスペリエンス
- S3とHDFS間でのデータの参照と移動が可能。
- Splunk
- ログをリアルタイムに収集・蓄積して、柔軟かつ複雑な検索および分析を得意とする統合ログ管理ソフトウェア。
- 操作ツールはEMR Hadoopを使用してEMRおよびS3データを可視化するために使用することが可能。
- Flume
- 大量のログデータを効率的に収集・集約・移動することを目的に開発された高い信頼性と可用性を持つ分散型のサービス。クラスタ内の各マシンのログファイルを収集して、Hadoop HDFSなどの中央の永続的ストアに集約するロギングシステムを構築できる。
- S3DistCP
- DistCpを拡張したもので、S3からHDFSに大量のデータを効率的にコピーできる。HDFSからS3へのデータコピーも可能。
- EMR インスタンスタイプ
- マスターノード
- 50ノード以下:m5.xlarge
- 50ノード以上:m4.xlarge
- コア&タスクノード
- m5.xlarge
- マスターノード
他の分野のメモ
他の分野のメモはこちらです。
概要編

【AWS認定】AWS Certified Data Analytics Specialty学習メモ特集① ~概要編~
過去に受験したAWS Certified Data Analytics Specialtyの勉強方法をまとめていきたいと思います。
本記事は勉強方法と概要です。
blog.usize-tech.com
2022.05.30
Collection(収集)編
【AWS認定】AWS Certified Data Analytics Specialty学習メモ特集③ ~Collection(収集)編~
AWS Certified Data Analytics Specialtyを受験し、分野ごとに抑えておいた方が良い点まとめました。
今回は、Collection(収集)編です!
blog.usize-tech.com
2022.05.30
Analytics(分析)/Visualization(可視化)編
【AWS認定】AWS Certified Data Analytics Specialty学習メモ特集④ ~Analytics(分析)/Visualization(可視化)編~
AWS Certified Data Analytics Specialtyを受験し、分野ごとに抑えておいた方が良い点まとめました。
今回は、Analytics(分析)、Visualization(可視化)編です!
blog.usize-tech.com
2022.05.30
皆様のお役に立てば幸いです。
よろしくお願いします。