

こんにちは!SCSKの山口です。
二連続のBigQuery に関するブログ投稿になります。
今回は、業務で使用する機会のあった「BigQuery Migration Service」が便利だと感じたのでご紹介します。
BigQuery Migration Serviceの概要

BigQuery Migration Serviceは、”データ ウェアハウスを BigQuery に移行するための包括的なソリューション”です。
10を超える言語からのSQL変換が可能であり、データ転送、データ検証などのツールも用意されています。

今回はこのBigQuery Migration Serviceを用いて“SQLの変換”を実際にやってみたいと思います。
BigQuery Migration Serviceを使ってNetezzaからBigQueryへクエリを移行してみる
Netezza 用に作成されたSQLスクリプトは、そのままではBigQuery で使用することができません。
そのため、データウェアハウスをBigQuery へ移行した後もSQLスクリプトを使用したい場合は、”クエリの変換”が必要となります。
ここでは以下の簡単なNetezzaのSQL文を移行してみます。
[Netezza _Example]
CREATE TABLE "hoge_dataset.yamaguchi_test.TEST_TABLE2" ( class INTEGER not null, name NATIONAL CHARACTER(20), age INTEGER, height INTEGER, weight INTEGER )|
[Netezza _Example2]
SELECT
class,
name
FROM
"hoge_dataset.yamaguchi_test.TEST_TABLE"
ORDER BY
class
;
上記2ファイルが入ったフォルダをあらかじめCloud Storageへアップロードしておきます。

① 「BigQuery Migrartion API」の有効化
BigQuery Migration Serviceを利用するために、まずは「BigQuery Migration API」を有効化します。
② 変換ジョブの作成
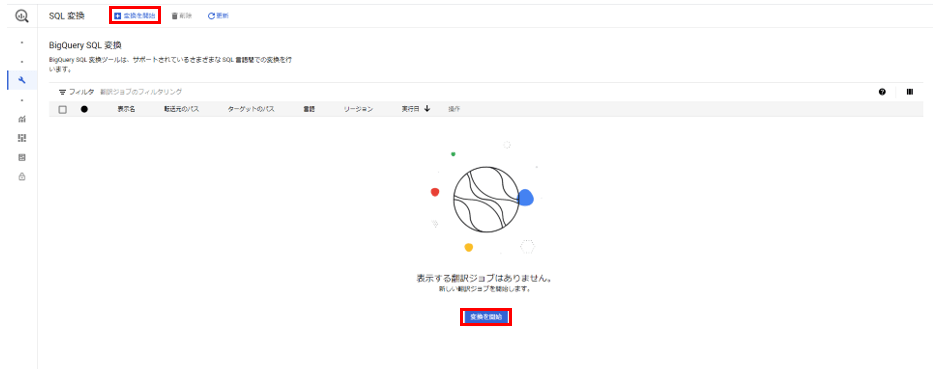
BigQueryページの左ペインより「移行-SQL変換」をクリックします。

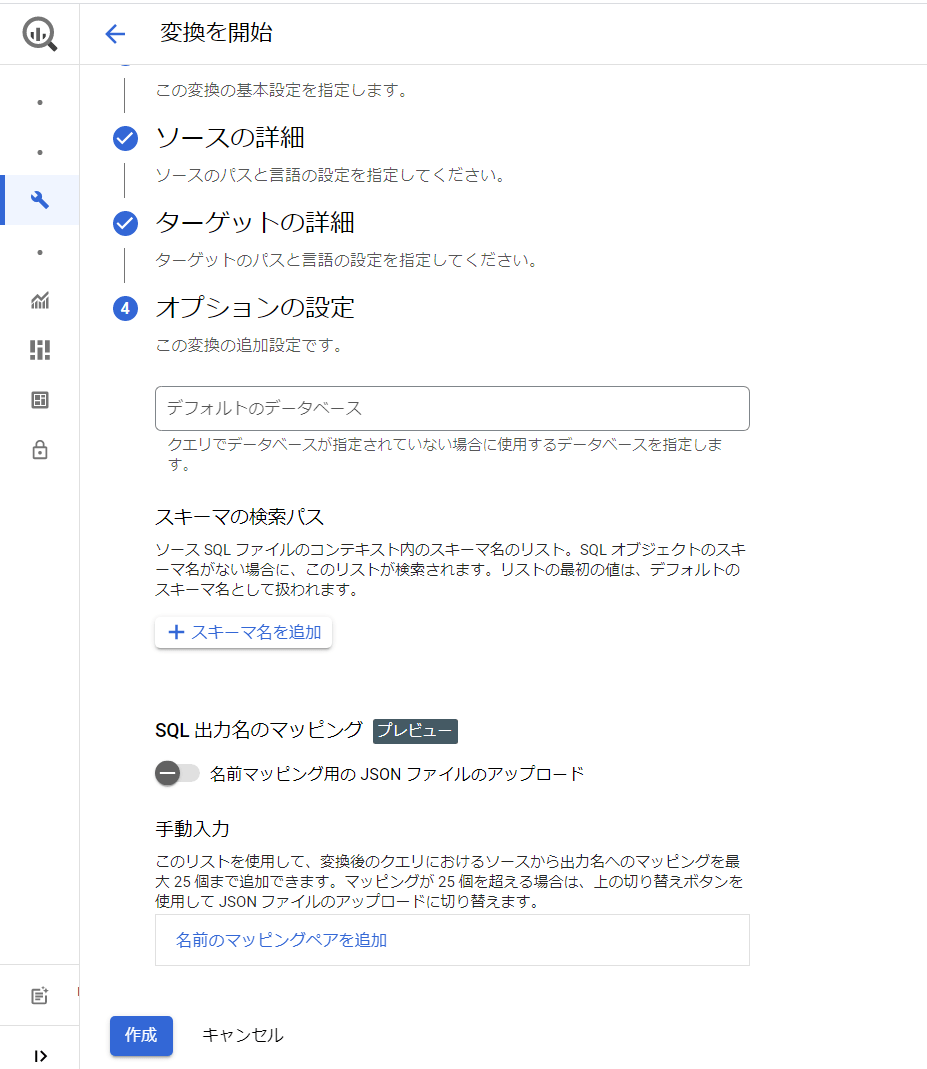
BigQuery SQL 変換ページの「変換を開始」(下図赤枠のどちらか)をクリックします。
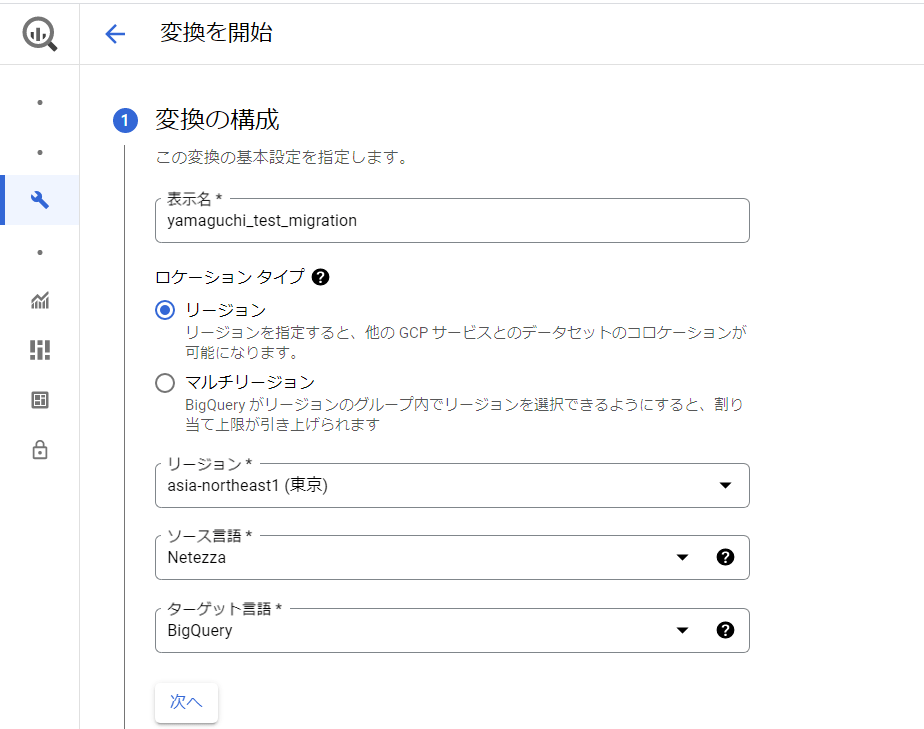
「変換の構成」を入力し、「次へ」をクリックします。
「ソースの詳細」にて変換対象のファイルが含まれるフォルダを指定し「次へ」をクリックします。

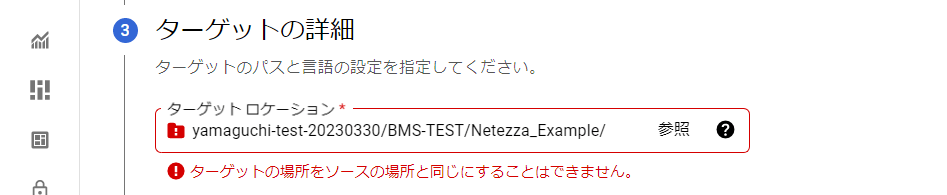
「ターゲットの詳細」にて出力される変換後のファイルの保存先を指定します。

ターゲットにはソースとは別のパスを指定する必要があります。
「オプションの設定」にて各種オプションを入力できます。(いったん空欄で実行してみます。)
最後に「作成」をクリックして完了です。
③ 変換結果確認
問題なく変換が完了したら緑のチェックマークがつきます。

ターゲットのパスに行って変換結果のクエリを確認してみましょう。
Outputのフォルダ内に変換結果のファイルが吐き出されています。
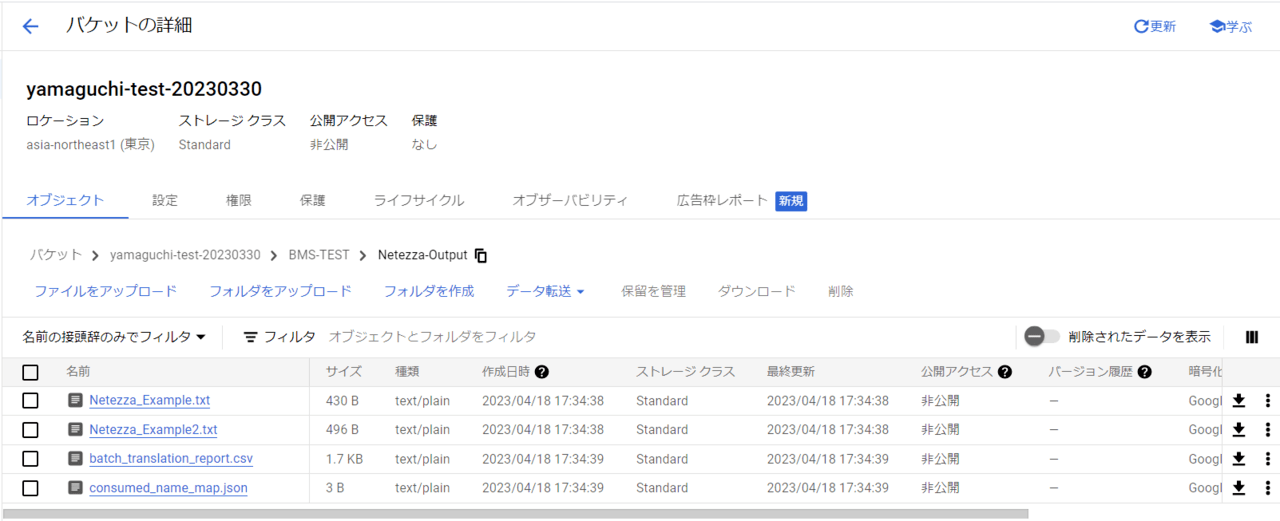
入力のファイルと見比べてみます。
| 変換前(Netezza SQL) | 変換後(GoogleSQL) | |
|---|---|---|
| Netezza_Example |
CREATE TABLE TEST_TABLE ( class INTEGER not null, name NATIONAL CHARACTER(20), age INTEGER, height INTEGER, weight INTEGER ) |
CREAte TABLE __DEFAULT_DATABASE__.__DEFAULT_SCHEMA__.TEST_TABLE ( CLASS INT64, NAME STRING, AGE INT64, HEIGHT INT64, WEIGHT INT64 ) ; |
| Netezza_Example2 |
SELECT
class,
name
FROM
TEST_TABLE
ORDER BY
class
;
|
SELTECT
TEST_TABLE.CLASS,
TEST_TABLE.NAME
FROM
__DEFAULT_DATABASE__.__DEFAULT_SCHEMA__.TEST_TABLE
ORDER BY
CLASS
;
|
一見問題なく変換できてそうですが、これ本当に回るのか、、、?と不安になったので変換後のクエリ文をBigQueryのワークスペースにコピペしてみます。
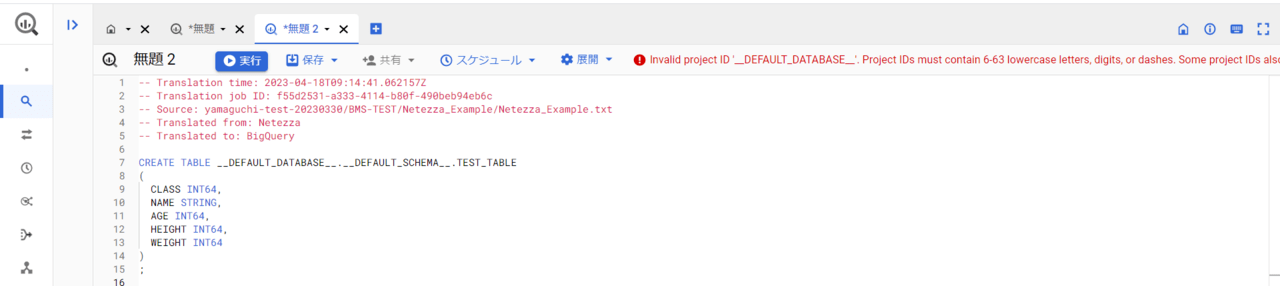
「__DEFAULT_DATABASE__と__DEFAULT_SCHEMA__なんて無いよ。」と怒られてしまいました。オプションを空欄にしたツケが回ってきたようです。
次はオプションを入力してやってみます。
④ オプションの設定を利用して変換を実行
オプションに以下を設定して再度変換を実行してみます。
- デフォルトのデータベース:プロジェクトID
- スキーマの検索パス:テーブル名

変換後のクエリは以下の通りです。
CREATE TABLE `hoge_dataset`.yamaguchi_test.TEST_TABLE ( CLASS INT64, NAME STRING, AGE INT64, HEIGHT INT64, WEIGHT INT64 ) ;
これをBigQueryのSQLワークスペースに貼り付けてみます。
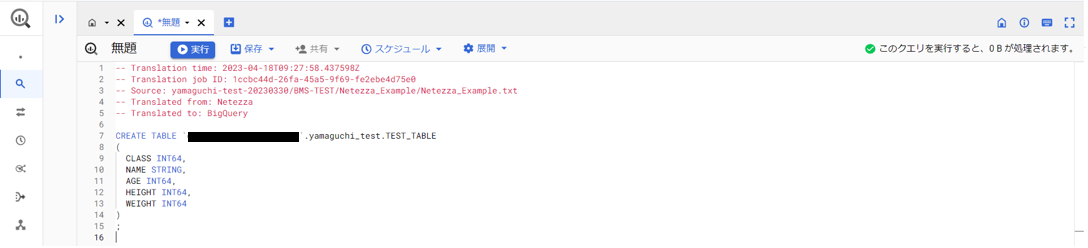
エラーが出ないので、手直しなし(貼り付けのみ)で実行できそうです。
貼り付けたクエリを実行してみます。
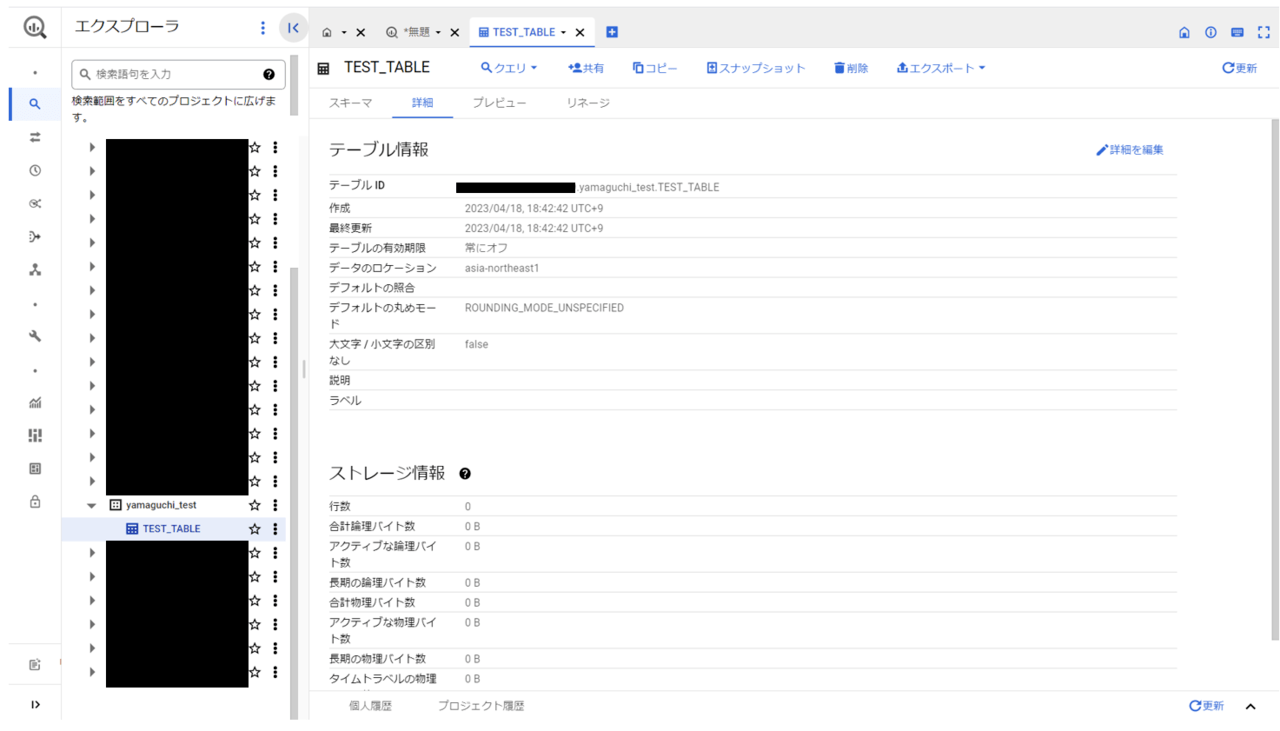
実行が成功し、テーブルが無事作成されました。
BigQueryのSQLワークスペース上でのSQL変換
実はBigQueryのSQLワークスペースでも簡単にSQL変換ができます。
先ほど作成したテーブルに下記データをあらかじめ追加しておきます。
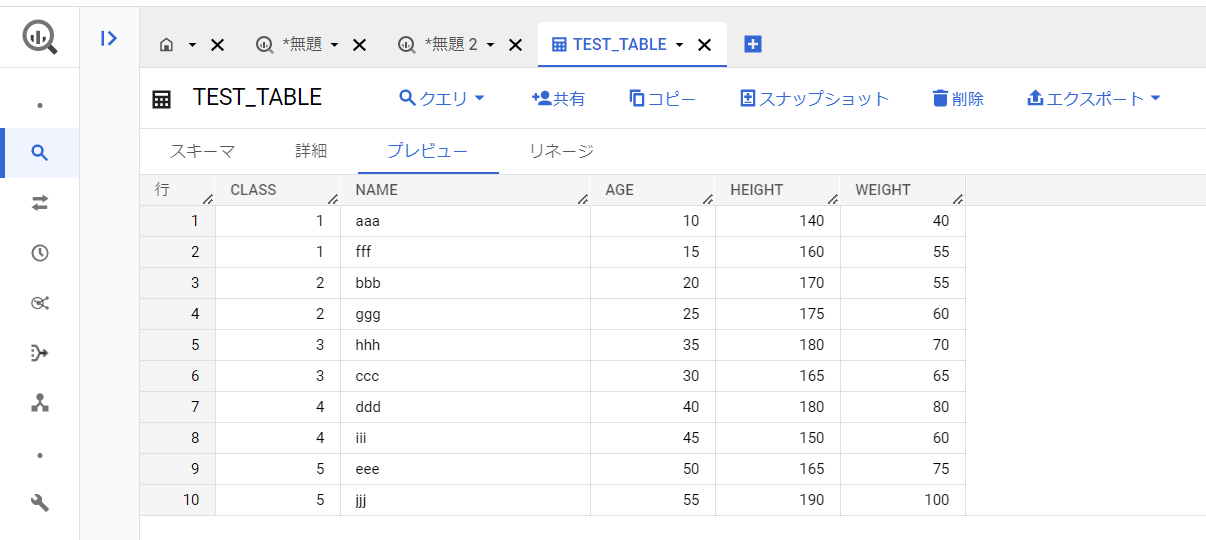
それではここからSQLワークスペースでのSQL変換をやってみます。
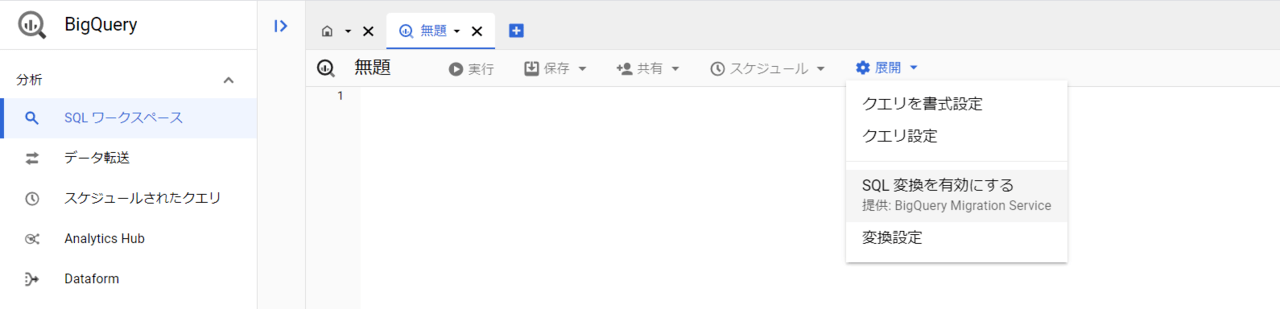
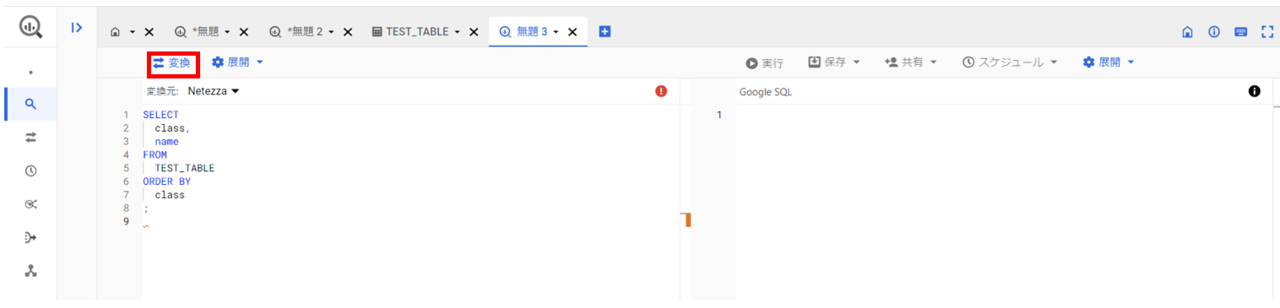
ワークスペースの「展開」タブ-「SQL変換を有効にする」を選択します。
「変換元」のプルダウンで今回はNetezzaを選択します。
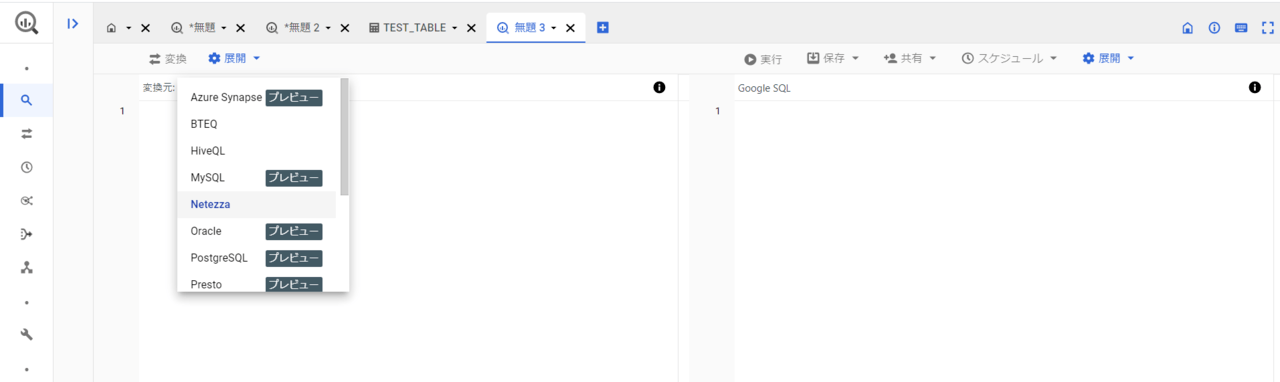
変換後のクエリ文(今回はNetezza_Example2を使用)を貼り付けて、赤枠の「変換」をクリックします。
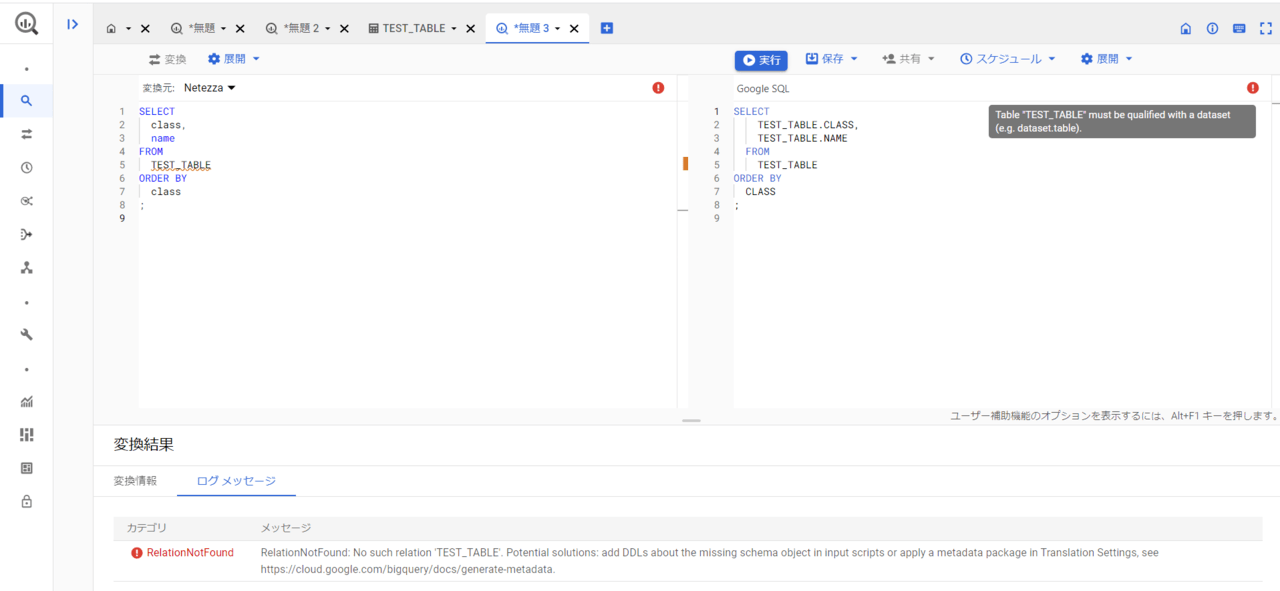
変換自体は成功しましたが、実行するためにはパス指定を手直しする必要があります。
パス指定を手直しして実行します。
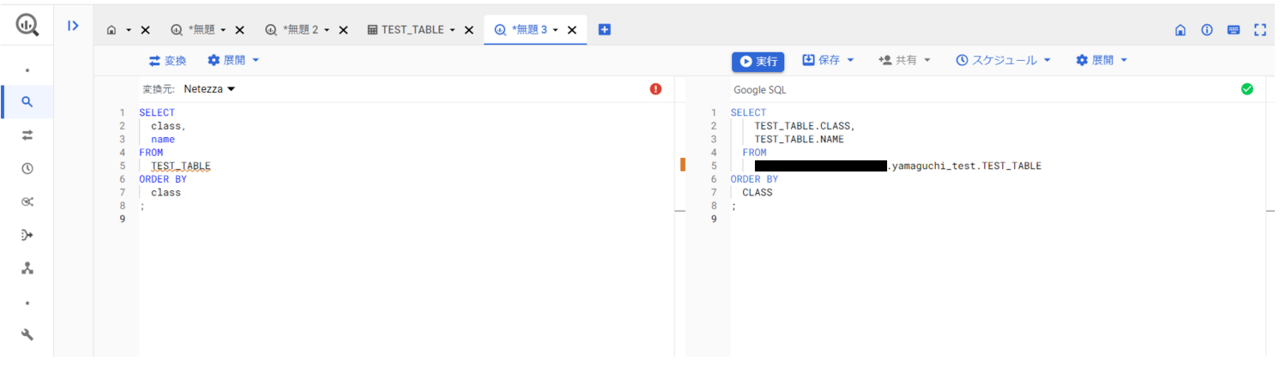

実行が成功し、正しく処理できていることが確認できました。
日本語のカラム名には対応している?
そういえば、BigQueryが日本語に対応した旨のリリースノートを見たことを思い出しました。
やってみた結果
ブログが長くなりそうなので結果のみ簡単に記載します。(前回投稿ブログの反省点。⇓)

結論から言いますと、日本語のカラム名を含むクエリの移行は不可能でした。(怒られました。)
ただし、日本語部分を「”」で囲み、文字列として認識させることで回避することが可能でした。
(例)日本語の認識失敗
〇 入力
CREATE TABLE TEST_TABLE ( クラス INTEGER not null, 氏名 NATIONAL CHARACTER(20), 年齢 INTEGER, 身長 INTEGER, 体重 INTEGER )
〇 実行エラー画面
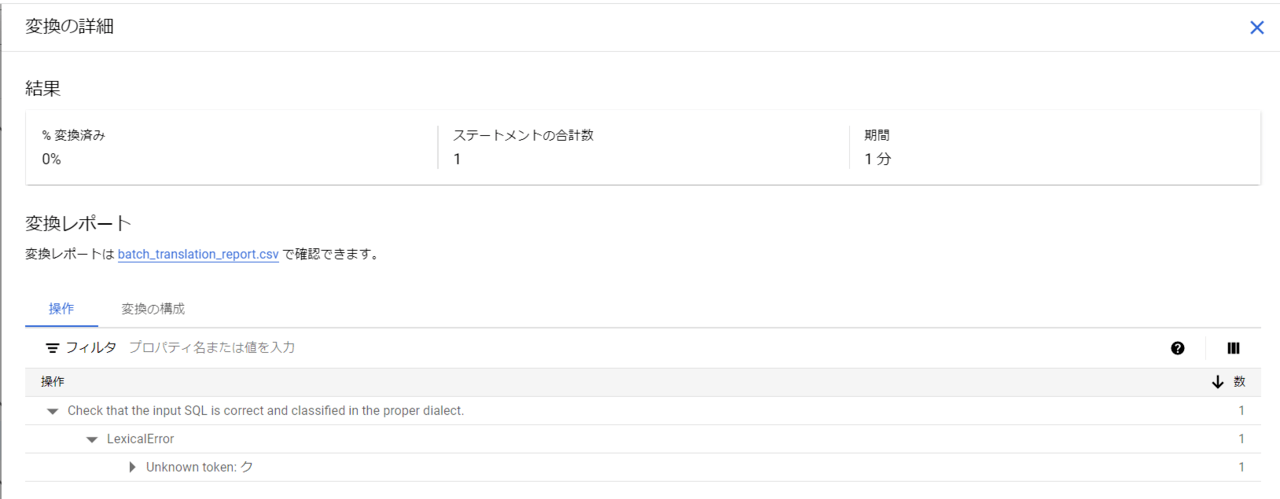
〇 出力

⇒ エラーメッセージのみで実は変換できているのでは、、、?と淡い期待を抱きつつ実行結果のファイルを覗いてみましたが、やはり怒られていました。(予想通り)
(例)日本語の認識失敗を回避
〇入力
CREATE TABLE TEST_TABLE ( "クラス" INTEGER not null, "氏名" NATIONAL CHARACTER(20), "年齢" INTEGER, "身長" INTEGER, "体重" INTEGER )
⇒ 日本語部を「”」で囲み、文字列と認識させることで変換できるのでは?とまたまた淡い期待を抱いて実行してみました。
(BigQuery Migration Serviceさえ誤魔化すことができたらBigQuery は日本語を認識してくれるはず。と考えたため。)
〇 実行エラー画面
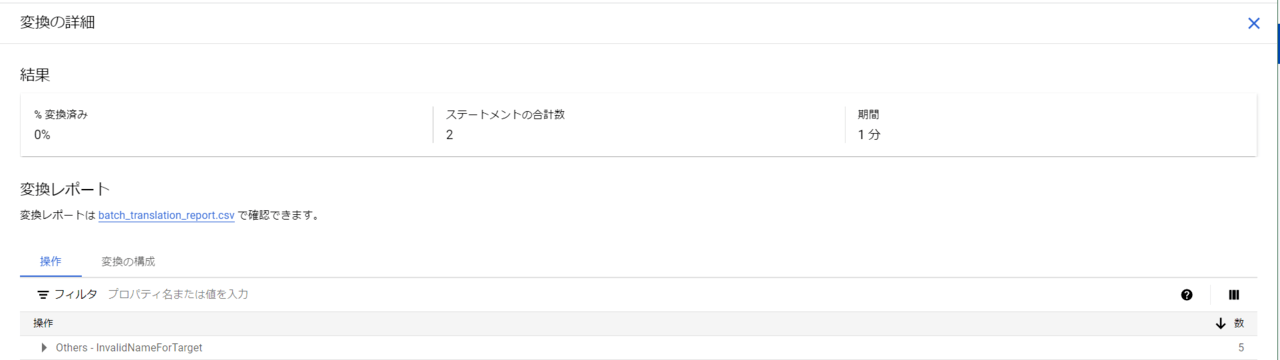
⇒やっぱり怒られた。。。と思ったんですが、よく見ると先ほどと違うエラーが出ています。念のため出力結果を見てみます。
〇出力
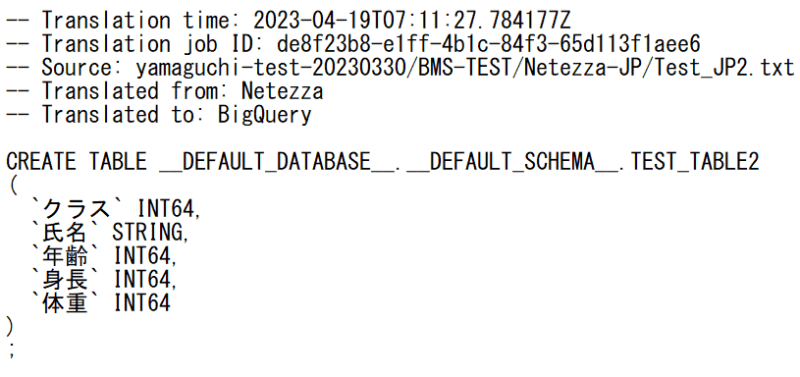
⇒ なんと変換できていました。(予想外)
変換済みは0%と表記されていますが、変換後のファイルが出力されていました。
〇 出力結果チェック
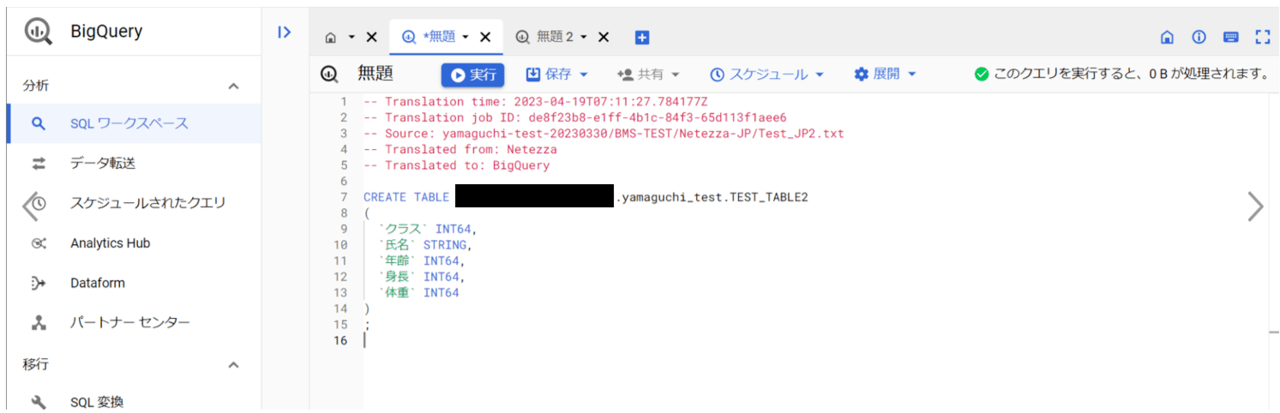
⇒BigQuery 自体は日本語のカラム名に対応しているので、SQLワークスペースへ貼り付けても特にエラーは吐かれませんでした。
(※パス指定部は手直ししています。)
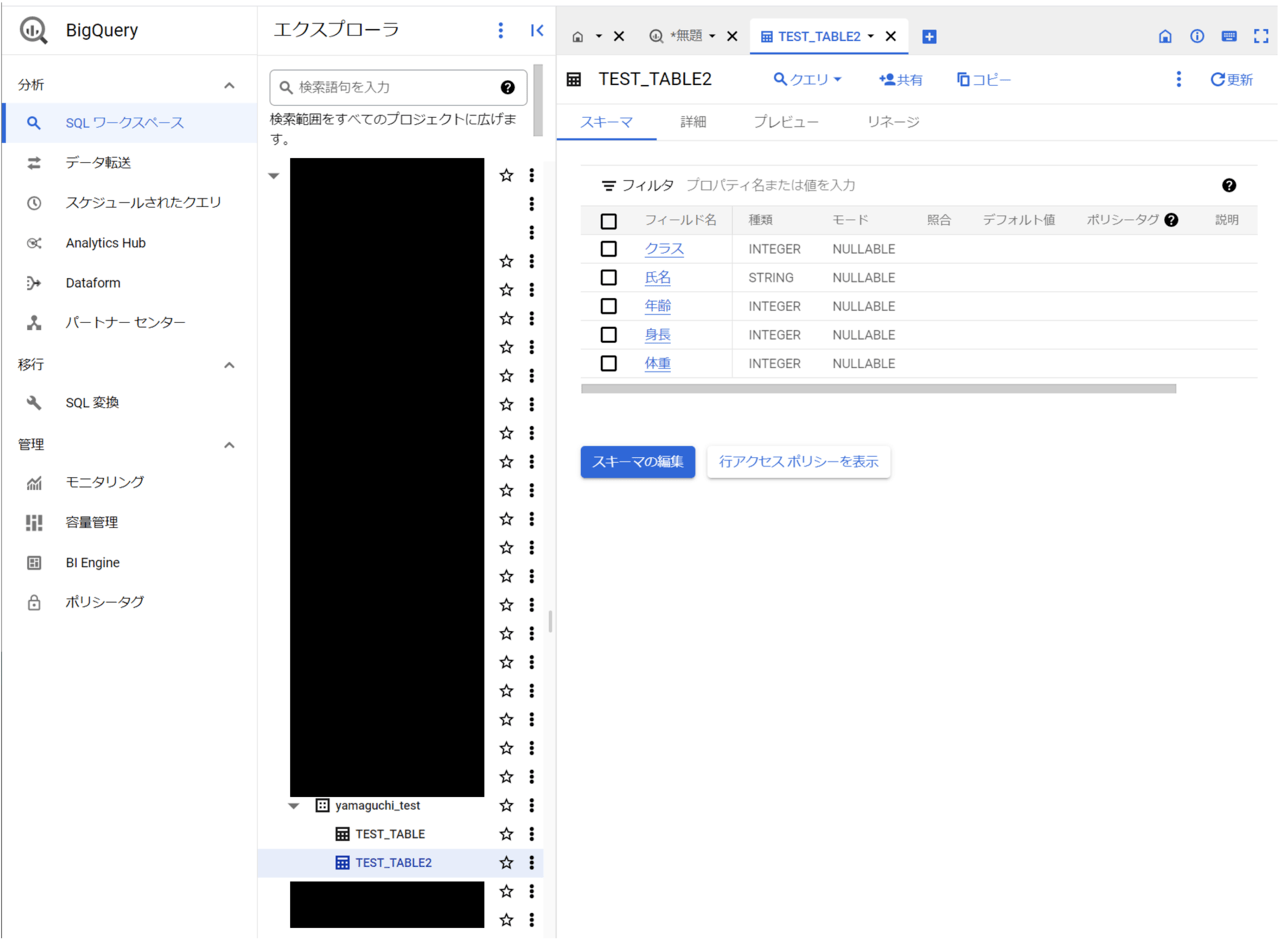
⇒実行してみたところ、期待通りのテーブルが作成されました。
所感
実際に使用してみた所感です。
使用したコードが簡単であった影響も考えられますが、「ちゃんと動いてくれる。使えそう。」というのが正直な感想です。
日本語対応等のBigQueryの仕様変更に追い付いていない点がありますが、変換ツールとして十分に使用できるレベルだと感じました。
今回はBigQuery Migration Serviceを用いたファイル単位での変換と、BigQueryのSQLワークスペースでのソースコード単位での変換 の二つをやってみましたが、これらを上手く使い分けることも重要だと思います。
ただし、より複雑なクエリ文の変換となる場合は、現状、完ぺきに変換をこなせない部分もありそうです。
その部分は機会があればまた次回のブログで書きたいと思います。
最後に
二連続のBigQuery に関するブログ投稿となりました。
前回投稿したブログがかなりのボリュームになってしまったので今回は簡潔にわかりやすく。と思っていたんですが、今見ると今回もなかなかのボリュームになっていました。
アウトプットのスピードももちろんですが、質も徐々に上げていきたいと考えています。