

こんにちは。SCSK石原です。
AWSを中心にデータ基盤を作成されている場合、AWS Glueが登場する機会が多いのではないでしょうか。AWS Glueには、ETL機能はもちろん、システムメタデータを管理できるAWS Glue Data Catalogがあります。
AWS Glue Data CatalogにはCrawlerという強力な機能があり、自動でスキーマを構成可能です。
また、インフォマティカ(Informatica)では、クラウドデータマネージメントプラットフォームとして「Intelligent Data Management Cloud(IDMC)」があり、その中の一つとして「Cloud Data Governance and Catalog(CDGC)」というデータカタログ機能を含むサービスあります。このサービスはシステムメタデータとビジネスメタデータの双方を管理できるものです。

今回はAWS Glueをより活用するために、ETL情報をCDGCで抽出しリネージュを取得、カラムレベルでのデータの流れを把握できることを検証します。
全体概要
検証環境の全体概要について、インフラ視点とデータ視点で説明します。
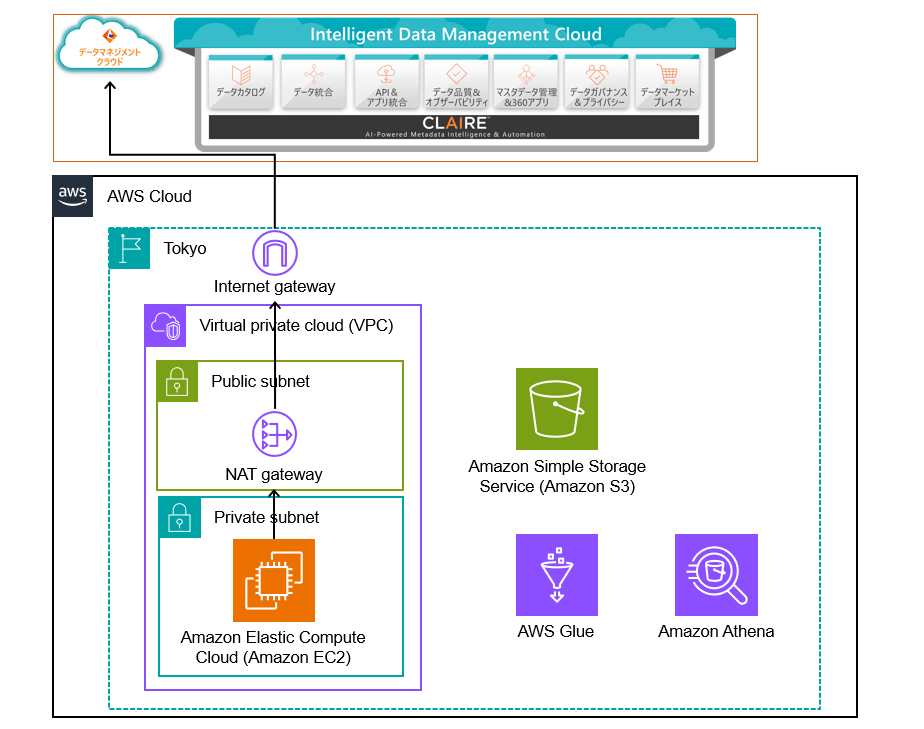
インフラ構成図
インフラ構成は以下の通りです。Amazon EC2にはSecureAgentというランタイム環境をインストールします。EC2からインターネット経由でIDMCに接続します。
VPC外には、データストアとしてAmazon S3、ETL及びデータカタログとしてのAWS Glue、クエリエンジンのAmazon Athenaを利用します。このほかにも、IAMなどのサービスを利用しますが下記図では割愛します。
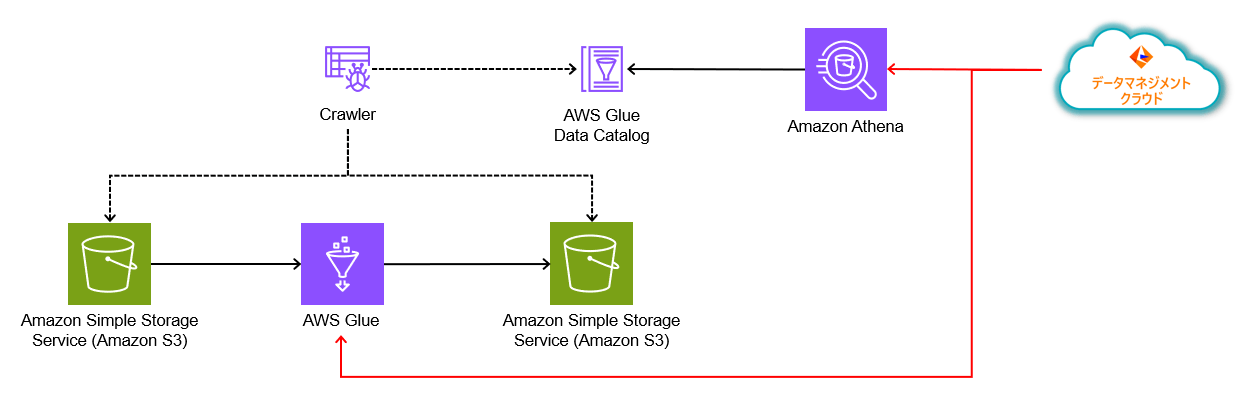
データ遷移図
コンポーネント間のデータの流れを整理します。AWS GlueにてETLを実行します。ソースシステムとターゲットシステムにはAmazon S3を利用します。
Amazon S3に格納したデータに対してAWS GlueのCrawlerを利用して、AWS Glue Data Catalogにシステムメタデータを登録します。
IDMCからは、Amazon Athena及びAWS Glueの接続コネクタを利用して、スキーマやテーブル情報などのシステムメタデータやカラムレベルのリネージュ情報を取得します。
今回は、Kaggleのチュートリアルで利用するTitanicのデータセットを利用させていただきました。

AWS側の準備
AWSの設定を行います。
AWS Glue Data Catalogの設定
Amazon S3にTitanicのデータ(CSVファイル)を格納しましたので、AWS Glue Data Catalogに登録します。
- AWS Glue Data Catalogのデータベース作成
- AWS Glue Classifiersの設定
- AWS Glue Crawlerでテーブルを作成
今回の設定値は以下の通りです。
| データベース名 | ishihara-db |
| テーブル名 | titanic |

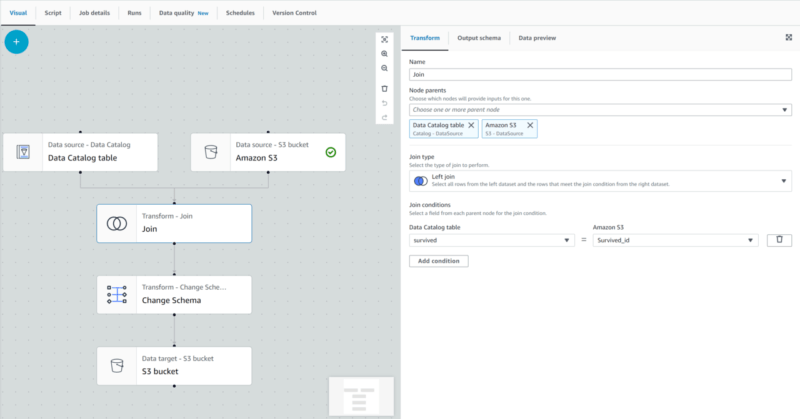
AWS GlueによるETLジョブ作成
後ほどリネージュを確認するために、2つのデータソースを結合してAmazon S3にファイルを出力するETLジョブを作成します。
結合に利用したデータは下記のとおりです。
| Survived_id | Survived_name |
| 0 | dead |
| 1 | survival |
ETLジョブ実行後に、出力されたデータに対してAmazon Athenaでクエリできることを確認しておきます。
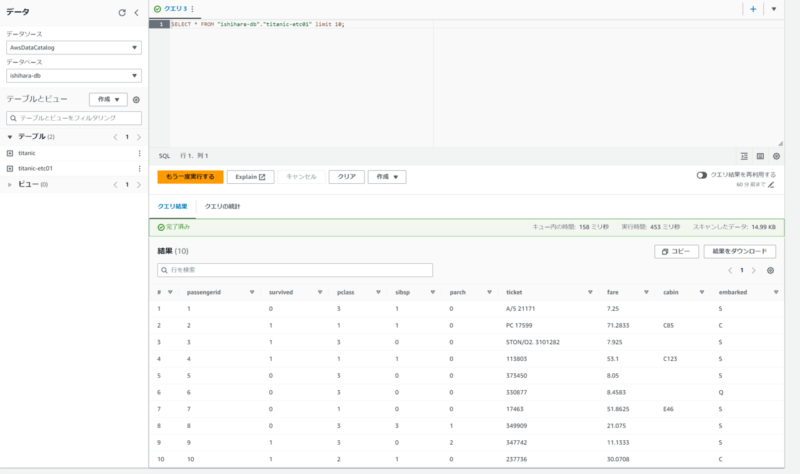
正常にクエリができていますので、AWS側の設定は完了です。

IAMユーザの準備
Amazon Athenaの接続設定をするためには、AWS IAMのユーザが必要になります。下記のドキュメントに従って適切なポリシーを保持したユーザを作成したのち、アクセスキーを発行します。

IDMC側の準備
次にCDGCからAWSの各種サービスへメタデータスキャン設定を行います。
Amazon Athenaへの接続
接続設定
接続設定は以下の通りです。先ほど作成したアクセスキーを利用します。
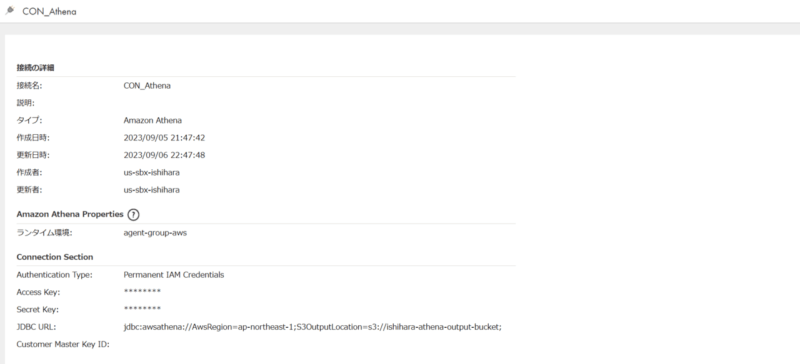
カタログソース設定(Amazon Athena)
Amazon Athenaのカタログソースを構成します。下記のマニュアルを参考に進めます。
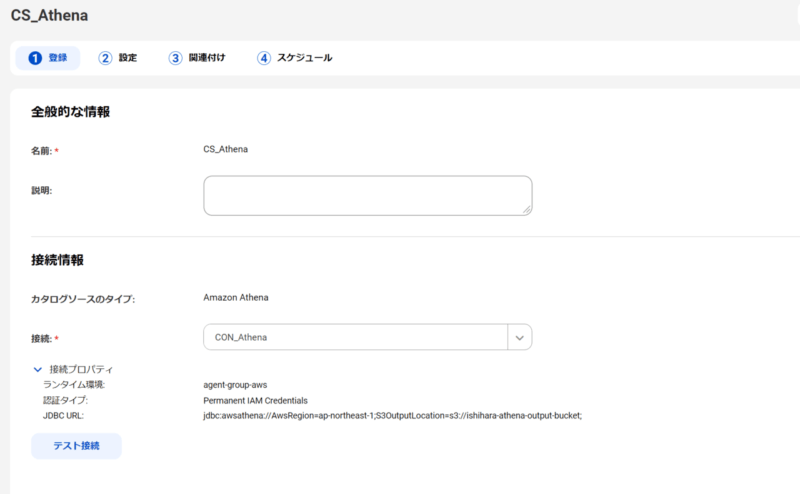
事前定義されたカタログソースのうち「Amazon Athena」を選択して、設定します。 
先ほど定義した「接続」を使用します。テスト接続が成功することを確認して次に進みます。
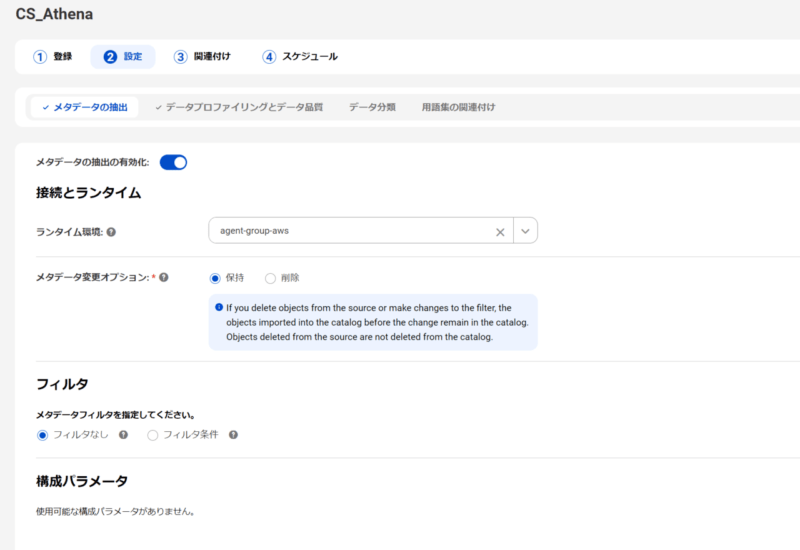
まずはメタデータの抽出が有効になっていることを確認して、保存します。
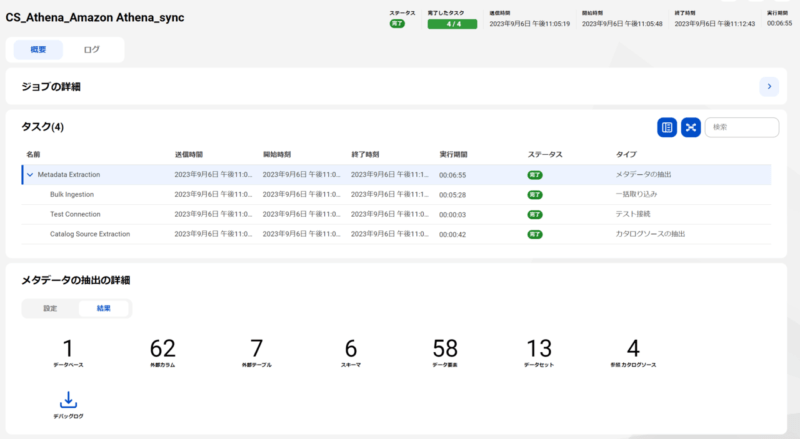
カタログソース設定が完了したのち、実行すると以下のジョブ画面を確認することができます。今回はフィルタ設定をしていないため、今回用に作成したAWS Glue Data Catalog以外のテーブルやスキーマも取り込まれています。
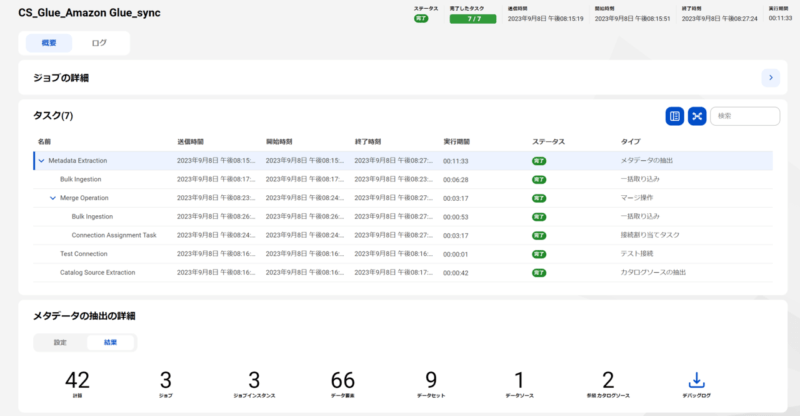
カタログソース設定(AWS Glue)
AWS Glueのカタログソースを構成します。下記のマニュアルを参考に進めます。

カタログソース設定(Amazon S3)
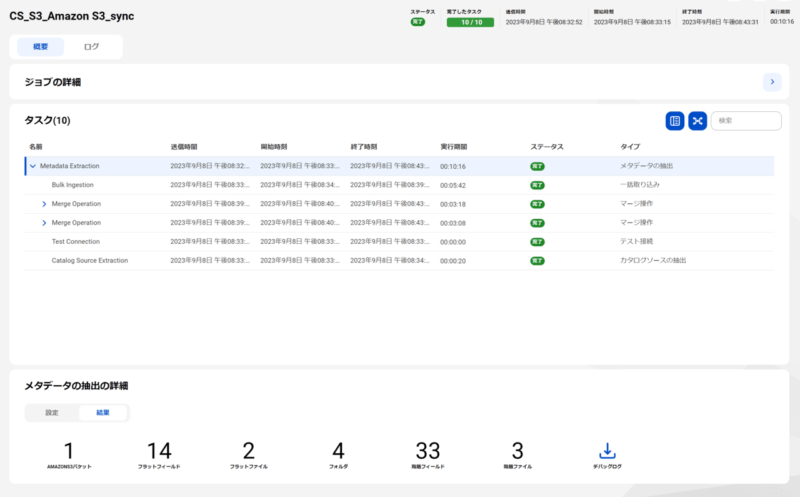
Amazon S3のカタログソースを構成します。下記のマニュアルを参考に進めます。

カタログソース設定をしたのち、実行した結果は下記のとおりです。
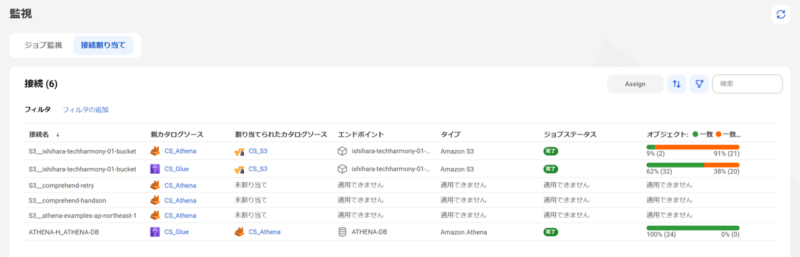
接続の割り当て
Amazon Athena,AWS Glue,Amazon S3のメタデータ抽出が完了したのち、関連する情報のマッピングを行います。
- Amazon Athena(S3__ishihara-techharmony-01-bucket)はAWS Glue Data Catalogを参照しており、実データはAmazon S3に存在するため、Amazon AthenaのカタログソースとAmazon S3のカタログソースをマッピングします。
- AWS Glue(S3__ishihara-techharmony-01-bucket)はAWS Glue Data Catalogを参照しており、実データはAmazon S3に存在するため、AWS GlueのカタログソースとAmazon S3のカタログソースをマッピングします。
- AWS Glue(ATHENA-H_ATHENA-DB)はAWS Glue Data Catalogを参照しているため、Amazon Athenaのカタログソースとマッピングします。AWS Glue Data CatalogはAmazon Athenaのカタログソースとして登録されているように見受けられます。
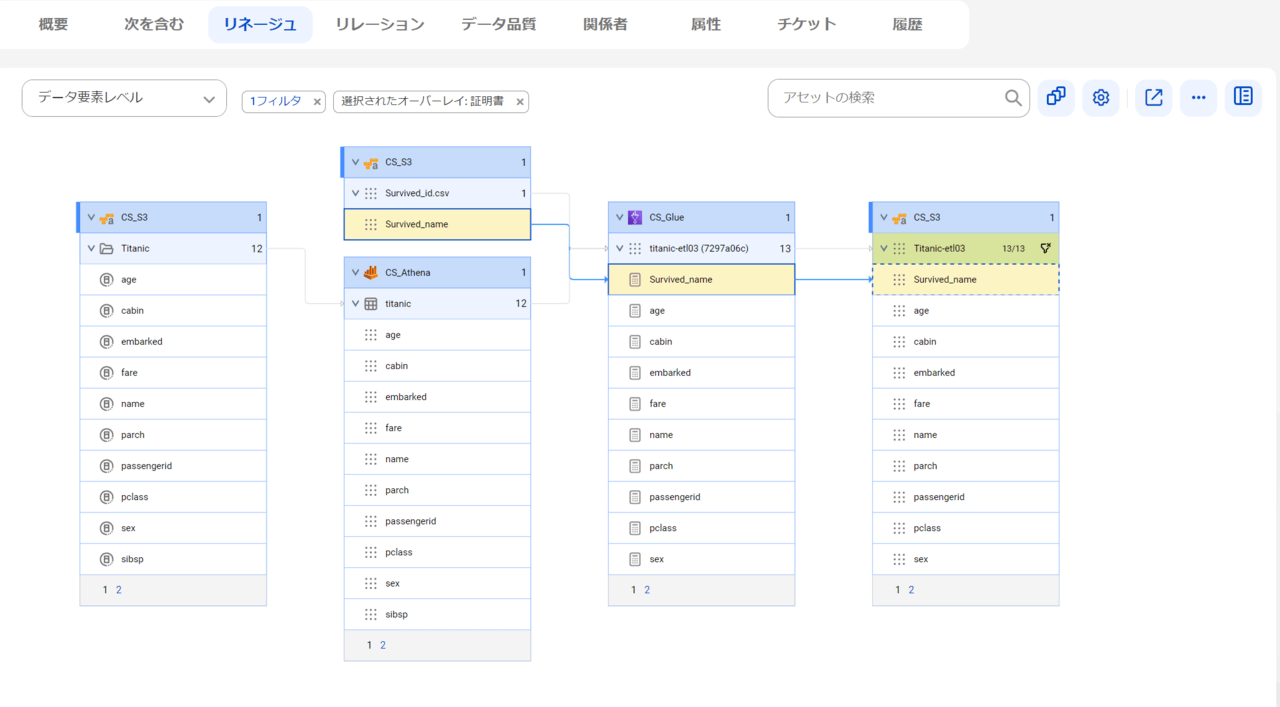
結果
AWS GlueをCDGCでスキャンすることで、カラムレベルでデータの流れを確認することができるようになりました。データの流れを可視化できることにより、データの透明性を高めることができます。
大規模なデータ基盤となれば、データリネージュが必要になると考えております。この記事が役に立てば幸いです。