

どうも、まったく絵心のない寺内です。
2022年7月、画像生成AIという触れ込みでMidjourneyというプログラムがオープンベータになりました。テキストを与えると、その内容にあった画像を数秒で生成する機械学習モデルであり、その生成画像のクオリティの高さに様々な業界に衝撃を与えました。MidjourneyはDiscordで使うことができ、無料版は生成できる画像数に制限があります。有料版にすることで、制限数の上限をあげたり、無制限にしたりすることができます。
時を同じくして8月、ロンドンにあるAI企業Stability AIが、Stable Diffusionというソフトウェアをオープンソースで公開し、Midjourneyを超える品質と話題になっています。
「クリエイティブの革命」とも、「AIの民主化」とも言われるStable Diffusionを、ここで体験してみましょう。
Stable DiffusionはPythonで簡単に実行できるようにできていますので、この記事ではAmazon SageMakerを使い実行する手順をご紹介します。
体験サイト
Stable Diffusionはオープンソースですが、体験サイトも存在します。以下のサイトにアクセスし、Promptのテキストボックスに描いてほしい絵や写真の内容を書くと、いい感じの画像を生成してくれます。
ただ体験サイトは利用者も多く、リクエストは待ち行列に入ります。
せっかくのオープンソースですから、自分の環境にインストールして自由に使ってみましょう。
手順の概要
Stable Diffusionは、GitHubのCompVis/stable-diffusion でツールが公開されていますが、肝心のモデル(Model Cardという)は、AI開発者コミュニティのHugging Face で配布されています。そこにはStable DiffusionのModel Cardの詳細な説明もあります。
そのため、まずHugging Faceのアカウントを取得します。そのアカウントで、Stable Diffusionのライセンスに同意することで、ダウンロードできるアクセストークンを入手できます。
ライセンスは、おおよそ以下のような内容です。
- 生成した画像は自由に使用してよい。ただし違法なもの、有害なものを生成してはいけない。
- モデルについても商業利用含めて自由に使用してよい。その際は、同様のライセンスとする。
アクセストークンを入手したら、そのトークンでHugging Faceにログインし、NVIDIAのGPUが搭載されたコンピュータでPythonコードを実行すると、Model Cardが自動でダウンロードされます。その後、そのModel Cardを使い画像を生成できようになります。
Hugging Faceへのサインアップ
以下のURLにアクセスし、ステップに従いメールアドレスで登録します。特段、難しいところはないと思います。

アクセストークンの入手
Hugging Faceにログインして、Stable DiffusionのModel Cardのページにアクセスします。

すると、ライセンスに同意するボタンがありますので、押下して同意します。
そして、アカウントのSettingsを選びます。
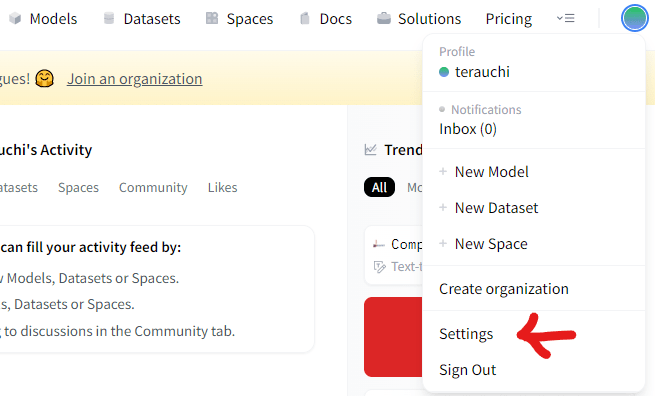
Settingsの画面の左のサイドメニューから「Access Tokens」を選ぶと、トークンを作成する画面があります。作成したら、アクセストークンをコピーします。
Amazon SageMakerのインスタンス作成
いよいよAWSにアクセスし、SageMakerのインスタンスを作成します。
SageMakerのサイドメニューから「ノートブックのインスタンス」を選択します。
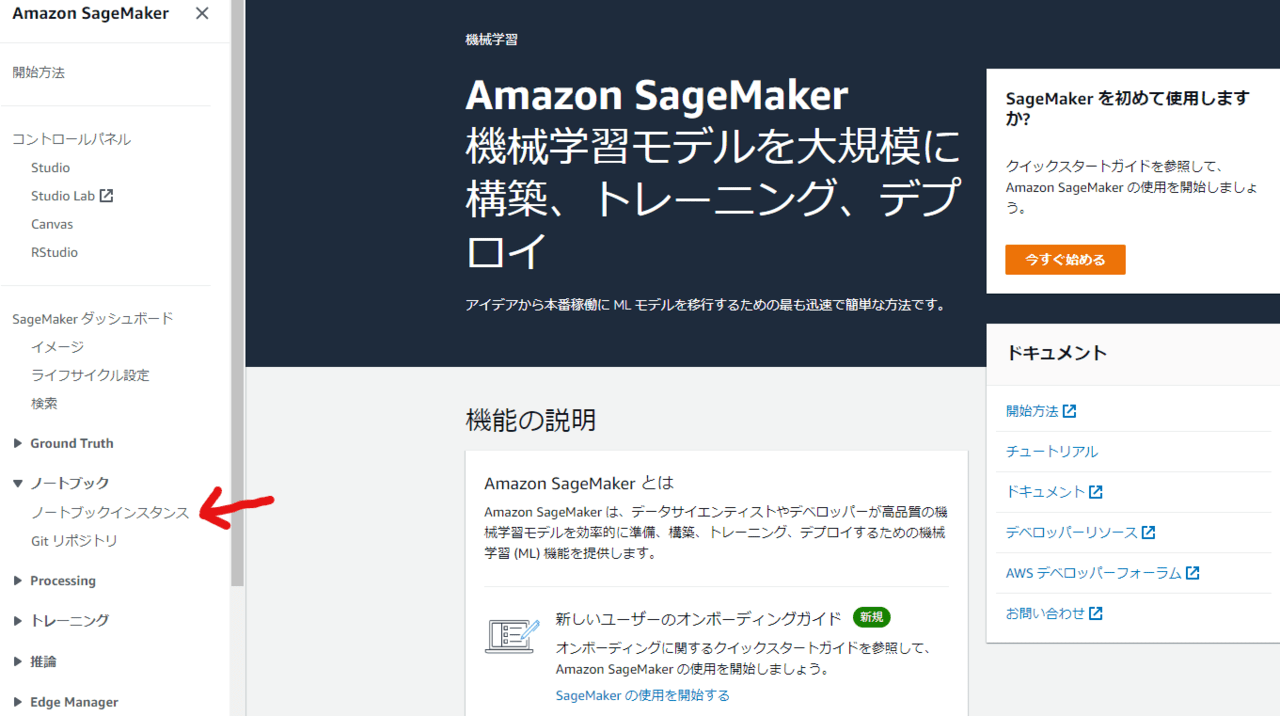
そして「ノートブックインスタンスの作成」ボタンを押します。設定画面では、以下のパラメータを指定してください。
- ノートブックインスタンス名: わかりやすい名前をつけます。
- ノートブックインスタンスのタイプ: NDIVIAのV100を搭載している「ml.p3.2xlarge」を選択します。
- IAMロール: 新規作成してデフォルトのまま「AmazonSageMakerFullAccess」とS3バケットへのアクセスの権限を得ます。S3は生成した画像を取り出すために使います。
その他の項目は特段変更しないでよいですが、必要に応じて適切に変更してください。
設定が終わったら、ノートブックインスタンスの作成ボタンを押下します。
ノートブックの作成
インスタンスがInServiceになったら、「Jupyter を開く」を押します。その後、「New」で conda_pytorch_p38 を選びノートブックを新規作成します。
Stable Diffusionの実行
このページにあるExamplesの手順でやっていきます。
まずノートブック上の環境に pip コマンドで必要なPythonライブラリをインストールします。なおExamplesでは ftfy は記載されていませんが、後で警告がでるので、一緒にインストールしておきます。
!pip install --upgrade diffusers transformers scipy ftfy
上記コマンドをセルに入力したら、Shift+Enterで実行します。しばし時間がかかりますので、終了まで待ってください。
次は huggingface-cli login によるログイン処理ですが、これはやらずプログラムにトークンを埋め込みます。
次にExamplesにあるプログラムを少し手直しします。
- 9行目の
use_auth_tokenの値はTrueとなっているが、先にHugging Faceのサイトから入手したトークンを埋め込む。 - 12行目の
promptに生成したい画像の内容を指示する。 - 16行目の出力ファイル名を適当に変更する。
- 最後に
imageコマンドを追記する。
すると、プログラムは以下のようになります。
import torch
from torch import autocast
from diffusers import StableDiffusionPipeline
model_id = "CompVis/stable-diffusion-v1-4"
device = "cuda"
pipe = StableDiffusionPipeline.from_pretrained(model_id, use_auth_token='XXXXXXXXXXXXXXXXXXXXX')
pipe = pipe.to(device)
# 土星のような輪を持つリンゴの写真
prompt = "Photo of an apple with rings like Saturn"
with autocast("cuda"):
image = pipe(prompt, guidance_scale=7.5).images[0]
image.save("apple.png")
image
これをShift+Enterで実行し、しばらく待つと、Model Cardのダウンロードが始まります。このダウンロードは最初の一度だけです。
さらに待つと、 {'trained_betas'} was not found in config. Values will be initialized to default values. という警告が出ますが、それでもしばらく待ちます。
すると、画像生成が始まり画像が表示されます。
Promptを調整し、気に入った画像ができたらS3に保存しましょう。
セルに以下のコマンドを入れると、S3に画像を転送します。
!aws s3 cp ファイル名 s3://バケット名
以上でStable Diffusionの基本が使えるようになりました。
作例
SF的な写真
以下のようなPromptで出力されたのが、下の画像です。
(パーツの多い巨大で屈強な人型ロボットが立っている全身、’ghost in shell’のような背景に崩れ燃えあがるビルディングの精巧な写真)

なかなかおもしろい感じのものができました。燃え上がっているのが背景のビルではなく、ロボットの方になっているのが不思議ですが、言語解析部分はたぶん文法を厳密には見てないのかもしれないですね。
ペンギンのイラスト
イラストも作ってみました。Promptは以下です。
(宇宙に浮かぶ大きな赤いリンゴの上で楽しく踊る皇帝ペンギンの精細なイラスト)

リンゴなのか? という感じですが、リンゴの芯のようにも、つぶれた実のようにも見えます。ペンギンの尻尾も長すぎます。
細かく見るとツッコミどころ多いですが、いい感じでできていますね。
まだまだ呪文力が足りません。
Promptについて
画像生成AIに与えるPromptの記述は、イメージしている望む画像を得るためにコツが必要です。コツをまとめたノウハウも流布されてきており、それはあたかも召喚魔術の呪文詠唱ように揶揄されています。そのためPromptのことを「呪文」とも呼ばれています。
このあたりも追求していくとおもしろいと思います。
次の展開
この後の応用として、以下のようなサイトが参考になります。
日本語対応
Stable Diffusionは、基本的に英語のキャプションの付いた画像で学習しています。そこで、日本語キャプションの画像を追加学習させたモデルが以下で公開されています。和風な物品を描画したいような場合には有効かと思います。

アニメ風画像の生成
二次元画像を追加学習し、アニメ風の画像を高品質で出力できるモデルが公開されています。いろいろ活用できそうです。

SEEDの固定
同じPromptを与えても、同じ画像は出力されません。これは乱数が組み込まれているためです。それではPrompt(呪文)をチューニングしていくときには不便です。そこで以下のサイトを参考に、SEEDを固定化することができます。

GPU不要の軽量版
GPUのいらないCPUのみで実行可能なプログラムが以下で公開されています。より気軽に実行したいときには便利かと思います。
https://github.com/bes-dev/stable_diffusion.openvino
では楽しいクリエイティブ活動を。