

こんにちは!SCSKの山口です。今回もBigQuery に関する投稿です。
以前、BigQuery のパーティショニングに関するブログを投稿したのですが、パーティショニングに関していろいろと調査をしているうちに「クラスタリング」が気になったので今回は実際にやってみたいと思います。

(BigQuery の概要、課金体系等に関してはコチラをご覧ください。)
データベース形式の分類
データベースは、データを保存する形式によって大きく2つに分けられます。まずこれらの形式について説明します。
行指向形式データベース
一つ目が”行指向形式”です。従来のデータベースシステムの多くがこちらに分類されます。
例)MySQL PostgreSQL など
この形式は「データが各行ごとに保存」されています。以下のイメージです。
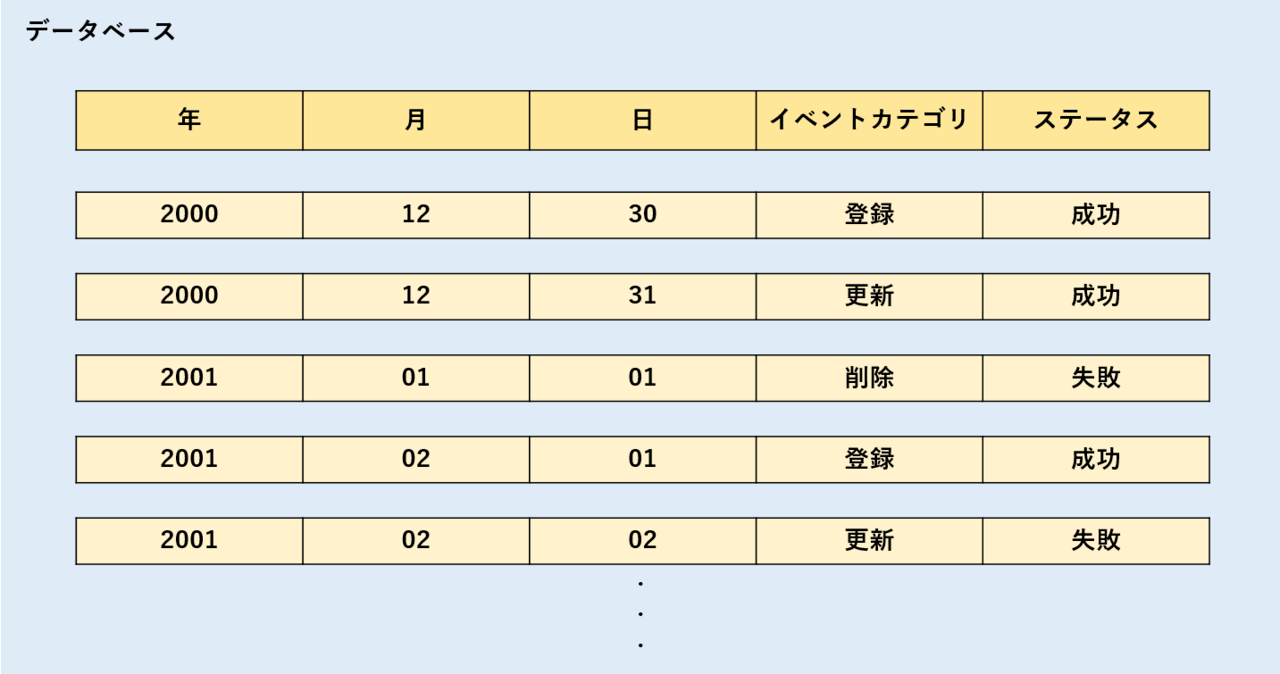
レコードへアクセスする際は各行に対して”すべての列”にアクセスします。
列指向形式データベース
二つ目が”列指向形式”です。
この形式は「データが各列ごとに保存」されています。以下のイメージです。
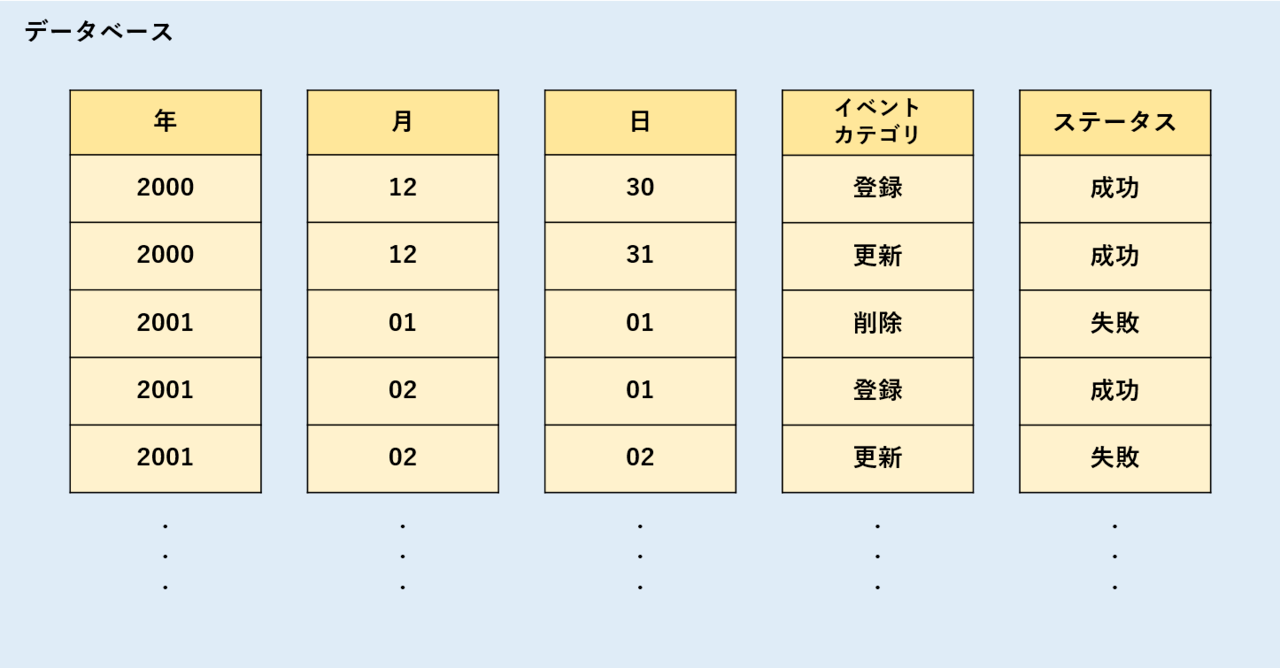
レコードへアクセスする際は”あらかじめ指定された列”にのみアクセスします。
BigQueryでは、テーブルデータを”列指向形式”で格納します。
列指向形式データベースは、大量のレコードからデータを集計する分析ワークロードに適しています。
数百万行にわたる列に対して処理をする場合でも、特定の列のみへアクセスすることで分析クエリでの読み取り量を減らし、効果的に分析を行うことが可能です。
この特性が、「大規模なデータのほぼリアルタイムでの分析」を可能としています。

クラスタリングとは
BigQueryにおけるクラスタリングでは、データを並び替えてストレージブロックにグループ化する作業が行われます。
クラスタリングされたテーブル(クラスタ化テーブル)でフィルタや集計を行うクエリは、テーブルやテーブル パーティション全体ではなく、クラスタ化列に基づいて関連するブロックのみをスキャンします。
やってみた
ケース1:テーブル作成時にクラスタリング
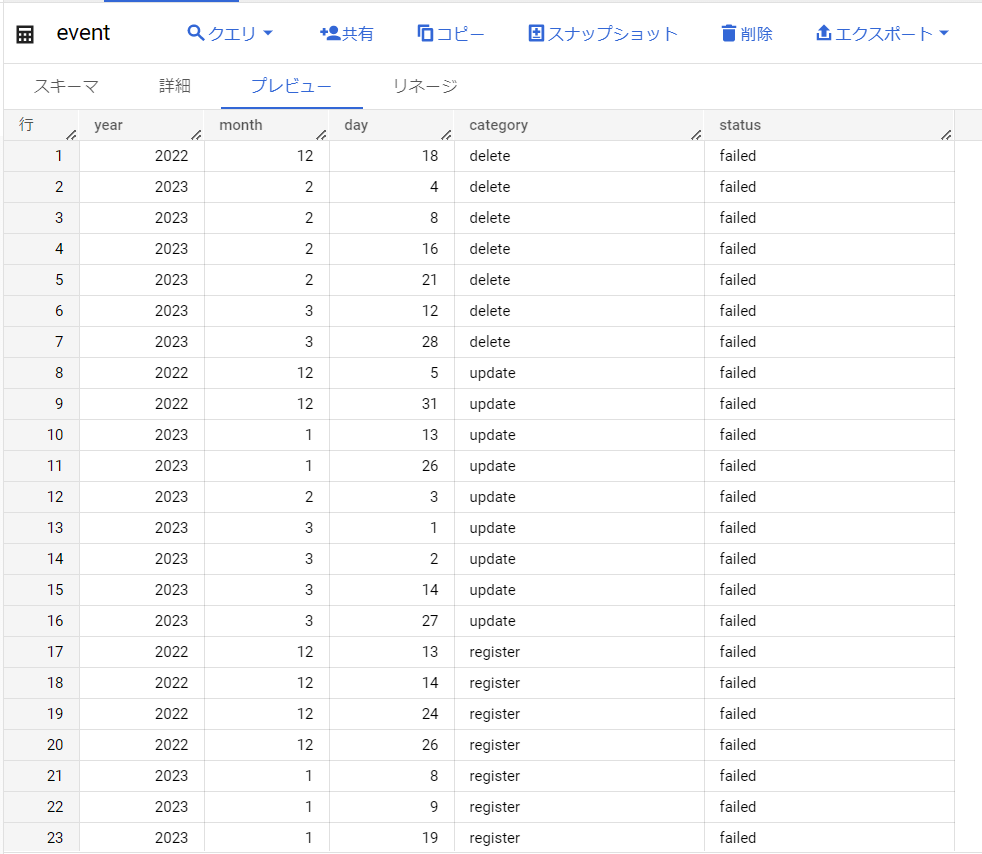
今回は下記の「event」テーブルを使用します。
「年、月、日、イベントカテゴリ、ステータス」のスキーマがあり、登録/更新/削除の操作が行われた日付と、成功/失敗のステータスが格納されています。
あらかじめGoogle Cloud StorageにアップしておいたファイルからBigQuery テーブルを作成する際にクラスタ化テーブルにしてみます。
作成方法:[テーブルを作成]画面で以下のように入力し、テーブルを作成します。
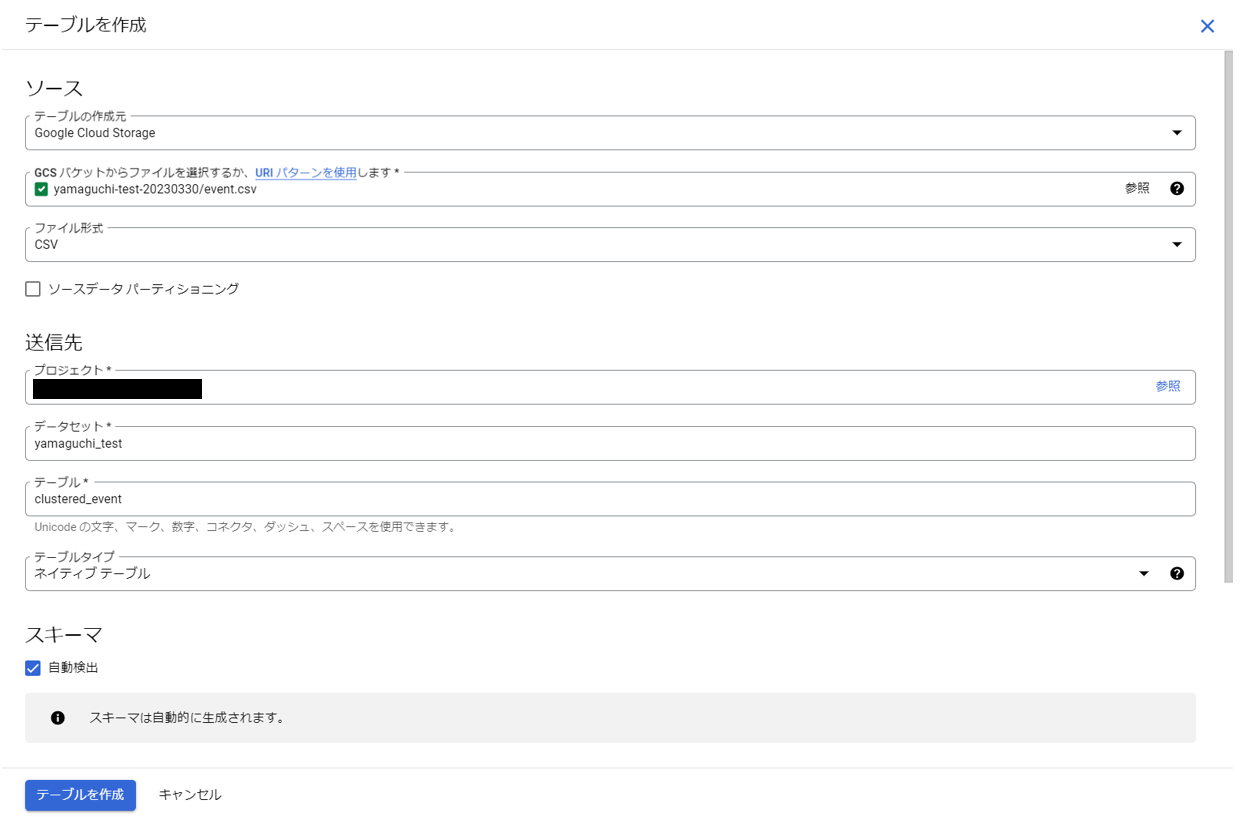
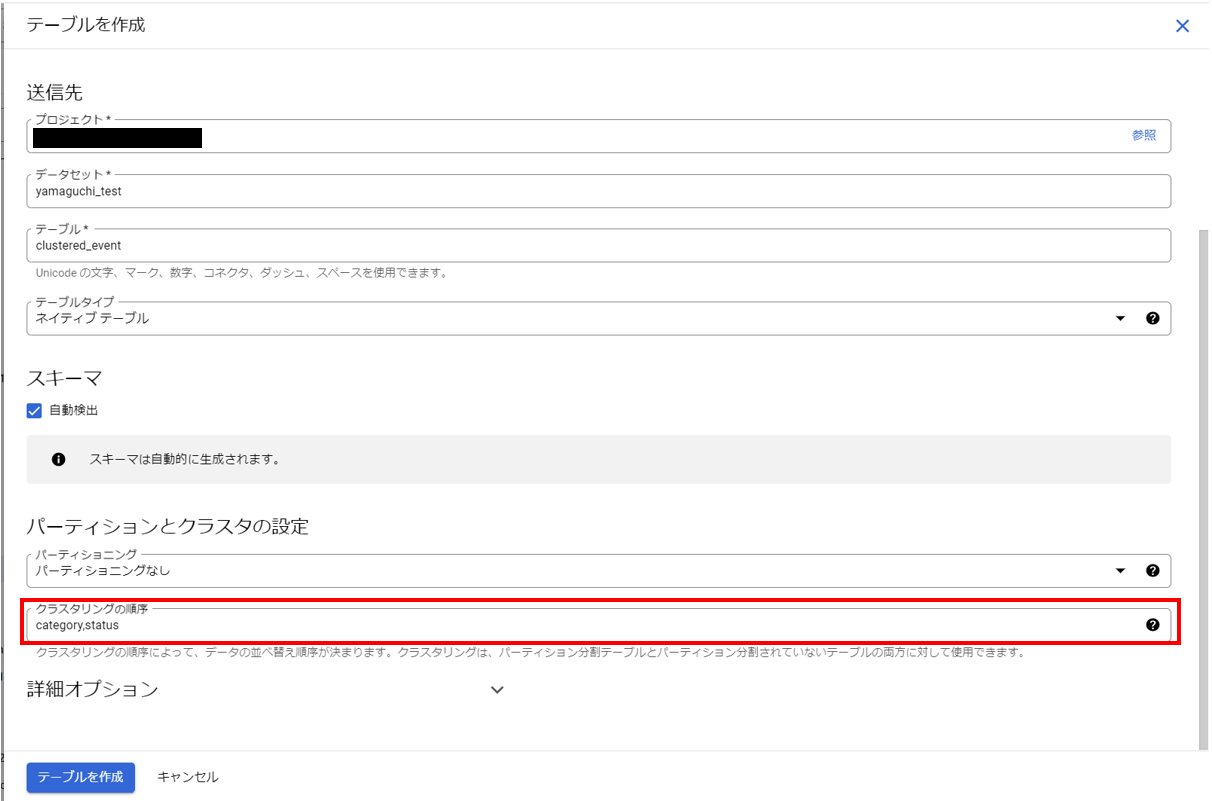
⇒[クラスタリングの順序]で今回は”category,status”(赤枠内)を選択し、テーブルを作成します。
これでクラスタ化テーブルが作成されている(はず)です。
あっさり過ぎて怖いので作成したテーブルを見てみましょう。
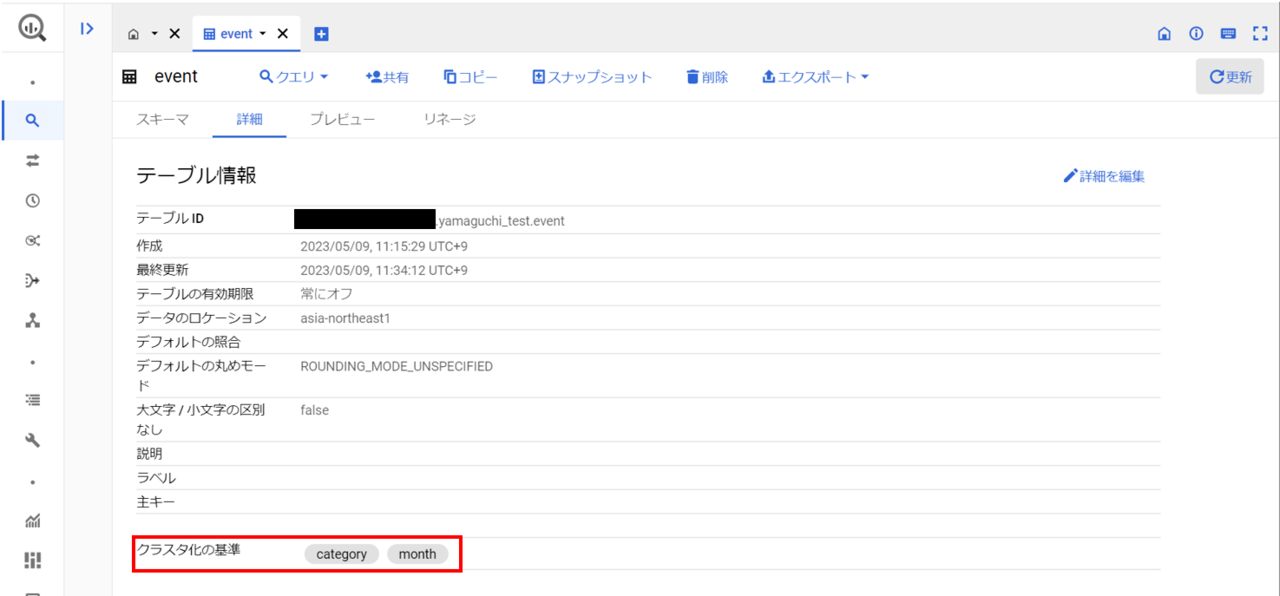
無事に作成されたようです。
ケース2:既存のテーブルをクラスタリング
引き続き「event」テーブルを使います。
下記の通り、初期状態(BigQueryに読み込んだだけの状態)ではクラスタリングが有効化されていません。
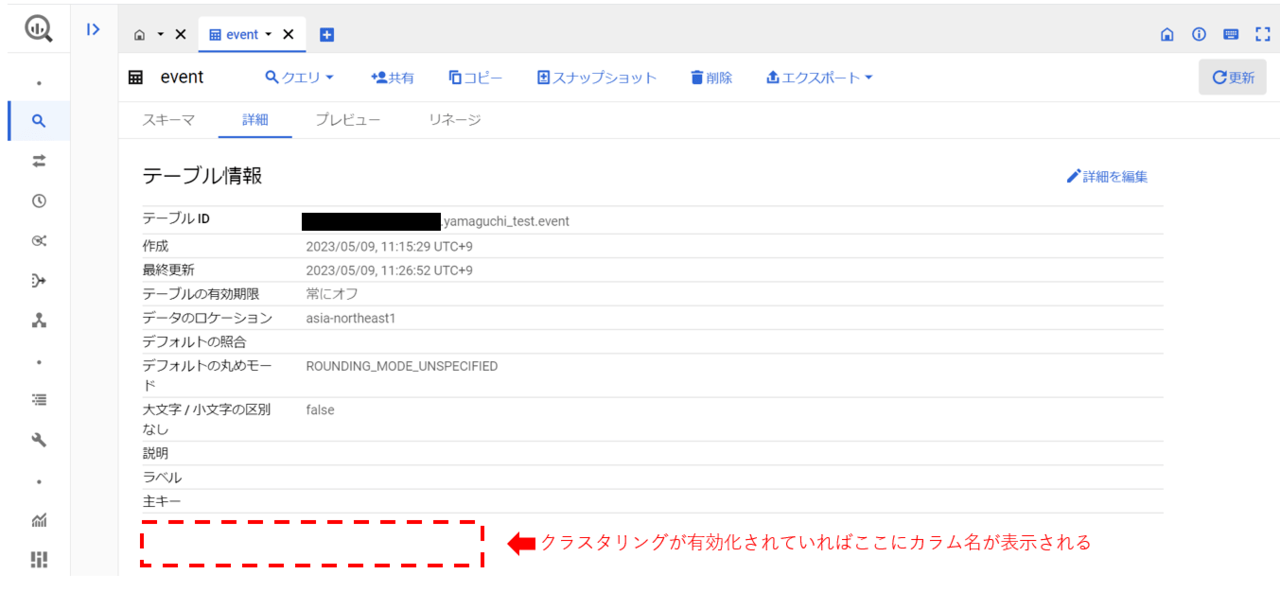
既にBigQuery 上に作成済みのテーブルに対してクラスタリングを行う方法を調査したところ、BigQuery コマンドラインツールの”bq update”コマンドを使用することで可能とのことだったので、今回はこれを試してみます。
上記を参照すると、
| bq update –clustering_fields (クラスタリングに使用する列名のカンマ区切り列) (データセット名) . (テーブル名) |
こちらの実行することで既存テーブルに対するクラスタリングが可能なようです。
さっそくCloud Shellで試してみます。下記をCloud Shell上で実行します。
| bq update –clustering_fields category,month yamaguchi_test.event |
![]()
無事成功したようです。再度、eventテーブルのプロパティを確認してみます。
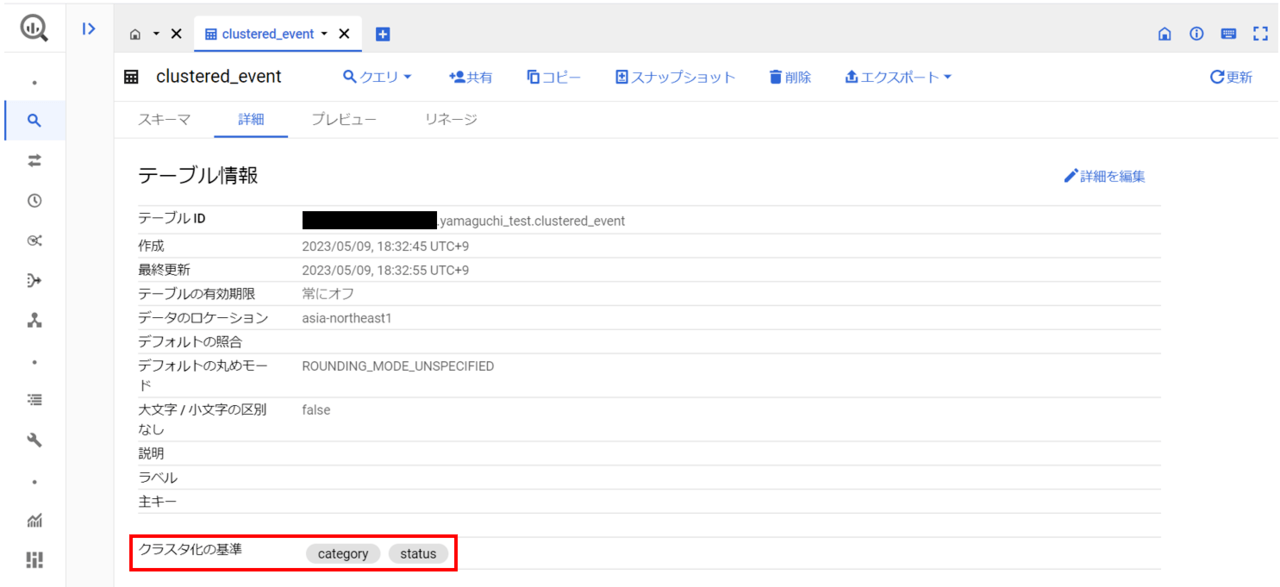
問題なくクラスタ化テーブルが作成できました。
クラスタリングの中身を覗いてみる
クラスタリングの処理を行うことで、テーブルの中身が一体どうなっているのかを見ていきたいと思います。
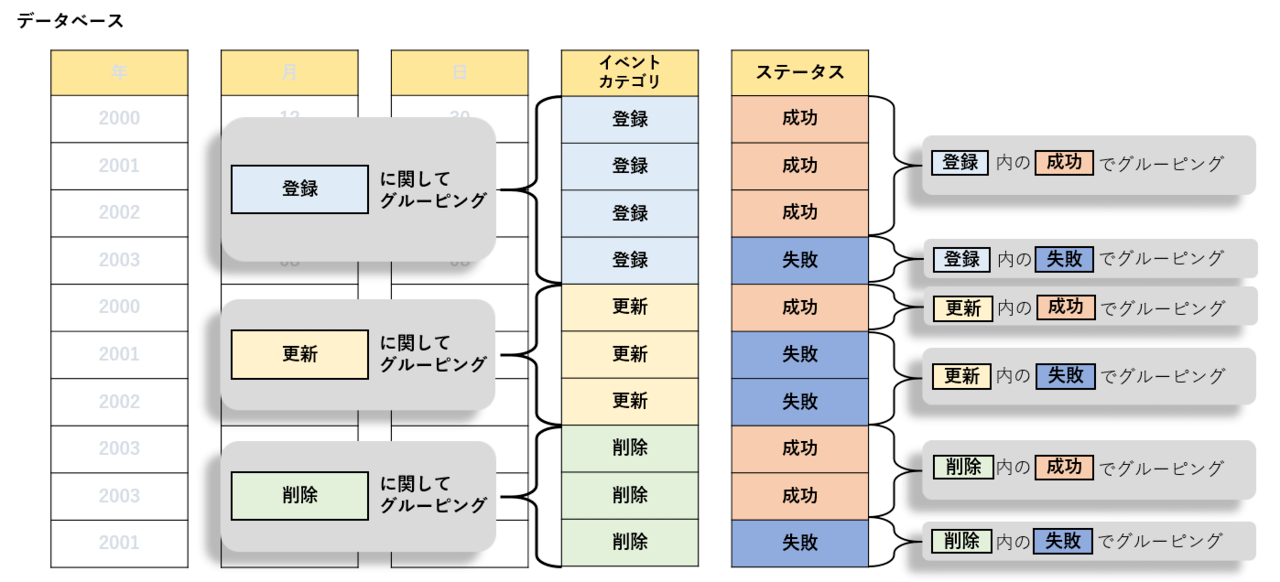
「データベース形式の分類」で例に挙げた表を再利用します。今回の登場人物は以下の通りです。
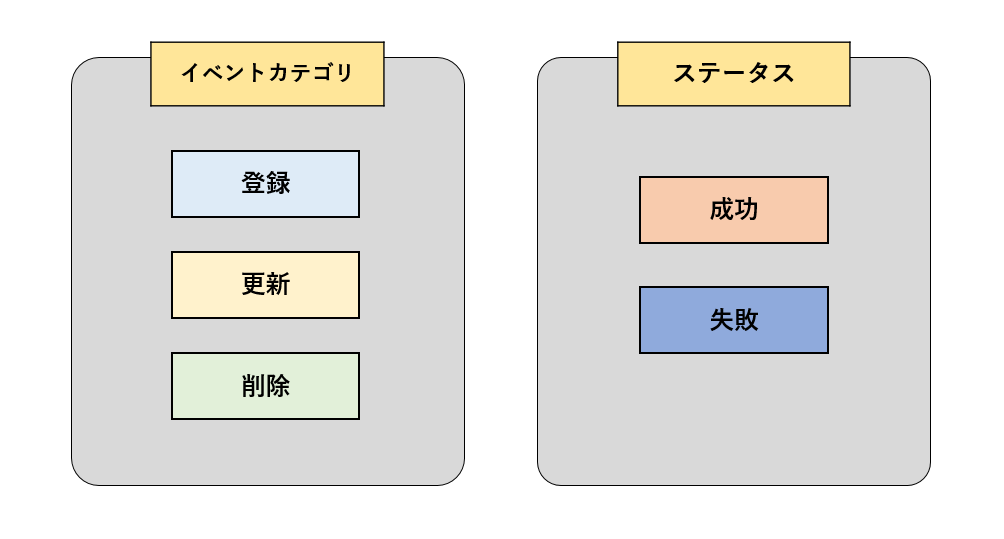
| [登場人物]
「イベントカテゴリ」スキーマ所属:登録、更新、削除 「ステータス」スキーマ所属:成功、失敗 |
わかりやすいように、「データベース形式の分類-列指向形式データベース」で使用したテーブル例を拡張し、上記登場人物をキャスティングします。
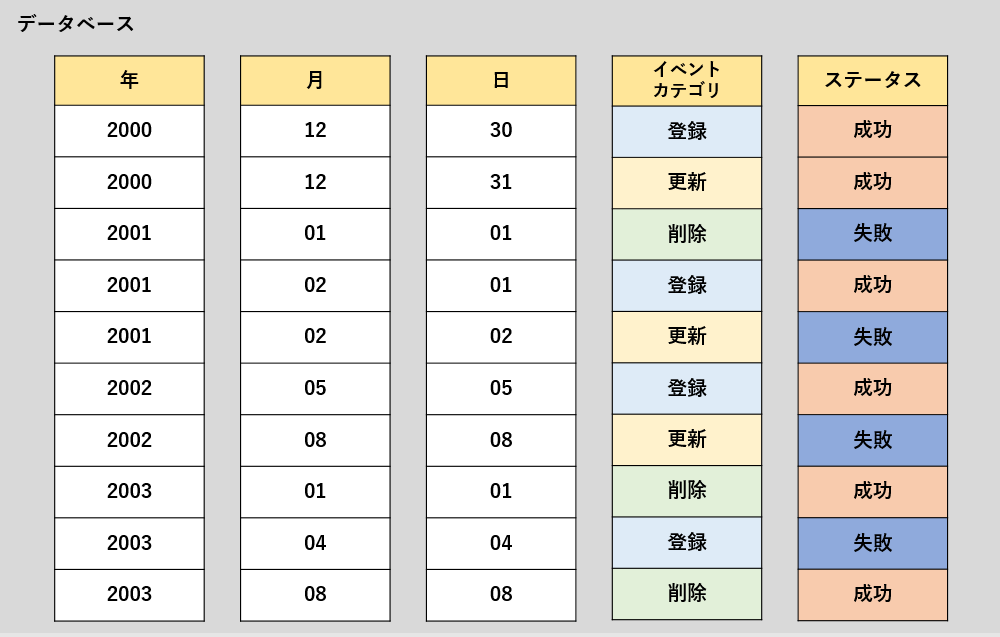
上記のテーブルに対して、「イベントカテゴリ」、「ステータス」でクラスタリングすると下記のような”クラスタ化”が行われます。
| Before(クラスタリング前) | After(イベントカテゴリ、ステータスでクラスタリング) |
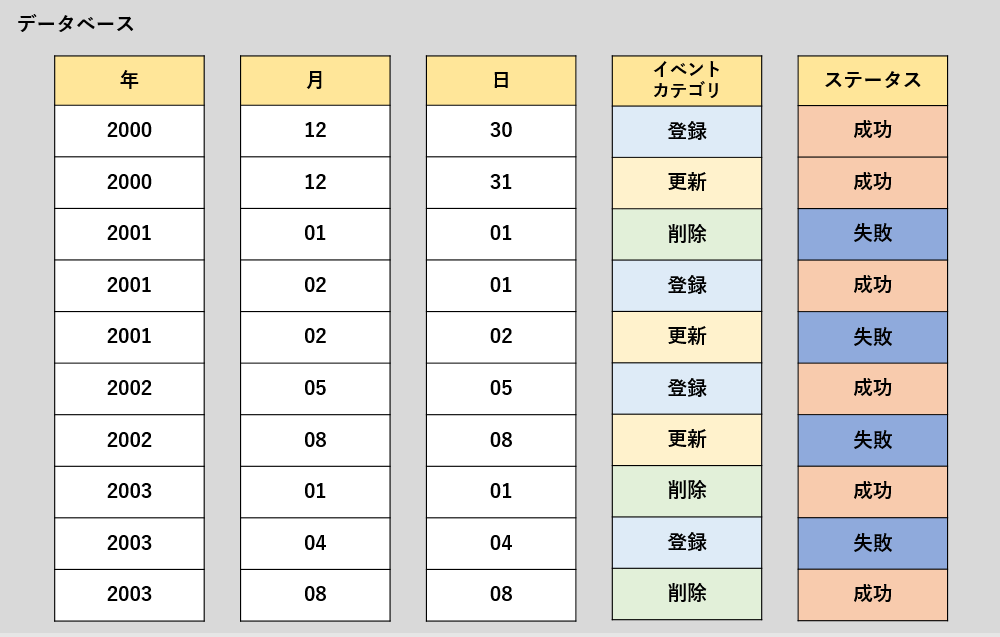 |
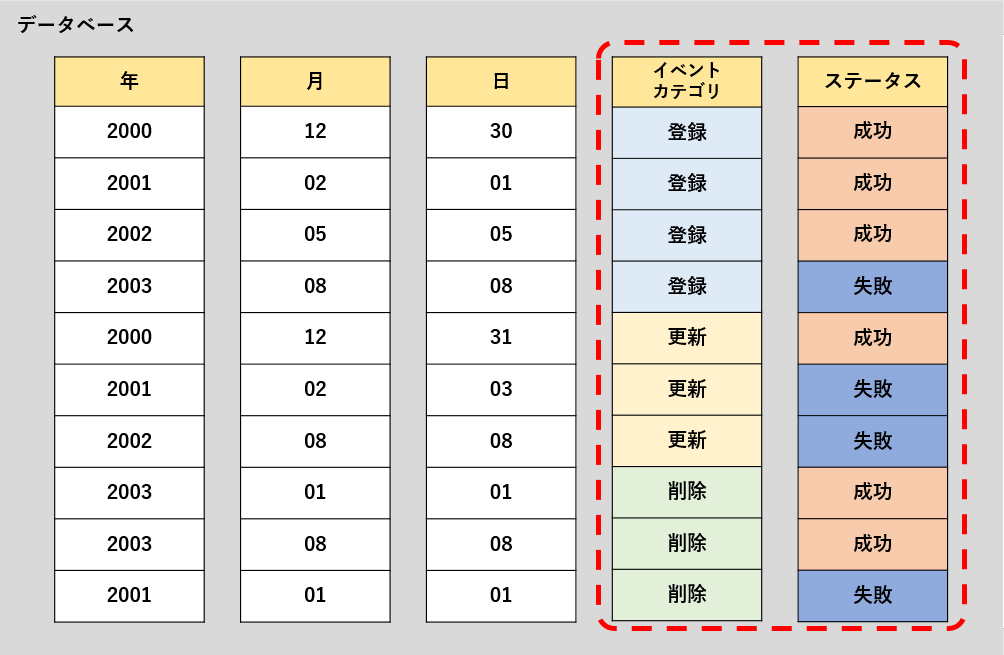 |
クラスタ化とさらっと言ってしまいましたが、要は下記のようなグルーピングのようなことが行われています。
クラスタリングによるメリット・推奨シーンは?
[メリット]
分析の際にクラスタリングされたテーブルを使用し、効率的なデータアクセスを可能にすることで、以下の効果を得ることができます。
- クエリのパフォーマンス向上
- クエリ費用の削減
クラスタ化テーブルの概要 | BigQuery | Google Cloud
[推奨シーン]
ここではクラスタリングの効果がより発揮されるシーンをご紹介します。
① 複数の列に対してフィルタするクエリがある場合
→クラスタリングでは分割基準を4列まで指定可能
② カーディナリティ(列に含まれる値の種類)が大きい列に対してフィルタするクエリがある場合
→クラスタ化により、入力データの取得先に関する詳細なメタデータが BigQuery で処理され、クエリが高速化される
逆に、以下の場面ではクラスタリングの効果がうまく発揮できないのでご注意ください。
〇クエリ費用を厳密に見積もる必要がある場合
→クラスタ化テーブルのクエリ料金は、クエリ実行後にしかわからない
〇クエリテーブルが1 GBより小さい場合
→通常、1 GB未満のテーブルではクラスタリングしてもパフォーマンスが大きく向上しない
まとめ
今回はBigQueryにおけるクラスタリングについて紹介しました。
過去にパーティショニングについてのブログも執筆しましたが、両者を状況によって使い分けることで、よりパフォーマンスを向上させることが可能になります。
パーティショニングとクラスタリングは互いに欠点もありますが、併用することが可能なので弱点を補完して使用することも可能になると思われます。