

 本記事は 新人ブログマラソン2024 の記事です。 本記事は 新人ブログマラソン2024 の記事です。 |
こんにちは。部署配属から4ヶ月が経ち、新人と名乗れる期間も少なくなってきていることに気づきました、SCSKの さと です。
最近、Datadog Learning Centerに新しいコース「Getting Started with Monitors」が追加されていることに気づいたので、本日はそのご紹介です。
Datadogとは
とはいえ、皆さんの中にはDatadogに馴染みのない方も少なくないのではないでしょうか。本題に入る前に、まずはDatadogとはどんなサービスか、安心と信頼の公式HPからの引用を用いて簡単に説明いたします。
Datadog はクラウド アプリケーションのための モニタリングとセキュリティ プラットフォームです。Datadog の SaaS プラットフォームは、インフラストラクチャ監視、 アプリケーションパフォーマンス監視、ログ管理を統合および自動化して、お客様のテクノロジースタック全体を一元的にリアルタイムで監視できるようにします。
つまり、クラウド上で動くアプリやシステムの健康状態をひとまとめにして分かりやすく監視することで、これらのIT環境に発生する問題を予防し、また問題が起こったときには原因を特定し素早く解決できるよう助けてくれるサービスですね。私の所属する部署では、クラウドサービスの監視にこのDatadogサービスを利用しています。
Datadog Learning Centerのここがすごい!

そしてこのDatadog、公式のLearning Centerで70近くあるコースを通してその概要から実際の設定方法まで学ぶことができるんです。さらには、コースによってはハンズオン用のラボ環境付き。しかも全部無料(ここ重要)!個人的にありがたいポイントは、公式のコンテンツであるため正確でありながら、ドキュメントよりも噛み砕いて説明されててとっつきやすいところ、そしてなにより手を動かして学ぶことで実感をもって内容を身につけられる点です。
そんな至れり尽くせりなDatadog Learning Centerですが、一つ玉にキズなところがあります。それは全部英語なところ。コースによっては一部日本語訳が表示されたりするのですが、特にハンズオンはページ翻訳も効かず、モニタリングを学ぶつもりが英語の勉強になっていたりします。
しかしそんなことで怯んでいてはもったいない!せっかく用意されたコース、モリモリ学んで使い倒しましょう!
やってみた:Getting Started with Monitors

……という訳で改めて、本記事では新しく開講された「Getting Started with Monitors」に沿って、モニタリングの基本的な概念とこれらをコース上でどのように触っていけるかを説明したいと思います。このコースは、入門講座「Introduction to Observability」で扱われる可観測性の3つの柱であるメトリクス、ログ、トレースの概念について基本的な理解をしていることを前提としています。
目安の受講時間は1.5時間ですが、じっくりハンズオンに取り組みたい人は2〜3時間楽しめる内容になっていると思います。
【講義パート】モニターの種類
Enrollを押してコースを開始すると、まずは扱う概念をテキスト形式で学びます。
サービス監視
サービスの監視においては、以下に示す「REDメトリクス」をモニタリングするのが基本です。これらは特にユーザーリクエストの処理を扱う場合に有用な情報を提供してくれます。メトリクスについては本記事の後半でも扱うのでざっくり説明すると、「システムやアプリの状態を数値データとして表したもの」であり、定期的に収集されてタイムスタンプとともに記録され、しばしばグラフの形で可視化されます。
| Rate | レート | ユーザーやサービスから発せれられるHTTPリクエスト、APIコール、DBクエリなどの数。これが急激に変化していたら、突然のトラフィック増加やDDoS攻撃、リクエスト元のシステムの障害など、なんらかの問題が起こっているかもしれません。 |
| Error | エラー | 5xx系のサーバーエラーやAPIコール、DBクエリの失敗などのこと。これを辿ることで、アプリケーションあるいはバックエンドの問題を特定できます。あるいは、これをチェックすることで、ユーザーが問題に直面しているかを知ることができます。 |
| Duration | 時間 | リクエストの処理にどれくらいの時間がかかるか(レイテンシー)。サービスの応答性を示し、ユーザーに影響が出始めるまえにボトルネックを見つけるのに役立ちます。 |
インフラストラクチャ監視
インフラストラクチャの監視は、アプリケーションやサービスを支えるシステムが期待通りの働きをしているかを確認するのに不可欠です。主な監視対象は以下のとおりです。
| CPU使用状況 | system.cpu.[…] のメトリクスで監視可能。物理あるいは仮想マシンが過不足なく使用されているかを示します。CPUの使用率が高すぎるとシステムの速度低下やアプリケーション障害の原因となり危険な一方で、使用率が低すぎるのもリソース割り当てが非効率なことを示しており、好ましくありません。 |
| メモリ使用状況 | system.mem.[…] のメトリクスで監視可能。過剰にメモリ使用がされていると、メモリリークやクラッシュ、システム遅延の原因となります。これを監視することで、問題の早期発見とシステムダウンの予防になります。 |
| ストレージ | system.disk.[…] のメトリクスで監視可能。ディスク容量が不足すると、サービスの中断、データの破損、ログ書き込み不可の原因となります。これを監視することで、システムが正しく機能するための容量があることを保証します。 |
ハンズオンラボの説明
上の内容についてハンズオンを通して学ぶ前に、一旦ハンズオン環境について説明します。ハンズオンを立ち上げると、ローディング画面には以下のようなあらすじが表示されます。
You joined a startup, Storedog, and they are using Datadog to monitor their e-commerce app. They just installed the Datadog Agent and now they want to start monitoring their tech stack. You’ve been tasked with creating a robust monitoring setup to get complete visibility into your infrastructure and application performance.
(君は、スタートアップ企業Storedogの一員となった。Storedogでは、eコマースアプリケーションをモニタリングするのにDatadogを使っている。たった今、Datadogエージェントがインストールされ、彼らは技術スタックのモニタリングを始めようとしている。君の任務は、堅牢なモニタリングの仕組みを作ってインフラストラクチャおよびアプリケーションのパフォーマンスをまるごと可視化することだ。)
この裏ではハンズオン環境が立ち上がっており、1分ほど待つとこの環境にアクセスできるようになります。本コースでは、ラボ環境は2時間有効です。また、14日間有効なDatadogのトライアルアカウントが払い出され、ターミナルに認証情報が表示されます。これをDatadogのウェブサイトに入力することで、Datadogのコンソールにアクセスできるようになります。
右上には、この環境を使用できる残り時間が表示されています。これが0になると環境はシャットダウンされますが、再度の立ち上げが可能です。この時、同一アカウントの試用期間内であれば既に登録したモニター等の設定は保存されます。さらに、Datadogのトライアルアカウント自体も試用期間が過ぎた後に自動で更新されます。
なお、Storedogのeコマースサイトはモックアップではあるものの、ラボ画面から本当にWebサイトにアクセスすることが可能です。
モニターを作成してみる
それでは、早速Datadogを使ってモニターを作ってみます。モニターの種類は色々ありますが、ここではオーソドックスなメトリクスのモニターを作成します。
フォームを使ってゼロからモニターを作成する
Monitor > New Monitorからメトリクスモニターを選択します。
1. 検出方法の選択
まずは、どのように測定を行うかを決めます。モニターの種類によってその後の設定項目は変わってくるのですが、ドキュメントページではタブ形式でその後何を設定すればよいか一目で分かるようにしてくれています。便利!
今回は、しきい値を選択し、メトリクスが一定の水準を上回った(下回った)場合にアラートを発報するようにします。

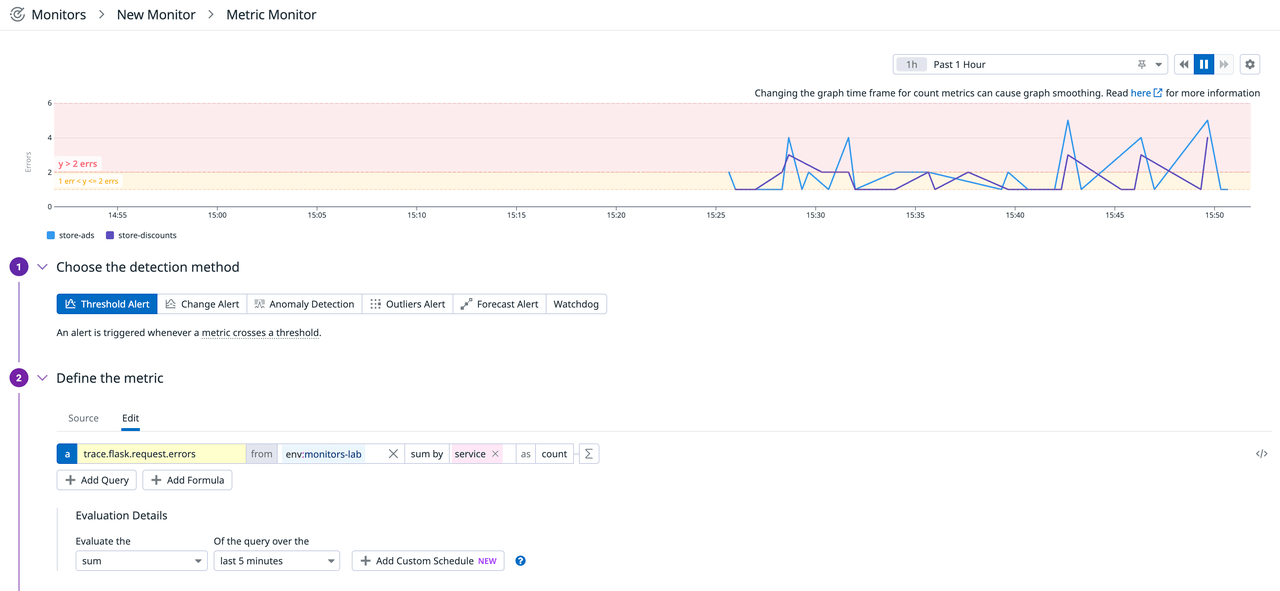
2. メトリクスの定義
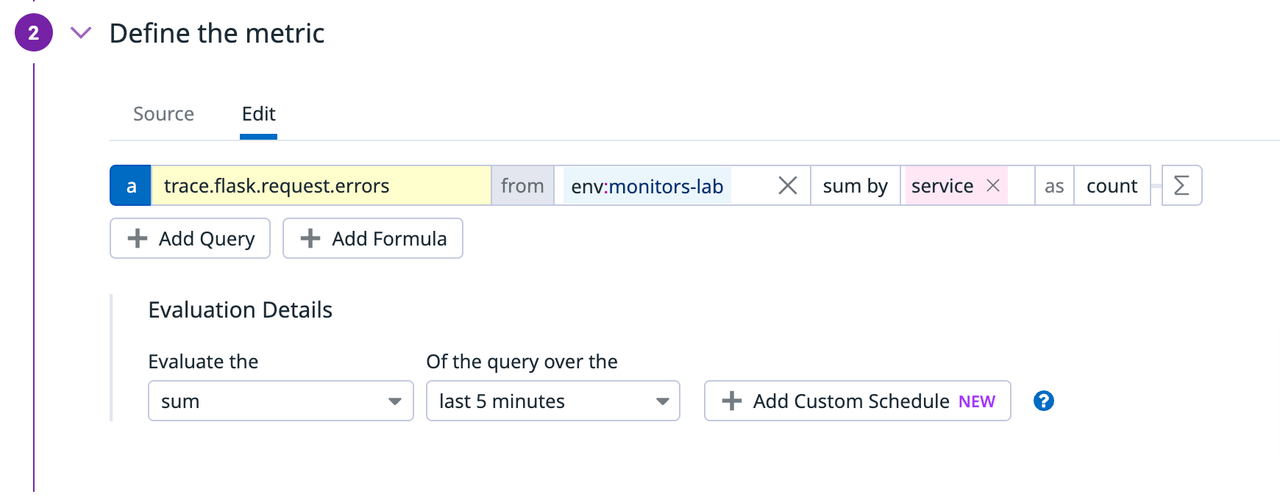
ここでは、メトリクスを選択することで何の値をモニタリングの対象とするか、そしてそのグルーピングの仕方について設定を行います。今回は、monitors-labという環境タグがついたtrace.flask.request.errorsメトリクスの和をサービスタグごとにとっています(この環境では、store-adsとstore-discountsという2つのサービスが動いています)。
その下(評価の詳細)では、更に値の集計関数を規定しています。ここでは、上記グルーピングされたエラー数の過去5分の和を評価の対象としています。
3. アラート条件の定義
どのような場合にアラートを発報するか、条件を指定します。しきい値の場合は、値がいくつより大きい/以上/以下/より小さい/等しい/等しくない場合にするかを指定します。

条件を入力すると、画面上部に表示されていたメトリクスのグラフと共にしきい値を表すラインが表示されました。
4. 通知の設定
通知設定では、変数を用いたカスタムの通知メッセージを作成できます。このメッセージは、メールの他にSlackなどを宛先とすることができます。今回は、ハンズオンの例と同じように変数を使わないシンプルなメッセージにしています。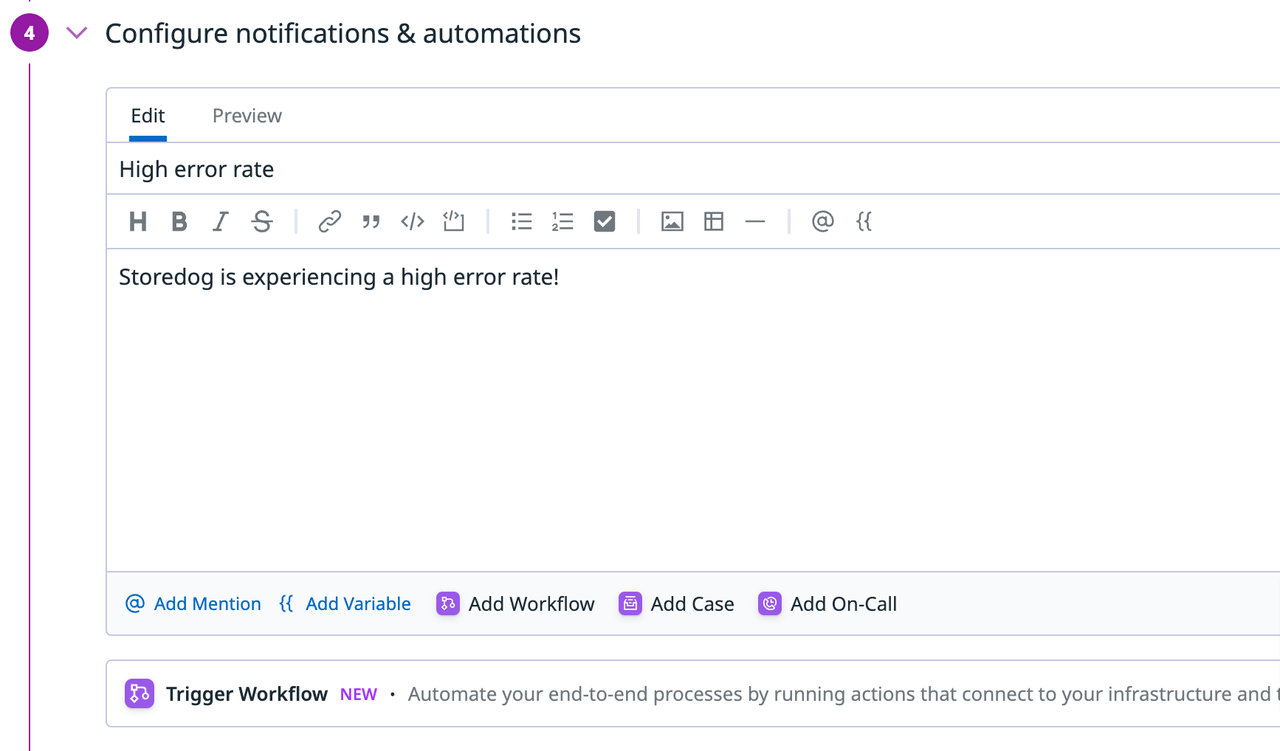
5. 権限設定
モニターは、ユーザーの権限にかかわらず全員が見ることができます。またデフォルトでは、モニター編集権限を持っているユーザーが編集できるのですが、ここの項目では更にきめ細やかなアクセス制御をすることができます。
設定し終わったら、Createを押して作成完了です。
モニターのステータスを確認する
Createを押すと、モニターのステータス画面に遷移します。作成したモニターの状態を確認してみましょう。
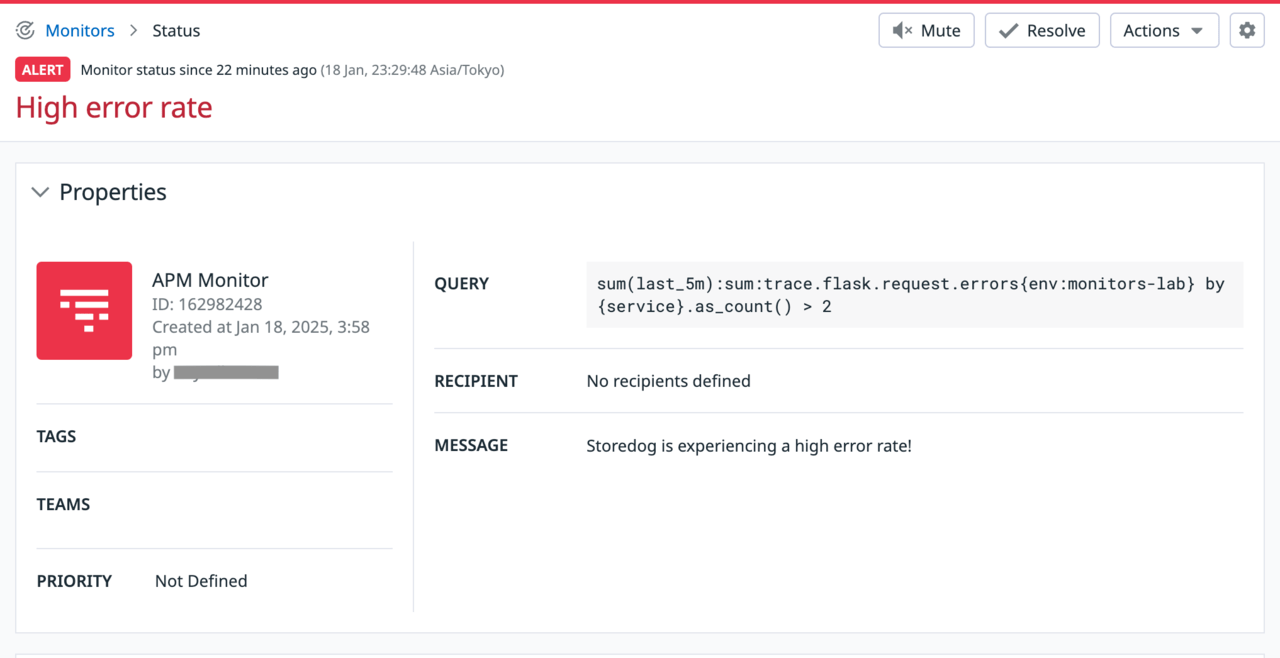
ヘッダー・プロパティ
ヘッダーでは、モニターの状態(OK/警告/アラートなど)が示されます。また、上部右側のボタンからは、アラートのミュートや解決ができます。なお、解決を押すとモニターは一時的に解決になりますが、再度メトリクスの値が評価された際にアラートの条件に当てはまっていれば再びアラート状態に移ります。プロパティでは、モニターの状態のほか、種類、作成時刻などのメタデータを確認可能です。
ステータスと履歴
ステータスと履歴のセクションでは、どのようにモニターの状態が移り変わってきたかを確認できます。
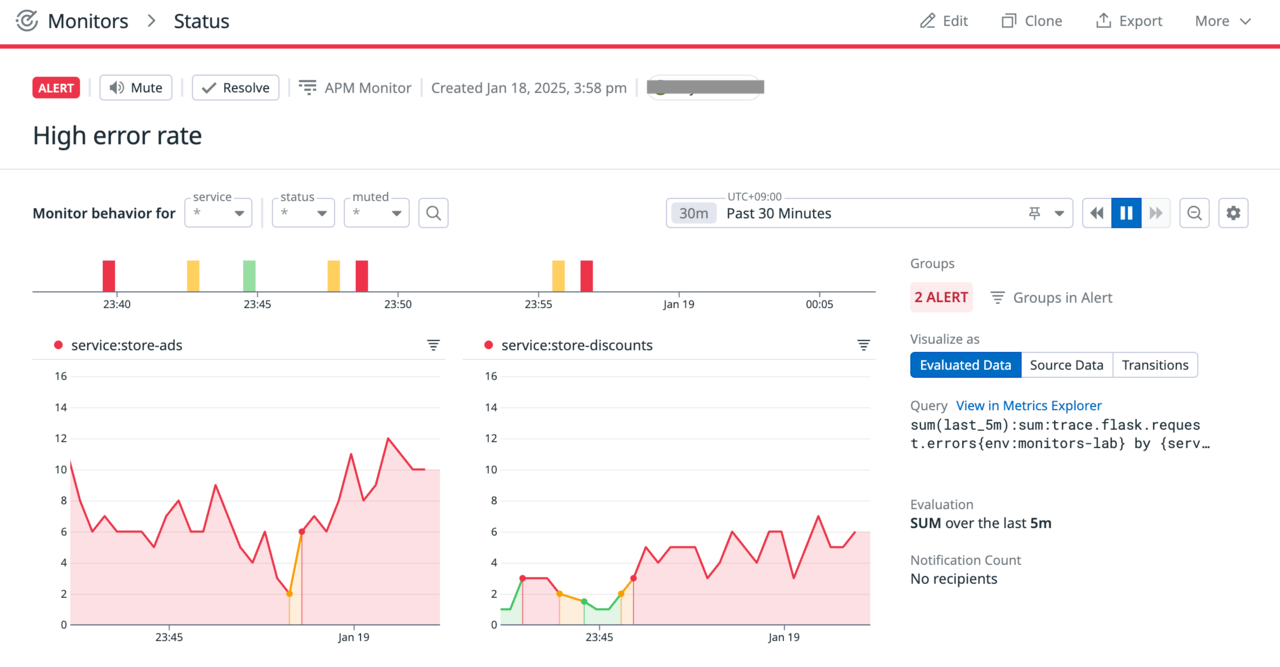
グループステータスのグラフでは、グループ化されたモニターのそれぞれについて状態が棒グラフで表示されます。今回は、store-adsとstore-discountsでグルーピングを行っているので、これらのグラフが表示されました。その下には、いつエラーが起こったのかを示す履歴グラフが表示されています。アラート時の挙動を見るためにしきい値を低く設定しているため、23:30頃のモニター作成とほぼ同時にアラート状態になっていることが分かります。
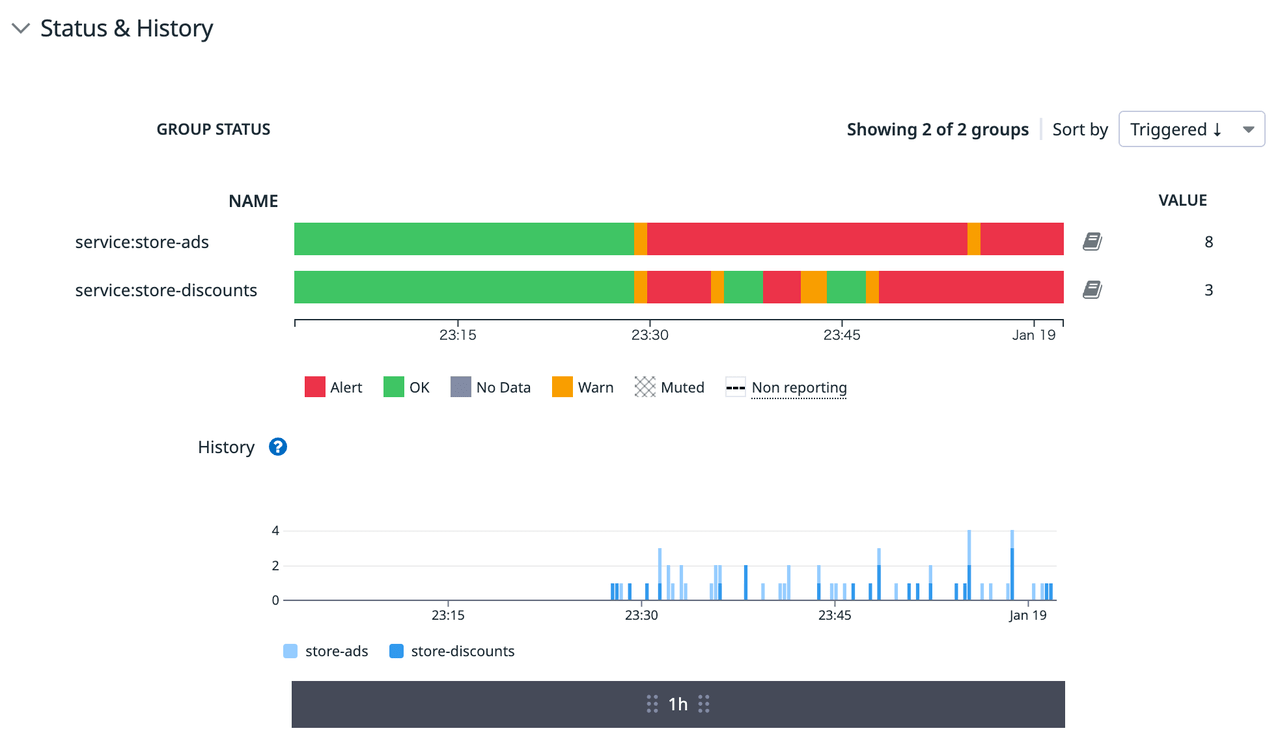
更にその下にあるのは評価グラフです。履歴グラフが生データ(未加工のデータ)を表示しているのに対し、評価グラフではこの生データに対して前述の手順「メトリクスの定義」の「評価の詳細」において定義済みの集計関数を適用した結果の値がアラート条件とともに視覚化されています。すなわち、今回の設定では過去5分間のエラー数の和がしきい値とともに示されています。

参考:新UI
ステータス画面はまもなく新しいものに切り替わる予定です。
新しいUIでは、Visualize asの下の選択を切り替えることで生データのグラフ、評価値のグラフ、状態変化のグラフを表示することができます。
おわりに
いかがでしたか?「Datadogのコースで学んでみたいけど、英語だからちょっとなぁ…」と思っている方にとって、この記事が足がかりとなれば幸いです。
ここまでお読みいただき、ありがとうございました。