

こんにちは。SCSKの山口です。
今回は、Google Cloud認定資格の受験レポート その①です。
はじめに
先日、Google CloudのAssociateレベルの認定資格として、下記二つの認定資格が追加されました。
に関しては、前身となるProfessional Workspace Administrator を取得済みであれば有効期限が切れるまでは何とかなるようです。
問題は「Associate Data Practitioner」です。
情報収集として、社内で受験済みの人がいないか探し回っていますが、本ブログ執筆時点で見つけ切れず、なんとか自力で対策するしかなさそうです。。。というわけで、今日から対策を始めようと思ったのですが、「せっかくだから受験前後でブログ書いてみよう」と思いつき、今日から執筆を始めました。
受験前後のブログではそれぞれ下記を書こうと思っています。
・対策内容
・抑えておく要点
・合否
・出題内容(受験前の想定とのギャップ)
・抑えておいた方が良い要点
- Google Cloud歴 3年目
- BigQuery一番よく触っている
- Professional Data Engineer取得済み
- 最新のTOEICスコア:645(※試験が英語版しかないので書きました。)
対策内容
ここでは、受験前に実際に取り組んだ対策の内容を書きます。
とりあえず試験ガイドを見てみる
試験ガイドは、認定資格ページにリンクが貼ってあります。
https://services.google.com/fh/files/misc/v1.0_associate_data_practitioner_exam_guide_english.pdf?hl=ja
英語があまり堪能ではないので、PDFでダウンロードして「NotebookLM」にアップして日本語で読みました。
ドキュメントをほとんど翻訳しただけの内容を書きますが、あまり深読みせず、「こんな感じのが問われるんだな。」と大まかな内容を把握するために使いました。
①データ準備と取り込み(~30%)
このセクションでは、その名の通り「データの取り込み~利用可能な状態にするまでのプロセス」に焦点が当てられています。
- データ処理方法(ETL,ELT,ETLT)の理解と適切な選択
- データ転送ツールの適切な選択
- データの品質評価とクレンジング
- データ形式の識別とストレージ選択
この辺りが問われるそうです。
②データ分析とプレゼンテーション(~27%)
このセクションでは、データの分析、可視化、機械学習モデルの活用に関する知識とスキルに焦点が当てられます。
- BigQueryとJupyter Notebookを用いたデータ分析
- Lookerを用いたデータ可視化とダッシュボード作成
- 機械学習モデルの定義、トレーニング、評価、利用
この辺りが問われるそうです。
③データパイプラインのオーケストレーション (~18%)
このセクションでは、データパイプラインの設計、実装、自動化、監視に関する知識に焦点が当てられます。
- 適切なデータ変換ツールの選択
- ELTとETLの使い分け
- データ処理タスクのスケジュール、自動化、監視
- イベントドリブンデータ取り込みの活用
この辺りが問われるそうです。
「ELTとETLの使い分け」に関しては、①のデータ処理方法と重複しているように見えますが、ここではETLとELTのユースケースを評価した上での適切な選択が求められるようです。
④データ管理(~25%)
このセクションでは、アクセス制御、ライフサイクル管理、高可用性と障害復旧、セキュリティ対策とコンプライアンスなど、データ管理の重要な側面に焦点が当てられます。
- アクセス制御とガバナンス
- ライフサイクル管理
- 高可用性と障害復旧
- セキュリティ対策とデータプライバシー規制への準拠
この辺りが問われるそうです。
とりあえず模擬試験を受けてみる
模擬試験は、認定資格ページにリンクが貼ってあります。

試験の詳細な内容はここには載せませんが、正解率は12/20でした。(まずい、、、)
英語なのもあり、ちょっと難しく感じます。
ここまでの内容をふまえ、受験前に抑えておいた方が良いと思われる(実際に学習した)内容を書きます。
抑えておく要点
試験ガイドと模擬試験の内容を加味し、試験前にこれだけは押さえておこうと思っている内容を書きます。
ETL/ELT で登場するサービス
本試験には、ETL/ELTを実現するために使用する多くのサービスが登場しそうです。
登場しそうなサービスと特徴、ユースケースを私がわかる範囲でまとめます。
| サービス名(元名称) | 機能概要 | 特徴・ユースケース |
|---|---|---|
| Dataflow(Apache Beam) | 大規模なデータ処理パイプラインを構築・実行するためのフルマネージドサービス
データの検証とクリーニング |
|
| Dataproc(Apache Hadoop、Apache Spark) | Apache Hadoop および関連エコシステムをクラウド上で実行するためのマネージドサービス |
|
| Data Fusion | コード不要でデータ統合・変換処理を構築するためのクラウドネイティブETLサービス |
|
| Cloud Composer(Apache Airflow) | 複雑なワークフローを定義・管理するフルマネージドワークフローオーケストレーションサービス |
|
試験で特に重要になりそうなのが、「元名称」と「特徴・ユースケース」です。
元名称は、例えば、「Apache Hadoopの処理を移行したい」など、移行元のワークフローが特定されているような問題の際に使えます。この場合は「Dataproc」を使用している選択肢に絞り込むことができます。
元名称で特定できない場合に、「特徴・ユースケース」の知識を使います。問題文中の要件に合わせてサービスを選択できます。
ETL/ELTの使い分け
模擬試験の内容を見る限、割と明確に処理の順序が記載されている(Loadする前にTransformしたい。とか)ので、軽く表にまとめます。
| 方式 | 処理順序 | メリット | デメリット |
|---|---|---|---|
| ETL | 抽出 → 変換 → ロード |
|
|
| ELT | 抽出 → ロード → 変換 |
|
|
Data Fusionを使うかどうか
試験問題を解く際、数を熟していくと「これはData Fusion使う必要あるのか、、、?(スケジュールクエリとかで事足りるのか、、、?)」という分かれ道に立つことが多くなると思います。
その際に使える判断基準の例を書いておきます。
・データソースはどこか?(BigQuery or その他)
・問題に登場するユーザのスキルは?(SQLに精通、開発経験がない、GUIで開発したい、など)
・重複排除
・データフォーマット統一
BigQuery
BigQueryは他試験でもかなり多く目にするGoogle Cloudの目玉サービスの一つですが。本試験でもかなり多くの問題に登場しそうです。
模擬試験の出題内容から、抑えておいた方が良いと思われる項目を書きます。
アクセス制御
BigQueryのアクセス制御は、ユーザに行わせる(許可する)アクションに合わせて下記ロールを付与する必要があります。
| 許可する処理 | 必要なロール |
|---|---|
| データ閲覧(読み取り) |
|
| データ編集(読み取り+書き込み) |
|
SELECTのようなデータの閲覧しか行わないユーザには「閲覧者」
UPDATEのようなデータの編集を行うユーザには「編集者」を付与する必要があります。
また、上記どちらのユーザも「クエリの実行」は行うので、「ジョブユーザ」を付与する必要があります。
暗号化
Google Cloud内のデータは、基本的にGoogleが管理する暗合鍵(GMEK)でデフォルトの暗号化がされています。
一方で、暗号化に顧客管理の暗号鍵(CMEK)を使用することもできます。CMEKを使用することで、複雑な暗号化要件に対応することもできます。詳細は公式ドキュメントをご参照ください。
似た用語で、顧客提供の暗号鍵(CSEK)があります。CSEKは顧客がGoogleのインフラストラクチャ外で暗号鍵を管理できるため、Googleから暗号鍵にアクセスされたくないような厳格な規制要件がある際に使用されます。
本試験では、GMEK、CMEK、CSEKに加えて「認証付き暗号化(AEAD)」も取り扱われるようです。
AEAD 暗号化関数を使用すると、暗号化と復号に使用する鍵からなる鍵セットを作成し、これらの鍵を使用してテーブル内の個々の値を暗号化および復号できます。
たとえば、BigQueryテーブルの列レベル、行レベルで暗号化を適用する。みたいな使い方が可能です。
パーティショニング
BigQueryには、日時のカラムでデータを論理的に分割するパーティショニング機能があります。詳細は過去ブログをご覧ください。

本試験では、パーティショニング機能を活用したGoogle Cloud内でのデータの整理が出題されるようです。たとえば、下記のような要件、実現方式があります。
・BigQueryに分析用のデータをため込んでいる
・最初の一年間は分析に利用される(頻繁にクエリされる)
・一年経過後は、長期保管に切り替える
・BigQueryをパーティション分割する(月単位)
・一年経過後にCloud Storageへエクスポートする
公開データセット
BigQuery には一般公開データセットと呼ばれる一般提供のデータセットが用意されています。
- 世界の気象データ
- 国勢調査データ(アメリカ)
- 小売店の販売実績データ
など、様々な種類のデータが大量に用意されており、なんとGoogleがこれらの保存費用を負担してくれています。
我々ユーザは、これらのデータへアクセスし、様々な用途に使用することができますが、もちろん「クエリ料金」は発生します。
むやみにエクスポートやコピーをしてしまうと膨大な料金が発生してしまう恐れがあるので、必要に応じて「参照」だけを行うことが推奨されます。
Cloud Storage
これまた他試験でも馴染みのあるサービスですが、知識が必要になりそうなところがあるので説明します。
冗長化と高可用性
GCSのデータの冗長化、高可用性を実現する方式は、下記の二つがあります。
- マルチリージョン
- デュアルリージョン
かなり似た概念で、混乱すると思うので下記表でまとめます。どちらも、複数のリージョンにデータを複製する手法です。
| マルチリージョン | デュアルリージョン | |
|---|---|---|
| データの場所 | 複数の大陸にまたがる2つ以上のリージョン
例)アジアとヨーロッパのリージョン |
特定の2つのリージョン
例)アジア内の二つのリージョン |
| 可用性 | 非常に高い(広範囲な障害に対応) | 高い(リージョンレベルの障害に対応) |
| レイテンシ | グローバルアクセスに最適 | 特定の地域へのアクセスに最適 |
| コスト | 高 | (マルチリージョンと比較すると)低 |
| ユースケース | グローバル、ミッションクリティカルなアプリケーション | リージョンレベルの障害対応、地域特化型アプリケーション、データ所在地規制 |
ストレージクラス
Cloud Storageにはストレージクラスと呼ばれるオプションがあり、保存するデータの性質によって適切な選択をすることでコストパフォーマンスを最大化することができます。
BigQueryの章で紹介したパーテイショ二ングと組み合わせることで、要件に合わせた高コスパなデータ保管が実現できます。
また、オブジェクトに対する操作の状況に応じて自動的にストレージクラスを設定することができる「オートクラス機能(Autoclass)」といった便利なものも存在します。
各クラスの概要は下記のとおりです。
| ストレージクラス | 最小保存期間 | オペレーション料金 | ストレージ料金(GB/月)※東京リージョン | データ取得にかかる時間 |
|---|---|---|---|---|
| Standard | なし | なし | $0.023 | 高速 |
| Nearline | 30日 | $0.01/GB | $0.016 | 高速 |
| Coldline | 90日 | $0.02/GB | $0.006 | 数分以内 |
| Archive | 365日 | $0.05/GB | $0.0025 | 数時間以内 |
最小保存期間
Standard以外のクラスには「最小保存期間」が設定されています。
オブジェクトがバケットに保存された後、削除や移動を行った場合でも、各storageクラスで定められた最小保存期間分の料金が発生します。
例えば、Nearlineのバケットに保存したオブジェクトを10日後に削除した場合でも、30日分の料金が発生します。その分、移動等をせず保存しておくだけなら料金が抑えられるってことですね。
オペレーション料金
Standard以外のクラスには「オペレーション料金」が設定されています。
バケットに保存されたオブジェクトデータ(またはメタデータ)を読み取り、コピー、移動、書き換えする際に発生します。
長期保存(Archive)の予定だったけど、思いのほかオペレーションの対象になってしまった。となると、割高な料金が発生してしまいます。
データ転送ツール
BigQuery Data Transfer Service(BDTS)
BDTSは、あらかじめ設定されたスケジュールに基づいて BigQueryへのデータの移行を自動化するマネージドサービスです。
下記を使用することが可能です。
- Google Cloudコンソール
- bqコマンドラインツール
- BigQuery Data Transfer Service API
サポートされているデータソースの全容は公式ドキュメントをご参照ください。Googleのサービス(Google広告、Youtubeなど)だけでなく、AWSやSalesforce、Olacleのサービスのほか、オンプレミスからの転送もサポートしている点は把握しておく必要があります。
Storage Transfer Service(STS)
STSを使用することで、オンプレミスや他ストレージサービスから、Cloud Storageへのデータ移動をシームレスに行うことができます。
下記の特徴があります。
- データ転送を自動化:手動プロセス、カスタムスクリプトが不要
- 大規模データ転送:ペタバイト単位のデータも移動可能
- ネットワークパフォーマンスを最適化:シンプルさを求めるならマネージド転送。ルーティングと帯域幅を制御したいなら自己ホスト型エージェントを使用
- 移行ステータスの確認が可能:移行ステータスの詳細なレポートを取得可能
Transfer Appliance
Transfer Applianceは、Googleアップロード施設に転送して安全にデータを保存できる大容量ストレージデバイスで、データはGoogleアップロード施設からCloud Storageにアップロードされます。
実際には、下記手順で実施します。
- Transfer Applianceをリクエスト:要件に適したアプライアンスを選択
- データをアップロード:アプライアンスにデータをアップロード
- Transfer Appliance を返送:データアップロード完了後、アプライアンスを返送する
- Google がデータをアップロード:Cloud Storage バケットにデータがアップロードされる
代表的なユースケースとしては、下記が考えられます。
- インターネット経由のデータ移動に時間がかかりすぎる場合
- データ移動に使用できる帯域が十分に確保できない場合
- オフラインでのデータ移動を行いたい場合
- セキュリティ要件が高い場合
Looker
模擬試験を解いて、一番驚いたのが「Looker」に関する出題です。
ここでは要点だけ書きますが、Lookerが初耳の方は公式のドキュメントをご確認ください。
Lookerは、一言で言うと「可視化ツール(BIツール)」です。LookMLというモデリング言語を使用し、SQLデータベース内のデータを使って、ビジネスユーザーが理解しやすい形でデータ分析を行うための土台を作ります。
LookML の概念と用語については、下記公式ドキュメントにまとめられています。
実際の画面もあるので、Lookerが触れる環境がない方にもおすすめです。

LookMLの主な要素
Lookerでは、Viewファイル内でDimensionとMajorを定義し、データを集計・分析します。
- Explorer:ユーザが実際にでーあを探索、分析するためのインタフェースを定義する。
- View:データベースのテーブルやビューを指す。分析の対象となるデータを定義する。
- Dimension:分析の軸(観点)となる項目(日付、地域、商品名など)を定義する。
- Major:集計、計算される値(売上、利益、顧客数など)を定義する。
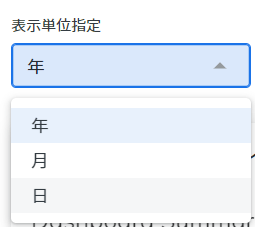
例えば、Lookerダッシュボードで上図のようなフィルタを作りたい際は、
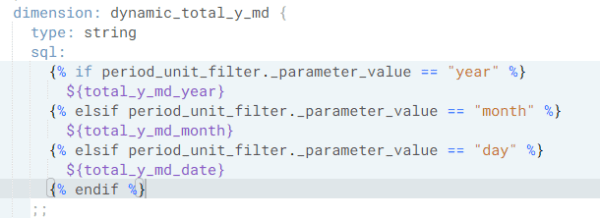
- LookMLで「Dimension」の作成
- Lookerの「Explorer」でフィルタの作成
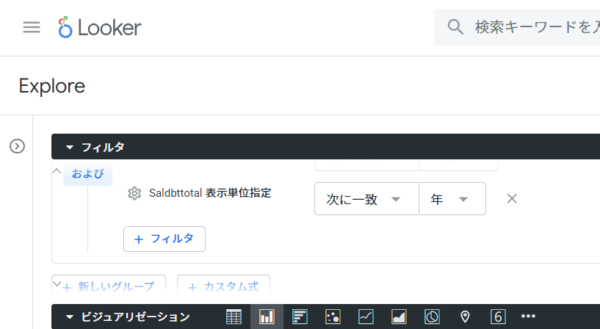
をする必要があります。
Lookerでのアクセス制御
LookerではGoogle CloudのIAMと同様、ユーザを「グループ」でひとまとめにし、まとめて権限を付与することができます。
Google Cloud同様、Lookerにおいてもグループへの権限付与がベストプラクティスとされています。
まとめ
いったん、ここまでの内容(+これまでの知識)で試験挑んできます。
更新なかったら察してください、、、