

こんにちは。自称ネットワークエンジニアの貝塚です。SCSKでAWSの内製化支援『テクニカルエスコートサービス』を担当しています。
先日、EC2 Amazon Linuxを使って検証をしておりまして、付け焼刃でネットワーク周りの設定ファイルを変更してOSを再起動したところ、インスタンスに接続できなくなりました。その時回復するためにやったことを本稿にメモとして残したいと思います。
まずは状況整理
使用していたOSはAmazon Linux 2023。AWSの公式AMIから作成したものです。
OSにはセッションマネージャーを使用してログインしていました。OSのIPアドレス周りの設定を変更しOSの再起動をしたところ、セッションマネージャーで接続ができなくなりました。細かい切り分けはしていませんが、状況的にインスタンス側のネットワークの問題と断定してよいでしょうから、sshなどIPアドレスを使ってログインする手段はいずれもダメだと考えられます。
EC2シリアルコンソール
何か手段なかったか……?と考えていたところ、そういえばシリアルコンソールの機能があったな、と思い当たります。でも普段使っているEC2ではシリアルコンソールの接続ボタンは押せなかったような記憶が……などと考えつつ、藁にもすがる思いで画面を開きます。
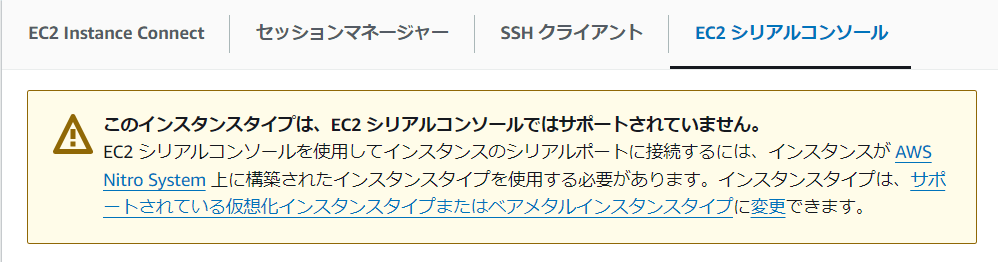
Nitroかあ……。実はNitro Systemというのにあまり興味がなく、どのインスタンスタイプがNitroなのか全く知りません。まずは調べるところから。

T3がNitroのようです。……よかった。どんな高額インスタンスが必要なのかドキドキしてしまいました。t2.microが好きすぎてT3すらほとんど使ったことありませんでした。早速インスタンスタイプを変更して起動。今度は接続ボタンが押せるようになっていて、一安心。コンソールを流れていく文字列を眺めていると、cloud-initが169.254.169.254に接続できません、みたいなログが出ています。やっぱりネットワーク設定が悪かったんだな、さてどこをどう直せばいいのだろうな……
![]()
あー……パスワード設定してあるユーザ、いないですね。
ルートボリュームのデタッチ&アタッチ
レスキューモード(エマージェンシーモード?)で起動すればいける気がするけれど、GRUB起動メニューにアクセスしなければいけないはずで、シリアルコンソールの画面を起動したときにはとっくにOS起動処理が始まっていたから、EC2ではGRUB起動メニューにアクセスできないのかなあ。あ、そういえばEC2ではルートボリュームをデタッチして別のインスタンスにアタッチできると聞いたことがあるような。
少々検索し、こちらの記事にたどり着きます。

まさに探していた情報そのものです。レスキュー用のLinuxインスタンスを準備し、早速試します。
- インスタンス一覧から起動しなくなったインスタンスをチェックし、「ストレージ」タブからルートボリュームを特定。
- ルートボリュームを選択し、アクション→ボリュームのデタッチを実行。
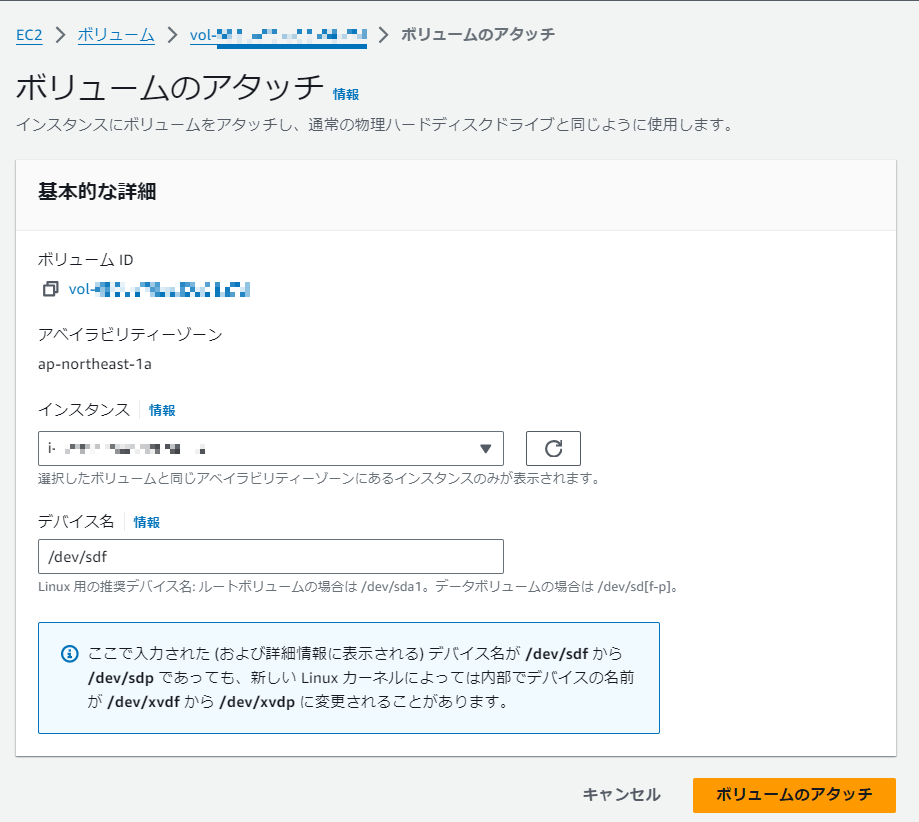
- レスキュー用インスタンスにアタッチするために再度そのボリュームを選択し、アクション→ボリュームのアタッチを選択。
一覧からレスキュー用インスタンスを選択。デバイス名はデフォルトで表示されていた/dev/sdfとしました。(スクリーンショットに表示されているインフォメーションの通り、レスキュー用インスタンスのOS側では/dev/xvdf に変更されていました)
- レスキュー用インスタンスにデバイスが認識されていることを確認し、mount。
[ec2-user@ip-10-32-1-157 ~]$ sudo lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS xvda 202:0 0 8G 0 disk ├─xvda1 202:1 0 8G 0 part / ├─xvda127 259:0 0 1M 0 part └─xvda128 259:1 0 10M 0 part /boot/efi xvdf 202:80 0 8G 0 disk ├─xvdf1 202:81 0 8G 0 part ├─xvdf127 259:2 0 1M 0 part └─xvdf128 259:3 0 10M 0 part [ec2-user@ip-10-32-1-157 ~]$ [ec2-user@ip-10-32-1-157 ~]$ sudo mount -t xfs /dev/xvdf1 /mnt/ mount: /mnt: wrong fs type, bad option, bad superblock on /dev/xvdf1, missing codepage or helper program, or other error.
あれれ。だめですね。wrong fs type とか言われていますが、ファイルシステムはxfsで間違いないはず……。
またしばし検索……。
うん、これですね。

なるほど、そういえば、起動しなくなったインスタンスも、レスキュー用インスタンスも、同じAMIから作ったAmazon Linux 2023のインスタンスでした。/ のUUIDが同じだからエラーになったのですね。確認してみたところ、確かに同じUUIDでした。
[ec2-user@ip-10-32-1-157 ~]$ sudo lsblk --fs NAME FSTYPE FSVER LABEL UUID FSAVAIL FSUSE% MOUNTPOINTS xvda ├─xvda1 xfs / 439aed1d-715f-48fd-bfa0-0e5f1a23088b 6.4G 20% / ├─xvda127 └─xvda128 vfat FAT16 C86C-DC3E 8.7M 13% /boot/efi xvdf ├─xvdf1 xfs / 439aed1d-715f-48fd-bfa0-0e5f1a23088b ├─xvdf127 └─xvdf128 vfat FAT16 C86C-DC3E
上記記事の手順に従ってUUIDの変更を実施し、再びmount。
[ec2-user@ip-10-32-1-157 ~]$ sudo uuidgen 12e50054-6690-41a6-b532-e75946ba9c6b [ec2-user@ip-10-32-1-157 ~]$ sudo xfs_admin -U 12e50054-6690-41a6-b532-e75946ba9c6b /dev/xvdf1 Clearing log and setting UUID writing all SBs new UUID = 12e50054-6690-41a6-b532-e75946ba9c6b [ec2-user@ip-10-32-1-157 ~]$ [ec2-user@ip-10-32-1-157 ~]$ sudo mount -t xfs /dev/xvdf1 /mnt/rescue/ [ec2-user@ip-10-32-1-157 ~]$ [ec2-user@ip-10-32-1-157 ~]$ ls /mnt/rescue/ bin boot dev etc home lib lib64 local media mnt opt proc root run sbin srv sys tmp usr var
OKですね!
起動しなくなった原因のファイルを取り除き、umountした上で、今度はレスキュー用インスタンスからボリュームをデタッチします。そして再び起動しなくなったインスタンスにボリュームをアタッチ。ルートボリュームなのでデバイス名は /dev/xvda を指定します。
インスタンス起動!シリアルコンソールで起動を見届け……
grub>
あれえ……。
そういえばすっかり読み流していましたが、先ほどの記事の末尾に
Finallly, we can start digging into the content of the device mount on
/mntand do whatever was required. Perhaps, one note if this device will be moved back to the original EC2 instance do not forget to updat the/mnt/etc/fstabfile with the updated UUID of this modified boot device.
※ Change the UUID on a xfs file system より引用
UUIDが変わったから /etc/fstab の変更を忘れるなよって書いてありました。ドキュメントはよく読もう!
再度、ルートボリュームをレスキュー用インスタンスにアタッチし、fstabを修正します。
今度こそ!
grub>
あっれえ…。
その後、AWS re:Postの関連しそうな記事を参照し、fstabのオプションを変更してファイルシステムのチェックを無効にしたり、XFSのリペアをしたりいろいろ試しますが、相変わらずgrubのプロンプトになってしまいます。ひとつ試すたびにボリュームの付け替えをしているので、ひたすら面倒です。
最終的には、fstab以外におそらくgrubの設定ファイルにもUUIDが含まれていそうな気がする!だけどもう調べるの面倒くさい!となって、一度変更したファイルシステムのUUIDを元のUUIDに戻してあげることでOSの起動に成功したのでした。
教訓
- パスワードを設定したOSユーザ作っておくの大事。(でも軽い検証のときはそのひと手間も面倒ですよね)
- UUID被りを避けるため、レスキュー用インスタンスはレスキューされるインスタンスとは異なるOSバージョンにしておくと面倒がない。(でも違うディストリビューションとかにしちゃうと操作感が違って面倒くさいしねえ)
- ドキュメントはよく読もう(でもちゃんと読んでもうまくいかないことはある)
後日談
その1
後日確認したら、grubの設定ファイルにUUIDが書かれていました。検証してないけれど、ここも追加で書き換えれば起動できていたはず。
$ sudo cat /boot/loader/entries/e8e94dc055b04f2484035693fbb04115-6.1.56-82.125.amzn2023.x86_64.conf title Amazon Linux (6.1.56-82.125.amzn2023.x86_64) 2023 version 6.1.56-82.125.amzn2023.x86_64 linux /boot/vmlinuz-6.1.56-82.125.amzn2023.x86_64 initrd /boot/initramfs-6.1.56-82.125.amzn2023.x86_64.img options root=UUID=439aed1d-715f-48fd-bfa0-0e5f1a23088b ro console=tty0 console=ttyS0,115200n8 nvme_core.io_timeout=4294967295 rd.emergency=poweroff rd.shell=0 selinux=1 security=selinux quiet grub_users $grub_users grub_arg --unrestricted grub_class amzn
その2
この記事を書くために資料整理していたら、先述のルートボリュームのデタッチ・アタッチを解説した記事から以下の記事へリンクが張られているのを発見しました。

1. 一時的にマウントするために、UUIDの重複を無視する
アタッチしたボリュームは一時的にマウントするためのものであり、本来のEC2にアタッチし直す場合は、このアプローチを採用します。
マウント時にUUIDの重複を無視するオプション(
-o nouuid)を渡します。
※ Amazon EBSマウント時の「wrong fs type, bad option, bad superblock on…」というエラーを解決する方法を教えてください より引用。
UUIDの重複を無視するオプションがあったようですね。もう少しだけ丁寧に調べていればこんな苦労しなくて済んだのに……(よくある)
まとめ
疲れました。