

 本記事は 新人ブログマラソン2024 の記事です。 本記事は 新人ブログマラソン2024 の記事です。 |
こんにちは!SCSKの新人、黄です。
前回までの記事では、Rubrikの基本機能と、その強力なランサムウェア対策について詳しくご紹介しました。多くの方に興味を持っていただき、とても嬉しかったです!
「まだ読んでいない!」という方は、ぜひ以下の記事をご覧ください。
さて、今回ご紹介するのは、Rubrikのもう一つの注目機能、「Rubrik Sensitive Data Discovery」です。
名前の通り、機密データを検知し、適切に管理できる機能です。
興味がある方は、ぜひ詳しく見ていきましょう!
Sensitive Data Discovery とは?
上記のような悩みを解消し、データの安全性を高めるために役立つのが Rubrik Sensitive Data Discovery です。
Sensitive Data Discoveryは、設定したルールに基づいてバックアップデータをスキャンし、機密データを自動的に検出する機能です。
特に以下の 3 つのポイントがメリットです。
- バックアップデータを活用したスキャン
通常の業務データに影響を与えず、バックアップデータを活用して機密情報をスキャンできます。
これにより、負担なくデータの安全性を確保できます。 - 自動検出とリスク分類
設定されたルールにより、氏名やクレジットカード番号などの機密データを自動で検出し、リスクレベルを分類できます
手動での確認作業を減らし、効率的な管理が可能です。 - 直感的なレポート機能
分析結果はダッシュボードで可視化され、どこにリスクがあるのか一目で把握できます。
これにより、迅速な対策が可能になります。
実際に使ってみた!Sensitive Data Discovery シミュレーション
ここまで、Sensitive Data Discoveryについてご紹介してきましたが、「実際の運用イメージがわからない!」 と感じる方もいらっしゃるのではないでしょうか?
そこで今回は、VMware vSphere上の仮想マシン(VM) を例に、Sensitive Data Discovery を実際に動かすシミュレーションを解説します!
このシミュレーションを通じて、どのように機密データが検出され、管理されるのかを具体的にイメージしていただけると思います。
vSphere と RSC(Rubrik Security Cloud) の連携の仕組み
参考資料:vSphere仮想マシンRSCは、VMware vSphere 環境 とシームレスに連携し、仮想マシン(VM)のデータ保護と管理を実現します。
- vCenter Server 接続RSC は vCenter Server と接続し、VM を自動検出・管理します。
- 複数クラスター管理1つの vCenter を複数の Rubrik クラスターで管理可能。VM の保護範囲を柔軟に設定できます。
- SLA ドメイン適用VM に SLA ドメイン(バックアップポリシー)を適用し、自動保護を実現
シミュレーションの全体像
Sensitive Data Discovery を使ったシミュレーションは、以下のような流れで進めてみました。
| ステップ1 | Sensitive Data Discovery の基本設定 | アナライザーとポリシーの作成 |
| ステップ2 | 初期分析 | 既存の全バックアップデータを自動スキャン |
| ステップ3 | テストデータの準備 | 機密データあり/なしのファイルを作成 |
| ステップ4 | Sensitive Data Discovery実行 | 機密データの検出 |
| ステップ5 | 結果確認 | ダッシュボードで結果を可視化 |
ステップ 1: Sensitive Data Discovery の基本設定
まず、RSC コンソールの 「Data Security Posture」 メニューを選択し、Sensitive Data Discovery の設定画面に移動します。
ここでは、Sensitive Data Discovery の 「脳」 とも言える、アナライザー と ポリシー の2つの設定を行います。これらの設定を行うことで、Rubrik が機密データを自動的に検出し、管理できるようになります。
アナライザーの設定
Rubrik では、以下の2種類のアナライザーを利用できます。
事前定義済みアナライザー
62種類のテンプレートから選択可能です。
例えば、IPアドレス や Google APIキー など、一般的な機密データのパターンを簡単に検出できます。
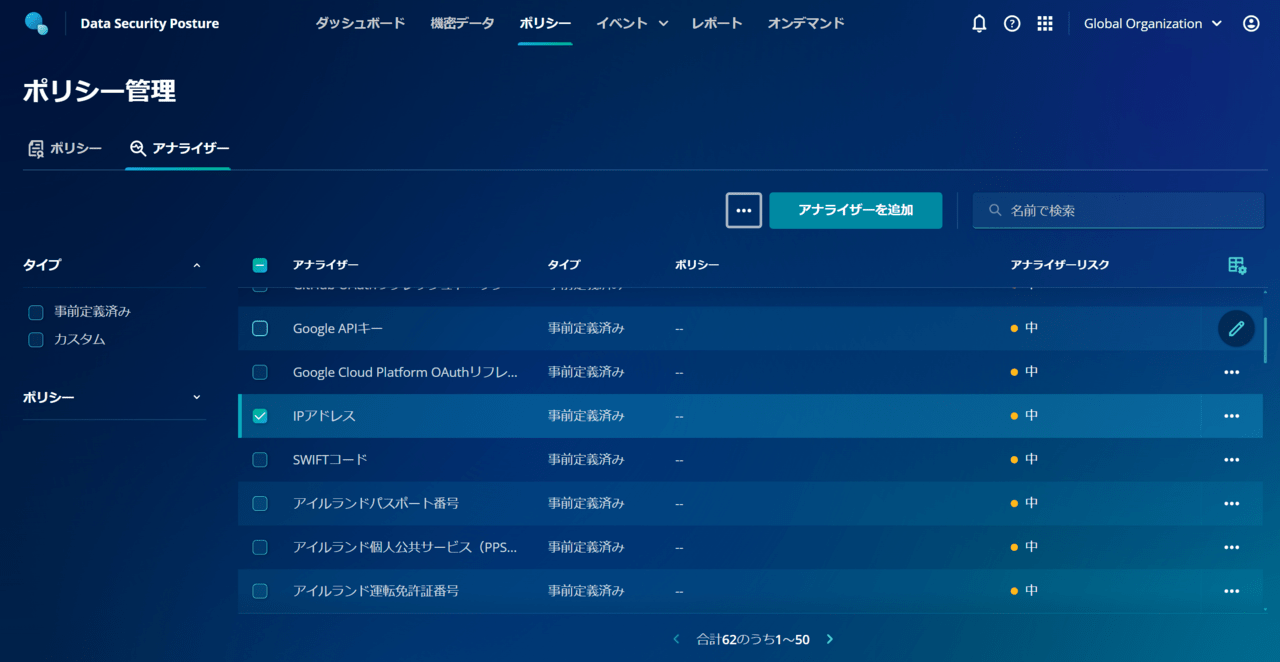
カスタムアナライザー
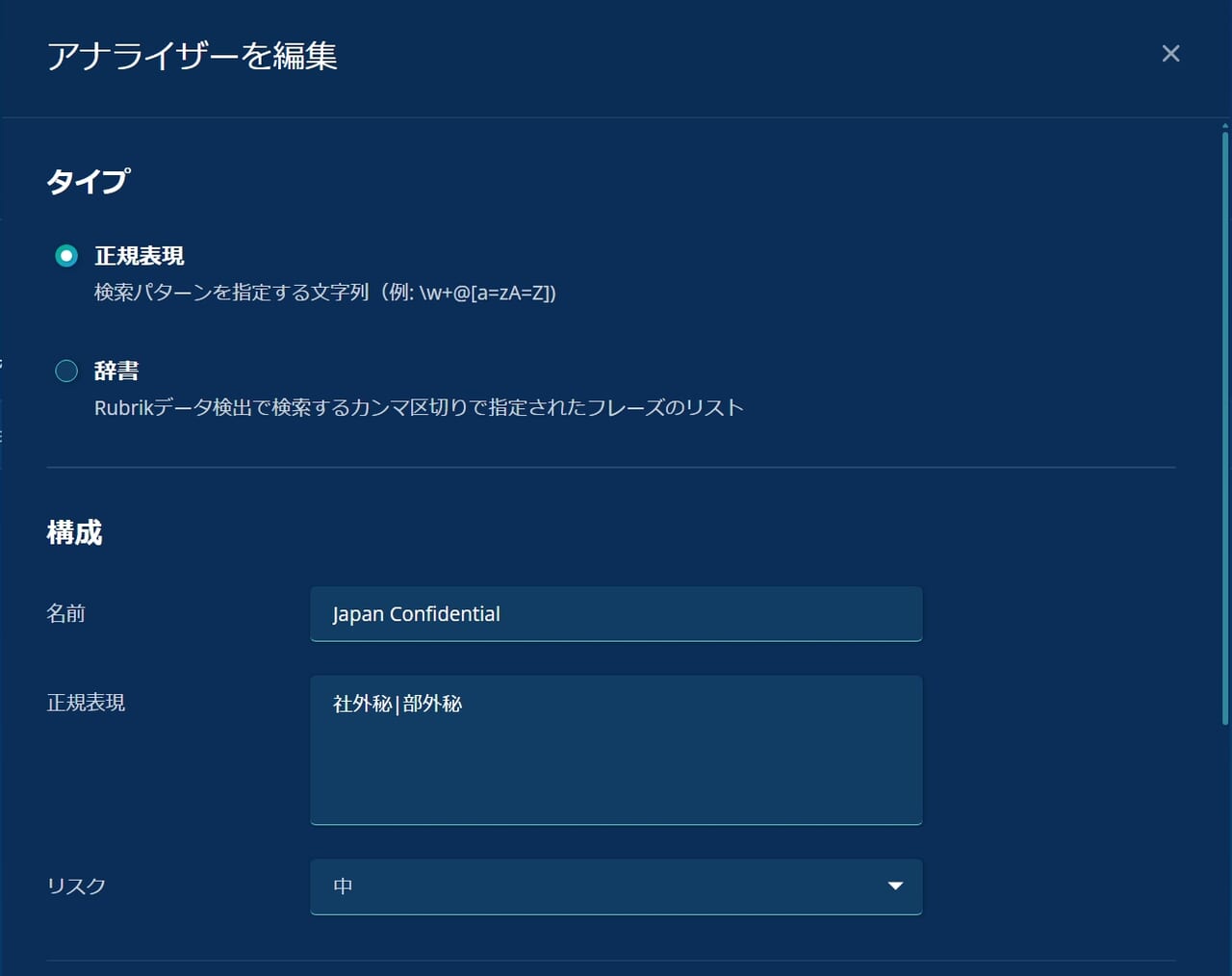
独自のルールを追加可能です。特定のキーワードやパターンに基づいて、柔軟に機密データを定義できます。
ポリシーの設定
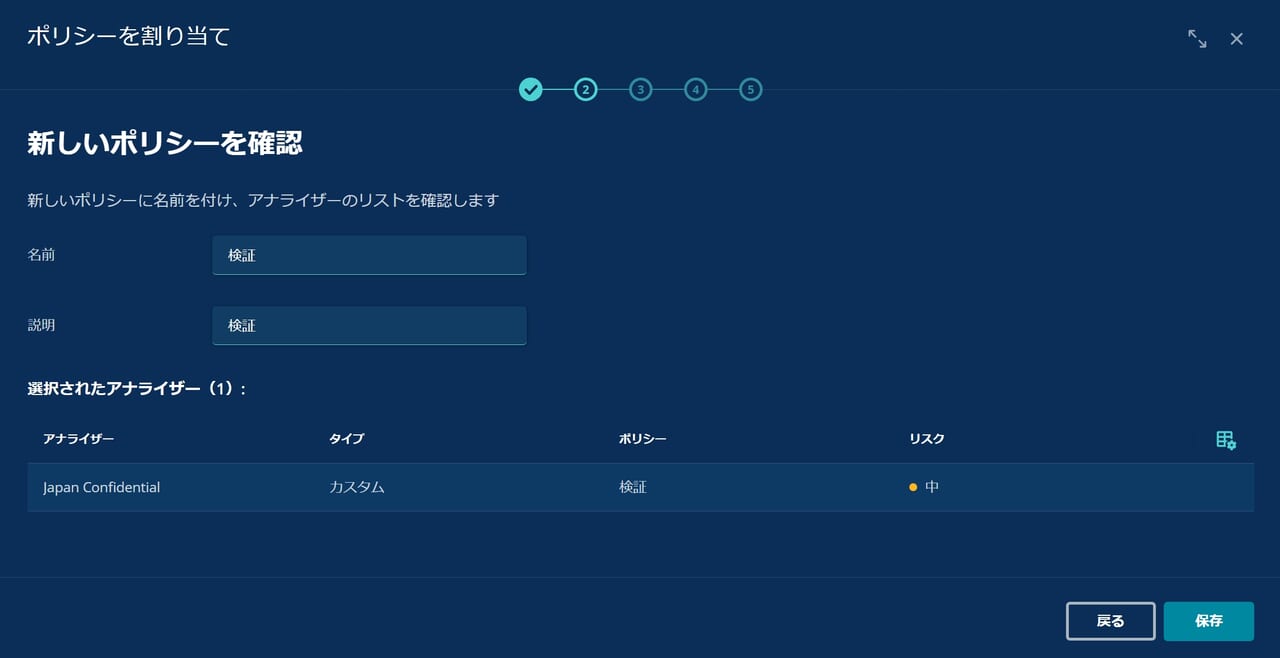
具体的な操作として、まずポリシーに含まれるアナライザーを確認し、ポリシーの名称を設定します。
なお、1つのポリシーに複数のアナライザーを含めることも可能です。
次に、分析対象のオブジェクトを指定します。
ここで特に重要なのは、SLA ドメインルールが設定されているオブジェクトのみが機密データ分析の対象になる という点です。
Rubrik は下図のような 2 つの方法を提供しており、
- オブジェクトタイプ別:特定のオブジェクトを選択する方法
- クラスター別:Rubrik CDM を指定し、CDM 配下のすべての SLA ドメインを持つオブジェクトを分析する方法
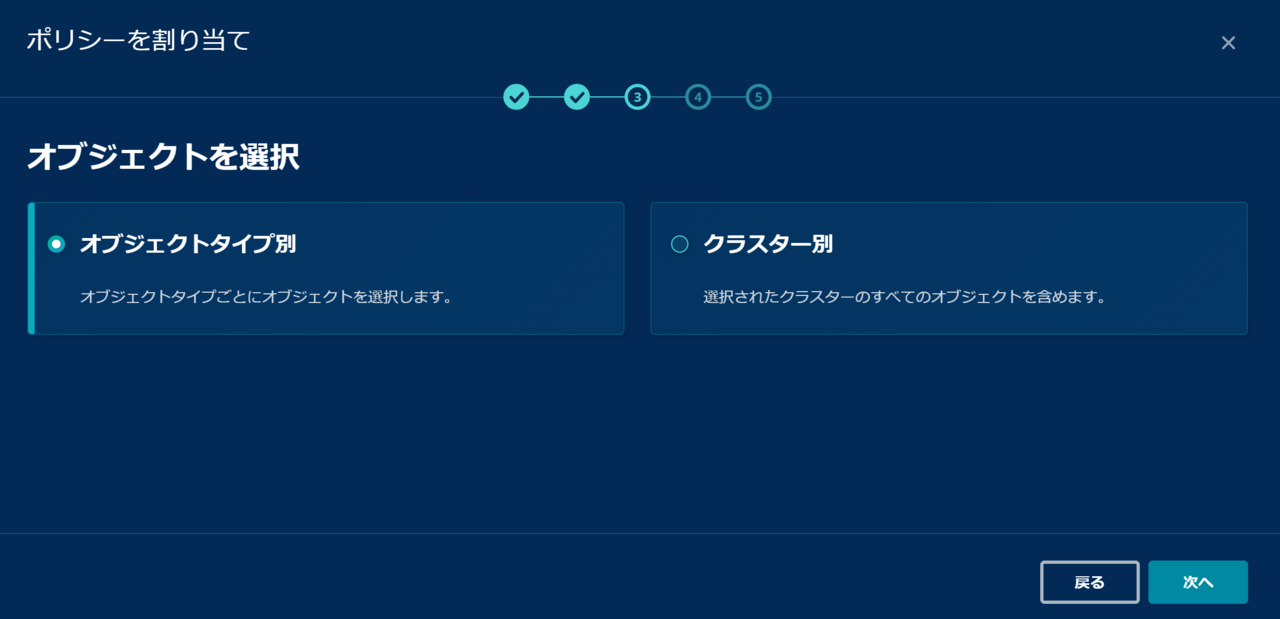
今回は、特定の vSphere の仮想マシンを分析するため、1 つ目の「オブジェクトタイプ別」を選択します。
以下の図のように、Rubrik は複数のプラットフォームと連携しており、異なる環境に存在するオブジェクトも RSC(Rubrik Security Cloud)を通じて一元管理できます。これも Rubrik の大きな利点の一つです。

今回としては、vSphereプラットフォームをクリックして、特定のVMを選択します。
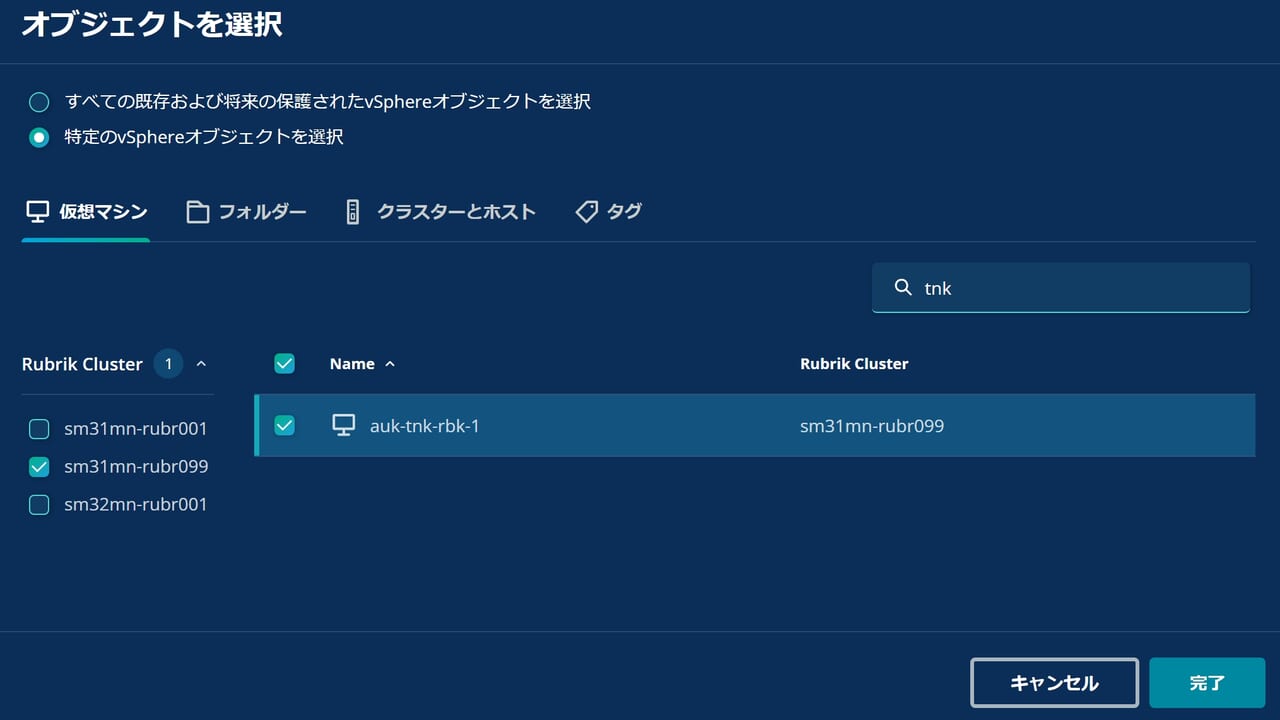
ステップ 2: 初期分析
ポリシー設定後、Rubrik は自動的に初期分析を行います。
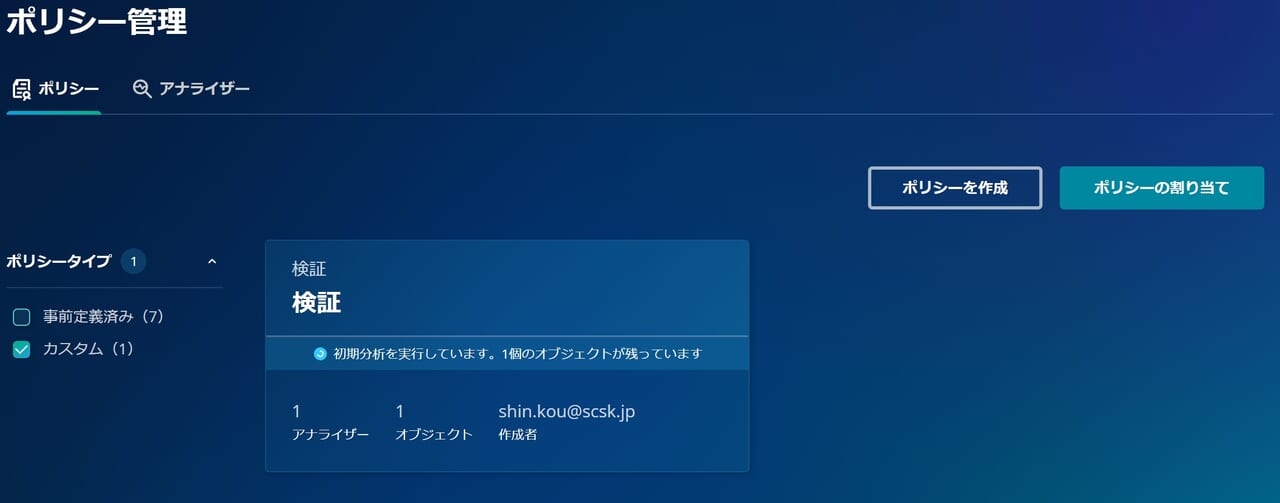
初期分析では、対象となるVMのすべてのバックアップ世代をスキャンします。
つまり、今後取得するバックアップデータだけでなく、Sensitive Data Discovery機能を利用する前に取得したバックアップデータも含めて機密データの有無を分析することも可能です。
ステップ 3: テストデータの準備
検出精度を検証するため、VM 内に以下の2種類のファイルを作成:
- 機密データあり:「社外秘」を含むmail.txtファイル
- 機密データなし:mail_normal.txtファイル


ステップ 4: Sensitive Data Discovery実行
ポリシーとアナライザーを設定するだけで、対象のオブジェクトがバックアップデータを取得するたびに自動的に実行されます。
Rubrik の公式説明によると、最大 24 時間以内にスキャンが完了するとされていますが、今回のシミュレーションではバックアップ取得後、約 30 分で機密データの検知結果が反映されました。
それでは、結果を一緒に確認してみましょう!
ステップ 5: 結果確認
下図のように、Data Security Postureダッシュボードで簡単に確認可能です。
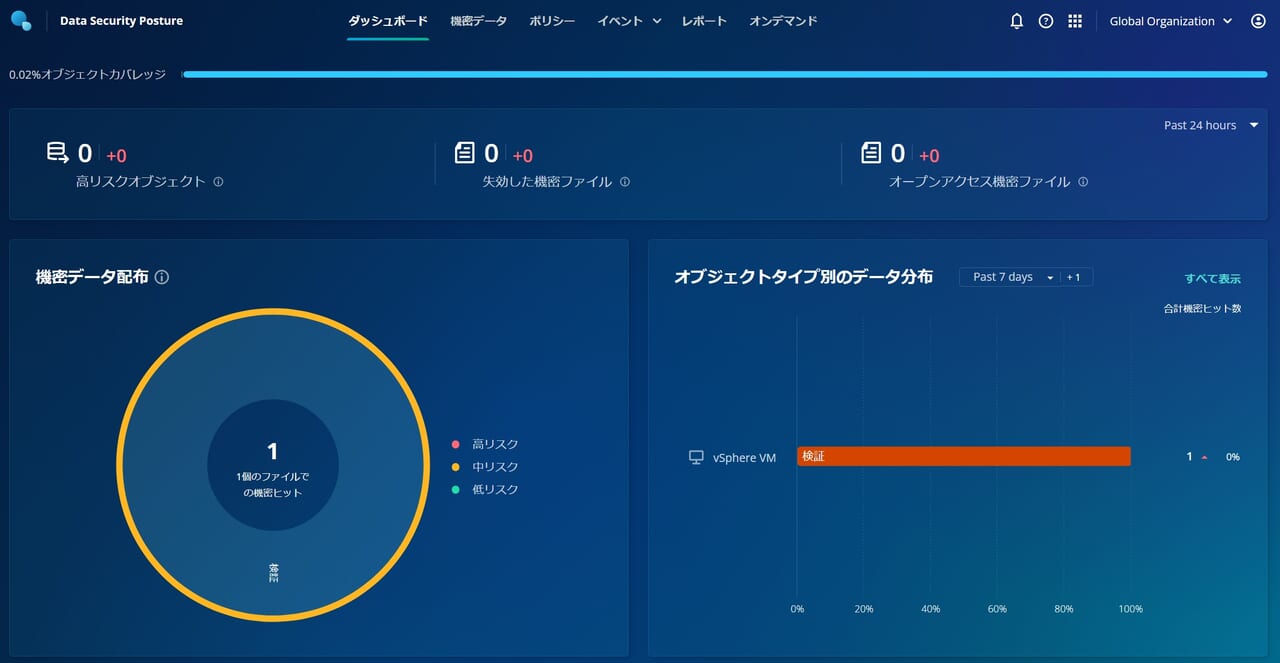
Sensitive Data Discovery が vSphere VM 内の機密データを適切に検出し、一つの中リスクのファイル(mail.txt)が存在することが判明しました。
なぜ中リスクなのかというと、設定したアナライザー「Japan Confidential」のリスク評価を中リスクに指定しているためです。
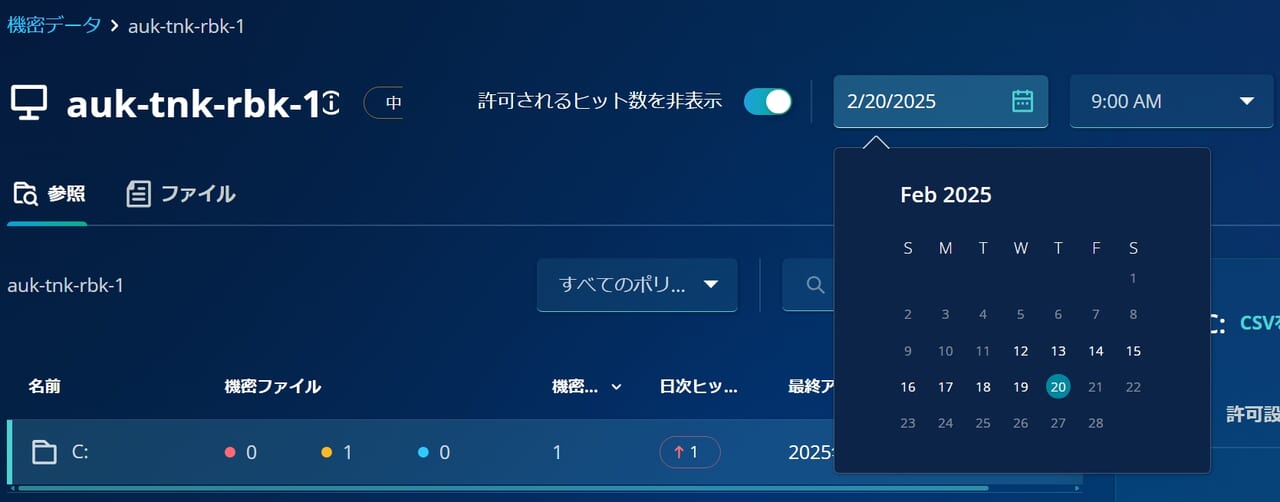
メニューの「機密データ」をクリックすると、下図に示すように、どの VM のどのファイルに機密情報が含まれているのかを追跡でき、適切な対応が可能になります。
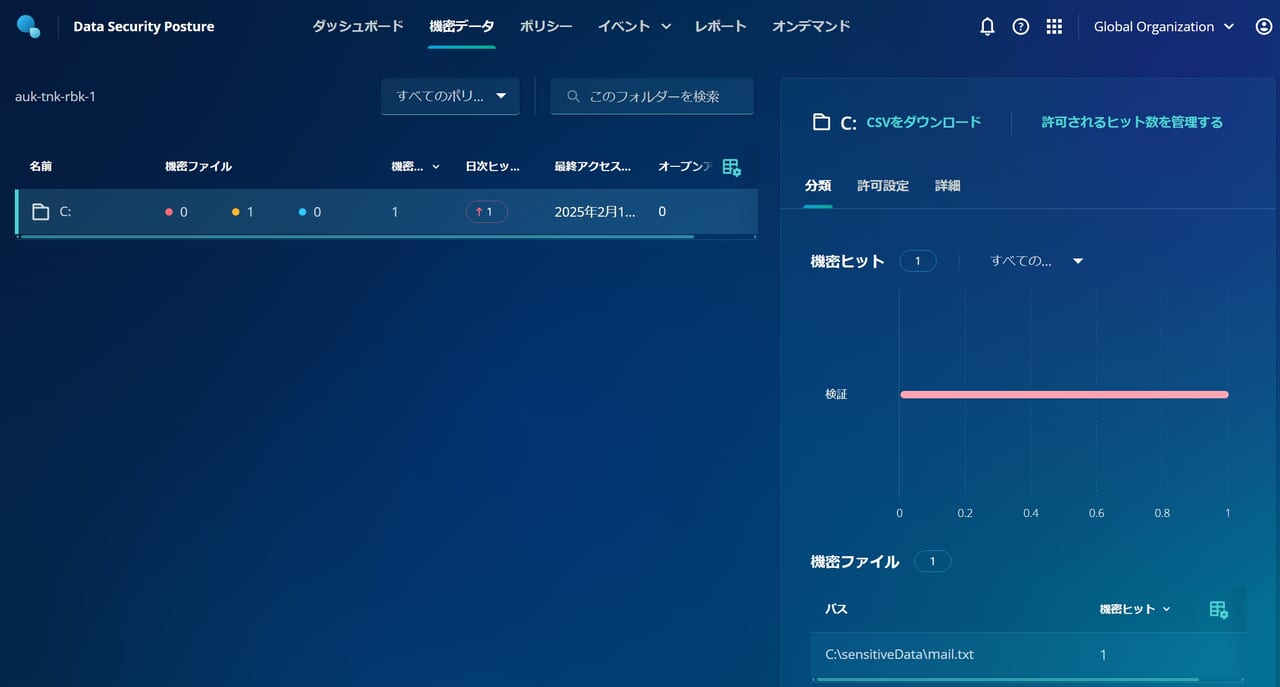
さらに、下図のように、Sensitive Data Discovery はすべてのバックアップ世代をスキャンするため、どの時点のバックアップデータから機密データが含まれるようになったのか特定することも可能です。
最後に
Rubrik Sensitive Data Discovery を使えば、機密データの管理がグッと楽になります。
✔ 機密データを自動で検出し、可視化
✔ バックアップデータを活用し、通常業務に影響を与えない
✔ ポリシー設定だけで継続的に監視可能
実際に試してみると、どこにどんな機密情報があるのか一目で分かるので、データ管理の負担を減らせます。
興味がある方がいらっしゃいましたら、ぜひぜひ 機密データの監視 | Rubrik をご覧ください。
また、Rubrik Sensitive Data Discovery は、今回のシミュレーションで使用したテキストファイルだけでなく、PDF、Excel、Word など多様なファイル形式に対応しています。詳しくは サポートされているファイル形式をご確認ください。
ここまでご覧いただき、ありがとうございました。
今後も、Rubrik の便利な機能について紹介していく予定です。それでは、また次回!