

こんにちは、広野です。
サーバーレス環境で大量の同一処理をさせようと思ったら、AWS Step Functions の Map ステートを使用するのが便利です。本記事では、その仕組みの概念やユースケースを紹介します。実際の実装例は、また別の記事で紹介したいと思います。

Map workflow state - AWS Step Functions
Learn how to use the Map workflow state to run a set of steps in your Step Functions workflows.
docs.aws.amazon.com
やりたいこと
- インプットデータ(ここでは JSON)をもとに、サーバーレス環境で同一処理の並列実行(並列処理)をさせたい。
- インプットデータの処理順序にはこだわらない。
- 並列処理中にエラーが発生しても、全データを一通り処理させたい。
- 並列処理後、データごとに結果をまとめて取得したい。
実現イメージ
以下のようなイメージで、AWS Step Functions ステートマシンを作成します。
ここで、Map ステートの中に並列実行させたい処理を入れます。
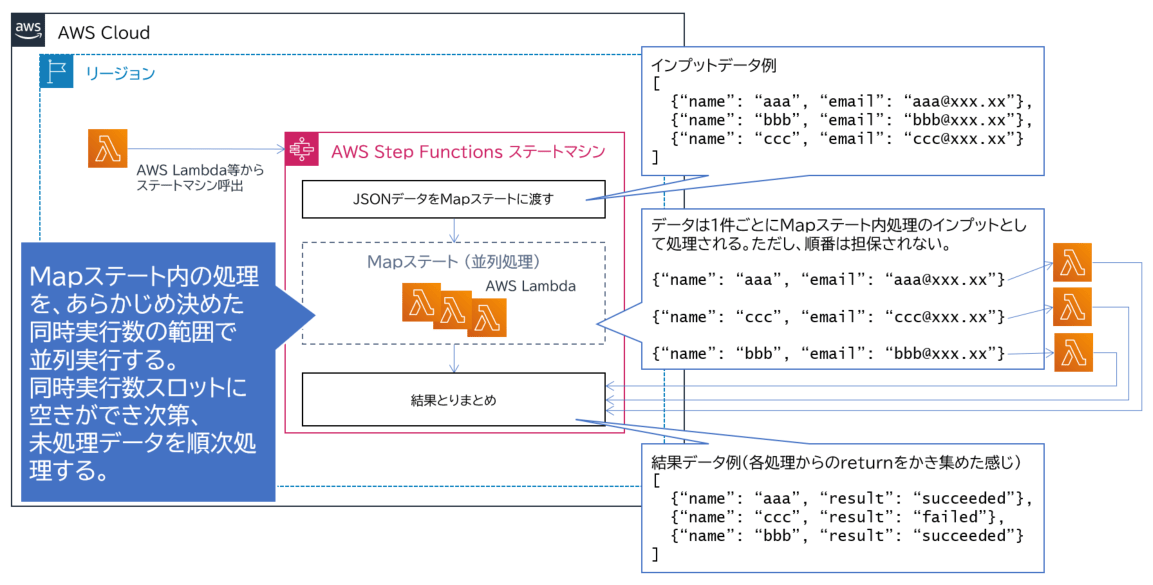
インプットデータは図のように1件ずつ分割されて並列処理されます。
同時実行数は AWS 推奨では 40 件ですが、変更可能です。また、同時実行数を 1 件にすると 1 件ずつ処理されます。ただし、データの処理順番は担保されません。
Map ステートの良いところ
- やはり、データさえ渡せば同じ処理を一気に処理してくれることでしょう。ループ処理を書く必要がなく、管理も楽です。
- データの処理順番さえ気にしなければ、使いどころは多いと思います。
私は Amazon Cognito のユーザインポートや一括削除に使っています。データ登録のバッチ処理に使えると思います。 - Map ステート内処理の結果を、最後に全てまとめてくれるのも最高です。後続処理で結果を一覧にして確認できますので。
ただし、それを確実に実現するには各処理の中でエラー処理を入れておく必要があります。上の例で言えば、AWS Lambda 関数の中で予期せぬエラーが発生しても、エラーをキャッチして関数を異常終了させず、failed という結果を return してくれるようにコードを書くことが必要です。
また、各処理が他の処理のエラーを気にせず独立して進行させられる設計でないとこの使い方はできないと思います。
まとめ
いかがでしたでしょうか?
Map ステートはめっちゃ便利です。
前述の通り、私は Amazon Cognito のユーザインポート等に使っていますが、それと似たような用途には必ずマッチすると思います。ちなみに Amazon Cognito には AWS 純正のユーザインポート API が用意されていますが、1 件 1 件の結果を確認しづらかったのと、各ユーザ登録後にグループへの所属をさせたいなど、ちょっとしたカスタマイズが必要だったので自分で Map ステートを使ってインポートジョブを作りました。
本記事が皆様のお役に立てれば幸いです。