

こんにちは。SCSKの松渕です。
皆さん、ペット飼っていらっしゃいますか?自分のペットは、周りとどれだけ違うんでしょうか。気になったことありませんか。
そして、AIでどれだけちゃんと識別できるんだろうか、と。
ということで、今回はGoogle Cloud Vertex AIのAutoMLを利用して、
写真に写っている猫を、私の飼っている猫(リク)と、そのほかの猫を分類するモデル「リクか、リク以外か」を作ってみました。
用語整理 ~Vertex AI と AutoML と Vertex AI Vision~
前段として用語の整理します。コロコロと名前変わるのでわかりにくいですよね。。
- Vertex AI
Google Cloudが提供するAI開発のための統合プラットフォームです。
データの準備からモデルのトレーニング、そして運用まで、AI開発の全工程をサポートする強力な基盤といえます。
Vertex AIの中では、AIモデルを作るためのアプローチとして、主に2つの方法が提供されています。- カスタムトレーニング:データサイエンティストがPythonなどのコードを書いてモデルを構築する方法です。
- AutoML(自動機械学習):今回利用する方法で、専門的な知識がなくてもカスタムAIモデルを作成できる機能群です。
- AutoML
Vertex AIプラットフォーム内で利用できる機能群で、専門家でなくてもカスタムAIモデルを作成できます。「画像」「テキスト」「表データ」など、様々なデータに対応したAutoMLがあります。今回は、画像を使ったAutoMLを利用しました。
以前は「AutoML Vision」と呼ばれてました。 - Vertex AI Vision:
少し混乱しやすいのですが、Vertex AI Vision(旧称Visual Inspection AI)という全く別のサービスもあります。リアルタイムの動画ストリームや膨大な画像データから継続的にインサイトを抽出し、高度なビジョンAIアプリケーションを構築・運用することを目的としています。
製品の正常/異常の分類 タスクについて
今回はAutoMLですが、Vertex AI Vision(旧称Visual Inspection AI)でも「製品の正常/異常の分類」という目的であれば画像から二値分類タスクができます。
Visual Inspection AIの新モデル Anomaly Detection を触ってみた!!(Tech hermony)
データ準備
Step1:目標枚数の決定
画像分類用のAutoMLでは、各ラベルにつき最低10枚のサンプルがあればモデル作成できます。今回のケースでは最低20枚(リク10枚、リク以外10枚)が必要でした。一般的に、学習データは多ければ多いほど精度が向上し、画像のパターンも可能な限り多様な条件である方が望ましいです。
今回は、リク50枚、リク以外50枚の合計100枚で試しました。
Google Cloudのドキュメントでは、各ラベル(クラス)につき1,000枚以上を推奨しています。
AutoML モデルの上限(Google Cloud ドキュメント)
最低10枚という非常に少ない枚数でも学習できるのは、内部的にデータ拡張が行われているためだと考えられます。
事前構築済みの検索スペース(Google Cloud ドキュメント)
データ拡張(Data Augmentation)って知っていますか??①(Tech hermony)
「画像のパターンも可能な限り多様な条件」と書きましたが、これは一般的な原則です。ユースケースによっては、特定の条件に画像を揃えた方が望ましい場合もあります。例えば、動物病院で診察前の猫の全体像を映した写真のように、固定の場所である程度統一された画角で撮影されることが想定される場合は、サンプル画像もそれに合わせて条件が統一されたもので集めた方がモデルの精度は高まります。
一方で、今回は「いわゆる日常写真」からリクを分類することを想定していたため、明度や背景、リクのポーズなども意図的に「多様な条件」で収集しました。
Step2:サンプル画像収集(リク画像)
スマホに保存されている沢山の画像の中から50枚選んでPC送るだけでした。かわいい。

Step3:サンプル画像収集(リク以外画像)
猫カフェに行った時の写真や親戚の猫の写真などを集めました。
気持ち、リクと色味が似ている猫を中心に集めました。こちらもかわいい。

構築
Step4:データセットの作成
データセット作成画面へ
Vertex AI のトップ画面(ダッシュボード)の下段にある「データセットを作成」を押下します。
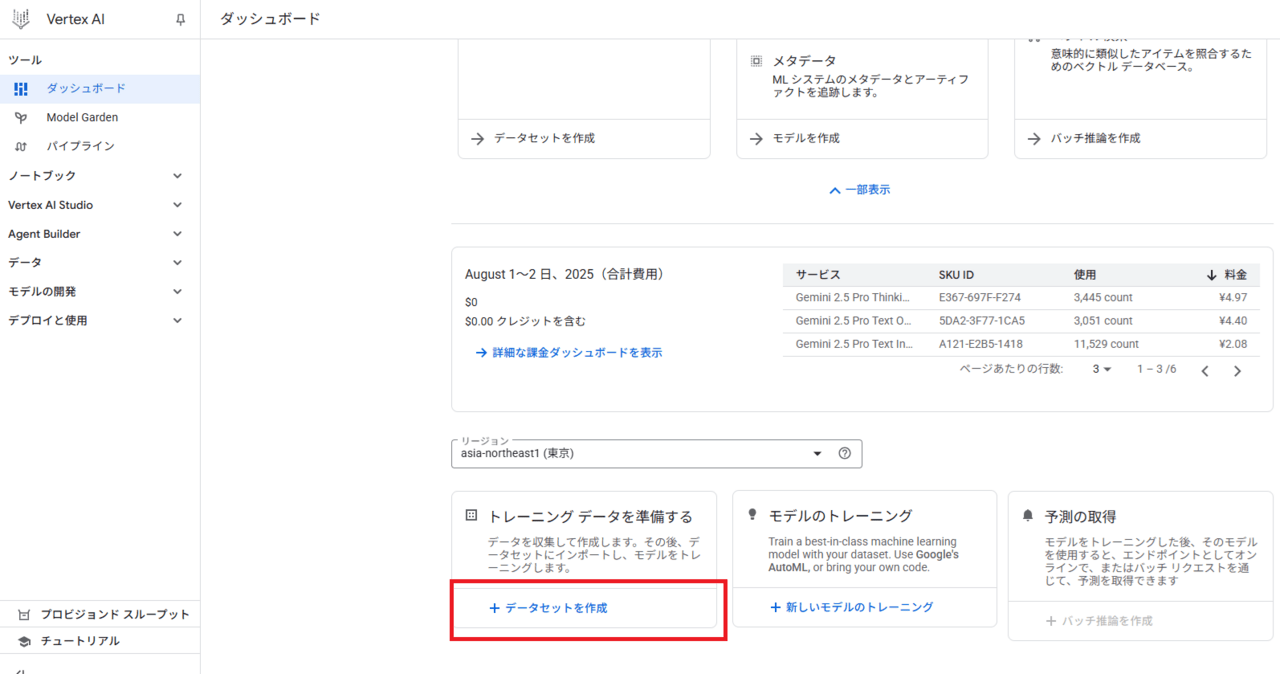
単一ラベル分類を選択
データセットを作成の画面に遷移します。
データセット名を入力します。
今回は二値分類タスクのため、「単一ラベル分類」を選択して、「作成」を押下します。
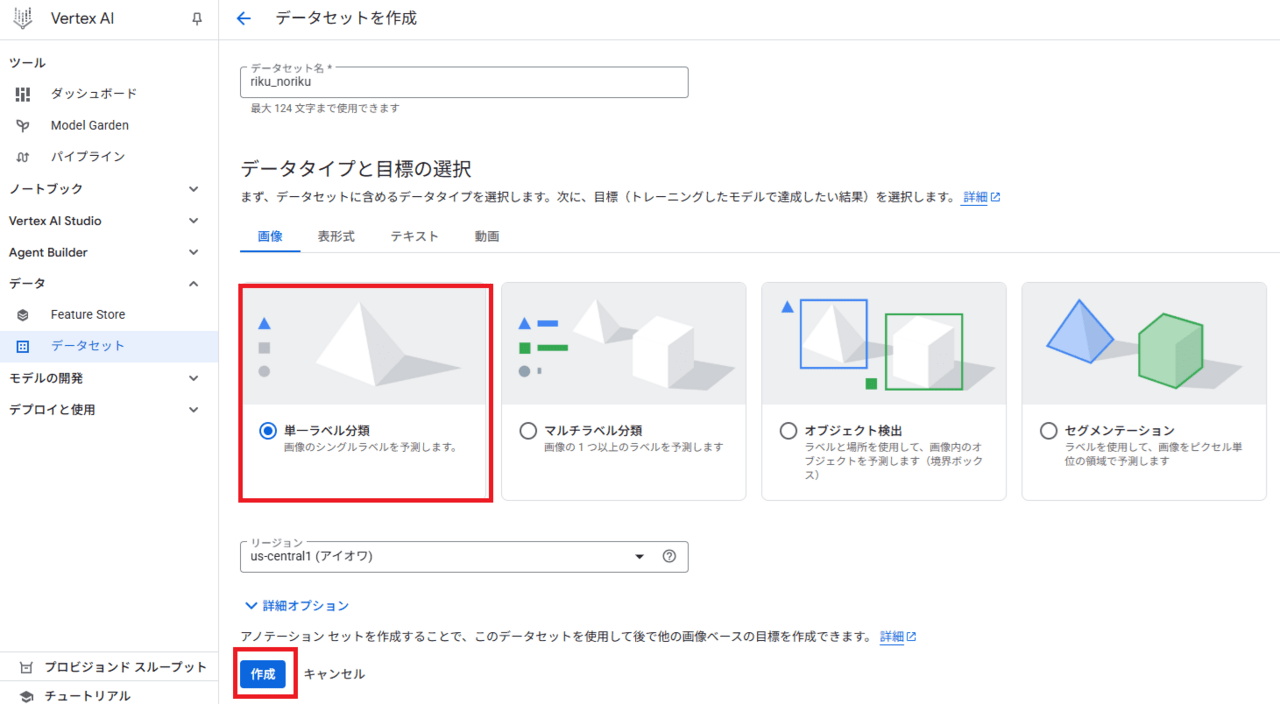
データ保管のリージョンについて
上記の画面でリージョンがアイオワになっていることに気づいた方もいるかもしれません。
これは、内部的にVision Warehouseを使用しているためで、このブログ執筆時点では、
提供されているリージョンがオランダとアイオワのみとなっています。
Vision Warehouse のリージョンの選択(Google Cloud ドキュメント)
そのため、画像のAutoML 使う場合、データ保管リージョンに日本を選べないのでご注意ください。
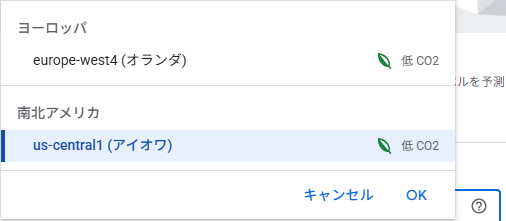
画像インポート方法選択
画面のインポート方法を選択。今回はパソコンから直接画像アップロードしました。
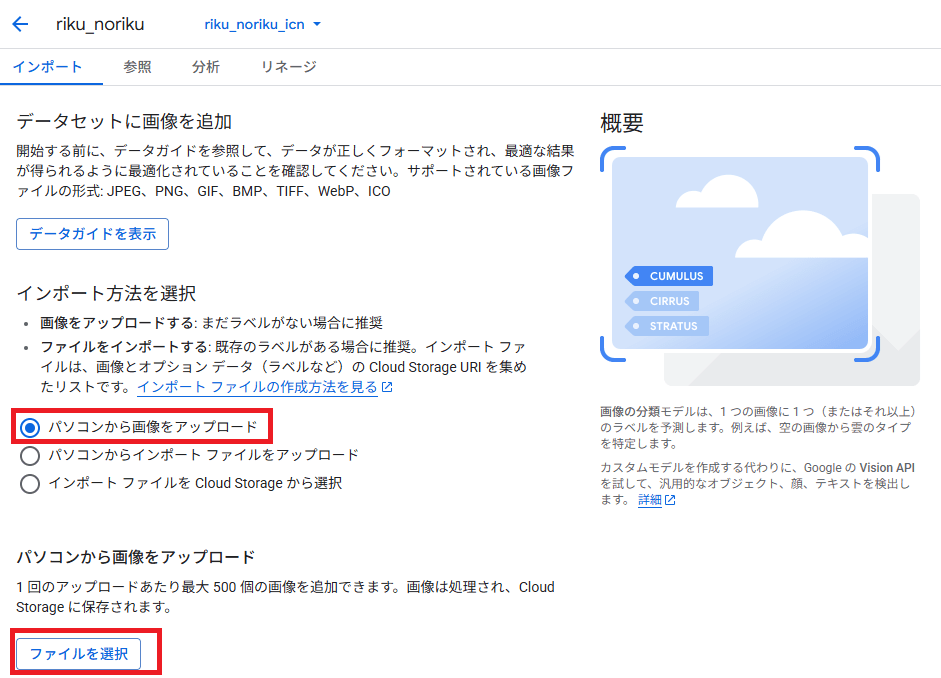
画像アップロード確認
パソコンからアップロードしたらこのような画面が出てきました。
データ分類(トレーニング、検証、テスト)が各画像に対して選べるようになってます。
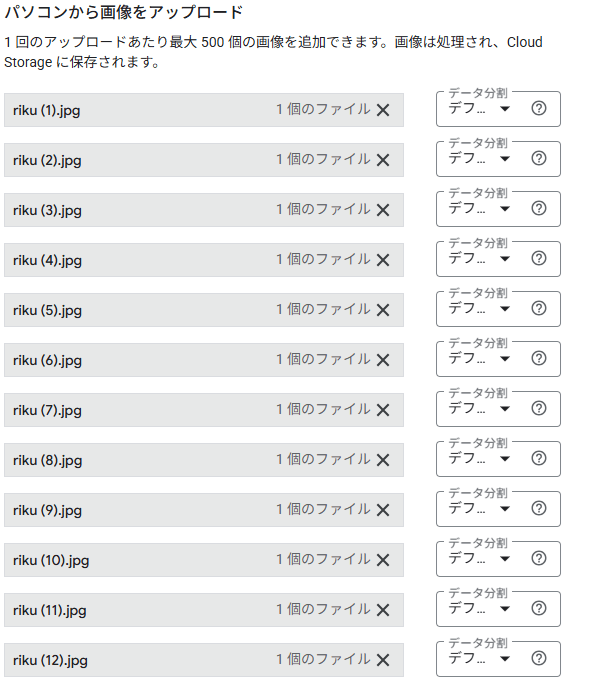
下にスクロールし、サンプル画像を保管するGCSのパスを入力して「続行」を押下します。
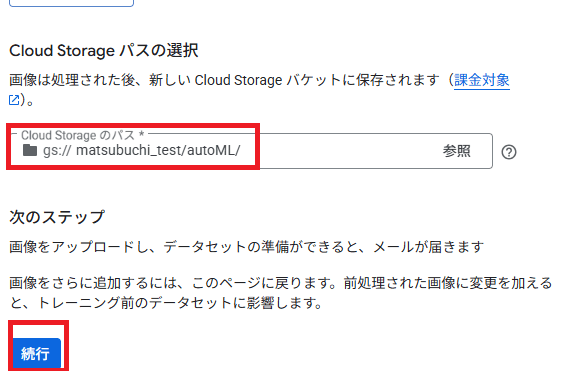
インポートを待つ
インポートが開始されます。時間を計測していませんでしたが、合計100枚(約22MB)で20分くらいかかったと思います。
愛猫への思いが強く、画像が大きめだったのも原因かもしれません。
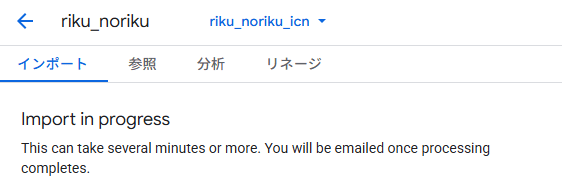
以下のような文言が出てきます。
また、インポート終わったらメールも届きます。
Step5:ラベリング
ラベル定義
インポートが終わるとデータセットの画面にデータがずらっと並びます。とてもかわいい。
新規ラベル追加をクリックしてラベル作ります。
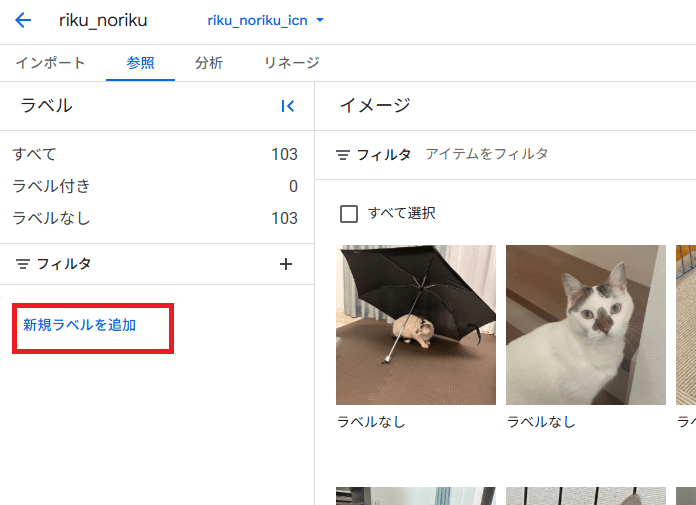
今回は「riku」と「non_riku」としました。ちなみに、ラベルに日本語やハイフンは使えません。
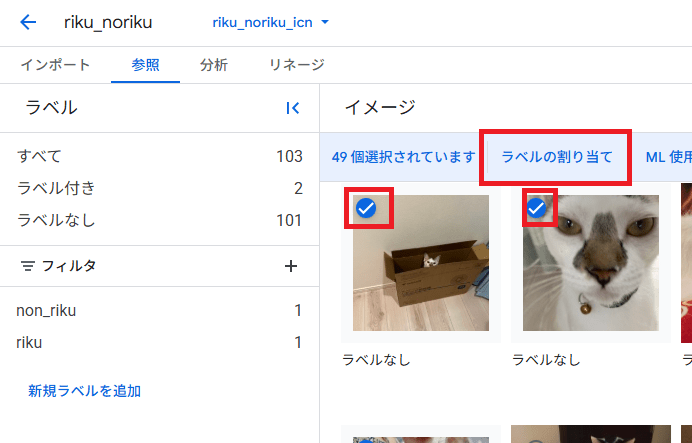
ラベル割り当て
画像選択してラベル割り当てます。
Step6:トレーニング
トレーニング開始ボタン押下
すべての画像にラベルを割り当てられたら、右側の「新しいモデルのトレーニング」を押下します

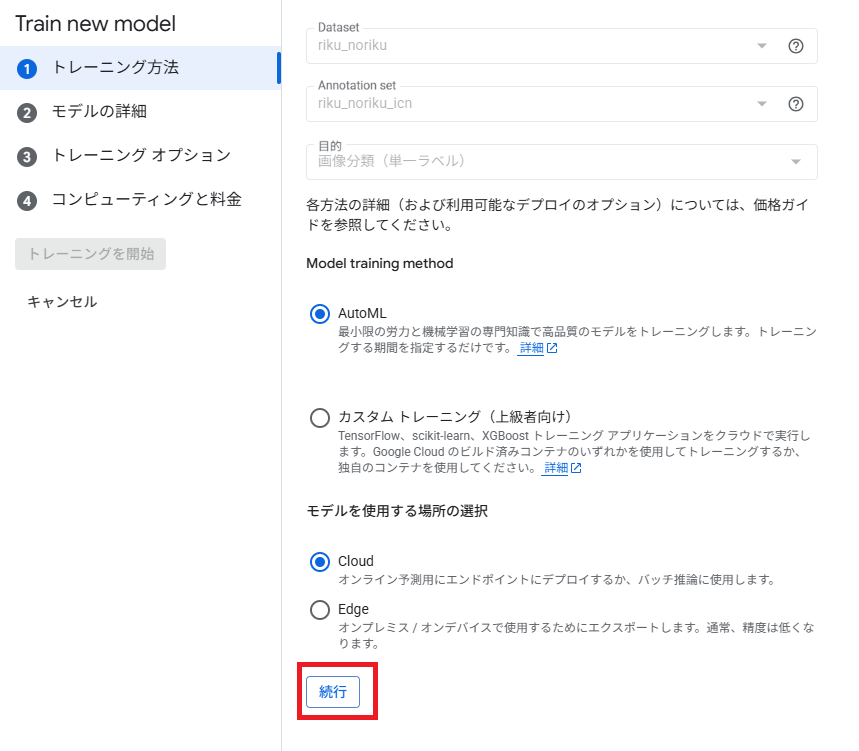
トレーニング方法選択
カスタムモデルを作る場合はここでカスタムトレーニングを選択します。今回はAutoML選択。
余談ですが、「Edgeモデル」も選択できます。
これは、リアルタイム応答が必要な場合や、IoT機器への搭載、オフラインで動作させるようなユースケースで有用です。
AutoML Edge モデルのトレーニング(Google Cloud ドキュメント)
モデルの詳細
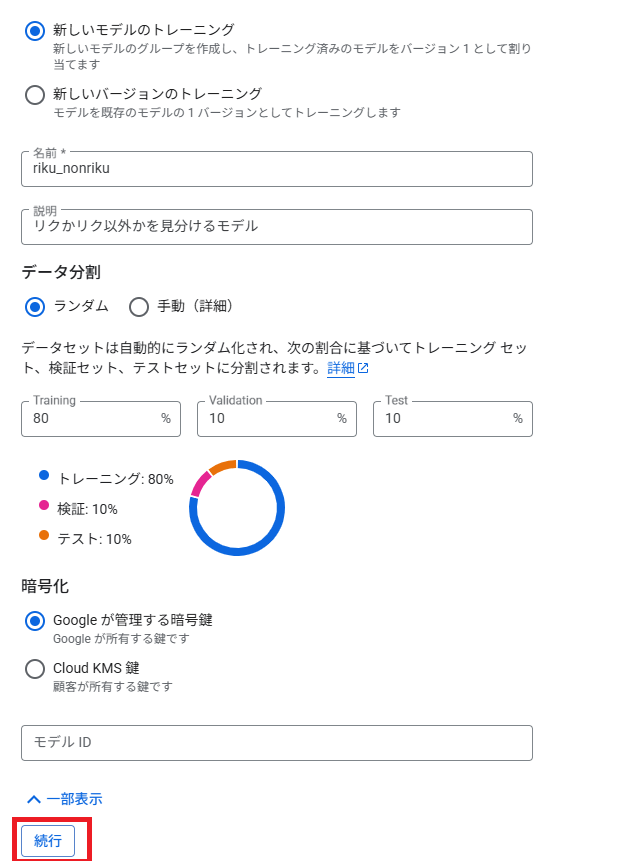
今回は新しいモデルのトレーニングを選択します。
学習の割合は手動で変えることも可能ですが、今回はデフォルトの通りの割合で進めます。
Vertex AIのデフォルトで以下の割合で分割されます。
トレーニング:80%
検証:10%
テスト:10%
AutoML モデルのデータ分割の概要(Google Cloud ドキュメント)
トレーニングオプション
増分トレーニングかどうか尋ねられます。既存のモデルに追加学習を行う場合は増分トレーニングを選び、既存モデルを選択します。
今回は新規なのでそのまま続行します。

ノード時間の最大値を選択
どの程度の時間使って学習するかの最大値を選択します。
8~800の間で入力します。最小の8で進みます。

トレーニング待ち
トレーニング完了まで待ちます。
なお、トレーニング完了したらメールが届きます。
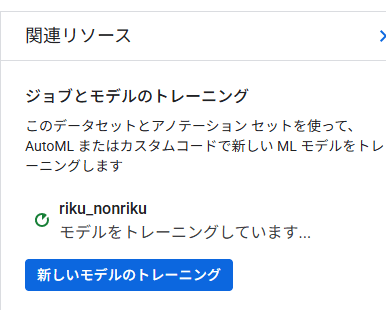
トレーニング完了
トレーニング完了したら、「トレーニング」の項目に完了と出力されます。
今回は1時間43分かかりました。
評価、デプロイ
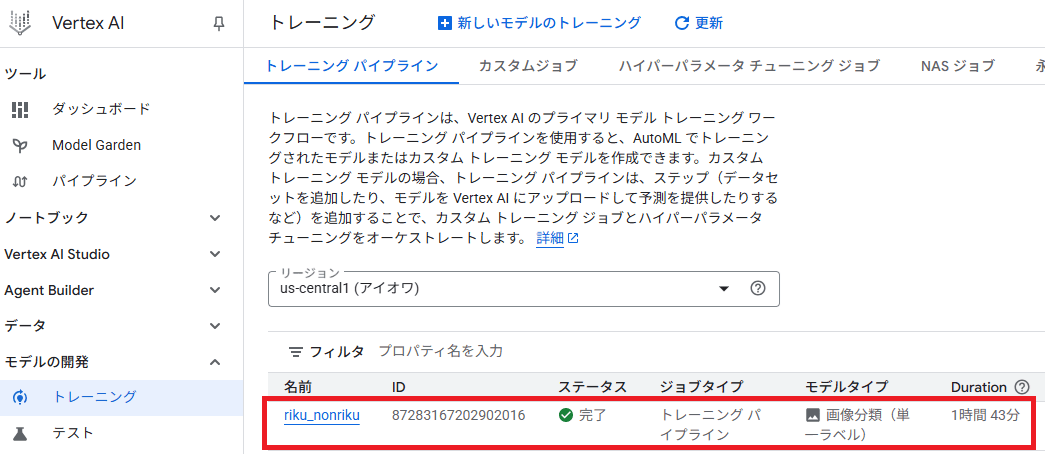
Step7:評価結果確認
モデル全体の評価指標確認
AutoMLの素晴らしい点の一つは、モデルの評価まで終わらせてくれるところだと思います。
トレーニング終わった時点で再現率、適合率、混合行列、PR曲線等の各種指標を出力してくれます。
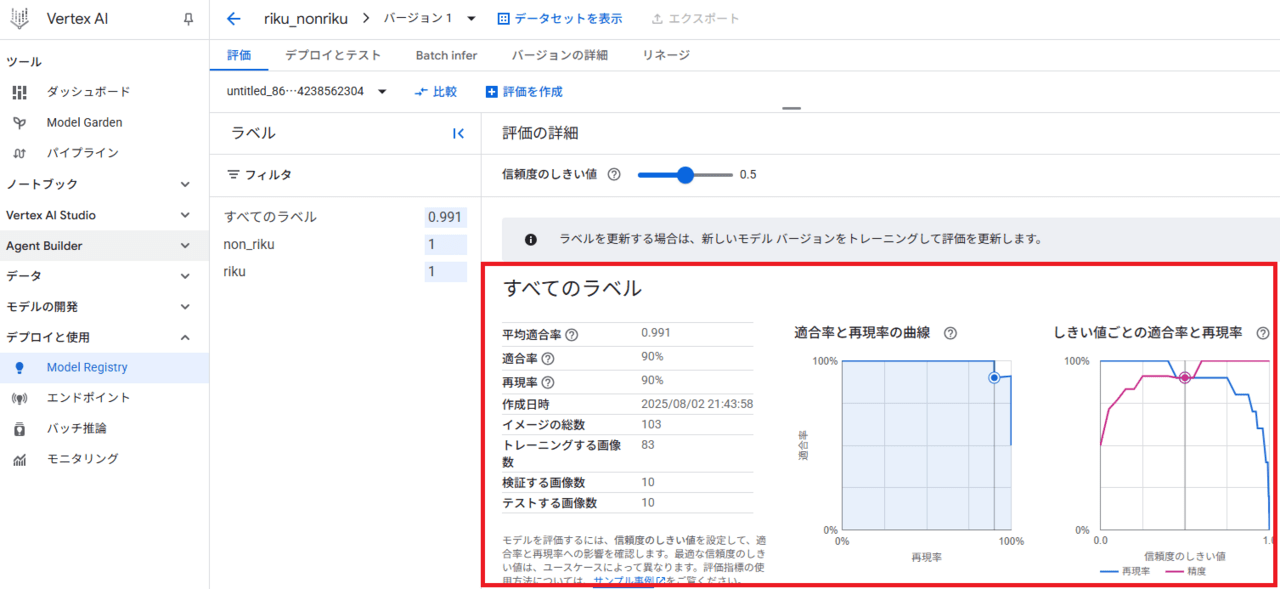
今回は、いい感じに1つ間違えていました。偽陽性が1サンプルありますね。

参考までに、混合行列と再現率/適合率/正解率の計算方法は以下の通りです

間違えたサンプルの確認
混合行列で、1サンプル間違えているのが確認できました。
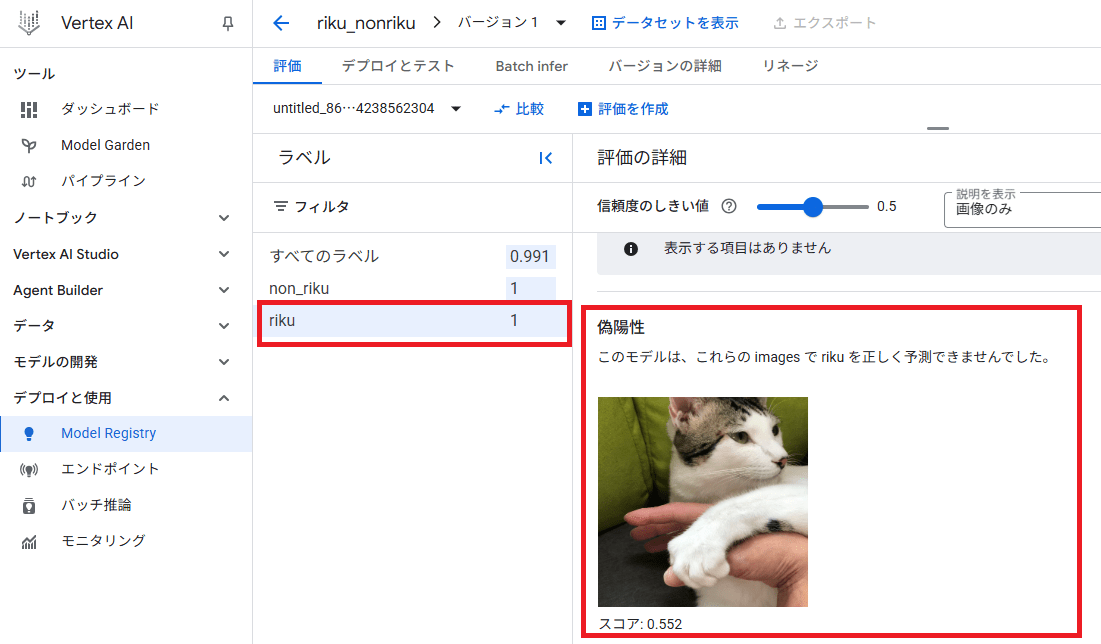
評価のラベルから「riku」ラベルを選択すると、間違えたサンプルと正解したサンプルが見れます。
・・・なるほど、リクっぽい猫ですね。
ただ、スコアも0.552と、閾値である0.5をわずかに上回っただけだったことが確認できます。
正しかったサンプルの確認
正しく分類できたものは、どれも高いスコアであることがわかります。かわいい。
non-rikuも0.78~1の間のスコアでした。

例えば、0.5を閾値にして「リクか、リク以外か」の二値分類とするだけでなく、
スコアが0.7未満の場合には「リク以外の可能性もある」といった選択肢を設け、
人間が目視確認するフローを組み込むなど、ユースケースに応じた柔軟な対応検討が必要となるでしょう。
Step8:デプロイして遊んでみる
やりたいことはほぼ終わったのですが、せっかくならデプロイまでしようと思います。
エンドポイントにデプロイを選択
モデルの画面から、「デプロイとテスト」を選び、「エンドポイントにデプロイ」を押下。
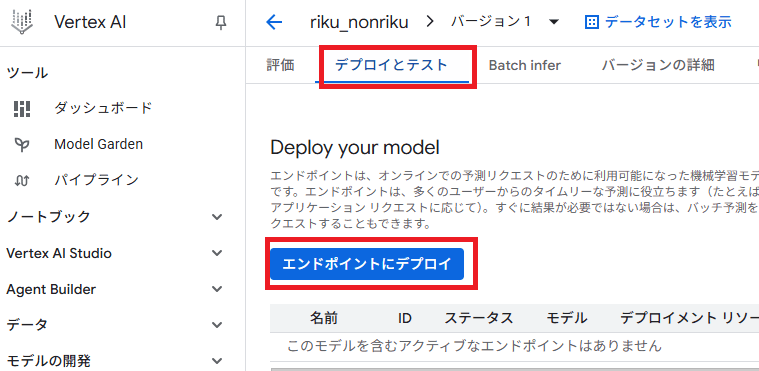
エンドポイントの定義
エンドポイント名を選択して続行を押下します。
プライベートアクセスにするには、カスタムモデルもしくはAutoML 表形式モデルのみです。
とはいえ、デフォルト設定でもIAMで認証されたトークンが必須になるため、
誰でもアクセスできるわけではないのでご安心ください。
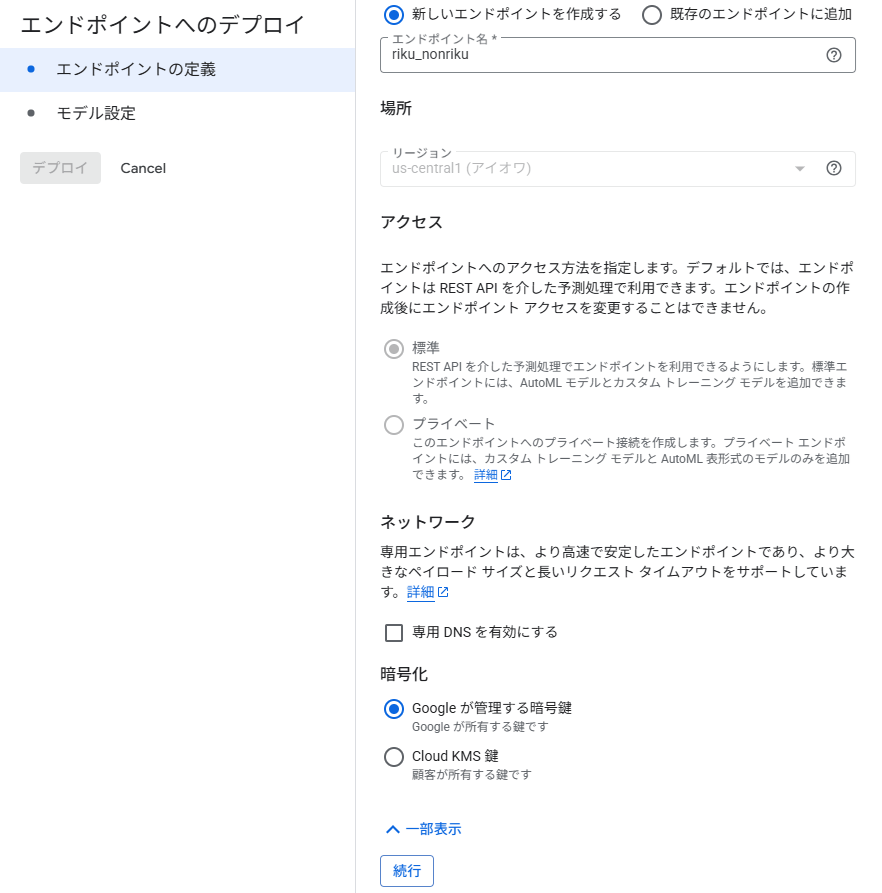
モデル設定
モデル設定を行います。「コンピューティングノードの数」は、今回は1としてます。
本番環境への適用なら2以上をお勧めします。
AutoMLのSLOは、2ノード以上を利用した前提で99.9%と定義されております。
AutoML VisionのSLO(Google Cloud ドキュメント)
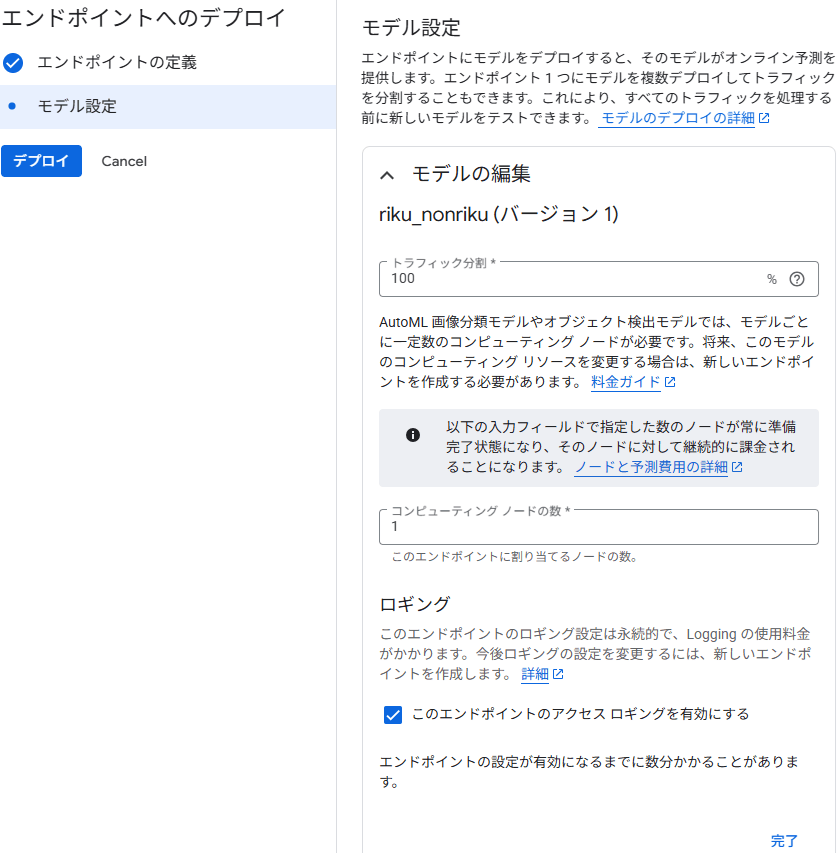
モデル設定
モデルのデプロイされるまで待ちます。
![]()
テスト
デプロイも完了したらメールきます。体感10分くらいでした。
以下の画面のステータスが「アクティブ」になります。
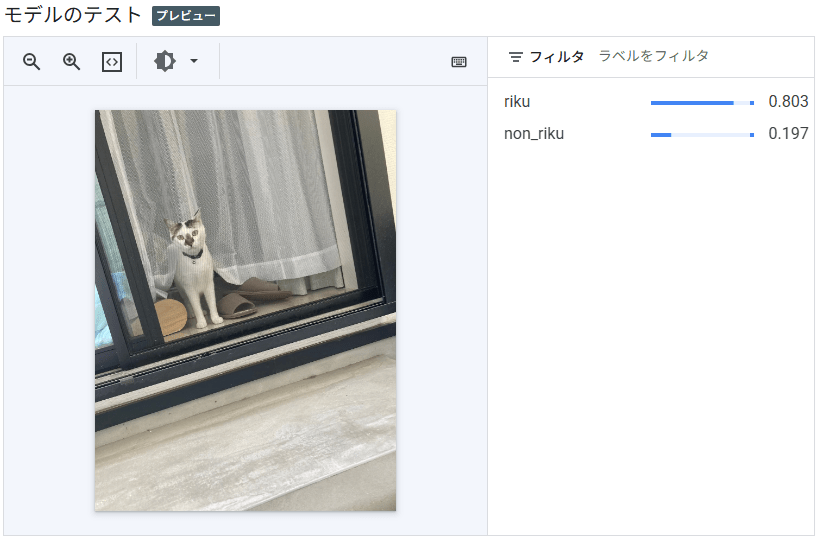
また、下部に「モデルのテスト」という項目が出てきました。ここからテストします。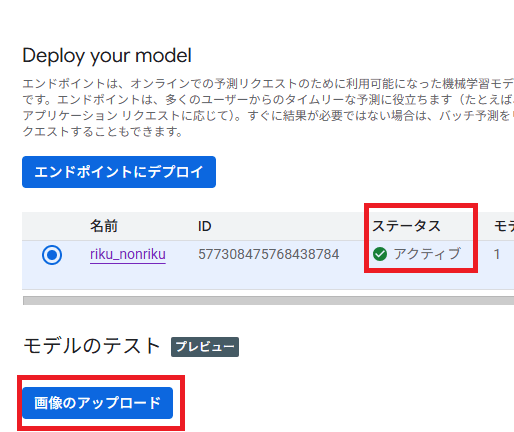
今までのサンプルとはまた別の画像でテストしてみます。しっかりとリクと判定されましたね! かわいい。
今回はコンソールからGUIでのテストで終わりますが、もちろんAPIからも呼び出し可能です。
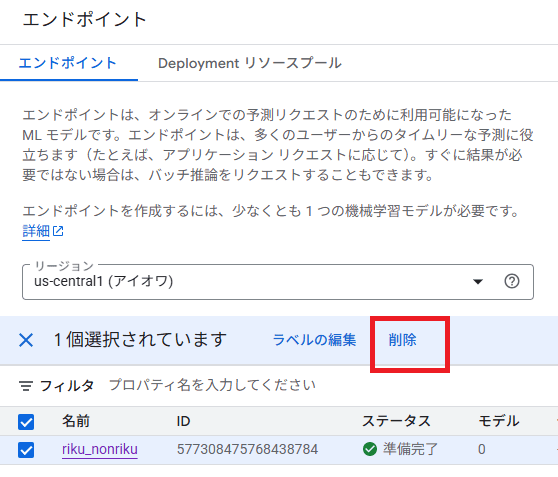
後片付け
エンドポイント削除の前に、モデルのデプロイを解除が先に必要です

エンドポイントの削除が可能になりました。削除して終わります。
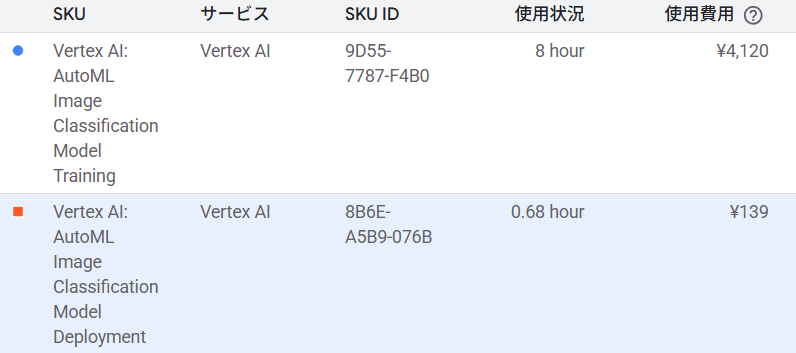
Step9:コストの確認
後日、コスト確認しました。
合計 \4,259- でした。
トレーニング(8ノード時間): \4,120-
デプロイ(1ノード、約40分): \ 139-
まとめ
今回は、Google Cloud Vertex AI の AutoML を使って、愛猫リクとそれ以外の猫を分類するオリジナルAIモデル「リクか、リク以外か」を構築しました。
AutoML を利用することで、専門的な知識がなくても、データの準備からラベリング、モデルのトレーニング、そして評価、デプロイまでの一連のプロセスをスムーズに進められることがお分かりいただけたかと思います。特に、直感的な GUI 操作で高品質なモデルが構築できる点は、AutoML の大きな魅力です。
実際のビジネス案件でAIモデルを使うとなると、評価は非常に重要なポイントになります。100%の精度は現実的に難しいため、どの評価指標を重視するか、そして間違えた場合の対応をどうするかといった判断が不可欠です。
具体的には、再現率を重視するのか、適合率を重視するのか。また、誤分類が発生した際のセーフティネットとして人の判断を組み込むのか、といった検討が求められます。各評価指標を深く理解した上で、「このユースケースでは、この程度の数値が出ればビジネスに活用できる」という明確な判断基準を持つことが、AI導入成功の鍵となるでしょう。